论文阅读 | A Measurement Study ofWechat Mini-Apps/微信小程序的测量研究
引言
本文提出了第一款能够自动下载、解包、索引微信小程序的大型微信小程序爬虫MiniCrawler。
挑战
获取小程序的方式多种多样。可以在微信内部的小应用搜索界面中手动输入关键字进行下载,或者扫描二维码,或者使用小应用的共享url获取。然而,这些方法都不能进行扩展。此外,与谷歌Play商店不同的是,小程序没有门户网站。不能用网络流量分析工具(如Burp Suite[27])来探测微信和它的服务器之间的流量来构建爬虫,因为微信已经使用私有和加密协议保护了它的客户端和服务器之间的通信。因此,必须对微信应用程序进行逆向工程,从微信二进制文件中识别出小程序程序搜索界面,自动生成关键字,获得规模化的小程序程序。
- 识别微信代码内的小程序搜索和下载接口。由于搜索小程序程序的唯一接口是在微信应用程序内部,必须逆向工程微信代码来识别它。然而,微信是一个超过100mb的巨型软件,由本机代码和Java字节码组成。同时,大量使用混淆(如符号重命名、反调试和反仿真)来阻止逆向。如何查明感兴趣的代码,用正确的输入调用它们,并解析从服务器返回的输出,是必须解决的第一个挑战。
找接口
- 创建覆盖范围更广的关键词列表。即使可以确定微信应用程序内部的搜索界面,根据关键字收集小程序程序信息,也必须定义单词列表,因为它直接影响可以访问多少小程序程序。一个直观的方法是尝试使用所有可能的单个单词(例如,汉字,英文字母和数字)进行搜索。然而,一个单词搜索最多只能返回500个小程序程序,这取决于它们的流行程度和与关键字的接近程度,而且只有流行的小程序程序将被收集。为了收集尽可能多的小程序程序,不仅需要使用单个单词,还需要使用短语及其组合。然而,汉语中有太多的短语,尝试它们是不实际的。
建立字典
- 绕过微信限制。服务器端基于用户行为为每个用户构建了一个风险模型。例如,根据微信服务器[30]为每个用户维护的专有风险模型,如果用户积极地使用某些动态分析框架(如钩住[29]),她的帐户可能会从临时限制登录被禁止到永久帐户封锁。一旦该账户被屏蔽,需要花费5-30美元才能获得另一个账户,因为微信需要一个与该账户关联的唯一手机号码。
反爬绕过
使用静态和动态分析找接口
使用微信搜索小应用程序时,有一个搜索按钮,然后,必须存在一个处理点击事件的函数,这个事件处理程序将向微信服务器发送输入请求,以返回与搜索关键词匹配的列表。 也就是说,必须有一个服务器API,只需要准备正确的输入来触发这个API。 此准备由事件处理程序执行。 因此,首先使用动态分析来定位这个事件处理程序。在Android中,事件处理程序作为类字段附加到GUI元素(在Android中也称为视图)。但是,通过实验发现,视图是WebView,按钮是HTML按钮,通过JavaScript(Web代码)对Java(本地代码)进行函数调用。为了找到Java中搜索逻辑的实现,我们hook并跟踪JavaScriptInterface,这是JavaScript代码可以用来调用Java代码的唯一函数。
在确定了JavaScriptInterface函数之后,首先使用工具JADX[28]反编译微信代码,开始静态分析。 但是,代码非常模糊。 幸运的是,发现微信包含丰富的日志代码,日志例程中使用的字符串(例如,“constructors:keyword=%s”)提供了关于代码功能的大量线索。 有了这些日志字符串,我们很快就找到了生成HTTP(S)请求到微信服务器的代码。 通过进一步反向工程HTTP(S)请求的相应参数,包括URL、HTTP头和令牌(通过动态拦截传出的网络API),我们可以开发一个独立的Python程序来生成搜索请求,而无需再运行微信应用程序。
虽然已经对小程序搜索API进行了反向工程,但仍然无法下载小程序,必须从微信代码中找到下载API。 我们遵循类似的做法,先动态分析,然后静态分析,然后定位代码。 但与迷你App搜索API通过提供相应参数就可以使用独立程序直接查询微信服务器不同,下载API要复杂得多。 更具体地说,它涉及许多异步调用,更糟糕的是,我们无法确认它是否使用HTTP(S)。 但是,我们仍然可以通过运行真正的微信应用程序下载小应用程序,只要我们能够找到以小应用程序标识符作为下载输入的界面。 因此,我们从Download Event的处理程序函数构建了一个调用图,并动态地钩住了所有的callees。 通过打印它们的所有参数,我们成功地识别了以小程序程序ID作为输入的函数。 然后,在运行时,我们在真实的微信应用中动态更新这个小应用ID,从而下载相应的小应用。
使用NLP收集和生成高质量的关键字
为了解决C2,我们需要优化关键词,以最大限度地扩大小应用程序的覆盖面,同时最大限度地减少对微信服务器的请求量。 为此,我们同时使用了广度优先搜索(BFS)和深度优先搜索(DFS)算法。 在我们的BFS中,我们使用前1000个最常用的汉字作为关键字来搜索种子小程序程序,并将进一步用于我们的DFS搜索。 在我们的DFS中,我们从收集的名称和描述中扩展关键字,基于相同类别中的小程序程序往往具有相似的描述。
虽然用提供的最常用的词执行BFS非常简单,但我们需要NLP分析来进行DFS搜索。 更具体地说,在DFS搜索中,我们必须对种子mini-apps的名称和描述执行单词拆分(使用NLP),然后将拆分后的单词用作关键字。 我们对所有新搜索的小程序程序继续这样的过程。 这种方法的关键观察是,小程序程序的描述往往包含高质量的词,因为微信限制描述长度不超过120个词,并且要求开发者简洁准确地总结小程序程序的使用情况。 因此,提供类似功能的小应用程序在其描述中很可能会有共同的词,搜索这些关键词可以让我们接触到更多的应用程序。
我们认为,我们的算法收集的小程序程序具有代表性,原因有二:(𝑖)我们的算法使用了前1,000个最常见的汉字作为初始输入,搜索结果很可能是常用的小应用程序。如前所述,终端用户获取小程序程序的唯一界面是使用内置界面,这需要用户在搜索框中输入中文字符或单词。使用很少使用的中文字符或单词的小程序程序将使小程序程序不太可能暴露给用户。(𝑖𝑖)我们的算法实现了大覆盖:根据目前的报告[6],WeChat现在有超过一百万个小程序程序可用,我们的算法已经收集了1,395,456个元数据。
因此,为了规避腾讯的帐户封锁,我们注意到我们可以使用高级帐户(即,低风险的账户),并且在我们的实验期间它们从未被阻止。更具体地说,高级账户是指()几𝑖个月甚至几年前注册的账户,(𝑖𝑖)有很多好友(不仅仅是一两个好友),(𝑖𝑖𝑖)有发布WeChat时刻、与好友交流等活跃活动,以及(𝑖𝑣)与账户绑定支付卡(借记卡或信用卡)使用微信支付的账户。通过了解这些高级帐户的功能,我们可以有意识地使用这些类型的帐户,并执行更具体的真实用户类型的活动,使它们更像真实用户。例如,对于一个特定的账户,虽然我们不能操纵该账户的注册日期,但我们可以添加更多的好友,更频繁地使用这个账户,使该账户看起来像一个正常的账户。
使用高级帐户,以避免被封锁
WeChat有一个复杂的风险模型来评估每个用户的帐户,并在必要时阻止它,以对抗“网络水军”[31]或虚假帐户攻击。这是因为WeChat账号可以被用来滥用优惠券或点击欺诈[30]。因此,每个用户的账户都有一个风险评分。如果一个账户刚刚注册,几乎没有朋友,几乎不说话,除了下载小程序程序之外没有其他活动,那么它很可能会被禁止,正如我们的研究所证实的那样。
MINICRAWLER详细设计
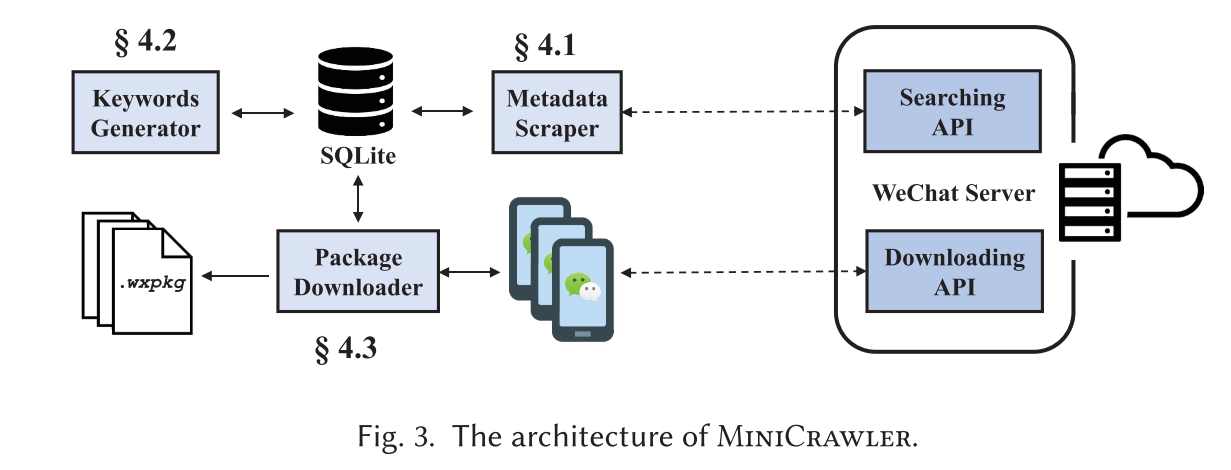
MiniCrawler由三个关键组件组成,如图3所示:
(1)元数据抓取器(§4.1),其将关键字列表作为输入并通过与小程序搜索API交互来产生小程序的元数据,
(2)关键字生成器(§4.2),其对小程序名称和描述执行NLP分析以生成高质量关键字
(3)包下载器(§4.3),其将小程序标识符(ID)列表作为输入,并通过执行相应的WeChat代码来下载它们。
元数据抓取器
在S1(§3.2)中,我们已经发现了具有所需信息的具体值的小程序搜索API,因此我们实现了一个独立的Python脚本来与此API交互。我们的Python脚本将(1)从SQLite数据库读取关键字,(2)从服务器搜索小程序程序,(3)存储返回的结果(即,小程序元数据)到数据库。
-
读取关键词。使用SQLite数据库来存储关键字和迷你应用程序元数据。虽然我们可以从数据库中随机选择关键字进行搜索,但我们决定从最流行的单词开始(即,在我们收集的元数据中具有较高频率的词),因为利用这些词,我们的脚本可能能够找到更多的迷你应用。因此,每次都会查询尚未被选中的前10个最受欢迎的关键字。
-
搜索迷你应用程序。利用所提供的关键字,脚本将与迷你应用搜索API交互以检索匹配的迷你应用的元数据。更具体地说,它会根据关键字构造一个HTTP(S)请求消息,我们使用Python库请求将其发送到WeChat服务器。
-
存储结果。服务器将以JSON格式响应,其中包含miniapp元数据列表。图4中示出了这样的元数据的示例。我们可以看到,响应消息中关于小应用的信息比用户在WeChat GUI中可以看到的更多,例如appid,小应用的标识符;nickName,迷你应用的昵称;标签,应用程序的类别;评估,这意味着评估分数(即,评级);等等。
