一,超级详细的ClickHouse安装部署文档(RPM版安装),新手小白一看就能学会!!!
ClickHouse安装部署博客笔记(RPM版)
前言
ClickHouse是一个高性能的列式数据库,专为在线分析处理(OLAP)而设计。它能够实时生成分析数据报告,并支持对大数据进行快速的查询。本文将带你一步步完成ClickHouse的单机安装部署,确保你能够顺利上手这个强大的数据库系统。
第1步:下载RPM文件(下面有下载地址以及对应rpm文件截图)
RPM与GZ包的区别
-
文件类型:
- RPM:二进制文件格式,用于RedHat、CentOS等基于RPM包管理器的Linux发行版。
- GZ:压缩文件格式,通常用于源代码或二进制可执行程序的发布。
-
安装方式:
- RPM:可通过命令行工具(如yum或rpm命令)或图形界面工具进行安装、升级和卸载。
- GZ:需先解压缩,然后根据程序的安装方式进行安装和配置。
-
依赖性检测:
- RPM:自动检测并处理安装所需的运行库和依赖项。
- GZ:需手动检查和安装所需的依赖项。
-
版本控制:
- RPM:可管理软件版本,支持安装多个版本的软件,方便升级和回滚。
- GZ:需手动管理不同版本的软件包。
下载地址
ClickHouse RPM 包下载
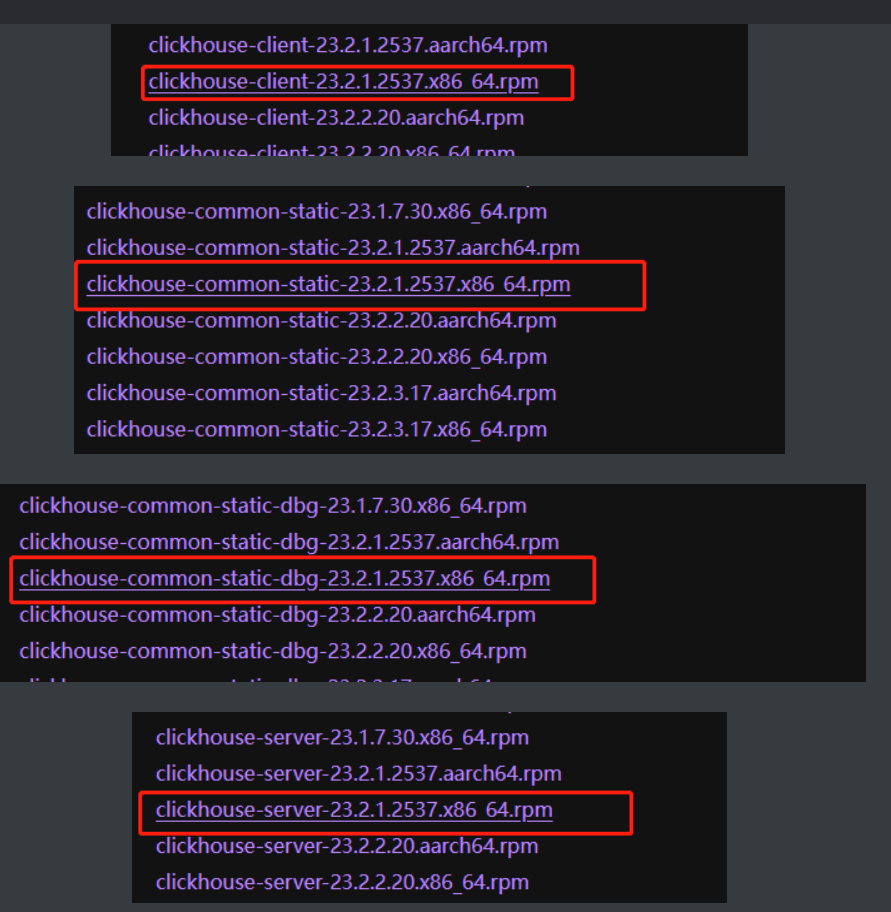
第2步:上传RPM文件到Linux
-
将下载的RPM文件上传到Linux系统的指定目录,例如

-
使用
mkdir命令创建目录(如果目录不存在):mkdir -p /usr/local/soft/clickhouse-rpms -
使用
scp或rsync等工具将RPM文件从本地上传到Linux服务器。
第3步:开始安装
安装前的准备
- 确保你的Linux系统是基于RPM的发行版,如CentOS或RedHat。
- 确保你有足够的权限(如root权限)来执行安装命令。
安装步骤
-
进入目录:
cd /usr/local/soft/clickhouse-install -
使用rpm命令安装:
sudo rpm -ivh *.rpm- 注意:安装过程需要输入密码,建议使用简单的密码如
123456。
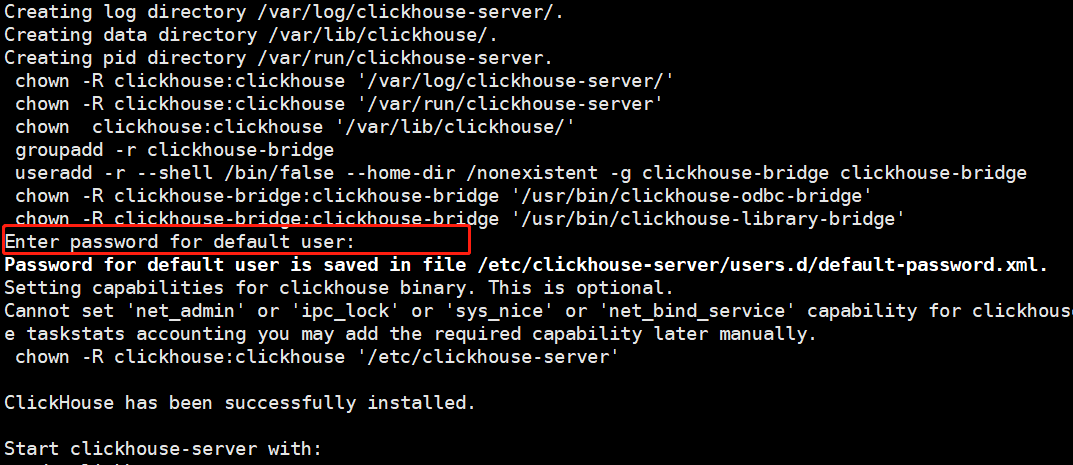
- 注意:安装过程需要输入密码,建议使用简单的密码如
-
启动服务:
systemctl start clickhouse-server -
查看服务状态:
systemctl status clickhouse-server- 确认服务是否成功启动。
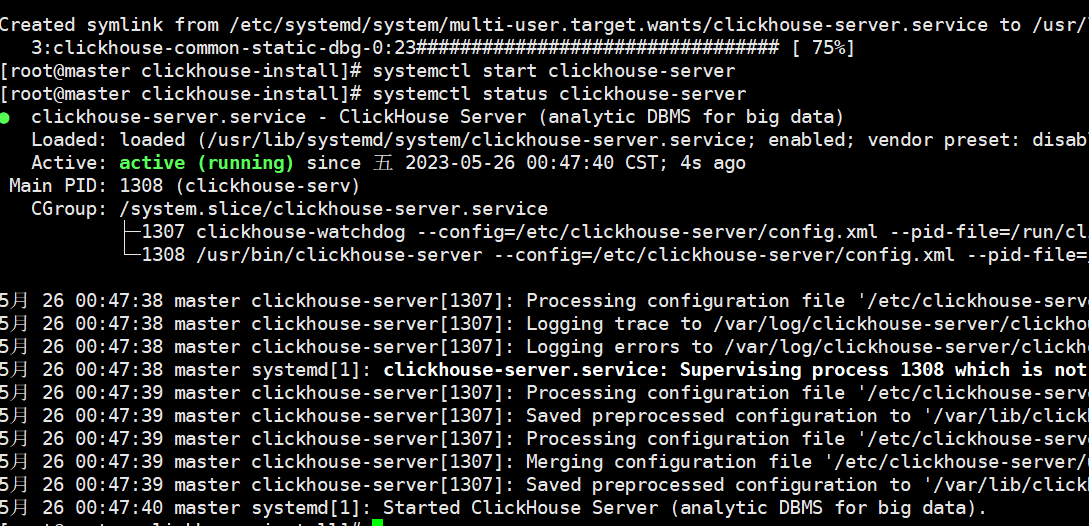
- 确认服务是否成功启动。
-
停止服务(如果需要):
systemctl stop clickhouse-server -
重启服务(如果需要,也可以停掉服务再启动):
systemctl restart clickhouse-server注意
安装时输入密码
在安装过程中,系统会提示输入密码,输入时不会显示。这是正常现象,只需输入你设置的密码即可。
运行成功状态
安装成功后,你可以通过查看服务状态来确认ClickHouse是否成功运行。如果服务状态显示为active (running),则表示服务正在运行。
第4步:远程工具连接
修改配置文件
-
打开ClickHouse配置文件:
vim /etc/clickhouse-server/config.xml -
搜索并放开下面配置的注释:
<listen_host>0.0.0.0</listen_host>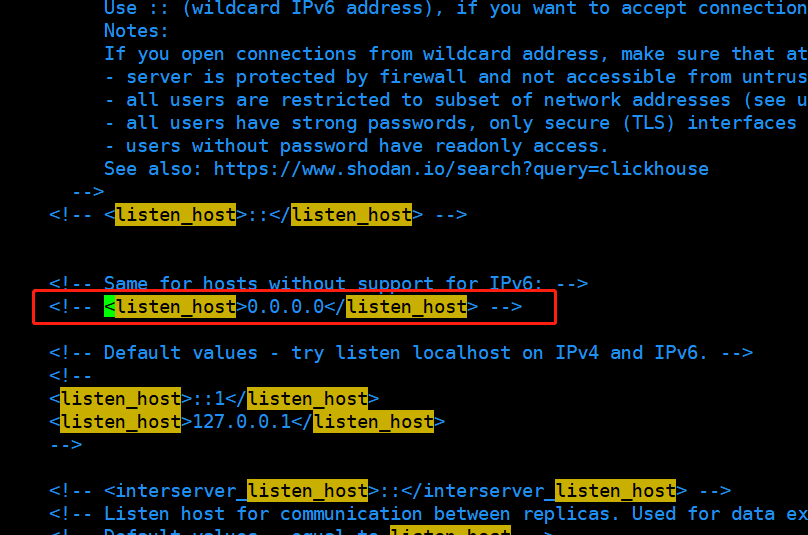
- 这一步是为了允许ClickHouse服务接受来自任何IP地址的连接。
-
保存并退出:
:wq! -
重启ClickHouse服务:
systemctl restart clickhouse-server注意
修改配置文件的时候可以更改端口号,clickhouse的端口号会与hadoop的端口号冲突(都是9000),在配置文件后面可以找到,将9000改为9001(不要和其他端口号冲突即可),新手可以不做修改,不会影响使用。
使用DBeaver连接
-
打开DBeaver,新建连接,选择ClickHouse。

-
点击“下一步”,设置JDBC连接,配置主机、用户名和密码。
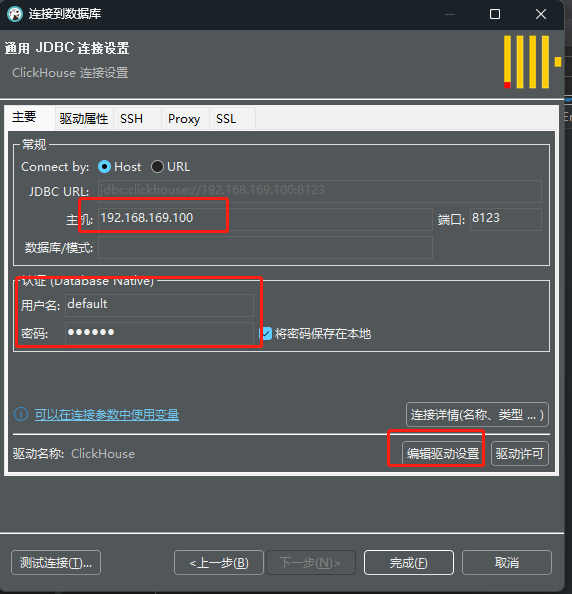
-
点击“编辑驱动设置”,配置ClickHouse驱动包。下载完成后,点击“确定”。
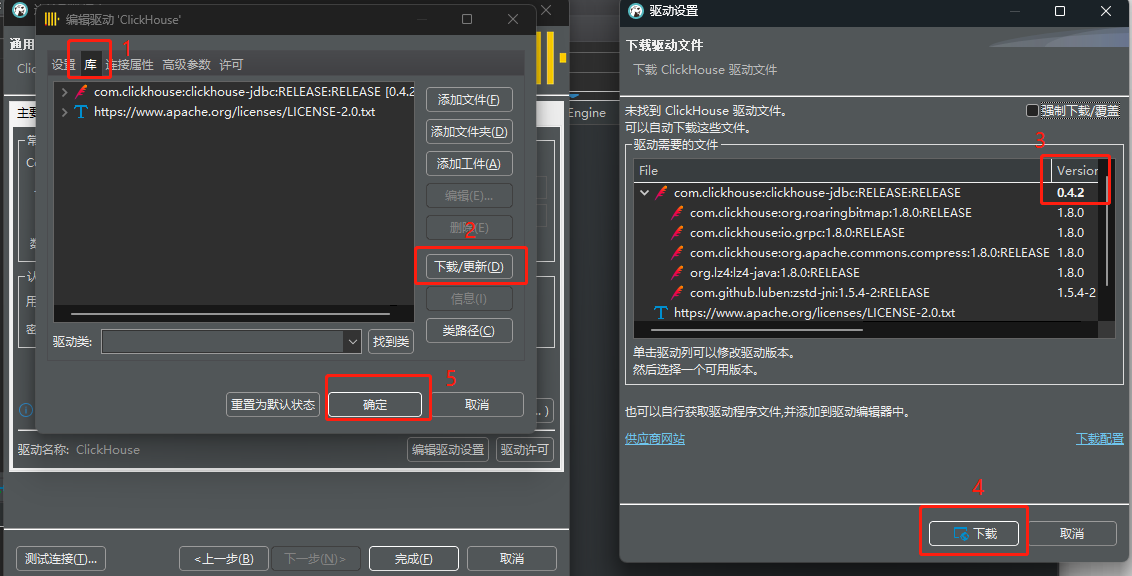
-
测试连接。如果连接成功,你将看到连接状态为“成功”。
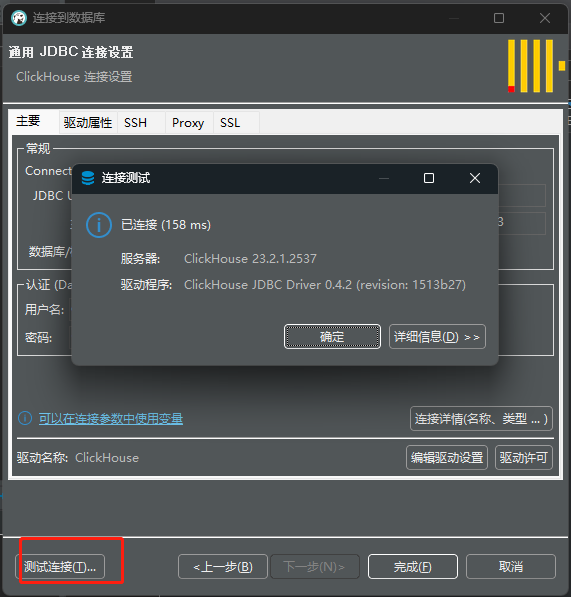
连接成功后的操作
连接成功后,你就可以开始使用DBeaver或其他支持ClickHouse的客户端工具来操作ClickHouse数据库了。
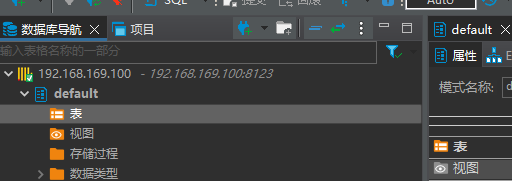
第5步:学习新组件的方式
学习数据库(如Hbase, ClickHouse等)
- 了解数据库的分类、特点、特性、历史背景、应用场景。
- 安装(单机版、集群部署),启动,修改配置文件,查看状态。
- 学习如何建库、建表。
- 了解数据类型。
- 学习函数,特别是特有函数。
- 尝试自己写一个分析案例。
- 学习数据库的特性,独有的特有功能,架构等高级用法。
- 使用Java、Python、Scala等语言连接数据库进行操作。
学习框架组件(如Hadoop, Hive, Spark等)
- 找到官网,了解组件的概述,了解组件能干什么,适用于什么场景。
- 安装(单机版、集群部署),启动,修改配置文件,查看状态。
- 配置环境变量。
- 学习架构,熟悉架构中的小组件,熟悉组件的工作原理。
- 使用一个小案例,将组件跑通。
- 思考与其他组件结合的方式。
- 使用Java、Python、Scala等语言操作组件,跑通一个案例。
学习平台(如阿里云DataWorks, 袋鼠云的平台,Dophinscheduler等)
- 找到官网,熟悉平台能做什么,尝试注册账号。
- 看文档,操作平台,完成一个最小的案例。
- 部分平台可以在Linux中搭建,尝试搭建一下。
- 使用Java、Python、Scala等语言,连接平台并操作。
通过以上步骤,你可以系统地学习和掌握ClickHouse的安装、配置和使用,以及如何与其他组件和平台结合使用。这将为你在大数据处理和分析领域打下坚实的基础。