supervision 检测和分割的Detection类 Day(1)
之前的随笔,算是一个简要的supervision的使用方法,但对于大部分内容本人还是一知半解,因此我查看官方文档,对照着官方文档来进行supervision的详细学习,并对其中一些重要的方法和属性进行解释
Detections and Segmentation-检测与分割
一、Detections 类
supervision是这样描述Detections类的:
Supervision 库中的 sv.Detections 类将来自各种目标检测和分割模型的结果标准化为一致的格式。这个类简化了数据的操作和过滤,提供了一个统一的 API,以便与 Supervision 的跟踪器(tracker)、注释器(annotator)和工具集成。
1.属性
- xyxy:检测框的左上角坐标和右下角坐标
- confidence:置信度
- class_id:检测的物体对应的索引
- data:对应的类名
- tracker_id:跟踪器的id
- mask:图像分割产生的掩膜,如果不是图像分割,则会是None
- box_area:返回每个检测框的面积
- area:如果Detections类定义了掩膜,则返回掩膜的面积值,否则返回检测框的面积值
2.重要方法
-
from_ultralytics(ultralytics_results):
- ultralytics_results:yolo的推理结果
通过这个方法能够将YOLO的推理结果ultralytics_results转换为sv.Detections的实例
还有很多其他的from_xxx的方法,将其他的推理结果转换为Detections的实例,这里就不一一列举了 -
with_nms(threshold=0.5, class_agnostic=False):
- threshold:设定的IoU的阈值,默认为0.5
- class_agnostic:执行的非极大值抑制是否与类无关,默认为False表示有关
对于一个图片,可能会出现一个物体同时被识别成两种类型,如下图

如图,虽然画面上只显示了三个框,但实际上,后方的车即被识别成了car类,又被识别成了truck类,可见下方的detections内容
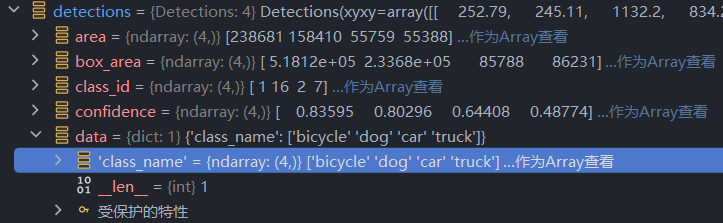
with_nms采用了nms,即非极大值抑制的方法,用以解决多个框重叠的问题,该方法会计算某个框与其他框的IoU(相当于相交比),对于IoU大于阈值的两个框,会舍弃掉其中置信度较小的框,保留置信度更大的从而达到减少框重叠的功能
import cv2
import supervision as sv
from ultralytics import YOLO
cv2.namedWindow('img1',cv2.WINDOW_NORMAL)
model=YOLO('yolo11n.pt')
image=cv2.imread('images/dog_bike.jpeg')
result=model(image)[0]
detections=sv.Detections.from_ultralytics(result)
#detections调用with_nms方法,设定阈值为0.5,类无关的非极大值抑制
detections=detections.with_nms(0.5,True)
box_annotator=sv.BoxAnnotator()
box_annotator.annotate(scene=image,detections=detections)
labels=[
f'{class_name} {confidence:.2f}'
for class_name,confidence
in zip(detections['class_name'], detections.confidence)
]
label_annotator=sv.LabelAnnotator()
label_annotator.annotate(scene=image,detections=detections,labels=labels)
cv2.imshow('img1',image)
cv2.waitKey(0)

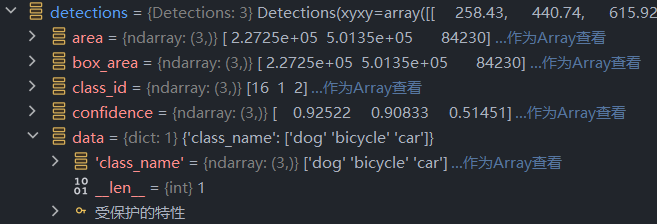
可见,后方的车辆最终被识别成了car类型,truck类被去除了
-
with_nmm(threshold=0.5,class-agnostic=False)
与with_nms功能基本一致,只不过nmm采用的是非极大值合并的方法
-
_getitem_
Detections类重写了__getitem__方法,使得可以直接用索引的方式进行切片过滤等操作,其中过滤操作是较为重要的,官方的学习文档中提供了几种过滤方法
先提供一个未经过滤的检测图

-
通过具体的类别:
#之前的操作省略,仅展示过滤操作 detections=detections[detections.class_id==0] #class_id==0为person类
-
按类的集合:
selected_classes = [0, 2, 41] detections = detections[np.isin(detections.class_id, selected_classes)]
-
按置信度:
detections = detections[detections.confidence > 0.6]
-
按区域面积大小:
detections = detections[detections.area > 100000] #也可以用detections.area/image.area来按照相对大小来过滤
-
按方框尺寸:
w = detections.xyxy[:, 2] - detections.xyxy[:, 0] h = detections.xyxy[:, 3] - detections.xyxy[:, 1] detections = detections[(w > 300) & (h > 200)]
-
按照多边形区域:
使用PolygonZone函数,之后学到之后再讲解
-
混合过滤检索
即将之前的所有情况组合起来,使用&和|来连接
-