AI-5 深度学习计算
5.1块和层
我们一直在通过net(X)调用我们的模型来获得模型的输出。 这实际上是net.__call__(X)的简写。 这个前向传播函数非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。
Sequential的设计则是为了把其他模块串起来。
5.1练习
1如果将MySequential中存储块的方式更改为Python列表,会出现什么样的问题?
将无法通过parameters()迭代器访问参数。

2实现一个块,它以两个块为参数,例如net1和net2,并返回前向传播中两个网络的串联输出。这也被称为平行块。
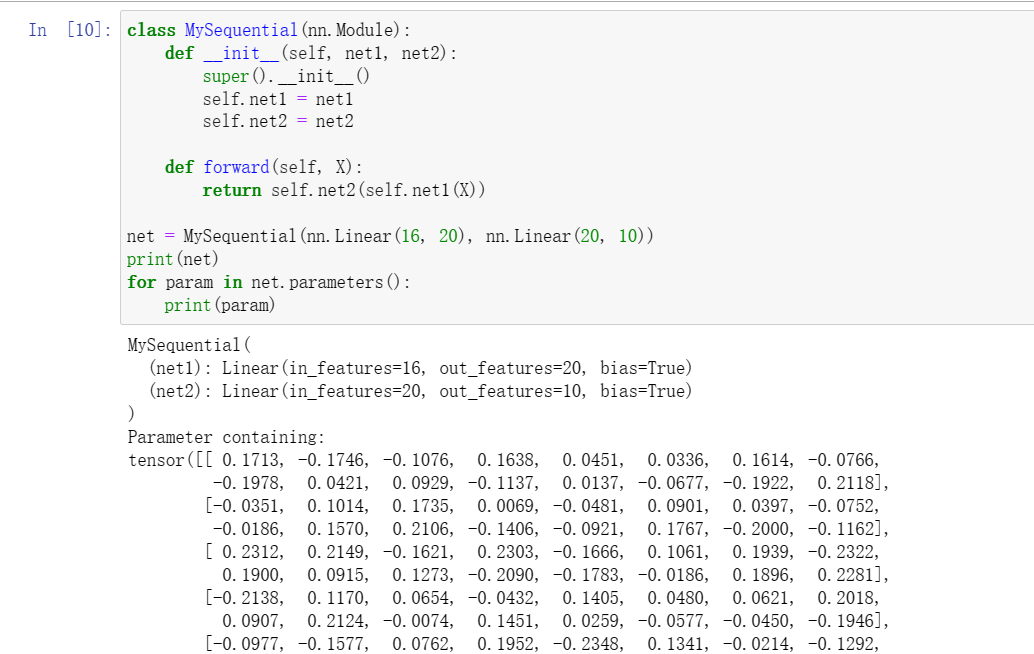
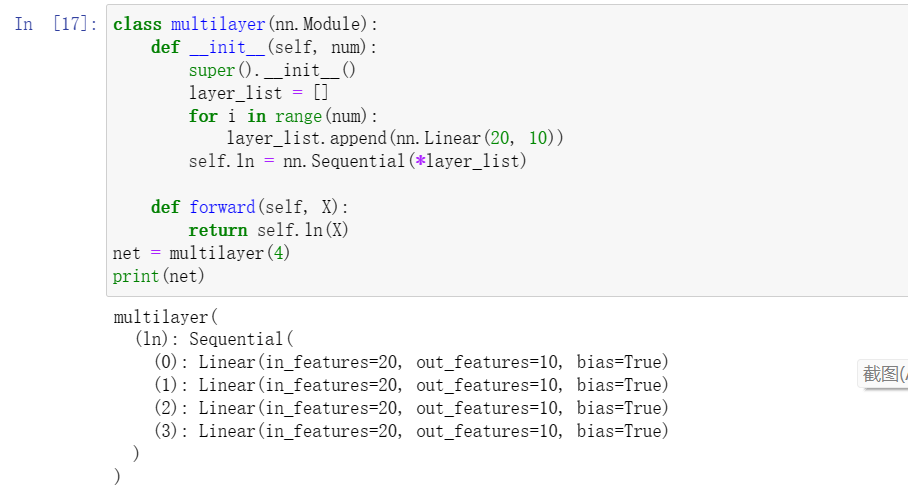
3假设我们想要连接同一网络的多个实例。实现一个函数,该函数生成同一个块的多个实例,并在此基础上构建更大的网络。
通过sequential连续定义多个块
5.2. 参数管理
经过训练后,我们将需要使用这些参数来做出未来的预测。 此外,有时我们希望提取参数,以便在其他环境中复用它们, 将模型保存下来,以便它可以在其他软件中执行, 或者为了获得科学的理解而进行检查。
当通过Sequential类定义模型时,可以像访问列表一样访问模型的参数。
print(net[2].state_dict())另外,这一节还有一些参数初始化的方法。
5.2. 练习
1使用 5.1节 中定义的FancyMLP模型,访问各个层的参数。
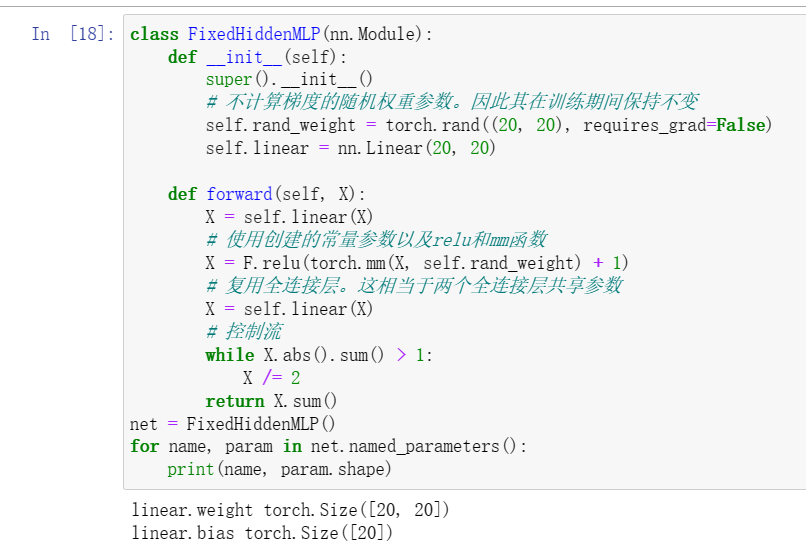
2查看初始化模块文档以了解不同的初始化方法。
包括初始化为1,0,推荐增益值等等,链接:torch.nn.init — PyTorch 2.0 documentation
3构建包含共享参数层的多层感知机并对其进行训练。在训练过程中,观察模型各层的参数和梯度。
共享参数层的参数是具有相同的内存地址,他们的参数回同步改变。
4为什么共享参数是个好主意?
也许可以减小参数所占空间?
5.3. 延后初始化
我们定义了网络架构,但没有指定输入维度。我们添加层时没有指定前一层的输出维度。我们在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
练习
1如果指定了第一层的输入尺寸,但没有指定后续层的尺寸,会发生什么?是否立即进行初始化?
框架会自动设置后续尺寸。
2如果指定了不匹配的维度会发生什么?
会报错
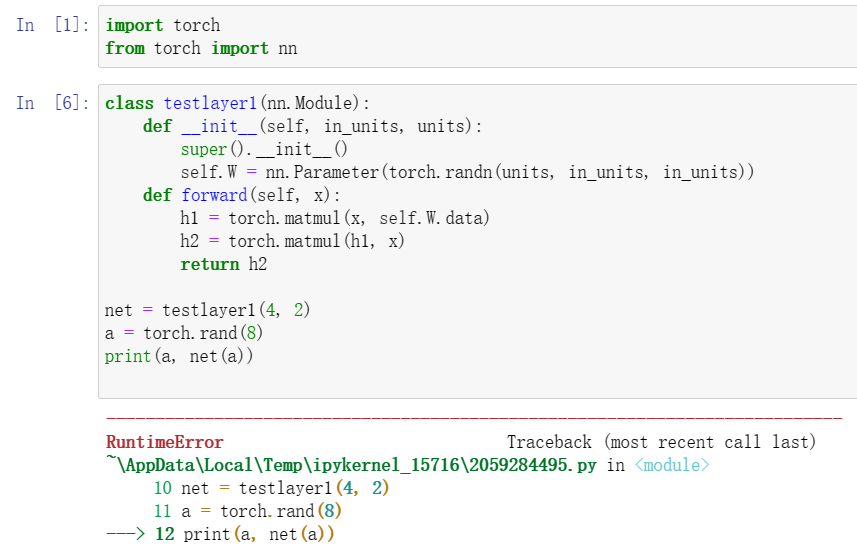
3如果输入具有不同的维度,需要做什么?提示:查看参数绑定的相关内容。
会共享参数?