真会C#?
Web Framework Benchmarks:权威的web框架性能评测网站
简介和基础
C#简单介绍
特点:
●通用性语言
●类型安全
●面向对象:封装(为对象object创造边界,把面向外部的行为和内部的实现细节分离,外部行为就是public方法,实现细节就是private方法)、继承、多态
目标:生产力
●简洁性
●表达力
●高性能
创作者:Anders Hejlsberg
●Turbo Pascal的创作者
●Delphi的主设计师
●Typescript的创作者
C#是平台中立的,与平台无关
C#的面向对象特性
C#里的构建块,是一个封装了数据和函数的单元,这个单元叫类型(Type)。C#有统一的类型系统,所有的类型都继承于共同的基类Object
在传统的面向对象范式里,唯一的类型(Type)是Class,C#里还有其他类型,如Interface(只对成员进行描述,没有具体实现)。接口在需要多重继承的场景特别有用。
唯一 一种函数成员(Function Member):方法(Method)。方法还包括:属性(Property)和事件(Event,简化了对象状态更改的操作),还有其它的
C#主要是一-种面向对象的语言,但是也借用了不少函数式编程的特性,比如函数可以当作值来对待:委托Delegate;支持纯(purity)模式,避免使用值可变的变量
类型安全
C#主要来说是类型安全的,类型安全是指类型的实例只能通过定义好的协议来进行交互,从而保证类型的内部一致性。比如字符串类型不能进行数值类型的操作
静态类型Static Typing,在编译时就保证类型安全,我的理解就是提前写死类型,在编译时就检查有没有违规的操作,而不是运行时才去检查
动态类型dynamic[daɪˈnæmɪk]
强类型Strongly Typed language
内存管理
依赖于运行时来执行自动内存管理。CLR:Common Language Runtime(公共语言运行时)。CLR里有GC:Garbage Collector(垃圾收集器)
C#没有消灭指针,通常情况下不需要使用指针
平台支持
原来C#主要是在Windows.上面运行
现在可以在所有的平台.上运行
●Windows
●Mac
●Linux
●ios
●Android
CLR简介
.NET/.NET Core的核心就是CLR:Common Language Runtime,CLR和语言无关,不仅仅支持C#
C#是一种托管语言,会被编译成托管代码(IL:Intermediate Language),CRL把IL转化为机器(x64,x86)的原生代码,什么时候转化?JIT(Just-In-Time)编译(刚执行前编译),Ahead-of-Time编译(可提升启动速度)
托管代码的容器:Assembly(程序集,exe或dll,)或Portable Executable,包含IL和类型信息(metadata)。因为有类型信息存在,程序集之间才可以引用
Ildasm可以查看生成的IL语言
支持C#的框架
.NET Framework
.NET Core
Unity
Xamarin
UWP
WinRT
Windows Phone
XNA
Silverlight
.NET Micro Framework
Mono
Sql Server
.NET/.NET Core简介(入门)

Nuget:统一管理库的仓库,可以下载第三方的类库
编译
C#编译器把.cs结尾的源码文件编译成Assembly。Assembly是.NET Core里的包装和部署的单元。Assembly可以是应用程序(.exe),也可以是库(.dll)。.net core只有dll
句法和类型简介
标识符identifier:标识符就是程序员给他们所写的类、方法、变量等起的名字。标识符必须是一个完整的单词,它由Unicode字符组成,并且由字母或者下划线开头。
关键字Keyword:关键字就是对编译器有特殊意义的一些名字。如using,class,static,void,int。大部分关键字都是保留的,意思就是你不可以把它们当作标识符来用。如果非得用关键字当标识符,前面加一个@,实际起效果的标识符不含@
上下文关键字:用于在代码中提供特定含义,但不是C#中的保留字。一-些上下文关键字(如partial和where)在两个或多个上下文中有特殊含义。
类型定义了一个值的蓝本。变量是一个存储位置,它在不同的时期可能是包含不同的值。常量永远表示相同的值。C#里所有的值都是类型的实例。值的含义,变量可能拥有的值是什么,都由它的类型决定。
构造函数和实例化
数据是通过实例化一个类型来创建的。
预定义的类型直接写Literal(我的理解是常量)就可以被实例化了。
而自定义类型则通过new操作符来创建实例。
实例成员VS静态成员
操作于类型实例的数据成员和函数成员都叫做实例成员。
操作于类型而不是类型实例的数据成员和函数成员叫做静态成员。使用static关键字修饰
静态类static class的所有成员都是静态的。静态类不可以创建实例。例如Console,它在整个程序里就一个。
转换、值类型和引用类型、内置类型分类
转换
C#里,互相兼容的类型实例间可以相互转换。转换总是从现有的值创建出来一个新的值。隐式转换是自动发生的,显式转换需要手动进行
隐式转换的两个必要条件:编译器可以保证转换会成功;信息不会有损失(如低精度类型向高精度类型转换肯定能成功,因为高精度类型的存储空间更大)
显式转换的条件(任意一个成立):编译器不能保证转换会成功;信息可能会有损失
如果编译器可以断定转换肯定会失败,那么两种转换都会被禁止。
C#类型分类
值类型:包含所有的内置类型(数值、字符、bool)和自定义的struct和enum。值类型变量/常量的内容就是一个值。使用struct关键字可以创建自定义的值类型。值类型实例的赋值动作总是复制了该实例。值类型的实例所占的内存=它的字段需要内存的总和。CLR会把类型内的字段大小设置为该字段实际大小的整数倍。
引用类型:包含所有的class,数组,delegate,interface类型。包括字符串。引用类型的变量/常量的内容就是到一个含有值的对象的引用。包含两个部分:一个对象和到该对象的引用。给引用类型的变量赋值,复制引用而不是对象实例。允许多个变量引用同一个对象。需要为引用和对象单独分配内存。对象所占内存=其字段所占内存总和+额外的管理开销(最少8字节)。每个对象的引用还需要额外的4或8个字节(根据平台是32位还是64位)。
指针类型
值类型和引用类型的根本区别在于处理内存的方式。
Null是一个literal。可以把nul赋值给引用,表示该引用不指向任何一个对象。普通的值类型不可以为null。C#有一种可空类型nullable types)来表示值类型的null。
内置类型的分类
值类型
●数值型
Signed integer(sbyte,short,int,long)
Unsigned integer(byte,ushort,uint,ulong)
实数(float,double,decimal)
●逻辑(bool)
●字符(char)
引用类型
●字符串(string)
●对象(object)
内置类型在System命名空间下。除了decimal之外的内置类型叫做原始类型。通过指令,在编译后的代码里直接被支持,通常被翻译成底层处理器所直接支持的东西。System.IntPtr和System.UIntPtr也是原始类型。
数值类型

整数类型的Literal(字面量)可使用10/16进制符号,16进制是在前边加上0x(注意是数字0而不是字母o)前缀。从C# 7开始支持下划线,为了可读性,如int million=1_000_000; 0b表示二进制,如var b = 0b1010_1011_1100_1101_1110_1111;
默认情况下,编译器会推断一个数值literal是double还是整数类型。如果包含小数点,或以指数形式展现,那么就是double类型。否则literal的类型是下面列表里第一个能容纳该数值的类型:int,uint,long,ulong
数值的后缀会显式定义Literal的类型

U、L很少使用,因为uint、long、ulong要么可以被推断出来,要么可以从int隐式转换过来。D其实很多余。F、M是比较有用的,当指定float或decimal的Literal的时候,应该加上。
类型转换
当目标类型可以容纳源类型的时候,整数转换是隐式(自动)的。否则,就需要显式转换。如float可以隐式转换为double。所有的整数类型都可以隐式的转换为所有的浮点类型,反过来则必须进行显式转换(最大的整数类型转换为最小的浮点类型呢)。所有的整数类型可以被隐式的转换为decimal类型,反过来则必须进行显式转换口
当从浮点型转为整型时,小数部分是被截断的,没有舍入。把一个很大的整数隐式的转换为浮点类型之后;会保证量级不变,但是偶尔会丢失精度。这是因为浮点类型有更多的量级,而精度可能不足。
除法运算
针对整型的除法操作,会截断余数。
除数变量为0 ,会抛出DivideByZeroException,运行时异常
除数Literal为0,编译错误。
Overflow溢出
在运行时,整型的算术操作可能弓|起溢出。默认情况下,不会抛出异常。结果类似于“环绕”这种行为(到了最大范围值,加1,由于每个位都进1,变成了最小范围值)
checked操作符会告诉运行时,如果 整型的表达式或语句超出了该类型的极限,那么就会抛出OverflowException。checked操作符对++、--、+、-、*、/起作用。checked可以用于表达式(使用圆括号)或语句(使用花括号)。checked对float、double不起作用,因为它们有无限值(无限大和无限小)。
默认开启算数的overflow检查:1、/checked+命令行参数。 2、Visual Studio高级设置里面有 3、针对某部分代码想关闭overflow检查,使用unchecked操作符。
编译时算出来的表达式总会进行溢出检查,除非使用unchecked操作符。
8,1 6位整数类型byte、sbyte、short、ushort没有自己的算术操作符。C#会按需对它们进行隐式转换到大一点的整数类型。
float和double的特殊值

float/double除以0,1.0/0.0为正无穷。0.0/0.0为NaN。
使用==时,NaN不等于任何一个值,包括NaN。使用object.Equals()方法时,两个NaN是相等的。验证某个值是否为NaN,float.IsNan(),double.IsNaN()
bool和操作符
System.Boolean的别名,只有两个值true、false (Literal)。只需要1bit存储空间,但运行时会使用1byte内存(运行时和处理器可以高效操作的最小的块)。针对数组,Framework提供了BitArray类(System.Collections)在这里每个bool值只占用1 bit内存。
bool类型无法和数值类型进行相互转换。
==和!=操作符在用来比较相等性的时候,通常都会返回bool类型。对于值类型(原始类型)来说,==和!=就是比较它们的值。对于引用类型,默认情况下,是比较它们的引用
枚举类型(enum)可以使用==,!=,<,>,<=,>=这些操作符,就是比较它们底层对应的整型数值
&&和||有短路机制(a&&b,a若为假,则不判断b。a||b,a若为真,则不判断b),可避免NullReferenceException。
&和 | 也可以用来判断“与”和“或”的条件,但没有短路机制,所以很少用来进行条件判断。当使用于数值的时候,&和 | 分别执行的是按位与和按位或操作
条件操作符(三元操作符)q ? a:b有三个操作数,如果q为true,那么就计算a,否则计算b。
char和string
System.Char,一个Unicode字符,占2字节,Literal:'x'
转义字符表示无法按字面意思表达的字符
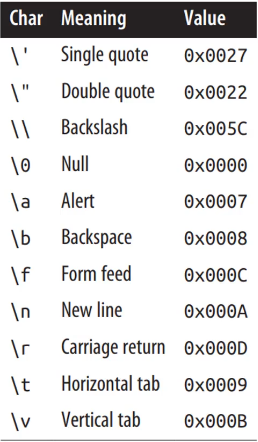
\u(\x)可以使用4位16进制来表示字符
char类型可以隐式转换到可以容纳无符号short类型的数值类型。对于其它的数值类型,需要显式的转换
System.String,表示一串不可变的Unicode字符,Literal : “a string”。是弓|用类型,==操作符比较string的值。适用于char的转义字符都适用于string
逐字字符串(verbatim string literal)@做前缀(在双引号外),不支持转义字符(反斜杠不再有特殊含义),支持多行字符串。想在字符串里面输入双引号,就输入两次双引号
+操作符用于字符串连接,如果其中一个操作数不是string类型,那么会调用它的ToString方法。大量使用+做字符串连接的效率很低,最好使用StringBuilder
字符串插值(string interpolation)C# 6,$前缀(双引号外),可包含表达式(在{}内),任何C#表达式都可以出现在{}内,会调用ToString或等效方法。
int x= 4;Console.WriteLine($"A square has {x} sides"); 注意到,{}里面的是一个变量构成的表达式
可以改变表达式的显示格式,使用:,后边跟着格式化字符串
默认只支持单行,除非使用@,$需在@前
想输入{,就需要输入{{
String不支持>,<等比较操作符,需要使用CompareTo方法
数组
表示了一组特定类型且数量固定的变量(元素)。数组的元素总是存储在连续的内存块里,读取效率高。所有的数组都继承于System.Array类
数组的声明:
char[] vowels = new char[5];
按索引访问元素(从0开始):
vowels[0}='a';
vowels[1]='b';
Console.WriteLine(vowels[1]);//b
数组的长度(元素的个数),Length属性
可使用for循环
一旦数组被创建,那么其长度不可改变。System.Collection和其子命名空间提供了更高级的数据结构,包括可变长度的数组和字典
创建数组时,所有的元素都会被初始化,其值为该类型的默认值。类型的默认值就是内存按位归零的结果
值类型VS引用类型(指数组的元素类型)
性能有区别,值类型:每个元素都作为数组的一部分进行分配内存。引用类型:创建数组时就是创建了一堆null引用(就是还没有指向任何实例的引用)。建议对元素是引用类型的数组初始化后对元素都进行初始化。数组本身是引用类型。int[] a = null;//ok的
多维数组
矩形数组rectangular array 代表着n维内存块
使用逗号来分割维度
int[,] matrix = new int[3,3];
GetLength(维度)方法可返回指定维度的长度,维度表示参数,从0开始
交错数组jagged array 元素类型为数组的数组
使用连续的中括号来声明和代表不同的维度
int[][] matrix = new int[3][];
内层维度并没有具体指明,内层维度的数组可以是任意长度
简化数组初始化表达式
char[ ] vowels = new char[ ]{'a','e','i','o','u'};
char[ ] vowels={'a','e','i','o','u'};
推断类型:var vowels = new[ ]{'a','e','i','o','u'};
推断类型:所有的元素必须可隐式转换为某一个类型
var x= new[ ]{1,10000000000};//long类型
边界检查
所有数组的索引都会被运行时检查的。如果使用了不合理的索引,抛出IndexOutOfRangeException。通常边界检查对性能的影响很小,JIT编译器可执行一 些优化,例如在进入循环前预先对所有的索引进行安全检查,避免在迭代中检查。C#还提供了"unsafe"代码,可以绕过边界检查。
变量和参数
一个变量代表一个存储的位置,它的值是可以改变的。变量可以是本地的变量(方法内部的变量),参数(值类型、ref、out),字段(类里的field),数组的元素
Stack和Heap是变量和常量的所在地,生命周期不同
Stack(一块内存)存储本地变量和参数。随着函数的进入和退出,Stack也会随之增大和缩小。
Heap(一块内存),对象所在的地方(引用类型的实例)。当新的对象被创建后,它就会被分配在Heap上,到该对象的一个引用被返回。程序执行时,随着新对象的不断建立,heap会 被慢慢的填满。运行时的gc会周期性的把对象从heap.上面释放出来,所以不会导致内存耗尽。一旦一个对象不再被任何“存活”的东西所引用,那么它就可以被释放了
值类型的实例(和对象的引用)会放在变量声明时所在的内存块里。如果该实例是一个class的字段或数组的元素,那么它就在Heap上(我的理解是,class是引用类型,它的实例是分配在heap上的,而class的字段是实例的一部分,所以也在heap上)
C#里不可以显式删除对象,无引用的对象会逐渐被GC收集
Static字段在Heap上,它们会存活到应用程序域停止
确定赋值Definite Assignment
除非使用unsafe,否则在C#里无法访问末初始化的内存。Definite Assignment的三个含义:本地变量(方法里的变量)在被读取之前必须被赋值;当方法被调用的时候,函数的参数必须被提供(除非是可选参数);其它的变量(字段、数组元素)会被运行时自动初始化
默认值
所有类型的实例都有默认值。预定义类型的默认值就是内存按位归零的结果
通过default关键字来获取任何类型的默认值。decimal d = default(decimal);
自定义值类型(struct)的默认值就是该自定义类型定义的每个字段的默认值。
参数
一个方法可以有多个参数(parameters),参数(形参)(parameters)定义了必须为该方法提供的参数(实参)(arguments)
参数传递的方式
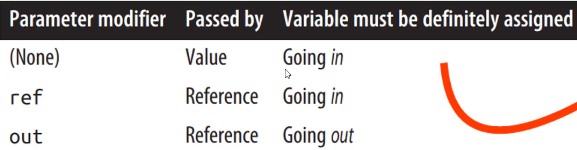
默认情况下,按值传递arguments。当传进方法时把arguments的值复制了一份(使用的是复制的值)
按值传递引用类型的arguments,复制的是引用,不是对象。
想要按引用传递,可以使用ref参数修饰符
无论是引|用类型还是值类型的参数,都可以按值或按引用传递(按引用传递可以理解为直接把原始值所在的地址传递过去,修改的就是原始值)
out和ref差不多,除了:1、进入函数前不需要被赋值。2、离开函数前必须被赋值。通常用来从方法返回多个值。从C#7开始,调用方法时,可以使用out临时声明变量。如Split("Stevie Ray Vaughan", out string a, out string b);变量a、b在方法调用的时候临时声明。当调用的方法有多个out参数时,你不需要其中一些out参数,可以使用下划线“_”来discard(弃用)它们。如Split("Stevie Ray Vaughan", out string a, out _);表示不需要用到第二个out参数
按引用类型进行传递的含义:当你按引用传递arguments的时候,相当于给现有变量的存储位置起了个别名,而不是创建了一个新的存储位置
params修饰符
可以在方法的最后一个参数使用params参数修饰符
可以接受任意数量的该类型的参数(相当于方法参数个数可变)
参数(parameters)类型必须是数组
也可使用数组作为arguments
static int Sum(params int[] ints) { } static void Main() { int total = Sum(1, 2, 3, 4); //inttotal=Sum(new int[]{1,2,3,4}); Console. WriteLine(total); //10 }
可选参数
从C#4.0开始,方法、构造函数、索引器都可以声明可选参数,可选参数需要在声明的时候提供默认值(所以就可以不提供实参了),调用时可以不填写可选的parameters
void Foo(int x= 23) { Console.WriteLine(x); }
Foo();相当于Foo(23);编译器在调用方法时把23写死进去
往public方法里添加可选参数,若该方法被其它Assembly调用,那么两个Assemblies都需要重新编译,就和添加了一个必填参数是一样的
可选参数的默认值必须是常量表达式或拥有无参构造函数(无参才可以直接调用以赋值)的值类型
可选参数不可以使用ref和out
必填参数必须在可选参数前面(方法声明时和方法调用时)(其实很简单,如果可选参数放在前面,就不好判断究竟实参是可选参数还是必填参数)。例外是:params 的参数仍然放在最后边。
命名参数
可以不按位置来区别arguments,使用名称来定位arguments,命名的arguments可以按任意顺序填写
void Foo2(int x, int y) { Console.WriteLine(x + ","+ y); } void Test2() { Foo2(x: 1, y: 2); //1, 2 Foo2(y: 2, x: 1);//1, 2 }
Arguments表达式被计算的顺序和它们在调用地点出现的顺序一致(意思就是先调用先计算,而与形参里的顺序无关)
static void Main() { int a=0; Foo2(y: ++a, x: --a); // 0,1 int b=0; Foo2(x: --b, y: ++b);//-1,0 }
在这个例子中,在两次调用中,虽然x、y的Arguments表达式都没变,但是因为表达式计算的次序不一样,所以最终传给x、y的值是不同的。可见,计算表达式的顺序是采用写在前面的先计算,而不会因为形参里x在前,就先计算x的Arguments表达式
可混合使用按位参数和命名参数,按位参数必须放在命名参数前(就是参数列表的前半部分按照实参出现的顺序对应到形参列表里的形参,参数列表的后半部分采取名称找到实参和形参的对应关系)
void Test2( ) { Foo2(1, y: 2); }
可混合使用可选参数和命名参数
void Bar(int a=0,int b=0,int c=0, int d=0){} void Test2() { Bar(d:3); }
ref Locals
C#7,可以定义一个本地变量,它引用了数组的一个元素或对象的一个字段。
int[] numbers= {0,1,2, 3,4}; ref int numRef= ref numbers[2];
numRef就是对numbers[2]的引用,修改numRef的时候,就是修改numbers[2]这个元素。Ref Local的目标必须是数组的元素,字段,本地变量。不可以是属性。常用于微优化场景,通常与ref returns(可以从方法返回ref local,这就叫做ref return)联合使用
static string X = "Old Value"; static ref string GetX() => ref X; //This method returns a ref static void Main() { ref string xRef = ref GetX(); //Assign result to a ref local xRef = "New Value"; Console.WriteLine(X); //New Value }
var
隐式(类型是推断出来的)强类型(类型是固定的,不可变)本地变量(方法内部使用)。声明和初始化变量通常一步完成,如果编译器能从初始化表达式推断出类型,就可以使用var。会降低代码的可读性
表达式和操作符
表达式其本质就是表示了一个值,最简单的表达式就是常量和变量。表达式可以通过操作符来进行转换和合并。一个操作符需要一个或多个输入操作数来产出新的表达式
操作符有一元、二元、三元,表示操作数的个数。二元操作符采用中缀表示法(操作符放在两个操作数中间),·例如:12*30
Primary Expressions就是表达式,但是它里面包括了使用操作符组成的表达式。例如:Math.Log(1),由两个表达式组成,第一个表达式使用.操作符来执行成员的查找,第二个表达式使用()操作符来实现了方法的调用
void表达式就是没有值的表达式,无法用于构健更复杂的表达式。Console.WriteLine(1)
赋值表达式使用=把另一个表达式结果赋给一个变量。赋值表达式不是void表达式,它有值,就是被赋的值,所以可以与其他表达式进行组合。如y=5*(x=2),a=b=c=d=0
复合赋值操作符就是使用另一个操作符来组合赋值的句法快捷方式,如x*=2相当于x=x*2,X<<=1相当于x=x<<1。事件event是个例外,+=和-=映射到event的add和remove 访问器。
操作符的优先级和结合性
*的优先级比+高
二元操作符(除了赋值,lambda,null合并操作符)是左结合的,也就是从左到右的进行估算。赋值、lambda、null合并和条件操作符是右结合的,从右向左估算
Null的操作符
C#提供了两种操作符,它们可以更容易的处理nul。Null合并操作符和Nul条件操作符
Null合并操作符:??。如果操作数不是null,那么把它给我;否则的话,给我一个默认值(就是??右侧的表达式)。如果左边的表达式非null,那么??右边的表达式就不会被计算。
Null条件操作符(Elvis): ?.,出现在C#6,允许你像 . 操作符那样调用方法或访问成员,当左边的操作数是null的时候,那么整个表达式就是null,而不会抛出NullReferenceException。一旦遇到null,这个操作符就把剩余表达式给短路掉了。x?.y?.z等价于x==null ? null:(x.y==null ? null : x.y.z)。最终的表达式必须可以接受null,可以和Null合并操作符一起使用
语句 Statement
函数由语句组成,这些语句按其出现的文本顺序执行。语句块就是{}之间的一系列语句
声明语句声明一个新的变量,也可使用表达式对该变量进行初始化,声明语句以分号;结束。bool rich=true,famous=false;
本地变量/常量的作用范围是当前的块,同一个块里面(包括里面嵌套的块)不可以声明重名的变量/常量
表达式语句是表达式,同样也是合理的语句。表达式语句要么改变了状态,要么调用了可以改变状态的东西(比如方法、函数)。改变状态其实就是指改变变量的值。表达式语句包括赋值表达式(包括自增和自减表达式)、方法调用表达式(void和非void)、对象实例化表达式
控制程序的走向:选择语句(if,switch)条件操作符(?:)循环语句(while,do.…while,for,foreach)
如果if后边的bool表达式的值为true,那么if语句的内容就会被执行。使用{}增加可读性。if 语句可以有else子句,else子句还可以嵌套if语句
switch语句允许你根据变量可能有的值来选择分支程序,可能比if语句更简洁一些。当指定常量的时候,只能使用内置的整数类型、bool、char、enum和string类型。每个case子句的结尾,必须使用跳转语句来表明下一步往哪里执行:
break(跳到switch语句的结尾)
goto case x(跳转到其它case)
goto default(跳转到default子句)
其它的跳转语句 return,throw,continue,goto label
C#7增加了switch with patterns。object类型允许任何类型的变量。每个case子句指定一个类型,如果变量的类型与该类型一样,那么就匹配成功(就是说,之前是对值进行判断,现在是对类型进行判断)。可以使用when来断言一个case(就是增加一个条件判断)。case子句的顺序是有关系的。可以case null
static void TellMeTheType(object x)//object allows any type. { switch(x) { case bool b when b=true://Fires only when b is true Console.WriteLine("True!"); break; case bool b: Console. WriteLine("False!"); break; } }
注意第2个case包含了第1个case的情况,所以第2个case写在前面会报错。
C#允许一串语句可重复地执行,称为迭代语句,如while,do...while,for,foreach语句。
while后跟着的一个bool表达式值为true的时候,会循环重复执行代码体,这个bool表达式在代码体循环执行之前被检验
do...while和while差不多,只不过bool表达式在代码体执行完之后才被检验
for和while循环差不多,但有特殊的子句用来初始化和迭代变量。for(初始化子句;条件子句;迭代子句){语句或语句块}。初始化子句:在循环开始前执行,用来初始化一个或多个迭代变量。条件子句:bool表达式,为true时,会执行代码体。迭代子句:每次语句块迭代之后执行;通常用来更新迭代变量。无限循环 for(;;)
foreach迭代enumerable对象里的元素,C#里大部分集合类型都是enumerable的
跳转语句有:break、continue、goto、return、throw。跳转语句遵循try语句的可靠性原则,跳转出try块时,在到达跳转目标之前,总会先执行try的finally块。不可以从finally块里面跳转到外边,除非使用throw
break语句可以结束迭代或switch语句的代码体
continue语句会放弃当前迭代中剩余语句的执行,直接从下一次迭代开始
goto语句把执行跳转到另一个label的语句块。当用于swtich语句内时,goto case case常量;(只能用于常量)Label相当于是一个代码块的占位符,放在语句前边,使用冒号:做后缀
static void Main(string[] args) { int i=1; startLoop: if(i≤5) { Console.write(i+""); i++; goto startLoop; } }
return语句会退出方法,并返回一个表达式,该表达式的类型和方法的返回类型一致(方法不是void的)。return语句可以放在方法的任何一个地方,除了finally块里
throw语句抛出异常,表示发生了错误。
命名空间
命名空间是类型的域,类型通常被组织到层次化(每层用点.分开)的命名空间中,使它们更容易查找且避免了冲突。命名空间是类型名称的组成部分。命名空间独立于Assembly(命名空间的名称和程序集的名称并非一样),对成员(类)的可见性也没有影响
namespace 关键字定义了块{}里面类型的命名空间。命名空间中的点表示嵌套命名空间的层次结构。未在任何命名空间里定义的类型被称为驻留在全局名称空间中
namespace Outer.Middle.Inner { class Class1{} class class2{} }
等价于
namespace Outer { namespace Middle { namespace Inner { class class3{} class class4{} } } }
using指令可导入一个命名空公间,允许你不需要类型的全名就可以使用该类型。可以在不同的命名空间中定义相同名称的类型
从C#6开始,你不仅仅可以引入命名空间,还可以引入具体的类型,这就需要使用using static。被引入类型的所有静态成员可被直接使用,无需使用类名。所有可访问的静态成员都会被引入,包括字段、属性、嵌套类型。也用于enum,这样的话它的成员就被引入了。如果多个static引入存在歧义的话,将会发生错误
using static System.Console; class Test2 { static void Main(){ writeLine("Hello");} }
命名的范围
在外层命名空间声明的名称可以在内部的命名空间里直接使用,无需全名。如果想要引用命名空间层次结构下不同分支的类型,可以使用部分名称
namespace MyTradingCompany { namespace Common { class ReportBase{} } namespace ManagementReporting { class SalesReport:Common.ReportBase{} } }
如果同一个类型名同时出现在外层和内层的命名空间里,那么,直接使用类型名的时候,使用的是内层的。
可以重复声明命名空间(不论是在一个文件还是多个文件),只要它们下面没有冲突的类型名就可以
namespace outer.Middle.Inner { class Class1{} } namespace Outer.Middle.Inner { class Class2{} }
可在一个命名空间内嵌套using指令。可以让using的东西的作用范围限制在这个命名空间内
namespace N1 { class Class1{} } namespace N2 { using N1; class Class2:Class1{} } namespace N2 { class Class3:Class1{}//Compile-time error }
为命名空间/类型起别名
引入命名空间之后,可能会导致类型名冲突。可以不引入完整的命名空间,只引入你需要的那个类型,然后给这个类型起一个别名
using PropertyInfo2 = System.Reflection.PropertyInfo; class Program1 { PropertyInfo2 p;}
using R = System.Reflection;//给命名空间起别名 class Program { R.PropertyInfo p; }
命名空间的高级特性
Extern别名允许你的程序引用两个全名相同的类型名,通常这两个类型来自不同的Assembly
//csc /r:W1=Widgets1.dll /r:W2=Widgets2.dll application.cs //相当于给dll起了别名 extern alias W1; extern alias W2; class Test static void Main() { W1.Widgets.Widget W1 = new W1.Widgets.Widget(); W2.Widgets.Widget W2 = new W2.Widgets.Widget(); }
命名空间别名限定符
内层命名空间的类型名会把外层命名空间下的类型名隐藏,有时即使使用全名也无法解决冲突。解决办法:使用global命名空间::或extern alias
namespace N { class A { public class B { } //Nested type static void Main() { new global::A.B(); }//global::A.B指命名空间A下的class B } } namespace A { class B{} }
NULL
可空值类型是System.Nullable<T>这个struct的实例。可空值类型除了可以正确的表示其底层数据类型(即T)的范围,还可以表示null。Nullable<int>简写为int?。Nullable<T>的常用属性和方法
HasValue //null:false;否则:true
Value //底层值类型的值
GetValueOrDefault() //底层值类型的值或该类型的默认值
GetValueOrDefault(默认值)//底层值类型的值或指定的默认值
Nullable<T>比较
都有值则按照正常的比较来进行
一个为null,一个有值,则不等
都为null则相等
Nullable<T>转换
T -> Nullable<T>隐式转换
Nullable<T> -> T显式转换(因为Nullable<T>的取值范围大于T )
Null和空,空白string
string name ="Nick";
string name = null;
string name ="";
string name =" “
判断Null和空,空白string
if(name == null){..}
if(string.isNullOrEmpty(name)){..}
if(string.isNullOrWhiteSpace(name)){...}//空字符串也是空白字符串,但是空白字符串并不是空字符串
检查Null的操作符
?:条件操作符
??Null合并操作符
?.Null条件操作符
string[] arr = null; arr?[0]. Trim();//不会报空引用异常,?[是针对索引表示法的null条件操作符
创建类型
class-字段和方法
class是最常见的一种引用类型。
字段FIELD是Class或Struct的成员,它是一个变量。
readonly修饰符防止字段在构造之后被改变。readonly字段只能在声明的时候被赋值,或在构造函数里被赋值
字段可以可选初始化,未初始化的字段有一个默认值。字段的初始化在构造函数之前运行
可以同时声明多个字段
static readonly int legs = 8, eyes = 2;
方法通常有一些语句,会执行某个动作
方法签名:方法名、参数类型(含顺序,但与参数名称和返回类型无关)。参数是按值传递的还是按引用传递的,也是方法签名的一部分。类型内方法的签名必须唯一
EXPRESSION-BODIED方法
int Foo(intx){return x*2;}可以简写为int Foo (int x) =>x*2;只适用于单表达式的方法
方法的重载OVERLOAD
类型里的方法可以进行重载(允许多个同名的方法同时存在),只要这些方法的签名不同就行(也就是说参数类型或者顺序不同)
void Foo (int x) {...} void Foo (ref int x) {...}//OK so far void Foo (out int x) {...}//Compile-time error
本地方法(C#7)
void WriteCubes() { Console.WriteLine (Cube (3)); Console.WriteLine (Cube (4)); Console.WriteLine (Cube (5)); int Cube(int value) => value *value * value; }
Cube方法的作用范围在WriteCubes内部,Cube方法可以访问WriteCubes方法的参数和本地变量。本地方法不可以使用static修饰符(外部方法是static那么本地方法也是static,所以不写)
构造函数与析构函数
构造函数运行class或struct的初始化代码。和方法差不多,有2点不同,方法名和Class类型一致,返回类型也和类型一致,并且返回类型就省略不写了。C#7,允许单语句的构造函数写成expression-bodied成员的形式。构造函数可以不是public的(不写访问修饰符就是private)。如果有一个私有的构造函数,那么C#编译器就不会自动生成一个无参的public构造函数,那么就无法从外部访问构造函数创建实例。这个私有构造函数只能被类内部方法访问,如果要实际访问,还得是static的,不然没有实例,非static方法根本就不存在,形成死循环。
构造函数重载
class和struct可以重载构造函数,调用重载构造函数时使用this
using System; public class Wine { public decimal Price; public int Year ; public Wine (decimal price) { Price = price; } public Wine (decimal price, int year) : this(price){ Year = year } ; }
当同一个类型下的构造函数A调用构造函数B的时候,B先执行。
可以把表达式传递给另一个构造函数,但表达式本身不能使用this引用,因为这时候对象还没有被初始化,所以任何方法的调用都会失败
public wine(decimal price, DateTime date) : this(price, this.GetYear())//this. GetYear()报错 { Date = date; }
public int GetYear() { return 1988; }
无参构造函数
对于class,如果你没有定义任何构造函数的话,那么C#编译器会自动生成一个无参的public构造函数。但是如果你定义了构造函数,那么这个无参的构造函数就不会被生成了
构造函数和字段的初始化顺序
字段的初始化发生在构造函数执行之前,字段按照声明的先后顺序进行初始化
DECONSTRUCTOR (C#7 )
C#7引入了deconstructor模式,作用基本和构造函数相反,它会把字段反赋给一堆变量。方法名必须是Deconstruct,有一个或多个out参数。Deconstructor可以被重载。
class Rectangle { public readonly float width, Height; public Rectangle(float width, float height) { Width = width; Height = height; } public void Deconstruct(out float width, out float height) { width = Width; height = Height; } } class Test { public static void Main(string[] args) { var rect = new Rectangle(3, 4); (float width, float height) = rect;//Deconstruction //float width, height; //rect.Deconstruct(out width, out height); //rect.Deconstruct(out var width, out var height); Console.WriteLine(width +""+ height); //3 4 } }
Deconstruct这个方法可以是扩展方法
class Rectangle { public readonly float width, Height; public Rectangle(float width, float height) { Width = width; Height = height; } } public static class Extensions { public static void Deconstruct(this Rectangle rect, out float width, out float height) { width = rect.Width; height = rect.Height; } } class Test { public static void Main(string[] args) { var rect = new Rectangle(3, 4); //Extensions.Deconstruct(rect, out var width, out var height); rect.Deconstruct(out var width, out var height); } }
扩展方法要求static类和static方法,第1个参数是要扩展的类型,需要this关键字。我的理解是,扩展方法,相当于对被扩展类扩展了一个方法,可以用被扩展类直接调用,就像它本身原来有这个方法一样(当然我不明白为什么不直接修改代码,而采用这样的方式去扩展类)
class-对象初始化、this、属性、索引器
对象任何可访问的字段/属性在构建之后,可通过对象初始化器直接为其设定值
public class Bunny { public string Name; public bool LikesCarrots; public bool LikesHumans; public Bunny(){} public Bunny(string n){ Name = n;} } Bunny b1 = new Bunny { Name="Bo", LikesCarrots=true, LikesHumans=false }; Bunny b2 = new Bunny ("Bo") { LikesCarrots=true, LikesHumans=false };
编译器生成的代码
Bunny temp1 = new Bunny(); temp1.Name = "Bo"; temp1.LikesCarrots = true; temp1.LikesHumans = false; Bunny b1 = temp1; Bunny temp2 = new Bunny ("Bo"); temp2.LikesCarrots = true; temp2.LikesHumans = false; Bunny b2 = temp2;
临时变量可以保证:如果在初始化的过程中出现了异常,那么不会以一个初始化到一半的对象来结尾。
this引用指的是实例的本身。this引用可以让你把字段与本地变量或参数区分开。只有class/struct的非静态成员才可以使用this(因为还没有实例化)
public class Test { string name; public Test (string name) { this.name = name;} }
从外边来看,属性和字段很像。但从内部看,属性含有逻辑,就像方法一样。属性的声明和字段的声明很像,但多了一一个get set块。get/set代表属性的访问器。get访问器会在属性被读取的时候运行,必须返回一个该属性类型的值。set访问器会在属性被赋值的时候运行,有一个隐式的该类型的参数value,通常你会把value赋给一个私有字段(value就是赋值给属性的值)。尽管属性的访问方式与字段的访问方式相同,但不同之处在于,属性赋予了实现者对获取和赋值的完全控制权。这种控制允许实现者选择任意所需的内部表示,不向属性的使用者公开其内部实现细节。如果属性只有get访问器,那么它是只读的。如果只有set访问器,那么它就是只写的(很少这样用)。属性通常拥有一个专用的“幕后”字段(backing field),这个幕后字段用来存储数据
从C#6开始,你可以使用Expression-bodied形式来表示只读属性。C#7,允许set访问器也可以使用该形式
public decimal Worth { get => currentPrice * sharesOwned; set => sharesOwned = value / currentPrice; }
属性最常见的一种实践就是:getter和setter只是对private field进行简单直接的读写。自动属性声明就告诉编译器来提供这种实现
public class Stock { ... public decimal CurrentPrice{get;set;} }
编译器会自动生成一个私有的幕后字段,其名称不可引用(由编译器生成)。set访问器也可以是private或protected。从C#6开始,你可以为自动属性添加属性初始化器
public decimal CurrentPrice{get;set;}= 123;
只读的自动属性也可以使用(只读自动属性也可以在构造函数里被赋值)
public int Maximum{get;}= 999;
get和set访问器可以拥有不同的访问级别。典型用法:public get,internal/private set。如果不写就是属性的访问级别public
C#的属性访问器内部会编译成get__XXX和set__XXX
public decimal get_CurrentPrice{...} public void set_CurrentPrice(decinal value){..}
简单的非virtual属性访问器会被]IT编译器进行内联(inline)操作,这会消除访问属性与访问字段之间的性能差异。内联是一种优化技术,它会把方法调用换成直接使用方法体。
索引器
索引器提供了一种可以访问封装了列表值或字典值的class/struct的元素的一种自然的语法。语法很像使用数组时用的语法,但是这里的索引参数可以是任何类型的(比如字符串)
string s ="hello"; Console.WriteLine(s[0]);//'h' Console.WriteLine(s[3]);//'l'
索引器和属性拥有同样的修饰符,可以按照下列方式使用null条件操作符:
string s = null; Console.WriteLine(s?[0]);//s为null不会抛出异常,而是返回null
实现索引器需要定义一个this属性,并通过中括号指定参数。
class Sentence { string[] words = "The quick brown fox".Split(); public string this[ int wordNum]//indexer { get { return words[ wordNun];} set { words[ wordNum] = value;} } } //使用索引器 Sentence s =new Sentence() ; Console.WriteLine (s[3]);//fox s[3] = "kangaroo"; Console.WriteLine (s[3]);//kangaroo
一个类型可以声明多个索引器,它们的参数类型可以不同。一个索引器可以有多个参数
public string this[int arg1,string arg2] { get{...}set{...} }
如果不写set访问器,那么这个索引器就是只读的。索引器在内部会编译成get_ltem和set_ltem方法
public string get_Item(int wordNum){...} public void set_Item(int wordNum,string value){...}
class-常量、静态构造函数和类、终结器、局部类和方法、nameof
常量是一个值不可以改变的静态字段,在编泽时值就已经定下来了。使用const关键字声明,声明的同时必须使用具体的值来对其初始化。任何使用常量的地方,编译器都会把这个常量替换为它的值。常量的类型可以是内置的数值类型、bool、char、string或enum。方法里可以有本地的常量
常量比静态只读字段(static readonly)更严格:1、可使用的类型常量更少。2、字段初始化的语义上,常量得进行初始化。常量是在编译时进行值的估算的
当值有可能改变,并且需要暴露给其它Assembly的时候,静态只读字段是相对较好的选择
public const decimal ProgramVersion = 2.3;
如果Y Assembly引用了X Assembly并且使用了这个常量,那么在编译的时候,2.3这个值就会被固化于Y Assembly里。这意味着,如果后来X重编译了,这个常量变成 了2.4,如果Y不重新编译的话,Y将仍然使用2.3这个值(常量是编译时被替换成值的。X的常量值变了,和Y里的固定数值2.3并没有联系),直到Y被重新编译,它的值才会变成2.4。静态只读字段就会避免这个问题的发生
静态构造函数
静态构造函数,每个类型执行一次。非静态构造函数,每个实例执行一次。一个类型只能定义一个静态构造函数。必须无参,方法名与类型一致
class Test { static Test(){Console.WriteLine("Type Initialized");} }
在类型使用之前的一瞬间,编译器会自动调用类型的静态构造函数:实例化一个类型或访问类型的一个静态成员(这两种情况下会调用静态构造函数)。如果静态构造函数抛出了未处理的异常,那么这个类型在该程序的剩余生命周期内将无法使用了
只允许使用unsafe和extern修饰符
静态字段的初始化器在静态构造函数被调用之前的一瞬间运行。如果类型没有静态构造函数,那么静态字段初始化器在类型被使用之前的一.瞬间执行,或者更早,在运行时突发奇想的时候执行。静态字段的初始化顺序与它们的声明顺序一致
class Foo { public static int X = Y;//0 public static int Y = 3;//3 }
静态类
类也可以是静态的,其成员必须全是静态的,不可以有子类。例如System.Console、System.Math
FINALIZER终结器
Finalizer是class专有的一种方法,在GC回收未引用对象的内存之前运行,其实就是对object的Finalize()方法重写的一种语法
class Class1 { ~Class1() { ... } }
编译生成的:
protected override void Finalize() { ... base.Finalize(); }
C#7可以这样写:~Class1()=>Console.Writeline("Finalizing");
PARTIAL[ˈpɑːʃl] TYPE局部类型
允许一个类型的定义分布在多个地方(文件)。典型应用:一个类的一部分是自动生成的,另一部分需要手动写代码。每个分布的类都必须使用partial来声明,每个分布类的成员不能冲突,不能有同样参数的构造函数。各分布类完全靠编译器来进行解析:每个分布类在编译时必须可用,且在同一个Assembly里。如果有父类,可以在一个或多个分布类上指明,但如果在多个分布类上指明,必须一致。每个分布类可以独立实现不同的接口。编译器无法保证各分布类的字段的初始化顺序
partial类型可以有partial method。自动生成的分布类里可以有partial method,通常作为“钩子”使用,在另一部分的partial method里,我们可以对这个方法进行自定义。
partial class PaymentForm //In auto-generated file { ... partial void ValidatePayment (decimal amount); } partial class PaymentForm //In hand-authored file { ... partial void ValidatePayment (decinal amount) { if (amount > 100) ... } }
partial method由两部分组成:定义和实现。定义部分通常是生成的。实现部分通常是手动编写的。如果partial method只有定义,没有实现,那么编译的时候该方法定义就没有了,调用该方法的代码也没有了。这就允许自动生成的代码可以自由地提供钩子,不用担心代码膨胀。partial method必须是void,并且隐式private的
NAMEOF操作符 C#6
nameof操作符会返回任何符号(类型、成员、变量)的名字(string),利于重构
int count = 123; string name = nameof(count); //name is"count" string name = nameof(StringBuilder.Length); //This evaluates to "Length”.
继承
一个类可以继承另一个类,从而对原有类进行扩展和自定义。继承的类可以重用被继承类的功能。可以叫做子类和父类。C#里,一个类只能继承于一个类,但是这个类却可以被多个类继承(树形结构)
引用是多态的,类型为x的变量可以引用其子类的对象,因为子类具有父类的全部功能特性,反过来则不行。
引用转换:创建了一个新的引用,它也指向同一个对象。一个对象的引用可以隐式转换到其父类的引用(向上转换)。想转换到子类的引用则需要显式转换(向下转换)。(注意对比,数值类型的转换,我们考虑的是被转换的数有没有损失精度。而引用类型的转换,我们考虑的是转换而成的对象有没有损失精度。比如父类转换成子类,那么可能缺少了子类的一些成员,那么这个子类的实例是有损失的,是不行的)向下转换和向上转换一样,只涉及到引用,底层的对象不会受影响。向下转换需要显式转换,因为可能会失败。如果向下转换失败,那么会抛出InvalidCastException(属于运行时类型检查)
//House、Stock都是Asset的子类 House h = new House(); Asset a = h; // Upcast always succeeds Stock s = (Stock)a; // Downcast fails: a is not a Stock
as操作符会执行向下转换、如果转换失败,不会抛出异常,值会变为null
Asset a = new Asset(); Stock s = a as Stock;// s is null; no exception thrown
is操作符会检验引用的转换是否成功。换句话说,判断对象是否派生于某个类(或者实现了某个接口)通常用于向下转换前的验证:
if(a is Stock) Console.WriteLine(((Stock)a).SharesOwned);
如果拆箱转换可以成功的话,那么使用is操作符的结果会是true
C#7里,在使用is操作符的时候,可以引入一个变量
if (a is Stock s) Console.WriteLine (s.SharesOwned); //相当于 stock s; if (a is Stock) { s = (Stock) a; Console.WriteLine (s.SharesOwned): }
引入的变量可以立即“消费”
if (a is Stock s && s.SharesOwned > 100000) Console.WriteLine ("Wealthy");
VIRTUAL[ˈvɜːtʃuəl]函数成员
父类标记为virtual的函数可以被子类重写,包括方法、属性、索引器、事件。使用override修饰符,子类可以重写父类的函数。virtual方法和重写方法的签名、返回类型、可访问程度必须是一样的。重写方法里使用base关键字可以调用父类的实现
在构造函数里调用virtual方法可能比较危险,因为编写子类的开发人员可能不知道他们在重写方法的时候,面对的是一个未完全初始化的对象。换句话说,重写的方法可能会访问[依赖于还未被构造函数初始化的字段的]属性或方法
抽象类和抽象成员
使用abstract声明的类是抽象类,抽象类可以定义抽象成员。抽象成员和virtual成员很像,但是不提供具体的实现。子类必须提供实现,除非子类也是抽象的。抽象类不可以被实例化,只有其具体的子类才可以实例化
public abstract class Asset { //Note empty implementation public abstract decimal NetValue (get; } } public class stock : Asset { public long SharesOwned; public decimal currentPrice; //Override like a virtual method. public override decimal NetValue => CurrentPrice * SharesOwned; }
隐藏被继承的成员
父类和子类可以定义相同的成员:
public class A{public int Counter = 1;} public class B:A{public int Counter =2;}
class B中的Counter字段就隐藏了A里面的Counter字段(通常是偶然发生的)。例如子类添加某个字段之后,父类也添加了相同的一个字段。编译器会发出警告。
按照如下规则进行解析:编译时对A的引用会绑定到A.Counter。编译时对B的引用会绑定到B.Counter
A a = new A(); System.Console.writeLine(a. Counter); //1 B b = new B(); System.Console.WriteLine(b. Counter); //2 A x = new B(); System.Console.writeLine(x. Counter); //1
如果想故意隐藏父类的成员,可以在子类的成员前面加上new修饰符。这里的new修饰符仅仅会抑制编译器的警告而已
public class A {public int Counter = 1;} public class B: A { public new int Counter = 2;}
NEW VS OVERRIDE
public class Baseclass { public virtual void Foo() { Console. WriteLine ("Baseclass.Foo"); } } } public class Overrider: BaseClass { public override void Foo() { Console.WriteLine ("Overrider.Foo"); } } public class Hider : Baseclass { public new void Foo() { Console.Writeline ("Hider.Foo"); } } Overrider over = new Overrider(); Baseclass b1 = over; over.Foo(); //Overrider. Foo1 b1.Foo(); //Overrider. Foo1 Hider h = new Hider(); Baseclass b2 = h; h.Foo(); //Hider.Foo b2.Foo(); //BaseClass.Foo
注:override会在运行时判断对象的实际类型,从而调用对应的方法。而new完全根据引用变量的类型调用相应的方法
SEALED
针对重写的成员(其他成员不可使用),可以使用sealed关键字把它“密封”起来,防止它被其子类重写
public sealed override decimal Liability{get{return Mortgage;}}
也可以sealed类本身,就隐式地sealed所有的virtual函数了
BASE关键字
base和this略像,base主要用于:1、从子类访问父类里被重写的函数。2、调用父类的构造函数
public class House:Asset { public override decimal Liability => base.Liability + Mortgage; }
这种写法可保证,访问的一定是Asset的Liability属性,无论该属性是被重写还是被隐藏了
构造函数和继承
子类必须声明自己的构造函数。子类必须重新定义它想要暴露的构造函数。从子类可访问父类的构造函数,但不是自动继承的(如果子类不写构造函数,那么编译器会自动生成一个公有的无参构造函数,不要以为会从父类继承构造函数)。调用父类的构造函数需要使用base关键字,父类的构造函数肯定会先执行。
如果子类的构造函数里没有使用base关键宁,那么父类的无参构造函数会被隐式调用。如果父类没有无参构造函数,那么子类就必须在构造函数里使用base关键字(反正一定要调用父类的构造函数对父类成员进行初始化)
public class BaseClass { public int x; public Baseclass(){x = 1;} } public class Subclass : BaseClass { public subclass(){Console.WriteLine(x);} //1,先调用父类构造函数 }
构造函数和字段初始化顺序
对象被实例化时,初始化动作按照如下顺序进行:从子类到父类,字段被初始化,父类构造函数的参数值被算出。从父类到子类,构造函数体被执行(先初始化字段再执行构造函数,先执行父类构造函数,再执行子类构造函数)
public class B { int x = 1; //Executes 3rd public B (int x) { ... // Executes 4th } } public class D: B { int y = 1; //Executes 1st public D (int x) : base (x+1) // Executes 2nd { ... // Executes 5th } }
重载和解析
static void Foo (Asset a) {} static void Foo (Hguse h) {} //重载方法被调用时,更具体的类型拥有更高的优先级 House h = new House(...); Foo(h); //calls Foo(House) //调用哪个重载方法是在编译时就确定下来的 Asset a = new House(...); Foo(a); // calls Foo(Asset)
object型
object(System.Object)是所有类型的终极父类。所有类型都可以向上转换为object.。object是引用类型,但值类型可以转化为object,反之亦然。(类型统一)在值类型和object之间转化的时候,CLR必须执行一些特殊的工作,以弥合值类型和引用类型之间语义上的差异,这个过程就叫做装箱和拆箱。
装箱就是把值类型的实例转化为引用类型实例的动作。目标引用类型可以是object,也可以是某个接口。拆箱正好相反,把那个对象转化为原来的值类型。拆箱需要显式的转换,运行时会检查这个值类型和object对象的真实类型是否匹配,如果不匹配就抛出InvalidCastException
object obj =9; //9 is inferred to be of type int long x = (long) obj; //InvalidCastException object obj =9; long x= (int) obj; object obj =3.5; //3.5 is inferred to be of type double int x= (int) (double) obj; //x is now 3
装箱对于类型统一是非常重要的,但是系统不够完美,数组和泛型只支持引用转换,不支持装箱
object[] a1 = new string[3]; //Legal object[] a2 = new int[3]; //Error
装箱会把值类型的实例复制到一个新的对象。拆箱会把这个对象的内容再复制给一个值类型的实例
int i = 3; object boxed = i; i = 5; Console.WriteLine(boxed);//3
静态和运行时类型检查
C#的程序既会做静态的类型检查(编译时),也会做运行时的类型检查(由CLR执行)。静念检查:不运行程序的情况下,让编译器保证你程序的正确性。运行时的类型检查由CLR执行,发生在向下的引用转换或拆箱的时候。运行时检查之所以可行是因为:每个在heap上的对象内部都存储了一个类型token。这个token可以通过调用object的GetType()方法米获取
GETTYPE方法与TYPEOF操作符
所有C#的类型在运行时都是以System.Type的实例来展现的。两种方式可以获得System.Type对象:在实例上调用GetType()方法在类型名上使用typeof操作符。GetType是在运行时被算出的,typeof是在编译时被算出(静态)(当涉及到泛型类型参数时,它是由JIT编译器来解析的)System.Type的属性有:类型的名称,Assembly,基类等等
public class Point { public int x, Y; } Point p = new Point(); Console.WriteLine(p.GetType().Name); //Point Console.WriteLine(typeof(Point).Name); //Point Console.WriteLine(p.GetType() == typeof(Point)); //True Console.WriteLine(p.X.GetType().Name); //Int32 Console.WriteLine(p.Y.GetType().FullName); //System.Int32
TOSTRING方法
ToString()方法会返回一个类型实例的默认文本表示,所有的内置类型都重写了该方法。可以在自定义的类型上重写ToString()方法。如果你不重写该方法,那就会返回该类型的名称
当你调用一个被重写的object成员的时候,例如在值类型上直接调用ToString0方法,这时候就不会发生装箱操作。但是如果你进行了转换,那么装箱操作就会发生
int x = 1; string s1 = x.Tostring(); //Calling on nonboxed value object box =x; string s2 = box.Tostring(); //Calling on boxed value,使用的是装箱后的值
DBJECT 的成员列表
public class object { public object(); public extern Type GetType(); public virtual bool Equals (object obj); public static bool Equals (object objA, object objB); public static bool ReferenceEquals (object objA, object objB); public virtual int GetHashCode(); public virtual string Tostring(); protected virtual void Finalize(); protected extern object Memberwiseclone(); }
struct和访问修饰符
struct和class差不多,但是有一些不同:struct是值类型,class是引用类型。struct不支持继承(除了隐式的继承了object,具休点就是继承了System.ValueType)
class能有的成员,struct也可以有,但是以下几个不行:无参构造函数(实际上有,但不可重写)、字段初始化器(不可在声明字段的同时初始化)、终结器(析构函数)、virtul或protected成员(因为不支持继承,这两种没有意义)
struct有一个无参的构造函数,但是你不能对其进行重写。它会对字段进行按位归零操作。当你定义struct构造函数的时候,必须显式的为每个字段赋值。不可以有字段初始化器。
public struct Point { int x, y; public Point(int x, int y){this.x =x;this.y =y;} } ... Point p1 = new Point(); //p1.x and p1.y will be 0 Point p2 = new Point(1, 1);//p1.x and p1.y will be 1
访问修饰符
public,完全可访问。enum和interface的成员默认都是这个级别
internal,当前assembly或朋友assembly可访问,非嵌套类型的默认访问级别。
private,本类可访问。class和istruct的成员的默认访问级别。
protected,本类或其子类可以访问。
protected internal,联合(并的关系,不是与的关系)了protected和internal的访问级别。
class Class1{} //Class1 is internal (default) class ClassA { int x;} // x is private (default)
类型的访问级别会限制成员的访问级别
class C { public void Foo() {}}
class C默认是internal访问级别,小于内部方法的public访问级别,所以内部方法的实际访问级别是internal。
当重写父类的函数时,重写后的函数和被重写的函数的访问级别必须一致。有一个例外:当在其它Assembly重写protected internal的方法时,写后的方法必须是protected
朋友ASSEMBLY
通过添加System.Runtime.CompilerServices.InternalsVisibleTo这个Assembly的属性,并指定朋友Assembly的名字,就可以把internal的成员暴露给朋友Assembly。
[assembly: InternalsvisibleTo("Friend")]
如果朋友AssemblyStrong name,那么就必须指定其完整的160字节的public key
[assembly: InternalsvisibleTo("StrongFriend, Publickey=9024f000048c...")]
接口简介
接口与class类似,但是它只为其成员提供了规格,而没有提供具体的实现。接口的成员都是隐式抽象的。一个class或若struct可以实现多个接口。接口的成员都是隐式public的,不可以声明访问修饰符。实现接口就是对它的所有成员进行public的实现
可以隐式地把一个对象转化成它实现的接口。一个internal的class(其他Assembly是不可访问的),可以通过把它的实例转化成IEnumerator接口来公共地访问它的成员。
按口可以继承其它接口,会继承其它接口的所有成员
实现多个接口的时候可能会造成成员签名的冲突。通过显式实现接口成员可以解决这个问题。
interface I1{void Foo();} interface I2{int Foo();} public class Widget: I1, I2 { public void Foo() { Console.WriteLine ("Widget's implementation of I1.Foo"); } int I2.Foo() { Console.WriteLine ("Widget's implementation of I2.Foo"); return 42; } }
想要调用相应实现的接口方法,只能把其实例转化成相应的接口才行:
widget w = new widget(); w.Foo(); //Widget's implementation of I1.Foo ((I1)w).Foo(); //Widget's implementation of I1.Foo ((I2)w).Foo(); //Widget's implementation of I2.Foo
另一个显式实现接口成员的理由是故意隐藏那些对于类型来说不常用的成员(要调用I2.Foo需要将实例显式转换成相应的接口)
VIRTUAL的实现接口成员
隐式实现的接口成员默认是sealed的。如果想要进行重写的话,必须在基类中把成员标记为virtual或者abstract
public interface IUndoable { void Undo(); } public class TextBox: IUndoable { public virtual void Undo() => Console.WriteLine ("TextBox.Undo"); } public class RichTextBox:TextBox { public override void Undo() => Console.WriteLine ("RichTextBox.Undo"); } RichTextBox r = new RichTextBox(); r.Undo(); //RichTextBox.Undo ((IUndoable)r).Undo(); //RichTextBox.Undo ((TextBox)r).Undo(); //RichTextBox.Undo
原来写了实现的也可以用virtual关键字修饰。无论是转化为基类还是转化为接口来调用接口的成员,调用的都是子类的实现。因为使用了override 关键字,所以RichTextBox实例只有一个自己的Undo方法,父类的内覆盖掉,不存在了。这个实例即使用TextBox或IUndoable类型的变量来引用,对Undo方法的调用仍然是调用RichTextBox的Undo方法。
public interface IUndoable { void Undo(); } public class TextBox: IUndoable { public void Undo() => Console.WriteLine ("TextBox.Undo"); } public class RichTextBox:TextBox { public void Undo() => Console.WriteLine ("RichTextBox.Undo"); }
如果不使用virtual和override 关键字,那么子类仅仅只是隐藏了父类的方法,其实RichTextBox类型实例还是存在两个Undo()方法的。如果使用TextBox类型变量引用RichTextBox类型实例,调用Undo执行的是TextBox类型的Undo方法。如果使用IUndoable类型变量引用RichTextBox类型实例,调用Undo执行的是TextBox类型的Undo。可以理解为,只有TextBox类型实现了接口成员Undo方法。
显式实现(就是指明接口名和成员的方式)的接口成员不可以被标记为virtual,也不可以通过寻常的方式来重写,但是可以对其进行重新实现。
public interface IUndoable { void Undo(); } public class TextBox: IUndoable { public void Undo() => Console.WriteLine ("TextBox.Undo"); } public class RichTextBox:TextBox,IUndoable { public void Undo() => Console.WriteLine ("RichTextBox.Undo"); } RichTextBox r = new RichTextBox(); r.Undo(); //RichTextBox.Undo ((IUndoable)r).Undo(); //RichTextBox.Undo,因为RichTextBox也继承接口并实现其Undo方法 ((TextBox)r).Undo(); //TextBox.Undo
说明重新实现接口这种劫持只对转化为接口后的调用起作用,对转化为基类后的调用不起作用。重新实现适用于重写显式实现的接口成员(隐式实现可以直接用virtual和override )。即使是显式实现的接口,按口的重新实现也可能有一些问题:1、子类无法调用基类的方法。2、基类的开发人员没有预见到方法会被重新实现,并且可能不允许潜在的后果
接口与装箱
把struct转化为接口会导致装箱(接口是引用类型)。调用struct上隐式实现的成员不会导致装箱(不需要通过接口实例去调用)
interface I { void Foo();} struct s : I { public void Foo(){}}
S s = new S(); s. Foo(); //No boxing I i=s; //Box occurs when casting to interface. i.Foo();
枚举简介
枚举是一个特殊的值类型,它可以让你指定一组命名的数值常量(为了增强可读性)。
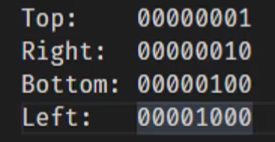
public enum BorderSide{Left,Right,Top,Bottom}
每个枚举都对应一个底层的整形数值(Enum.GetUnderlyingType())。默认是int类型,会按照枚举成员的声明顺序自动赋值.0,1,2….
也可以指定其他的类型作为枚举的整数类型,例如byte:
public enum Borderside:byte{Left,Right,Top,Bottom}
也可以单独指定枚举成员对应的整数值
public enum BorderSide:byte{Left=1,Right=2,Top=10,Bottom=11}
也可以只指定其中某些成员的数值,未被赋值的成员将接着它前面已赋值成员的值递增
枚举可以显式地和其底层的数值相互转换
int i =(int)BorderSide.Left; BorderSide side =(BorderSide)i; bool leftOrRight =(int)side <= 2;
在枚举表达式里,0数值会被编译器特殊对待,它不需要显式的转换:
BorderSide b = 0; if(b == 0) ...
因为枚举的第一个成员通常被当作“默认值”,它的值默认就是0。组合枚举里,0表示没有标志(flags)
FLAGS ENUM
可以对枚举的成员进行组合。为了避免歧义,枚举成员的需要显式赋值。典型的就是使用2的乘幂
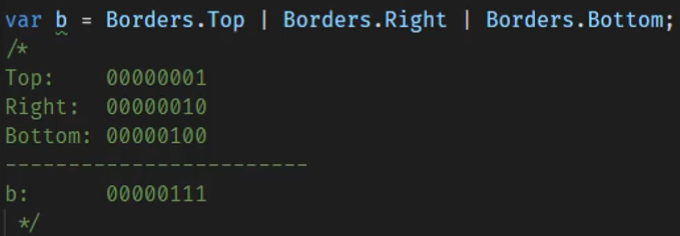
[Flags] public enum Bordersides{None=0,Left=1,Right=2,Top=4,Bottom=8}
flags enum,可以使用位操作符,例如|和&
BorderSides leftRight = BorderSides.Left | BorderSides. Right; string formatted = LeftRight. ToString(); //"Left, Right" if((leftRight & BorderSides.Left) !=0) Console.WriteLine ("Includes Left"); //Includes Left
原理:
因为使用2的乘幂,保证了同一列只有一个值为1
|按位操作,只要有1就为1
&按位操作,都为1才为1
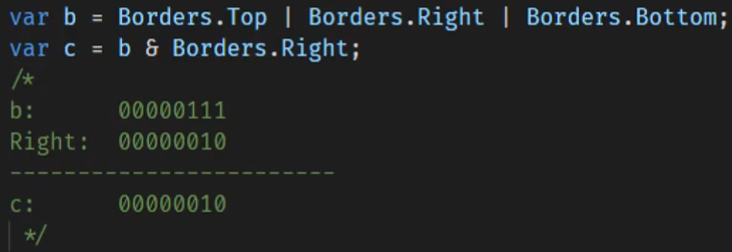
按约定,如果枚举成员可组合的话,flags属性就应该应用在枚举类型上。如果声明了这样的枚举却没有使用flags属性,你仍然可以组合枚举的成员,但是调用校举实例的ToString0方法时,输出的将是一个数值而不是一组名称(也就是加了flags特性之后,数值和名称之间建立起了对应关系)。按约定,可组合枚举的名称(指类型名称)应该是复数的。
在声明可组合枚举的时候,可以直按使用组合的枚举成员作为成员:
[Flags] public enum BorderSides { None=0, Left=1, Right=2, Top=4, Bottom=8, LeftRight = Left | Right, TopBotton = Top | Bottom, ALL= LeftRight | TopBottom }
枚举支持的操作符
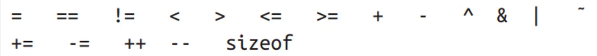
其中按位的、比较的、算术的操作符返同的都是处理底层值后得到的结果。加法操作符只允许一个枚举和一个整形数值相加,两个枚举相加是不可以的
类型安全的问题
public enum BorderSide { Left, Right, Top, Bottom } BorderSide b = (BorderSide)12345; Console.WriteLine(b); //12345 BorderSide b = BorderSide.Bottom; b++; //No errors
检查枚举值的合理性:Enum.lsDefined()静态方法。(检查枚举有没有定义对应数值的成员)
BorderSide side = (BorderSide)12345; Console.WriteLine(Enum.IsDefined(typeof(BorderSide), side));//False
什么是嵌套类型
嵌套类型就是声明在另一个类型(封闭类型)作用范围内的类型
public class TopLevel { public class Nested {} //Nested class public enüm Color{ Red, Blue, Tan } //Nested enum }
嵌套类型可访问封闭类型的私有成员(需要用到封闭类型的名称),以及任何封闭类型能访问的东西。可以使用所有的访问修饰符来声明,不仅仅是public和internal。嵌套类型的默认访问级别是private而不是internal。从封闭类型外边访问嵌套类型需要使用到封闭类型的名称
泛型简介
跨类型可复用的代码:继承和泛型。继承→基类。泛型→带有“(类型)占位符”的"模板”
泛型会声明类型参数-泛型的消费者需要提供类型参数(argument)来把占位符类型填充上。
public class Stack<T> { int position; T[] data = new T[100]; public void Push (T obj)=> data[position++] = obj; public T Pop()=> data[--position]; } var stack = new Stack<int>(); stack.Push (5); stack.Push (10); int x = stack.Pop(); //x is 10 int y = stack.Pop(); //y is 5
stack是Stack<int>类型的实例。
Stack<T> Open Type(开放类型)。Stack<int> Closed Type(封闭类型)。在运行时,所有的泛型类型实例都是封闭的(占位符类型已被填充了)
为什么泛型会出现?
如果不可以使用泛型,那么怎么解决泛型所解决的问题?第一种方法是为每一种类型都写一个类,会导致代码冗余。第二种方法是使用object类型,但是会出现向下转换,无法在编译时检测类型安全
public class ObjectStack { int position; object[] data = new object[10]; public void Push(object obj) => data[position++] = obj; public object Pop()=> data[--position]; } //需要装箱和向下转换,这种转换在编译时无法进行检查 stack.Push("s"); //wrong type,but no error! int i =(int)stack.Pop(); //Downcast-runtime error
泛型方法在方法的签名内也可以声明类型参数
static void Swap<T>(ref T a, ref T b) { T temp = a; a = b; b = temp; } int x= 5; int y = 10; Swap(ref x, ref y);//可以不指定T的类型,因为编译器可以隐式推断
在泛型类型里面的方法,除非也引入了类型参数(type parameters),否则是不会归为泛型方法的。比如public T Pop()=> data[--position];方法只是Stack<T>的一个普通方法,而非泛型方法。
只有类型和方法可以引入类型参数,属性、索引器、事件、字段、构造函数、操作符等都不可以声明类型参数。但是他们可以使用他们所在的泛型类型的类型参数。
public T this[int index] => data [index]; //索引器可以使用类型参数 public Stack<T>() {}// ,构造函数声明类型参数,Illegal
在声明class,struct,interface,delegate的时候可以引入类型参数(Type parameters)。其它的例如属性,就不可以引入类型参数,但是可以使用类型参数。
public struct Nullable<T> { public T value {get;} }
泛型类型/泛型方法可以有多个类型参数:
class Dictionary<TKey, TValue> {...} Dictionary<int,string> myDic = new Dictionary<int,string>(); var myDic = new Dictionary<int,string>();
泛型类型/泛型方法的名称可以被重载,条件是参数类型的个数不同:
class A {} class A<T> {} class A<T1,T2> {}
按约定,泛型类型/泛型方法如果只有一个类型参数,那么就叫T(也可以起其他名字,但要保证意图明显)。当使用多个类型参数的时候,每个类型参数都使用T作为前缀,随后跟着具有描述性的一个名字。
使用default关键字来获取泛型类型参数的默认值。
static void Zap<T> (T[] array) { for (int i = 0; i < array.Length; i++) array[i] = default(T); }
TYPEOF与未绑定的泛型类型
开放的泛型类型在编译后就变成了封闭的泛型类型。但是如果作为Type对象,那么未绑定的泛型类型在运行时是可以存在的。(只能通过typeof操作符来实现)
class A<T>{} class A《T1,T2>{} Type a1 = typeof(A<>); //Unbound type(notice no type arguments). Type a2 = typeof(A<,>);//Use commas to tndicate multiple type args.
泛型的约束
默认情况下,泛型的类型参数(parameter)可以是任何类型的。如果只允许使用特定的类型参数(argument),就可以指定约束。
where T: base-class //Base-class constraint。某个父类的子类 where T: interface //Interface constraint。实现某个接口 where T: class //Reference-type constraint。引用类型 where T: struct //Value-type constraint (excludes Nullable types)。值类型,不包括可空值类型 where T: new() //Parameterless constructor constraint。类型里必须有一个无参构造函数 where u: T //Naked type constraint。U继承于T
class SomeClass (} interface Interface1 (} class GenericClass<T,U> where T: SomeClass, Interface1 where U: new() {...}
表示T继承SomeClass,实现Interface1,U有一个无参构造函数
struct Nullable<T> where T : struct {...}
T是不可为null的值类型,Nullable<T>恰恰是为了使不可为null的值类型可为null
static void Initialize<T> (T[] array) where T:new() { for (int i= 0; i<array.Length; i++) array[i] = new T(); }
T有一个无参构造函数,所以可以使用new T();进行初始化
//裸类型约束。泛型类里有一个泛型方法,U继承于T class Stack<T> [ Stack<U> Filteredstack<U>() where U : T {...} ]
泛型的约束可以作用于类型或方法的定义。
public interface IComparable<T> { int CompareTo(T other); } static T Max<T> (T a, T b) where T: IComparable<T>//我认为,这几个T的类型都是一样的,包括IComparable<T>,它实际上是封闭泛型。也就是说,这里IComparable<T>的T是特指而不是泛指
{ return a.CompareTo (b) >0? a:b; } int z=Max (5, 10);//10 string Last = Max ("ant", "zoo"); //zoo
泛型类型的子类
泛型class可以有子类,在子类里,可以继续让父类的类型参数保持开放(就是T仍然是占位符,不是写死的)
class Stack<T>{...} class SpecialStack<T> : Stack<T> {...}
在子类里,也可以使用具体的类型来关闭(封闭)父类的类型参数
class IntStack:Stack<int>{...}
子类型也可以引入新的类型参数
class List<T>{...} class KeyedList<T,Tkey>:List<T>{...}
技术上来讲,所有子类的类型参数都是新鲜的。你可以认为子类先把父类的类型参数(argument)给关闭了,然后又打开了。为这个先关闭后打开的类型参数(argument)带来新的名称或含义。
class List<T>{...} class KeyedList<TElement,Tkey>:List<TELement>{...}
自引用的泛型声明
在封闭类型参数(argument)的时候,该类型可以把它自己作为具体的类型
public interface IEquatable<T> { bool Equals (T obj); } public class Balloon : IEquatable<Balloon>//这里有点怪的地方是,还没有完成Balloon的定义,就使用了它。Balloon实现了IEquatable<T>泛型接口 { public string Color { get; set; } public int cc { get; set; } public bool Equals (Balloon b) { if (b = null) return false; return b.Color == Color && b.CC == CC; } }
class Foo<T> where T: IComparable<T>{...}//比较怪的是T: IComparable<T>,接口里有T类型,而T实现了IComparable<T>,所以T引用了自己
class Bar<T> where T : Bar<T> {...}//这里的怪异感是上面两个例子的合并,泛型类Bar<T>还没定义完就使用了它。类Bar中有类型T,T又继承了Bar,也即是类bar中有自己的子类,是自引用
静态数据
针对每一个封闭类型,静念数据是唯一的(可以这样理解,每个封闭的类型都是不同的类,所以static字段也属于不同的类)
class Bob<T> { public static int Count; } class Test { static void Main() { Console. WriteLine (++Bob<int>.Count); //1 Console. WriteLine (++Bob<int>.Count); //2 Console. WriteLine (++Bob<string>.Count); //1 Console. WriteLine (++Bob<object>.Count);//1 } }
类型参数和转换
C#的转换操作符支持下列转换:数值转换、引用转换、装箱拆箱转换、自定义转换。决定采用哪种转换,发生在编译时,根据已知类型的操作数来决定。
StringBuilder Foo<T> (T arg) { tf (arg is StringBuilder) return (StringBuilder) arg;//will not compile,会被编译器以为是自定义转换 } StringBuilder Foo<T> (T arg) { StringButlder sb = arg as StringBuilder;//使用as操作符消除自定义转换的歧义 if (sb != null) return sb; ... } //更常见的解决方案,先转换为object,会被认为是引用转换 return (stringBuilder) (object) arg; int Foo<T> (T x) =>(int) x; // Compile-time error,有可能是数值转换,拆箱操作,自定义转换,无法确定是哪种,所以编译时不通过 //解决方案,先转换为object,那么最后就是拆箱操作。没有了歧义,就不会报错 int Foo<T> (T x) => (int) (object) x;
COVARIANCE, CONTRAVARIANCE, INVARIANCE
Covariance协变,当值作为返回值/out输出(T可以从子类转换为父类)
Contravariance逆变,当值作为输入input(T可以从父类转换为子类)
Invariance不变,当值既是输入又是输出
public interface IEnumerable<out T> public delegate void Action<inT> public interface IList<T>
记忆帮助:
IEnumerable<string> strings = new List<string> { "a", "b", "c" }; IEnumerable<object> objects = strings;
协变例子,因为是输出的,所以数据的转换方向是被转换类型(实际输出数据的类型)向目标转换类型(目标输出数据的类型)转换,实际输出数据的类型必须可以转换成目标输出数据的类型,所以被转换类型是目标转换类型的子类。
IList<string> strings = new List<string> { "a", "b", "c"}; IList<object> objects = strings; //假如上述转换成功(实际上报错) objects.Add(new object()); //第4个元素实际上不是字符串,不安全 string element = strings[3];
LIst的类型参数既作为输入,也作为输出,这里只关注输入的情况。IList<string>可以输入string类型的实例。当转换为IList<object>类型后,只能输入object类型实例。因为strings原来是一个字符串数组,所以可能会取出数组的元素作为字符串,这时候就会出错。抽象地说,因为是输入的,所以数据的转换方向是目标转换类型(实际传入数据的类型)向被转换类型(目标传入数据的类型)转换,实际传入数据的类型必须可以转换为目标传入数据的类型,所以目标转换类型得是被转换类型的子类。
VARIANCE([ˈveəriəns],差额)转换
涉及到variance的转换就是variance转换。Variance转换是引用转换的一个例子。引用转换就是指,你无法改变其底层的值,只能改变编译时类型。identity conversion,对CLR而言从一个类型转化到相同的类型
variance只能出现在接口和委托里。
如果从A到B的转换是本体转换或者隐式引用转换(也就是向上转换,子类转换为父类),那么从Ienumerabile<A>到Ienumerable<B>的转换就是合理的:
IEnumerable<string> to IEnumerable<obiect>
IEnumerable<string> to IEnumerable<IConvertible>
IEnumerable<IDisposable> to IEnumerable<obiect>
还有一点
C#的泛型,生产类型(例如List<T>)可以被编译到dll里。这是因为这种在生产者(例如List<T>)和产值封闭类型的消费者(例如List<int>)之间的合成是发生在运行时的。(c++是编译时合成)
Delegates委托
委托是一个对象,它知道如何调用一个方法。
委托类型定义了委托实例可以调用的那类方法,具体来说,委托类型定义了方法的返回类型和参数。
delegate int Transformer (int x); //委托类型名是Transformer static int Square (int x) { return x*x; }
把方法赋值给委托变量的时候就创建了委托实例。
Transformer t = Square;
调用
int answer = t(3); //answer is 9
委托的实例其实就是调用者的委托:调用者调用委托,然后委托调用自标方法。间接把调用者和目标方法解耦合了。
delegate int Transformer(int x); class Test { static void Main() { Transformer t = Square; //Create delegate instance。简写,完整写法是Transformer t = new Transformer(Square); int result = t(3); //Invoke delegate。简写,完整的写法是t.Invoke(3) Console.WriteLine(result); //9 } static int Square(int x) =>x*x; }
编写插件式的方法
方法是在运行时才赋值给委托变量的
namespace Demo { public delegate int Transformer(int x); class Util { public static void Transform(int[] values, Transformer t) { for (int i= 0; i<values.Length; i++) { values[i] = t(values[i]); } } } public class Program { static int square(int x) =x * x; static void Main() { int[] values ={1, 2, 3}; util.Transform(values, Square); foreach (int i in values) { Console. writeLine($"{i} "); } } }
}
多播委托
所有的委托实例都具有多播的能力。一个委托实例可以引用一组目标方法。+和+=操作符可以合并委托实例
SomeDelegate d = SomeMethod1; d += SomeMethod2; d = d + SomeMethod2;
调用d就会调用SomeMethod1和SomeMethod2。委托的调用顺序与它们的定义顺序一致。-和-=会把右边的委托从左边的委托里移除
d-= SomeMethod1;
委托变量使用+或+=操作符时,其操作数可以是null,就相当于把一个新的值赋给了委托变量。
SomeDelegate d = null; d += SomeMethod1;
相当于
d = SomeMethod1;
对单个目标方法的委托变量使用-=操作符时,就相当于把nul值赋给了委托变量。委托是不可变的,使用 += 或 -= 操作符时,实际上是创建了新的委托实例,并把它赋给当前的委托变量。如果多播委托的返回类型不是void,那么调用者从最后一个被调用的方法来接收返回值。前面的方法仍然会被调用,但是其返回值就被弃用了。
所有的委托类型都派生于System.MulticastDelegate,而它又派生于System.Delegate。C#会把作用于委托的+,-,+=,-=操作编译成使用System.Delegate的Combine和Remove两个静态方法。
实例方法目标和静态方法目标
当一个实例方法被赋值给委托对象的时候,这个委托对象不仅要保留着对方法的引用,还要保留着方法所属实例的引用,System.Delegate的Target属性就代表着这个实例。如果引用的是静态方法,那么Target属性的值就是null。
泛型委托类型
委托类型可以包含泛型类型参数
public delegate T Transformer<T>(T arg);
namespace Demo { public delegate T Transformer<T>(T arg); class Util { public static void Transform<T>(T[] values, Transformer<T> t) { for (int i= 0; i<values.Length; i++) { values[i] = t(values[i]); } } } public class Program { static int square(int x) =x * x; static void Main() { int[] values ={1, 2, 3}; util.Transform(values, Square); //Hook in Square. 完整的写法是util.Transform<int>(values, Square);但是因为可以通过传入的参数推断,所以可以省略不写 foreach (int i in values) { Console.writeLine(i + " "); } } } }
Func 和Action委托
使用泛型委托,就可以写出这样一组委托类型,它们可调用的方法可以拥有任意的返回类型和任意(合理)数量的参数。
Func和Action在System命名空间
delegate TResult Func <out TResult>(); delegate TResult Func <in T, out TResult>(т arg); delegate TResult Func <in T1, in T2, out TResult>(T1 arg1, T2 arg2); ... and so on, up to T16 delegate void Action(); delegate void Action <in T>(T arg); delegate void Action <in T1, in T2>(T1 arg1, T2 arg2); .. and so on, up to T16
注:这里的T1、T2、... TResult,虽然名称不同,但可以是相同类型的,可以理解为第1个参数的类型,第2个参数的类型…例子:
public static void Transform<T>(T[] values, Func<T,T> transformer)//这里可以看到,Func的类型参数可以是一样的。注意这里的T不是泛指,而是泛型Transform<T>的类型参数 { for (int i= 0; i<values.Length; i++) values[i] = t(values[i]); }
委托vs接口
委托可以解决的问题,接口都可以解决。什么情况下更适合使用委托而不是接口呢?当下列条件之一满足时:
接口只能定义一个方法
需要多播能力
订阅者需要多次实现接口
委托的兼容性
委托类型之间互不相容,即使方法签名一样:
delegate void D1(); delegate void D2(); D1 d1 = Method1; D2 d2 = d1; //Compile-time error
当你调用一个方法时,你提供的参数(argument)可以比委托的目标方法的参数(parameter)定义更具体。委托可以接受比它的目标方法更具体的参数类型(可以进行隐式转换),这个叫ContraVariance(逆变)。和泛型类型参数一样,委托的variance仅支持引用转换(比如不能是数值的隐式转换或者装箱操作)。
delegate void stringAction (string s); class Test { static void Main() { StringAction sa = new StringAction(ActOnobject); sa ("hello"); //hello } static void ActOnobject (object o) => Console.WriteLine (o); }
调用方法时,你可以得到一个比请求的类型更具体的类型的返回结果。委托的目标方法可以返回比委托描述里更具体的类型的返回结果,Covariance(协变)
delegate object ObjectRetriever(); class Test { static void Main() { ObjectRetriever o = new ObjectRetriever(Retrievestring); object result = o(); onsole.WriteLine(result);//hello } static string Retrievestring() => "hello"; }
注:理一理思路便于记忆。因为是按照委托描述里的参数类型输入实参的,所以委托实际引用的方法,参数的类型应该为委托描述的参数类型的父类,可以隐式转换。而返回值是从实际引用的方法返回的,所以实际引用的方法的返回类型应该为委托描述的返回类型的子类
Event事件
委托事件技术,是实现观察者模式的一种形式。观察者模式,看名字,其实很让人迷惑,听起来就好像是通知者,把消息发送出去,观察者主动捕获,从而做出反馈,又或者是,通知者直接把消息发送给观察者,观察者作出反馈。C#的事件机制也很迷惑人,比如说触发鼠标点击事件发生某特定行为,让人感觉真的是鼠标事件(也就是观察者模式中,通知者的状态)被观察者捕获到了。其实,C#里面类和类之间并没有什么消息通讯机制,所谓的通知,细节实现仅仅是通知的类直接调用观察的类的处理方法,而非开头所说的。观察者模式里,通知者有观察者的引用,从而在自身状态改变时,直接调用观察者的处理方法。而C#有委托技术,也就是方法的引用,从而解除了通知者对观察者的依赖
使用委托的时候,通常会出现两个角色,一个广播者(通知者),一个订阅者(观察者)。广播者这个类型包含一个委托字段,广播者通过调用委托来决定什么时候进行广播。订阅者是方法目标的接收者,订阅者可以决定何时开始或结束监听,方式是通过在委托上调用+=和-=。一个订阅者不知道和不干扰其它的订阅者。
事件就是将上述模式正式化的一个语言特性。事件是一种结构,为了实现广播者/订阅者模型,它只暴露了所需的委托特性的部分子集。事件的主要目的就是防止订阅者之间互相干扰。最简单的声明事件的方式就是在委托前面加上event关键字
//Delegate definition public delegate void PriceChangedHandler (decimal oldPrice, decimal newPrice); public class Broadcaster { //Event declaration public event PriceChangedHandler PriceChanged; }
Broadercaster类型里面的代码拥有对PriceChanged的完全访问权,在这里就可以把它当作委托。而Broadercaster类型之外的代码只能对PriceChanged这个event执行+=或-=操作。
编译器把事件的声明翻译成类似下面的代码:
PriceChangedHandler priceChanged; // private delegate public event PriceChangedHandler PriceChanged { add {priceChanged += value; } remove { priceChanged -= value;} }
add和remove关键字代表着显式的事件访问器,有点像属性访问器。编译器会查看Broadcaster内部对PriceChanged的引用,如不是+=或-=的操作,那就直接把它们定向到底层的委托字段priceChanged。编译器把作用在event的+=和-=操作翻译成调用add或remove访问器。
标准的事件模式
为编写事件,.NET定义了一个标准的模式。5ystem.EventArgs,一个预定义的框架类,除了静态的Empty属性之外,它没有其它成员。EventArgs是为事件传递信息的类的基类。
public class PriceChangedEventArgs : Systen. EyentArgs { public readonly decimal LastPrice; public readonly decimal NewPrice; public PriceChangedEventArgs (decimal LastPrice, decimal newPrice) { LastPrice = lastPrice; NewPrice = newPrice; } }
类名通常是根据所含有的信息进行命名,而不是所使用的事件。通常通过属性或只读字段来暴露数据
为事件选择或定义委托
回类型是void;接收两个参数,第一个参数类型是object,第二参数类型是EventArgs的子类。第一个参数表示事件的广播者,第二个参数包含需要传递的信息;名称必须以EventHandler结尾。
Framework定一了一个范型委托System.EventHandler<T,它满足上述规则。
public delegate void EventHandler<TEventArgs>(object source, TEventArgs e) where TEventArgs:EventArgs;
针对选择的委托定义事件
public class Stock { ... public event EventHandler<PriceChangedEventArgs> PriceChanged; }
可触发事件方法(就是调用委托的方法,通知、广播方法,为什么要包上一层呢?我的理解是可以从方法命名更直观地看出,这是发生事件后的处理方法)的名称必须和事件一致,前面再加上on,接收一个EventArgs参数
public class Stock { ... public event EventHandler<PriceChangedEventArgs> PriceChanged;
protected virtual void OnPriceChanged(PriceChangedEventArgs e) { if(PriceChanged!= nulL)PriceChanged(this,e); } }
注意在多线程的场景下,你需要在测试或调用前,把委托赋给一个临时变量,来避免线程安全相关的错误:
var temp = PriceChanged; if(temp!= null)tenp(this,e);
在C#6之后,可以这样写:
PriceChanged?.Invoke(this,e);
非范型的EventHandler
当事件不携带多余信息的时候,可以使用非范型的EventHandler委托。但是也需要给触发事件的方法传递一个EventArgs类型的参数,这时候可以把EventArgs.Empty属性传进去
public class Stock { string symbol; decimal price; public Stock (string symbol) { this.synbol = symbol; } public event EvenHandler PriceChanged; protected virtual void OnPriceChanged (EventArgs e) { PriceChanged?.Invoke(this, e); } public decimal Price { get { return price; } set { if (price = value) return; price = value; OnPriceChanged(EventArgs.Empty); } } }
事件访问器
事件访问器是事件的+=和-=函数的实现。
public event EventHandler PriceChanged;
编译器会把它转化为:一个私有的委托字段,一对公共的事件访问器函数(add_PriceChanged和remove_PriceChanged)。这两个函数的实现会把+=和-=操作交给私有的委托字段。也可以显式定义事件访问器
private EventHandler priceChanged; public event EventHandler PriceChanged { add { priceChanged += value; } remove { priceChanged -= value; } }
什么时候显式定义事件访问器?当事件访问器仅仅是另一个广播事件的类的中继。当类暴露大量event,但是大部分时候都只有少数的订阅者存在。显式实现一个声明了事件的接口。
事件修饰符
virtual,可以被重写;abstract,sealed,static.
public class Foo { public static event EventHandler<EventArgs> StaticEvent; public virtual event EventHandler<EventArgs> virtualEvent; }
Lambda表达式
Lambda表达式其实就是一个用来代替委托实例的未命名的方法;编译器会把Lambda表达式转化一个委托实例或一个表达式树(expression tree),类型是Expression<TDelegate>,它表示了可遍历的对象模型中Lambda表达式里面的代码。它允许lambda表达式延迟到运行时再被解释。
delegate int Transformer(int i); Transformer sqr = x =>x*x; Console.WriteLine(sqr(3));//9
实际上,编译器会通过编写一个私有方法来解析这个lambda表达式,然后把表达式的代码移动到这个方法里。
Lambda表达式的形式
(parameters)=> expression-or-statement-block (参数)=>表达式或语句块。其中如果只有一个参数并且类型可推断的话,那么参数的小括号可以省略
每个lambda表达式的参数对应委托的参数,表达式的返回类型对应委托的返回类型
Lambda表达式的代码也可以是语句块
x => { return x*x; };
Lambda表达式通常与Func和Action委托一起使用
Func<int, int> sgr = x=>x*x; Func<string, string, int> totalLength = (s1, s2) => s1.Length + s2.Length; int total = totalLength("hello", "world"); //total is 10;
如果参数类型不可推断的话,就要显式指定Lambda表达式的参数类型
void Foo<T>(T x)(} void Bar<T>(Action<T> a)//泛型方法Bar接受的参数是一个委托,这个委托有一个输入参数,类型是泛型方法Bar的类型参数T的类型 Bar(x => Foo(x));// what type is x? 注意这样的写法,=>还可以直接指向一个方法。Bar的类型参数T的类型就是x的类型。委托指向的方法就是Foo
//解决方法 Bar ((int x) =>Foo (x)); Bar<int> (x => Foo (x)); // Specify type parameter for Bar Bar<int> (Foo);//As above, but with method group
lambda表达式可以引用其所在方法的本地变量和参数
static void Main() { int factor = 2; Func<int, int> multiplier =n => n* factor; Console.WriteLine (multiplier(3)); //6 }
被Lambda表达式引用的外部变量叫做被捕获的变量(captured variables)。捕获了外部变量的lambda表达式叫做闭包。被捕获的变量是在委托被实际调用的时候才被计算,而不是在捕获的时候。
int factor = 2; Func<int,int> multiplier = n =>n*factor; factor = 10; Console.writeLine(multiplier(3));//30
Lambda表达式本身也可以更新被捕获的变量
int seed =0; Func<int> natural = ()=>seed++; Console.WriteLine(natural());//0 Console.WriteLine(natural());//1 Console.WriteLine(seed); //2
被捕获的变量的生命周期会被延长到和委托一样
static Func<int> Natural()//一个方法,返回类型是一个委托 { int seed =0; return () => seed++;//Returns a closure } static void Main() { Func<int> natural = Natural();//正常来说,Natural方法调用完后,方法里的本地变量就不存在 Console.WriteLine(natural()); //0 Console.WriteLine(natural()); //1 }
在Lambda表达式内实例化的本地变量对于委托实例的每次调用来说都是唯一的(意思是每次调用都会创建新的副本)。
static Func<int> Natural()//一个方法,返回类型是一个委托 { return () => { int seed =0; return seed++;}; } static void Main() { Func<int> natural = Natural();//正常来说,Natural方法调用完后,方法里的本地变量就不存在 Console.WriteLine(natural()); //0 Console.WriteLine(natural()); //0 }
当捕获for循环的迭代变量时,C#会把这个变量当作是在循环外部定义的变量,这就意味着每次迭代捕获的都是同一个变量。
Action[] actions = new Action[3]; //思考题:有一个int类型输入参数的Action是否写成Action<int>[] actions = new Action<int>[3]; for (int i=0; i<3; i++) actions[i]= () => Console.Write (i); //每个Action都是无参无返回的Action foreach (Action a in actions)a();//333,i的值是实际调用委托的时候才被计算
Action[] actions = new Action[3]; for (int i=0; i<3; i++) { int LoopSçopedi = i; //循环的每一轮产生的整型变量loopScopedi对应的内存空间是不同的,所以有3个副本,值分别是0、1、2,这3个副本都被延长了生命周期 actions[i]= () => Console.Write(LoopScopedi); } foreach (Action a in actions)a();//012
Lambda表达式vs本地方法
本地方法是C#7的一个新特性。它和Lambda表达式在功能上有很多重复之处,但它有三个优点:1、可以简单明了的进行递归。2、无需指定委托类型(那一堆代码).3、性能开销略低一点
本地方法效率更高是因为它避免了委托的间接调用(需要CPU周期内存分配)。本地方法也可以访问所在方法的本地变量,而且无需编译器把被捕获的变量hoist到隐藏的类。
匿名方法vs Lambda表达式
匿名方法和Lambda表达式很像,但是缺少以下三个特性:1、隐式类型参数。2、表达式语法,Lambda表达式可以只写一个表达式(匿名方法只能是语句块)。3、编译表达式树的能力,通过赋值给Expression<T>
delegate int Transformer(int i); Transformer sqr = delegate (int x) { return x*x;}; Console.WriteLine (sqr(3));//9
捕获外部变量的规则和Lambda表达式是一样的。但匿名方法可以完全省略参数声明,尽管委托需要参数
public event EventHandler Clicked = delegate{};
这就避免了触发事件前的null检查
//Notice that we omit the parameters: Clicked += delegate{Console.WriteLine("clicked");};
Try语句和异常
try语句指定了用来进行错误处理或清理的一个代码块。try语句块后边必须紧接着一个catch块或者是一个finally块,或者两者都有。当try块里发生错误的时候,catch块就会被执行。finally块会在执行完try块之后执行,如果catch也执行了,那就在catch块后边执行。finally块用来执行一些清理代码,无论是否有错误发生。catch块可以访问一个Exception对象,这个Exception对象里含有关于错误的信息。catch块通常被用来对错误进行处理/补偿或者重新抛出异常。finally块为你的程序增加了确定性:CLR总是尽力去执行它。它通常用来做一些清理任务。(有几种特殊情况,不会执行)
try { .. //exception may get thrown within execution of this block } catch (ExceptionA ex) { ... //handle exception of type ExceptionA } catch (ExceptionB ex) { ... //handle exception of type ExceptionB } finally { .. //cleanup code }
当异常被抛出的时候,CLR会执行一个测试,当前是否执行在能够catch异常的try语句里?如果是:当前执行就会传递给兼容 (指抛出的异常的类型和catch块关注的异常类型相同,或者指抛出的异常的类型是catch块关注的异常类型的子类) 的catch块里面,如果catch块完成了执行,那么执行会移动到try语句后边的语句(是指整个try...catch语句后的语句,而不是try语句块发生异常处后面的语句)。如果有finally块存在,会先执行finally块。如果不是:执行会返回到函数的调用者,并重复这个测试过程(在执行完任何包裹这语句的finally块之后)
catch
catch子句指定要捕获的异常的类型。这个异常必须是System.Exception或其子类。捕获System.Exception这个异常的话就会捕获所有可能的错误。当处理下面几种情况时,这么做是很有用的:1、无论是哪种类型的异常,你的程序都可能从错误中恢复。2、你计划重新抛出异常(可能在你记录了log之后)。3、你的错误处理器是程序终止运行前的最后一招。更典型的情况是,你会catch特定类型的异常。为的是避免处理那些你的处理程序并未针对设计的情况。你可以使用多个catch子句来处理多个异常类型(捕获具体类型的异常的catch子句应该放在前面,因为异常只会被一个catch子句捕获)。如果你不需要访问异常的属性,那么你可以不指定异常变量
catch(OverflowException) { ... }
更甚者,你可以把异常类型和变量都拿掉,这也意味着它会捕获所有的异常:
catch{...}
从C#6开始,你可以在catch子句中添加一个when子句来指定一个异常过滤器:
catch (WebException ex) when (ex.status == WebExceptionstatus.Timeout) { ... }
此例中,如果WebException被抛出的话,那么when后边的bool表达式就会被执行估算。如果计算的结果是false,那么后边所有的catch子句都会在考虑范围内(就是继续往下寻找匹配的catch子句)。
catch (WebException ex) when (ex.Status == WebExceptionStatus.Timeout) [...} catch (WebException ex) when (ex.Status == WebExceptionstatus.SendFailure) {...}
finally块
finally块永远都会被执行,无论是否抛出异常,无论try块是否跑完,finally块通常用来写清理代码。finally 块会在以下情况被执行:1、在一个catch块执行完之后。2、因为跳转语句(例如return或goto),程序的执行离开了try块。3、try块执行完毕后。唯一可以不让finall块执行的东西就是无限循环,或者程序突然结束。
using语句
很多类都封装了非托管的资源,例如文件处理、图像处理、数据库连接等。这些类都实现了IDisposable接口,这个接口定义了一个无参的Dispose方法用来清理这些资源。using语句提供了一个优雅的语法来在finally块里调用实现了IDisposable接口对象上的Dispose方法。
using (StreamReader reader = File.OpenText("file.txt")) { ... } //等价于 { StreamReader reader = File.OpenText("file.txt"); try { ... } finally { if (reader != null) { ((IDisposable)reader).Dispose(); } } }
抛出异常
异常可以被运行时或者用户抛出。
C#7之前,throw肯定是个语句。而现在它可以作为expression-bodied functions里的一个表达式:
public string Foo() => throw new NotImplementedException();
也可以出现在三元条件表达式里:
string ProperCase (string value) => value == null?throw new ArgumentException("value"):value
重新抛出异常
try { ... } catch (Exception ex) { //Log erron ... throw; //Rethrow same exception }
如果使用throw ex代替throw的话,程序仍可运行,但是新传递的异常的Stacktrace属性就不会反映原始错误了。这样重抛异常可以让你记录异常并且不会把它吞没,如果情况超出了你的预期(就是没有预料到的情况,不知道怎样处理,抛出去看调用者能不能处理),它允许你放弃在这里处理这个异常:
string s = null; using(Webclient wc = new WebClient()) try { s = wc.Downloadstring ("http://www.albahari. com/nutshell/"); } catch(WebException ex). { if (ex.Status == WebExceptionStatus.Timeout) Console.WriteLine("Timeout"); else throw;//Can't handle other sorts of webException, so rethrow }
使用C#6+,你可以这样简洁的重写上例:
catch(WebException ex)when(ex.Status == WebExceptionStatus.Timeout) { Console.WriteLine("Timeout"); }
其它常见的情景是抛出一个更具体的异常类型:
сгу { ...//Parse a DateTime from XML element data } catch(FormatException ex) { throw new xmLException("Invalid DateTime",ex); }
注意:在组建xmlException的时候,我把原异常ex,作为第二个参数传了进去,这样有助开调试。
有时候你会抛出一个更抽象的异常,通常是因为要穿越信任边界,防止信息泄露。
System.Exception的关键属性
StackTrace是一个字符串,展现了从异常发生地到catch块所有的被调用的方法。
Message关于错误的描述信息
InnerException引起外层异常的内层异常(如果存在的话)。而且InnerException本身还有可能含有InnerException
TryXXX模式
public int Parse(string input); public bool TryParse(string input,out int returnValue);
如果解析失败,Parse方法会抛出异常,而TryParse方法会返回false
枚举和迭代器
枚举器是一个只读的,作用于一序列值的、只能向前的游标。
枚举器是一个实现了System.Collections.lEnumerator或system.Collections.Generic.lEnumerator<T>接口的对象
技术上来说,任何一个含有名为MoveNext方法和名为Current的属性的对象,都会被当作枚举器来对待。
foreach语句会迭代可枚举的对象(enumerable object)。可枚举的对象是一序列值的逻辑表示。它本身不是游标,它是一个可以基于本身产生游标的对象。
可枚举对象enumerable[ɪ'nju:mərəbəl] object
一个可枚举对象可以是(任意一个):1、实现了IEnumerable或者lEnumerable<T>的对象。2、有一个名为GetEnumerator的方法,并且该方法返回一个枚举器(enumerator)
IEnumerator和IEnumerable是定义在System.Collections命名空间下的。IEnumerator<T>和IEnumerable<T>是定义在System.Collections.Generic命名空间下的。
枚举模式enumeration pattern
class Enumerator //Typically implements IEnumerator or IEnumerator<T> { public IteratorVariableType Current { get {...}} public bool MoveNext() {...} } class Enumerable //Typically implements IEnumerable or IEnumerable<T> { public Enumerator GetEnunerator() {...} }
using (var enumerator = "beer".GetEnumerator()) while (enumerator.MoveNext()) { var element = enumerator.Current; Console.WriteLine (element); }
集合初始化器
把可枚举对象进行实例化并且填充里面的元素:
using System.Collections.Generic; ... List<int> list = new List<int> {1, 2, 3};
编译器把它翻译成:
using Systen.Collections.Generic; ... List<int> list = new List<int>(); list.Add(1); list.Add(2); list.Add(3);
要求可枚举对象实现了System.Collections.IEnumerable接口,并且他还有一个可接受适当参数的Add方法。
迭代器 lterators
迭代器(Iterator)模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。迭代器模式在访问数组、集合、列表等数据时,尤其是数据库数据操作时,是非常普遍的应用,但由于它太普遍了,所以各种高级语言都对它进行了封装,所以反而给人感觉此模式本身不太常用了。
foreach语句是枚举器(enumerator)的消费者,而迭代器(iterator)是枚举器的生产者。
using system; using System.Collections.Generic; class Test { static void Main() { foreach (int fib in Fibs(6)) Console. Write(fib +""); } static IEnumerable<int> Fibs(int fibCount) { for (int i=0, prevFib = 1, curFib = 1; i < fibCount; i++) { yield return prevFib; int newFib = prevFib+curFib; prevFib = curFib; curFib = newFib; } } }
yield[jiːld] return语句表达的意思是:这是你向我请求从枚举器产生的下一个元素(意思就是说,Fibs方法的作用类似于一个枚举器,每次向调用者返回一个元素)。每逢遇到yield statement,控制权都会回归到调用者那里,但是被调用这的状态还是会保持的,这样的话可以保证当调用者列举出下一个元素的时候,方法可以继续执行。这个状态的生命周期被绑定到了枚举器上。这样的话,当调用者完成枚举动作之后,状态可以被释放。
原理解释:编译器把迭代方法转换成私有的、实现了IEnumerable<T>和/或lEnymerator<T>的类。迭代器块内部的逻辑被反转并且被切分到编译器生成的枚举器类里面的MoveNext方法和Current属性里。这意味着当你调用迭代器方法时,你所做的实际就是对编译器生成的类进行实例化;运行的代码里没有一行是你写的。你写的代码仅会在对结果序列进行枚举的时候才会运行,例如使用foreach语句。
迭代器(iterator)是含有一个或多个yield语句的方法、属性或索引器。(我的理解是,我们想对某个自定义集合进行遍历,但是又不想写代码去实现IEnumerable<T>和/或lEnymerator<T>接口,以进行遍历,于是使用yield语法糖,把这个任务交给编译器)
迭代器必须返回下面四个接口中的一个(否则编译器会报错):
//Enumerable interfaces System.Collections.lEnumerable System.Collections.Generic.IEnumerable<T> //Enumerator interfaces System.Collections.lEnumerator System.Collections.Generic.lEnumerator<T>
根据迭代器返回的是enumerable接口还是enumerator接口,迭代器会拥有不同的语义。
方法里可以含有多个yield语句:
class Test static void Main() { foreach (string s in Foo()) Console.WriteLine(s);//Prints "One", "Two", "Three" } static IEnumerable<string> Foo() { yield return "One"; yield return "Two"; yield return "Three"; }
vield break语句表示迭代器块会提前退出,不再返回更多的元素。return语句在迭代器块里面是非法的,你必须使用yield break代替。
static IEnumerable<string> Foo (bool breakEarly) { yield return "One"; yield return "Two"; if (breakEarly) yield break; yield return "Three"; }
送代器和try/catch/finally块
yield return语句不可以出现在含有catch子句的try块里面:
IEnumerable<string> Foo() { try{yield return"One";}//Illegal catch{...} }
yield return也不能出现在catch或者finally块里面。但是yield retun可以出现在只含有finally块的try块里面:
IEnumerable<string> Foo() { try{yield return"One";}//ok finally{...} }
当消费的枚举器到达序列终点或被disposed的时候,finally块里面的代码会执行。如果你提前进行了break,那么foreach语句也会dispose掉枚举器,所以用起来很安全。
当显式地使用枚举器的时候,通常会犯这样一个错误:没有dispose掉枚举就不再用它了,这就绕开了finally块。针对这种情况,你可以使用using语句来规避风险:
string firstElement = null; var sequence = Foo(); using (var enumerator = sequence.GetEnumerator()) if (enumerator.MoveNext()) firstElement = enumerator.Current;
组合序列
送代器是高度可组合的。
using system; using System.Collections.Generic; class Test { static void Main() { foreach (int fib in EvenNumbersonly (Fibs(6))) Console.WriteLine(fib); } static IEnumerable<int> Fibs(int fibCount) { for (int i=0, prevFib = 1, curFib = 1; i < fibCount; i++) { yield return prevFib; int newFib = prevFib+curFib; prevFib = curFib; curFib = newFib; } } static IEnumerable<int> EvenNumbersOnly(IEnumerable<int> sequence) { foreach (int x in sequence) if ((x%2) == 0) yield return x; } }
每个元素直到最后时刻才会被计算,也就是被MoveNext()操作请求(也就是foreach每循环一个元素的时候)的时候。

注:我的理解是,这图表示代码执行的路径,foreach向EvenNumbersOnly发起MoveNext()操作,EvenNumbersOnly向Fibs发起MoveNext()操作,Fibs一个接一个地返回元素,直到返回了符合EvenNumbersOnly要求的数据,EvenNumbersOnly再返回给foreach
可空类型
引用类型通过使用Null引用就可以表示一个不存在的值。然而,值类型通常就无法表示空值了。
string s = null;// OK, Reference Type int i = null;// Compile Error, value Type cannot be null
要在值类型里表示null值,你必须使用一种特殊的构造,它叫做可空(值)类型。可空类型是这样表示的:前面就是一个值类型,他后边跟着一个?(问号)
int? i = null;// OK, Nullable Type Console.WriteLine(i== null);//True
Nullable<T>结构体
T?这种写法表示的可空类型会被翻译成System.Nullable<T>。而System.Nullable<T>是一种轻量级且不可变的结构,它只有两个字段(Value和HasValue),这两个字段分别表示其真正的值(如果不是Null的话)和是否有非Null值。
public struct Nullable<T> where T: struct { private readonly T value; private readonly bool hąsValue; public Nullable(T value) { this.value =value; this.hasValue = true; } public bool HasValue { get { return hasValue; }} public T Value { get { if (!hasValue) { throw new InvalidOperationException(); } return value; } } }
已声明的构造函数把hasValue这个字段值设为了true.。和其他结构体一样,它也有一个隐式的无参构造函数。在那里hasValue的值原封不动,就是false;而value的值就是T的默认值。where T:struct这个约束,它允许T可以是任意的值类型,但不可以是Nullable<T>(因为Nullable<T>的存在就是为了使值类型可为空,所以他的帮助对象应该是基础的值类型)
无参的GetValueOrDefault()方法在HasValue为true的时候,会返回结构体里的值,如果HasValue为false,那么返回该类型的默认值。有参的GetValueOrDefault(T defaultValue)方法,在HasValue为false的情况下,会返回结构体里面的值或者通过方法参数指定的这个默认值。object里面定义的Equals(object)和GetHashCode()这两个方法也被相应的重写了,首先会比较HasValue属性的值,如果两个被比较对象的HasValue属性都是true,那么然后就会比较Value属性的相等性。
如果在HasValue为false的情况下,想去尝试获取Value的值,那么就会抛出InvalidOperationException。T?的默认值是null(和引用类型的null的意思不一样)
int? i = null;// OK, Nullable Type Console.WriteLine(i== null);//True
会被翻译成
Nullablecint> i = new Nullable<int>(); Console.WriteLine (! i.HasValue); //True
隐式和显式的可空转换
从T到T?的转换是隐式的(因为T?的范围比T大),而反过来,从T?到T的转换是显式的。
int? x = 5; //implicit int y = (int)x; //explicit
显式转换实际上就相当于直接调用可空类型的Value属性,所以,如果HasValue为false的话,那么也会抛出InvalidOperationException
假设有两个不可空的值类型S和T,并且可以从S转换为T(例如int到decimal),那么下列转换也都可用:
Nullale<S>到Nullable<T>(具体是隐式的还是显式的,与S转换为T一样)
S到Nullable<T>(具体是隐式的还是显式的,与S转换为T一样)
Nullable<S>到T(显式的)
int a = 3; decimal b = a; int? a1 = 4; decimal? b1 = a1; decimal? b2 = a; decimal b3 = (decimal)a1
注:隐式或显示是由S和T的取值范围以及可空值类型和值类型的取值范围来决定的,而可空值类型是大于值类型的取值范围的
可空类型的装箱和拆箱
当T?被装箱后,在堆内存上被装箱的值会包含T,而不是T?。之所以这种优化可以存在,是因为被装箱后的值是一个引用类型,而引用类型是可以表示Null值的(我的理解是,只保存T,不保存HasValue的值,因为HasValue与null有对应关系,而引用类型可以表示null)。C#也允许对可空类型进行拆箱操作,这里就需要使用as运算符。如果拆箱转换失败,那么得到的结果就是null(可空值类型的null就是HasValue为false),不会抛出异常。
object o = "string"; int? x= o as int?; Console.WriteLine (x.HasValue);//False
当一个不可空的值类型被装箱之后,其结果是得到一个类型的对象(实例)的一个引用,这里的类型是原始类型装箱后的一种形态。
int x = 5; object o = x;
这里的o就是到类型为“装箱后的int"的一个对象的引用。装箱后的int和int的差别,在C#里其实是看不出来的。如果你在这里调用o.GetType().那么其结果和typeof(int)的结果是一样的。
可空的值类型就没有类似的东西。对Nullable<T>装箱的结果依赖于HasValue属性:如果HasValue为false,结果就是null引用;如果为true,结果就是一个到类型为“装箱后的T"的对象的引用。
Nullable<int> noValue = new Nullablekint>(); object noValueBoxed = noValue; Console.WriteLine(noValueBoxed == null); Nullable<int> someValue = new Nullable<int>(5); object someValueBoxed = someValue; Console.WriteLine (someValueBoxed.GetType());
System.Object上面定义的GetType()方法不是virtual的,当装箱的时候规则貌似很复杂。具体来说就是,当你在值类型上调用GetType()方法时,这个值类型首先必须装箱。而针对可空值类型来说,它要么会引起NullReferenceException,要么返回底层的非可空值类型。
Nullable<int> noValue = new Nullable<int>(); //Console. WriteLine(noValue.GetType()); Nullable<int> someValue = new Nullable<int>(5); Console.WriteLine (someValue.GetType());
Null对于可空值类型的意义
Null有两种含义:Null引用或可空值类型HasValue为false时的值
下面这两种写法是等价的:
int?x = new int?();//使用无参构造函数进行初始化,HasValue为false int?x = null;
运算符提升
Nullable<T>这种结构体并没有给定义像<,>,==这样的运算符。
int? x= 5; int? y = 10; bool b =x<y; //true
编译器会从这个可空值类型的底层类型借用(或者叫提升)这个“小于”运算符,在语义上,编译器会把前面代码里这种比较操作翻译成:
bool b = (x.HasValue && y.Hasvalue) ? (x.Value < y.value) : false;
运算符提升的意思就是,你可以隐式地在T?上面使用T类型的运算符。当然,你也可以为T?定义新的运算符,以便提供特殊用途的null操作,但是大多数情况下,最好还是依靠编译器,让它为你自动应用系统的可空逻辑(我的理解就是让编译器自动为你生成上例的代码)
被提升的且用于判断相等性的运算符(==和 !=)会像引用类型那样处理null值:如果只有一个操作数是null,那么两个操作数肯定不等,结果就是false。如果两个操作数都非null,那么就会比较他们的真实值
Console.WriteLine (null == null); //True Console.WriteLine ((bool?) null == (bool?) nulL); //True
把一个null值与另一个null或者非null的值比较大小(< , <= , >= , >),都会返回false
bool b =x<y; //Translation: bool b= (x.HasValue && y.HasValue) ? (x.Value < y.Value) : false;
针对所有其它运算符(+,-, *, /, %, &, |, ^, <<, >>, ++,--, !, ~),如果任何一个操作数是null的话,那么返回的结果就是null
int? c=x +y; //Translation: int? c= (x.HasValue && y.HasValue) ? (int?)(x.Value + y.Value) null;

four,five,nulllnt的类型都是Nullable<int>,nulllin表示int? a = null。four表示int? a = 4。int? -(int? x)表示对一个类型为int?的变量x使用- 操作符,返回的值是int?。值得注意的是最后一行,因为可能会认为nullInt == nullInt是true的,但是,编译器看到是比较运算符,比较的逻辑是,两个操作数都不为null才会进行下一步比较。
唯一的例外是当&和|运算符应用于bool?这个类型的时候。当操作数是bool?类型的时候,&和 | 运算符会把null值当作未知值来处理,所以null | true的结果是true,这是因为:如果未知值是false,那么false | true,结果是true,如果未知值是true,那更是true了。同理,null & false结果就是false
bool? n = null; bool? f= false; bool? t= true; Console.WriteLine (n | n);//(null) Console.WriteLine (n | f);//(null) Console.WriteLine (n | t);//True Console.WriteLine (n & n);//(null) Console.WriteLine (n & f); //False Console.WriteLine (n & t);//(null)
针对Nullable<bool>,没有条件逻辑运算符。例如&&,||。

混合使用可空和不可空的运算符
你可以混合且匹配着使用可空和不可空类型,之所以可以这样操作,是因为从T到T?可以隐式转换。
int? a = null; int b = 2; int? c = a+b; //c is null - equivalent to a + (int?)b
可空类型和null运算符
可空类型与??运算符配合得特别好。
int? x = null; int y = x ?? 5; //y is 5 int? a = null, b= 1, c= 2; Console.WriteLine (a ?? b ?? c); //1 (first non-null value)
在可空值类型上使用??运算符,就相当于调用了GetValueOrDefault方法,并且为这个方法提供了一个显式的默认值作为其参数。当然,有一点不同是:如果变量不是null,那么默认值那部分的表达式就不会被执行。
可空类型也可以配合null条件运算符来使用
System.Text.StringBuilder sb = null; int? length = sb?.ToString().Length; int length = sb?.Tostring().Length ?? 0; //Evaluates to 0 if sb is null
可空类型和as运算符
as作用于可空值类型的结果是:如果原引用类型不对,那么返回null。如果类型匹配,就返回有意义的值。as作用于可空值类型的效率比较低下。
static void PrintValueAsInt32 (object o) { int? nullable = o as int?; Console.WriteLine(nullable.HasValue ? nullable.value.ToString() : "null"); } ... PrintValueAsInt32(5); //5 PrintValueAsInt32 ("some string");//null
扩展方法
扩展方法允许我们使用新的方法来扩展现有的类型,而且无需修改原有类型的定义。扩展方法是静态类的一个静态方法,在静态方法里的第一个参数使用this修饰符,第一个参数的类型就是要被扩展的类型
public static class StringHelper { public static bool IsCapitalized(this string s) { if(string.IsNullOrEmpty(s)) return false; return char.IsUpper(s[0]); } } //这里的IsCapitalized方法可以被这样调用: Console.WriteLine(StringHelper.IsCapitalized("Perth")); Console.WriteLine("Perth".IsCapitalized());
扩展方法的这种调用方式实际上是这样被翻译的:
argo.Method(arg1, arg2, ...); //Extension method call Staticclass.Method(arg0, arg1, arg2, ...);//Static method call
不只是类,接口也可以被扩展:
public static T First<T> (this IEnunerable<T> sequence) { foreach (T element in sequence) return element; throw new InvalidOperationException ("No elements!"); } ... Console.WriteLine ("Seattle".First()); //S
扩展方法和实例方法一样,也提供了一种整洁的方式来进行链式调用:
public static class StringHelper { public static string Pluralize(this string s){...} public static string Capitalize(this string s){...} }
就可以这样调用:
string x ="sausage".Pluralize().Capitalize(); string y = StringHelper.Capitalize(StringHelper.Pluralize("sausage"));
只有扩展方法所在的类处于作用范围内,才可以被访问扩展方法,典型的做法是引入命名空间
兼容(就是方法签名和调用匹配)的实例方法的优先级总是高于扩展方法
class Test public void Foo(object x){}//This method always wins static class Extensions { public static void Foo(this Test t, int x){} } //调用 var test = new Test(); test.Foo(12);
这样调用该Foo方法且传递参数甚至是int类型,而实际执行的方法却是Test的实例方法。这种情况下,唯一能调用扩展方法的方式就是使用静态调用的语法;也就是Extensions.Foo(...)
如果两个扩展方法拥有相同的签名,那么扩展方法必须像常规静态方法那样调用以避免歧义。而如果其中一个扩展方法的参数类型更具体,那么这个方法的优先级就会更高。
static class StringHelper { public static bool IsCapitalized(this string s){...} } static class ObjectHelper { public static bool IsCapitalized(this object s){...} } bool test1 ="Perth".IsCapitalized();
这种情况下,调用的就是StringHelper上的IsCapitalized方法。注意:类和结构体被认为比接口更具体
匿名类型
匿名类型就是由编译器即时创建的一个class,它用来存储一组数据。
创建匿名类型:new + object初始化器,并指定属性及其值
var dude = new { Name = "Bob", Age = 23 };
使用var关键字来引用匿名类,因为匿名类型没有名字。
匿名类属性的名称可以通过本身就是标识符/以标识符结尾的表达式推断出来(如果不写属性名。那么属性名就是标识符)
int Age = 23; var dude= new { Name= "Bob", Age, Age.ToString().Length }; //等价于 var dude = new { Name = "Bob", Age = Age, Length = Age.ToString().Length };
属性值是变量Age的值,由于属性名和变量名一样,直接写变量名就可以了。编译器可以推断出来属性名和变量名一样。
在同一个assembly下声明的两个匿名类实例,如果它们的元素名、顺序和类型都完全一致(和元素的值无关),那么它们的基础类型(underlying type)就是一样的
var a1 = new {x =2, Y=4 }; var a2 = new {x =2, Y=4}; Console.writeLine(a1.GetType() == a2.GetType()); //True var a1 = new {y =2, x=4 }; var a2 = new {x =2, Y=4}; Console.writeLine(a1.GetType() == a2.GetType()); //false
Equals方法被重写来进行相等性的比较
var a1 = new {x=2, Y=4}; var a2 = new {x=2, Y=4}; Console.WriteLine(a1.GetType(); == a2.GetType()); //True 类型相同 Console.writeLine(a1 ==a2); //False 引用不同的实例 Console.writeLine(a1.Equals(a2)); //True 两个实例的值相等
可以创建匿名类型数组,元素类型必须一致
var dudes = new[] { new { Name = "Bob", Age = 30 }, new { Name = "Tom", Age =40 } };
方法不可以返回匿名类型的对象(因为不知道类型名称,var不能作为返回类型),必须使用dynamic或者object,调用时依赖于动态绑定,并且会损失静态类型的安全性。
dynamic Foo() =>new { Name = "Bob", Age = 30 }; //no static type safety.
匿名类型主要用来写LINQ查询
TUPLE 元祖 (C# 7)
Tuple提供了简单的方式来存储一组数据。使用Tuple的主要目的是从方法安全地返回多个值,而且无需使用out参数。C#7的Tuple主要是依赖于一组支撑它的struct,叫做System.ValueTuple<>
创建tuple字面值最简单的方式就是在小括号里列出所有的值。
var bob=("Bob", 23);
通过xx(变量名).Item1,xx.Item2来引用tuple里面的未命名元素
Tuple是值类型,其元素是可变的(可读写)。你可以明确指定Tuple的类型,只需要在小括号里列出每个元素的类型即可
var joe =bob; //joe is a * copy* of job joe.Item1 = "Joe"; //Change joe's Item1 from Bob to Joe Console.WriteLine(bob); //(Bob, 23) Console.WriteLine(joe); //(Joe, 23) (string, int) bob = ("Bob", 23); // var is not compulsory with tuples!
可以从方法返回Tuple类型。
static (string, int) GetPerson() = ("Bob", 23); static void Main() { (string, int) person = GetPerson(); //Could use 'var' here if we want Console.WriteLine(person.Item1); //Bob Console.WriteLine(person.Item2); //23 }
Tuple可以和泛型很好地共存。
Task<(string, int)> a; Dictionary<(string, int), Uri> b; IEnumerable<(int ID, string Name)> c;// See below for naming elements
在创建Tuple字面值的时候,你可以给元素一个有意义的名字。
var tuple =(Name: "Bob", Age: 23); Console.Writeline(tuple.Name); //Bob Console.Writeline(tuple.Age); //23
在指定Tuple类型(指元素类型)的时候,也可以给元素起名。仍然可以通过Item1,ltem2来引用元素(VS没有智能提示)。
static (string Name, int Age) GetPerson()=("Bob", 23);
如果两个Tuple的元素类型、顺序都一致(元素名没关系),那么两个Tuple的类型就是兼容的。
(string Name, int Age, char Sex) bob1 = ("Bob", 23, 'M'); (string Age, int Sex, char Name) bob2 = bob1; //No error!
类型擦除
C#使用了一组现存的泛型struct来处理Tuple
public struct ValueTuple<T1>
public struct ValueTuple<T1,T2>
public struct ValueTuple<T1,T2,T3>
...
每个ValueTuple<> struct都有Item1,Item2 等字段。所以(string,int)就是ValueTuple<string,int>的一个别名而已。在底层类型里命名的元素没有对应的属性名(属性名都是Item1,Item2 等字段),元素名仅仅存在于源代码和编译器的想象中。在运行时,大部分元素名都会消失。针对返回命名Tuple的方法/属性,编译器会通过在成员的返回类型上使用TupleElementNamesAttribute,来释放出元素名。允许在其它的Assembly里面调用方法时可以使用命名元素。
ValueTuple.Create
可以使用ValueTuple(非泛型)类型上的工厂方法来创建Tuple。命名元素不可以通过这种方式创建,因为元素命名依赖于编译器的一些骚操作。
valueTuple<string, int> bob1 = ValueTuple.Create("Bob", 23); (string, int) bob2 = ValueTuple.Create("Bob", 23);
Deconstructing Tuples
Tuple隐式支持Deconstruction模式,你可以很简单的将Tuple deconstruct为多个变量
//常规写法 var bob=("Bob",23); string name = bob.Item1; int age = bob.Item2; //Deconstruction 模式 var bob =("Bob",23); (string name,int age) = bob;//Deconstruct the bob tuple into separate variables(name and age) Console.Writeline(name); Console.WriteLine(age); //语法别混淆了 (string name,int age)= bob;//Deconstructing a tuple (string name,int age)bob2=bob;//声明一个新tuple
相等性比较
ValueTuple<>也重写了Equals方法,让比较更有意义。通过例子可以看出,Tuple可以作为Dictionary的Key Tuple也实现了IComparable接口,所以Tuple也可以作为排序的Key
System.Tuple Classes
System命名空间下还有一族泛型类叫做Tuple(而不是ValueTuple),.NET Framework 4.0引入的class,而ValueTuple是struct
Attribute
Attribute是一种扩展机制,它可以为代码元素(Assembly,类型、成员、返回值、参数、泛型参数)添加自定义的信息。一个很好的应用场景就是序列化——把任意一个对象转化为特定格式 / 从特定格式转化过来
Attribute Class
一个Attribute是通过一个(直接或间接)继承了System.Attribute的类来定义的。把Attribute应用于代码元素:
[obsoleteAttribute] public class Foo[...}
按约定,所有的Attribute都应该以Attribute这个单词结尾。C#会识别这个后缀,并且允许你在附加Attribute的时候忽略这个后缀
[obsolete] public class Foo[...}
Attribute可以有参数
[XmLElement("Customer",Namespace="http://oreilLy.com")] public class CustomerEntity{...}
Attribute的参数可以分为两类:位置的和命名的。位置参数对应Attribute类型的公共构造函数的参数。命名参数对应Attribute类型的公共字段或公共属性。当指定Attribute的时候,必须包含与Attribute相应构造函数所对应的位置参数(构造函数里的参数都得要),而命名参数是可选的。
Attribute的目标
没明确指定的情况下,Attribute的目标就是紧随它的代码元素,通常是一个类型或类型的成员。也可以把Attribute附加到一个Assembly,这就需要显式指定Attribute的目标
[assembly:CLSCompliant(true)]
指定多个Attribute
对一个代码元素可以指定多个Attribute,每个Attribute可以列在同一个中括号内(使用逗号分开),也可以独占一个中括号。
[Serializable,Obsolete,CLSCompliant(false)] public class Bar{...} [Serializable][obsolete][CLSCompliant(false)] public class Bar{...} [Serializable,Obsolete] [CLSCompliant(false)] public class Bar{...}
Caller Info Attribute
从C#5开始,你可以使用下列三个Caller Info Attributes之一对可选参数进行标记:
[CallerMemberName]表示调用者成员的名称
[CallerFilePath]表示调用者源代码的路径
[CallerLineNumber]表示调用者在源码文件里面的行号
static void Main() => Foo(); static void Foo( [CallerMemberName] string memberName = null, [CallerFilePath] string filePath-= null, [CallerLineNumber] int lineNumber =0) { Console.WriteLine(memberName); //Main Console.WriteLine(filePath); //D:\Projects\dotnet\Demo\Program.cs Console.WriteLine(lineNumber);//9,Main方法所在的行 }
跟可选参数一样,这个替换是发生在调用时的。所以Main方法就是下面代码的语法糖:
static void Main()=> Foo("Main",@"D:\Projects\dotnet\Demo\Program.cs",9);
如果一个属性的get或者set方法调用了Foo,那么memberName的默认值就是属性的名称。
Dynamic Binding 动态绑定
静态绑定:通常来讲,引用在编译时就可以解析出来。
动态绑定:把解析类型、成员、操作的过程从编译时延迟到运行时。通常用于:你知道某个函数、成员、操作存在,但是编译器不知道
Animal a = new Animal(); a.Roar(); //The compiler can resolve this method call statically. public void MakeSomeNoise(object a) { //Things happen... ((Animal) a).Roar(); //You won't know if this works until runtime! }
dynamic类型
dynamic类型使用上下文关键字dynamic来声明:
dynamic d = GetSomeObject(); d.Quack();
因为d是dynamic的,编译器就会把Quack()方法绑定到d的这个动作延迟到运行时。
dynamic类型和object类型很像,但是它允许你使用在编译时还不知道的方式来操作。dynamic类型在运行时基于运行时的类型进行绑定,而不是编译时的类型。
静态绑定vs动态绑定
Duck d = ...
d.Quack();
静态绑定过程:编译器在Duck上寻找一个名叫Quack的无参方法->否则就扩大搜索范围,含有可选参数的Quack方法->父类上的方法->扩展方法,如果还是找不到,则编译失败。这个过程完全依赖于对运算对象(d)类型的静态知晓(就是说,从类型定义中提前知晓)。这就是静态绑定
在运行时,如果dynamic对象实现了IDynamicMetaObjectProvider,那么该接口就用来执行绑定。这叫做自定义绑定(Custom Binding)。否则,绑定发生的方式和编译器已经知道dynamic对象运行时类型一样。这叫做语言绑定(Language Binding)。如果成员无法进行绑定,那么就会抛出RunTimeBinderException
Custom Binding 自定义绑定
当一个dynamic对象实现了IDynamicMetaObjectProvider(IDMOP)的时候,就会发生自定义绑定。通常情况是,你从某个动态语言请求了一个IDMOP对象,该语言基于.NET的DLR(dynamic Language runtime)实现,例如ronPython或lronRuby。这些语言的对象都隐式实现了IDMOP接口。
动态绑定注意问题
动态绑定确实规避了静态的类型检查,但是没有规避运行时的类型检查。与反射不一样,使用动态绑定,你无法规避成员的访问规则。
动态绑定也会引起写性能问题,因为DLR的缓存机制。但是重复调用同样的动态表达式是有优化的,例如在循环里调用动态表达式。
Dynamic的运行时表述
dynamic和object类型很大程度上是等价的。运行时认为这个是true:
typeof(dynamic) == typeof(object) typeof(List<dynamic>) == typeof(List<object>) typeof(dynamic[]) == typeof(object[])
和object引用一样,dynamic引用也可以指向任何类型的对象(除了指针类型)
dynamic x = "hello"; Console.WriteLine (x.GetType().Name); //String x= 123; //No error (despite same variable) Console.WriteLine (x.GetType().Name); //Int32
从结构上看,object引用和dynamic引用没有什么区别。可以把object对象转化为dynamic类型,来执行“动态”的操作
object o = new System.Text.StringBuilder();//向上转换,对象o上看不到StringBuilder的操作,此时转换为dynamic就可以执行tringBuilder的操作了 dynamic d =o; d.Append("hello"); Console.WriteLine(o);//hello
若在一个提供了公共dynamic成员的类型上使用反射(应该是查看编译代码的意思),就可以看到这些成员以标记的对象的形式进行的表示:
public class Test { public dynamic Foo; } //is equivalent to: public class Test { [System.Runtime.CompilerServices.DynamicAttribute] public object Foo; }
动态转换
Dynamic类型可以隐式从其它类型转换过来,也可以隐式转换到其它类型(有条件):
int i = 7; dynamic d = i; long j =d;//No cast required (implicit conversion) int i = 7; dynamic d = i; short j = d;// throws RuntimeBinderException。实际类型是int,不可隐式转short。也就是说,dynamic要隐式转换,是有条件的,就是实际的类型可以隐式转换
var vs dynamic
var:让编译器推断出类型(编译时就可推断)dynamic:运行时推断出类型
dynamic x = "hello"; // static type is dynamic, runtime type is string var y = "hello"; //static type is string, runtime type is string int i = x; //Runtime error(cannot convert string to int) int j=y;//Compile-time error (cannot convert string to int)
dynamic x = "hello"; var y = x; //static type of y is dynamic int z = y; //Runtime error (cannot convert string to int)
动态表达式
涉及动态运算对象(即dynamic类型对象)的表达式就是动态表达式,缺失类型信息是有级联效果的(我的理解是,动态运算对象进行操作或运算,结果仍然是动态运算对象)。
dynamic x=2; var y =x*3;//Static type of y is dynamic
也有例外,把动态表达式转化为静态类型,就会得到一个静态表达式
dynamic x = 2; var y = (int)x; // static type of y is int
调用构造函数总会得到静态表达式(意思是指类型确定),哪怕是使用了dynamic类型的参数
dynamic capacity = 10; var x = new System.Text.StringBuilder(capacity);
字段、属性、方法、事件、构造函数、索引器、运算符和转换都可以动态调用。使用void返回类型来消费动态表达式(下例的list.Add(5)就是动态表达式)的结果是不可以的(这句话的意思不懂,不知道消费指的什么,但是我可以猜测,动态表达式不返回值,那么就不能把其赋值给一个对象),这点和静态的表达式一样,区别是,这个错误会发生在运行时
dynamic list = new List<int>(); var result = list.Add(5); //RuntimeBinderException thrown
动态调用,但却没有动态接收者
一个dynamic对象是dynamic函数的调用的接收者:
dynamic x = ... ; x.Foo(); //x.Foo()是一个动态的调用,没有接受者,x is the receiver
可以使用动态参数来静态地调用已知函数,这种调用遵循动态重载解析规则(运行时判断传入参数的类型来动态调用函数),包括:静态方法、实例构造函数、实例方法,但是接收者是静态已知类型
class Program { static void Foo (int x) { Console.WriteLine ("1"); } static void Foo (string x) { Console.WriteLine ("2"); } static void Main() { dynamic x = 5; dynamic y = "watermelon"; Foo(x); //1 Foo(y);//2 } }
由于不涉及动态接收者,编译器可以静态地执行一个基本的检查,看看动态调用是否会成功。如果没找到那么在编译时就会报错:函数名、参数数量
class Program { static void Foo (int x){Console.Writeline ("1"); } static void Foo (string x) { Console.Writeline ("2"); } static void Main() { dynamic x = 5; Foo (x, x); //Compiler error -wrong number of parameters Fook(x);//Compiler error-no such method name } }
动态表达式里面的静态类型
static void Foo(object x, object y) { Console.WriteLine ("oo"); } static void Foo(object x, string y) { Console.WriteLine ("os"); } static void Foo(string x, object y) {Console.WriteLine ("so"); } static void Foo(string x, string y) { Console.WriteLine ("ss"); } static void Main() { object o = "hello"; dynamic d ="goodbye"; Foo (o, d); //动态绑定,因为d参数是dynamic类型的,输出结果os }
很明显、动态绑定里面使用了动态类型。不明显的是,静态类型也用到了,而且在动态绑定中是尽可能的用到。o是静态可知的,这个绑定即使是动态的发生,也会利用这一点。这里重载解析会选择第2个Foo的实现,就是根据静态类型o和d的运行时类型。
无法动态调用的函数
有一些函数不可以被动态的调用:
扩展方法(以扩展的形式)
接口的成员(如果你需要转化为接口的话)
被子类隐藏的基类成员
因为动态绑定需要两方面的信息:被调用函数的名字和调用函数的对象
这三种情况,都需要额外的类型(缺少了调用函数的对象),并且它只在编译时知晓,运行时就“丢失了”。截至C#6,还无法动态的指定这些额外的类型
调用扩展方法的时候,额外的类型(它就是扩展方法所在的静态类)是隐式的。编译器会在你的代码里搜索你所给定的using指令。这使得扩展方法在编译时仅仅是一个概念,因为using指令在编译时就消失了(在它绑定过程中的映射简单名称到命名空间名)
public static void Main(string[] args) { dynamic d = 5; d.Hello(); //编译器这样编译上面两行,dynamic没有用到int的扩展方法(因为类型不同嘛)所以,相当于静态类对这两行来说消失了,编译完了,也没有生成IntHelper.Hello(x);这样的形式。运行时,只能从int类本身找Hello方法,自然找不到了 int x= 5; x.Hello(); //编译器会在编译时将上两句编译为:IntHelper.Hello(x); } public static çlass IntHelper { public static void Hello(this int x) { System.Console.WriteLine(x); } }
接口成员例子
interface IFoo { void Test(); } class Foo : IFoo { void IFoo.Test(){}} public class Program { public static void Main(string[] args) { IFoo f = new Foo();//Implicit cast to interface f.Test(); IFoo f = new Foo(); dynamic d = f; d.Test();//Exception thrown。运行时,d是Foo类型的,Foo类型没有Test方法 Console.writeLine(f.GetType().Name); //Foo } }
运算符重载
运算符是可以被重载的,可以为自定义类型提供更自然的语法。例如,实现自定义的struct来表示相应的原始类型
运算符函数
通过声明运算符函数,就可以对运算符进行重载。运算符函数有以下规则:函数名使用operator关键字,后边跟着运算符的符号。必须是static和public的。函数的参数代表着运算符的运算数。函数的结果代表表达式的结果 。至少有一个运算数的类型必须是函数所声明的类型
static void Main(string[] args) { Note B = new Note(2); Note CSharp = B+ 2; CSharp +=2;//重载了+后,对应的复合运算符也被重载了 } public struct Note { int value; public Note(int semitonesFromA) { value = semitonesFromA; } public static Note operator +(Note x, int semitones) { return new Note(x.value + semitones); } }
重载相等性和比较运算符
写struct的时候,有时候会重载相等性和比较运算符;而写class的时候却很少。重载相等性和比较运算符的时候有一些规则:
1、成对重载——C#编译器要求成逻辑对的运算符必须都被定义,它们是:(== !=),(< >),(<= >=)。
2、Equals和GetHashCode,大多数情况下,如果你重载了!=和== ,你通常需要重载Equals和GetHashCode这两个方法(定义在object类里),这样才能得到比较有意义的行为。如果你不这样做,那么C#编译器会给你一个警告
3、IComparable和IComparable<T>,如果你重载了(< >)和(<= >=)运算符,那么你就应该实现IComparable和IComparable<T>这两个接口
自定义隐式和显式转换
隐式和显式转换是可重载的运算符。
想在弱关联的类型之间做转换,下列策略更适合一些:写一个构造函数,参数是源类型。写一个ToXxx和一个static FromXxx方法,来做类型间的转换
注意:自定义转换会被as和is运算符忽略
Note n= (Note)554.37; //explicit conversion 显式转换 double x = n; //implicit conversion 隐式转换
实现:
public struct Note { int value; public Note(int semitonesFromA) { value = semitonesFromA; } //Convert to hertz 隐式转换 implicit[ɪmˈplɪsɪt] public static implicit operator double(Note x) =>440 * Math.Pow(2, (double)x.value /12); //Convert from hertz (accurate to the nearest semitone) 显式转换 public static explicit operator Note(double x) => new Note((int)(0.5 + 12 * (Math.Log(x /440)/Math...)); }
//即使做了自定义转换,仍然不被is和as认可 Console.WriteLine(554.37 is Note); //False Note n1 = 554.37 as Note; //Error
重载true和false
有一些精神上是bool,但却无法转换成bool的类型,在极端少数情况下,true和false运算符也会被重载。通过重载true和false运算符,这样的类型就可以与条件表达式和运算符一起无缝的工作了,包括:if,do,while,for,&&,和?:。System.Data.SqlTypes.SqlBoolean这个struct提供了这个功能
SqLBoolean a = SqlBoolean.Null; if (a) Console.writeLine("True"); else if (!a) Console.writeLine("False"); else Console.writeLine("Null"); public struct sqLBoolean { public static bool operator true(SqLBoolean x) => x.m_value==True.m_value; public static bool operator false(SgLBoolean x) => x.m_ value==False.m_value; public static SqlBoolean operator !(SqlBoolean x) { if (x.m_value == Null.m_value) return Null; if (x.m_value == False.m_value) return True; return False; } public static readonly SqlBoolean Null = new SqLBoolean(0); public static readonly SqlBoolean False = new SqlBoolean(1); public static readonly SqlBoolean True = new SqLBoolean(2); private sqlBoolean(byte value) { m_value = value; } private byte m_value; }
String和文字处理
char
char代表一个unicode字符,它是System.Char的别名。
System.Char定义了一组静态方法:l'oUpper 、ToLower、 IsWhiteSpace...可以通过char或者System.Char来调用
Console.WriteLine(System.Char.ToUpper('c')); //c Console.WriteLine(char.IsWhiteSpace('\t')); //True
char是16bit的,足够代表基本多语言平面的任何Unicode字符。如果超出这个范围,那么必须使用surrogate pairs
culture-invariant版本的方法
ToUpper,ToLower会遵循用户的地区(locale)设置,可能会引起bug:char.ToUpper('i')='I',这句话在土耳其地区设置里就会返回false,char.ToUpper('i')返回的是土耳其特有的字符
culture-invariant版本的方法,总会应用英语的Culture ToUpperlnvariant、ToLowerInvariant
string
string是System.String的别名,string是不可变的,string是字符的序列
创建重复字符的字符申
Console.write(new string('*', 10)); /**********
可以从char数组构建字符串,ToCharArray的作用正好相反
char[] ca = "Hello".ToCharArray(); string s = new string(ca); //s= "Hello"
string实现了1Enumerable-char>接口,所以可以forcach里面的char元素
IndexOFAny,它会返回一组字符里任意一个元素的第一个匹配的位置。
Console.Write("ab, cd ef".IndexofAny(new char[] {' ' , ','})):
因为string是不可变的,所以所有“操纵”string的方法返回的都是一个新的string,原来的string是原封不动的。
Null和空string
空string的长度为0,通过literal或string.Empty静态字段来创建。string可以为null,因为是引用类型。静态的string.IsNullOrEmpty通常用来判断字符串是否为空或者null