2023.7.24-2023.7.30暑假第三周博客
2023.7.25
今日学习了NameNode元数据
Hadoop是如何记录和整理文件和block块的关系呢?
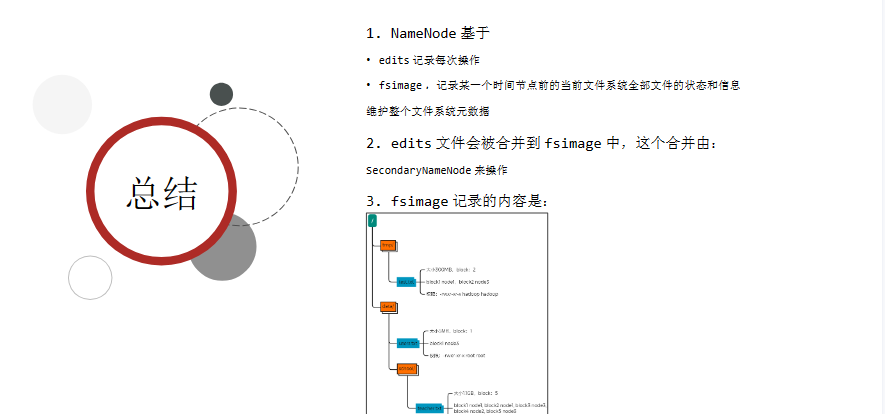
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
edits是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件及其对应的block

会存在多个edits文件确保不会有超大edits文件的存在,但是这样检索起来会很困难,效率低下,所以需要 合并edits文件,得到最终的结果
将全部的edits文件合并为最终结果,即可得到一个FSImage文件
所以维护过程为:
每次对HDFS的操作都会记录在edits文件中
当edits文件大小达到上限后,就会开启新的edits文件进行记录
如果没有fsimage文件,将全部edits文件合并为第一个fsimage
如果当前已经存在了fsimage文件,将全部edits文件和已存在的fsimage进行合并,形成新的fsimage
• dfs.namenode.checkpoint.period ,默认 3600 (秒)即 1 小时
• dfs.namenode.checkpoint.txns ,默认 1000000 ,即 100W 次事务
只要有一个达到条件就执行。
检查是否达到条件,默认 60 秒检查一次,基于:
• dfs.namenode.checkpoint.check.period ,默认 60 (秒),来决定
然后合并完成后提供给 NameNode 使用。
2023.7.26
今日学习的是HDFS数据的读写流程,这也是HDFS内容的最后一部分了,从明天开始就要进入YARN的学习了
写入的流程为:
1. 客户端向 NameNode 发起请求
2. NameNode 审核权限、剩余空间后,满足条件允许写入,并告知客户
端写入的 DataNode 地址
3. 客户端向指定的 DataNode 发送数据包
4. 被写入数据的 DataNode 同时完成数据副本的复制工作,将其接收的
数据分发给其它 DataNode
5. 如上图, DataNode1 复制给 DataNode2 ,然后基于 DataNode2
复制给 Datanode3 和 DataNode4
6. 写入完成客户端通知 NameNode , NameNode 做元数据记录工作
关键信息点:
• NameNode 不负责数据写入,只负责元数据记录和权限审批
• 客户端直接向 1 台 DataNode 写数据,这个 DataNode 一般是离客户
端最近(网络距离)的那一个
• 数据块副本的复制工作,由 DataNode 之间自行完成(构建一个
PipLine ,按顺序复制分发,如图 1 给 2, 2 给 3 和 4 )
句没有,少一句不行,用更短时间,教会更实用的技术!
高级软件人才培训专家
总结总结
1 、对于客户端读取 HDFS 数据的流程中,一定要知道
不论读、还是写, NameNode 都不经手数据,均是客户端和 DataNode 直接通讯
不然对 NameNode 压力太大
2 、写入和读取的流程,简单来说就是:
• NameNode 做授权判断(是否能写、是否能读)
• 客户端直连 DataNode 进行写入(由 DataNode 自己完成副本复制)、客户端直连 DataNode
进行 block 读取
• 写入,客户端会被分配找离自己最近的 DataNode 写数据
• 读取,客户端拿到的 block 列表,会是网络距离最近的一份
3 、网络距离
• 最近的距离就是在同一台机器
• 其次就是同一个局域网(交换机)
• 再其次就是跨越交换机
• 再其次就是跨越数据中心
HDFS 内置网络距离计算算法,可以通过 IP 地址、路由表来推断网络距离
2023.7.27
今日学习了分布式计算的概述
大数据体系内的计算, 举例:
• 销售额统计、区域销售占比、季度销售占比
• 利润率走势、客单价走势、成本走势
• 品类分析、消费者分析、店铺分析
等等一系列,基于数据得出的结论。 这些就是我们所说的计算。
分布式计算有两种模式
1.分散->汇总模式
2.中心调度->步骤执行模式
分散 -> 汇总模式:
1. 将数据分片,多台服务器各自负责一部分数据处理
2. 然后将各自的结果,进行汇总处理
3. 最终得到想要的计算结果
生活中的“人口普查”
就是典型的分散汇总的分布式统计模式
中心调度 -> 步骤执行模式:
1. 由一个节点作为中心调度管理者
2. 将任务划分为几个具体步骤
3. 管理者安排每个机器执行任务
4. 最终得到结果数据
生活中的各类项目的:项目经理 和 项目成员
就是这种模式,一个管理分配任务,其余人员领取任
务工作
MapReduce概述
MapReduce是 分布汇总模式的计算框架,提供了Map和Reduce两个接口
• Map 功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
• Reduce 功能接口提供了“汇总(聚合)”的功能
注: MapReduce 尽管可以通过 Java 、 Python 等语言进行程序开发,但当下年
代基本没人会写它的代码了,因为太过时了。 尽管 MapReduce 很老了,但现在
仍旧活跃在一线,主要是 Apache Hive 框架非常火,而 Hive 底层就是使用的
MapReduce 。
2023.7.28
YARN和MapReduce的关系
MapReduce是基于YARN运行的,即没有YARN无法运行MapReduce程序
YARN是Hadoop内部提供的进行分布式资源调度的组件
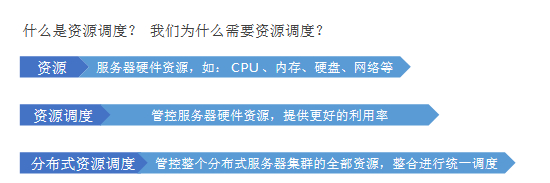
简单来说,就是对资源进行管理,使用更加有次序,不至于杂乱无序,提高效率
服务器会运行多个程序, 每个程序对资源( CPU 内存等)的使用都不
同
程序没有节省的概念,有多少就会用多少。
所以,为了提高资源利用率,进行调度就非常有必要了。
将服务器上的资源进行划分
对程序实行申请制度,需要多少申请多少
YARN 管控整个集群的资源进行调度, 那么应用程序在运行时,就是在 YARN 的监管(管理)下去运行的。
这就像:全部资源都是公司( YARN )的,由公司分配给个人(具体的程序)去使用。
比如,一个具体的 MapReduce 程序。
我们知道, MapReduce 程序会将任务分解为若干个 Map 任务和 Reduce 任务。
2023.7.29
ResourceManager :整个集群的资源调度者, 负责协调调度各个程序所需的资源。
• NodeManager :单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
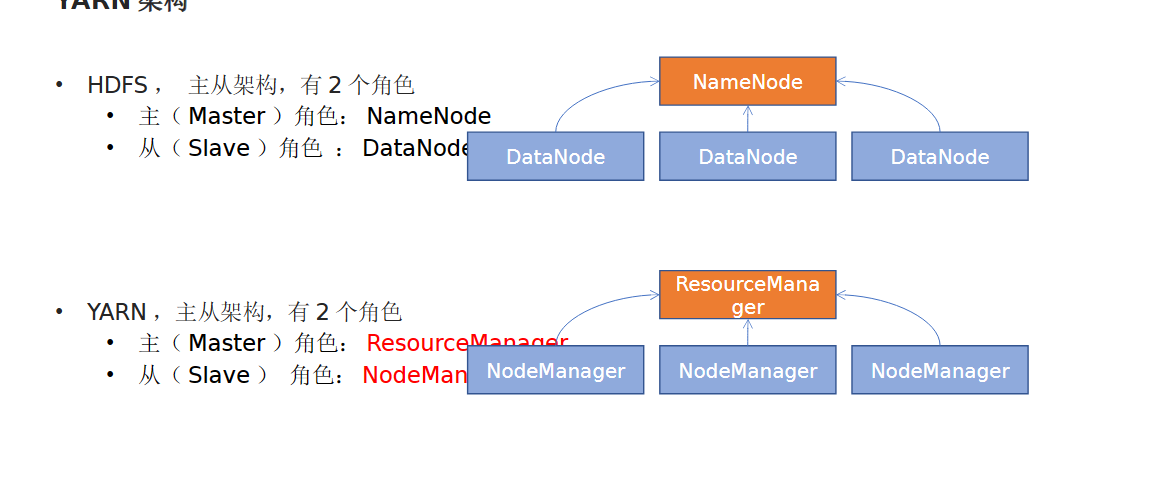
1. YARN 的架构有哪 2 个角色?
• 主( Master ): ResourceManager
• 从( Slave ): NodeManager
2. 两个角色各自的功能是什么?
• ResourceManager : 管理、统筹并分配整个集群的资源
• NodeManager :管理、分配单个服务器的资源,即创建管理容器,由容
器提供资源供程序使用
3. 什么是 YARN 的容器?
• 容器( Container )是 YARN 的 NodeManager 在所属服务器上分配
资源的手段
• 创建一个资源容器,即由 NodeManager 占用这部分资源
• 然后应用程序运行在 NodeManager 创建的这个容器内
• 应用程序无法突破容器的资源限制
2023.7.30
今天在LINUX中部署了YARN


对mapred-env.sh和mapred-site.xml文件进行了修改后
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
之后修改了yarn-env.sh
添加了环境变量
之后修改了yarn-site.xml文件
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
然后把配置文件分发到node2和node3
之后通过start-yarn.sh就可以启动yarn进程了
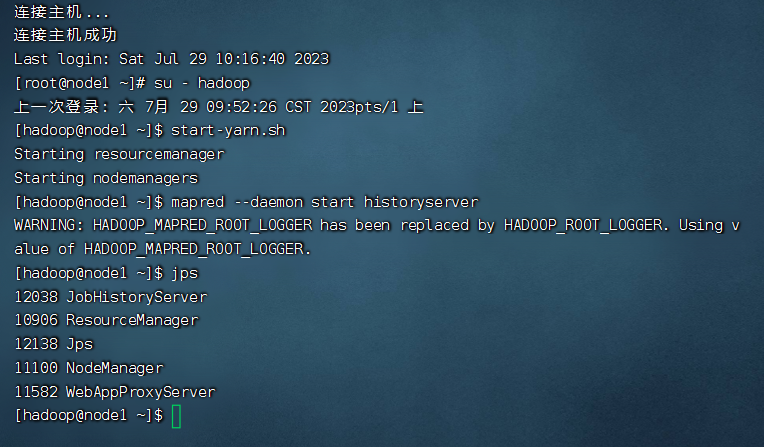
yarn提供了node1:8088端口进行监控和查看