18循环导入/文件类型/模块查找/包
循环导入问题(以后工作中项目的文件名肯定都是以英文为主 )
# 两个文件彼此导入彼此 (假如两个模块,一个模块为a,一个为b。在a里面导入import b,在b里面导入import a)
循环导入的时候极有可能出现某个名字还没有被创建就使用的情况导致报错(import 在定义函数之前,导致在两个模块里面来回执行,加载不到import后面的东西,导致调用不出来!)
"""在以后的编程生涯中 尽量去避免出现循环导入的问题"""
如果确实需要循环导入 那么需要确保双方使用的名字都必须'提前定义好'
(一错再错的办法)
方式1:将导入模块的句式写在定义名字的下面
方式2:将导入模块的句式写在函数体代码内
判断文件类型
py文件可以被分为两种类型
1.执行文件(现在的文件)
2.被导入文件(已经写好模块,需要导入到现在文件里面的文件)
有一个内置变量__name__
①当__name__所在的文件是执行文件的时候 结果是__main__
②当__name__所在的文件是被导入文件时候 结果是文件名(模块名)
可以借助于__name__区分被导入的代码和测试代码
if __name__ == '__main__':(在被导入模块里面写)
func() #下面写该导入模块需要被测试的代码(这样我们在写执行文件的时候,这些测试的代码不会进去,因为在导入模块中_ _name_ _等于导入的文件名!!)
"""
由于上述代码在很多启动脚本中经常使用 所以有简写方式
直接输入main之后按tab键即可(自动补全成if __name__ == '__main__':)
"""
"""
1.先从内存空间中查找
2.再从内置模块中查找
3.最后去sys.path查找(类似于我们前面学习的环境变量)
如果上述三个地方都找不到 那么直接报错!!!
"""
注意:在创建py文件时候一定不要跟模块名(内置/第三方)冲突!!
import sys
print(sys.path) # 结果是一个列表 里面存放了很多路径(查找模块的时候只需要站在执行文件所在层次的相关路径查看即可)
如何解决?
# 方式1:主动添加sys.path路径(类似于添加环境变量)
import sys
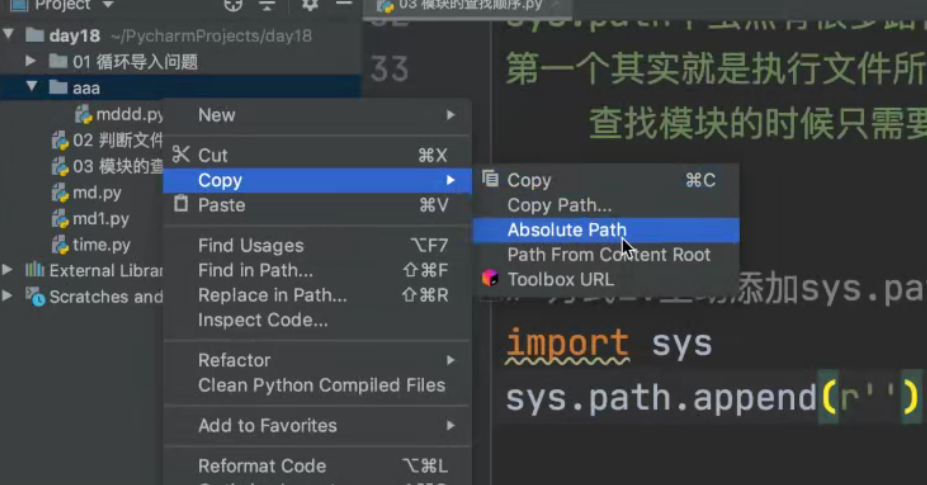
sys.path.append(r'/Users/jiboyuan/PycharmProjects/day18/aaa') #看下面图片(如何复制路径)
"""
pycharm会自动将项目目录所在的路径添加到sys.path中(从里面的py文件可以直接调用外层的py文件,但是外层的不能直接调用内层py,当然这个只是pycharm自动导入了,其他软件没有这个功能!!)
方式2:利用from...import...句式指名道姓的查找
from aaa import mddd # 从文件夹aaa中导入mddd模块
print(mddd.name)
from aaa.bbb.ccc import mm # 通过点的方式进入下一层目录(aaa表示最上层,bbb是aaa下一层py,一直后推)
print(mm.name)
"""
#.在导入模块的时候一切查找模块的句式都是以执行文件为准
无论导入的句式是在执行文件中还是在被导入文件中!!!
# 绝对导入
永远按照执行文件所在的路径一层层往下查找(无脑查找即可)
# 相对导入
相当导入打破了必须参照执行文件的所在路径的要求 只需要考虑当前模块所在的路径然后使用特殊符号.去查找其他模块即可
from . import a(比如当前在b.py文件里面,和a.py路径一个层级,只需要在b中用点号即可!!)
相对导入只能在被导入文件中使用 不能在执行文件中使用
"""
预备知识
.表示当前路径
..表示上一层路径
../..表示上上一层路径
"""
'''以后如果想一劳永逸 那么就只使用绝对导入即可'''
#从专业的角度来解释的话
包就是内部含有__init__.py的文件夹
#从实际的角度来解释的话
包就是多个模块的结合体(内部存放了多个模块文件)
eg:我们的电脑某个文件夹下面有很多不同类型的文件
视频文件、音频文件、文本文件、图片文件
包的导入方式:
①直接在创捷的模块下层创建__init__.py的文件,该模块就变成包
②直接点击模块py文件右键>>>点击重构>>>点击转换为python的包(英文就是package)
在执行文件里面导入包的方式:(在导入包的时候 索要名字其实是跟包里面的__init__.py要)
①如果想直接通过包的名字使用包里面所有的模块 那么需要在__init__.py中提前导入
上述方式的好处在于__init__可以提前帮你准备好可以使用的名字
在如果想直接通过包的名字使用包里面所有的模块 那么需要在__init__.py中提前导入
上述方式的好处在于__init__可以提前帮你准备好可以使用的名字里面提前写好包里面的所有py文件,到时候直接在执行文件中调用这个__init__.py文件即可
②也可以直接忽略__init__的存在使用绝对导入即可
上述方式的好处在于不需要考虑包的存在 直接当成普通文件夹即可
直接在执行文件中写
import 包名称 from m1,m2,m3(包里面所有文件,除了__init__.py)
'''包里面的__init__可以看成是你的管家 ,可以用可以不用.一般都使用绝对导入的方法'''
1.小白阶段
此阶段写代码就是在一个文件内不停地堆叠代码的行数(面条版本)
2.函数阶段
此阶段写代码我们学会了将一些特定功能的代码封装到函数中供后续反复调用
3.模块阶段
此阶段不单单是将功能代码封装成函数,并且将相似的代码功能拆分到不同的py文件中便于后续的管理
"""
为什么如此演变???
eg:我们可以现象成使用电脑的过程
小白阶段相当于在C盘下直接存取各种类型的文件
函数阶段相当于在C盘下创建文件夹管理文件
模块阶段相对于考虑性能在不同的盘下存档不同的数据
答案:更加方便、快捷、高效的管理资源
"""
# 我们实际工作中编写的程序软件都是有很多文件夹和文件组成的
这些文件夹和文件其实都有各自存在的意义和主要功能
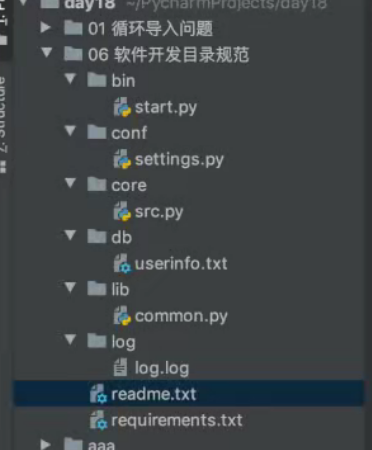
1.bin文件夹
存放程序的启动文件 start.py
2.conf文件夹
存放程序的配置文件 settings.py
3.core文件夹
存放程序的核心业务 src.py
就是最为重要的代码 能够实现具体需求
4.lib文件夹
存放程序公共的功能 common.py
5.db文件夹
存放程序的数据 userinfo.txt
6.log文件夹
存放程序的日志记录 log.log
7.readme文本文件
存放程序的说明、广告等额外的信息
8.requirements.txt文本文件
存放程序需要使用的第三方模块及对应的版本
ps:目录的名字可以不一致 但是主要的思想是一致的
就是为了便于管理 解耦合...
拿到启动文件之后直接运行即可 无需考虑程序内部的复杂程度 便于管理
当代码越来越多的时候 你才能体会到拆分的好处!!!