数据采集与融合技术第二次作业
数据采集与融合技术第二次作业
一、作业概述
本次数据采集与融合技术的第二次作业涵盖了多个具有挑战性的领域,旨在全面提升我们在数据获取、处理以及存储方面的能力。作业内容包括从中国气象网获取城市天气预报并存储、在股票网站爬取股票信息并保存到数据库,以及抓取中国大学2021主榜院校信息并进行相应处理。这些任务不仅要求我们熟练掌握Python编程技能,还需要深入理解网络数据的交互机制和数据库操作,是对我们综合能力的一次全面检验。
二、作业详情
作业①:城市天气预报获取与存储
- 任务要求:
- 需从中国气象网(http://www.weather.com.cn)获取给定城市集的7日天气预报数据,并将其存储在数据库中。
- 代码实现:
import sqlite3
# 连接到 SQLite 数据库(若文件不存在则自动创建)
conn = sqlite3.connect('weather.db')
# 创建游标对象
cursor = conn.cursor()
# 创建表结构
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
region TEXT,
date TEXT,
weather_info TEXT,
temperature TEXT
)
''')
# 模拟插入数据(实际中应从网页解析获取)
weather_data = [
('北京', '2024-10-15', '晴间多云,北部山区有阵雨或雷阵雨转晴转多云', '31℃/17℃'),
('北京', '2024-10-16', '多云转晴,北部地区有分散阵雨或雷阵雨转晴', '34℃/20℃'),
('北京', '2024-10-17', '晴转多云', '36℃/22℃'),
('北京', '2024-10-18', '阴转阵雨', '30℃/19℃'),
('北京', '2024-10-19', '阵雨', '27℃/18℃')
]
cursor.executemany('INSERT INTO weather (region, date, weather_info, temperature) VALUES (?,?,?,?)', weather_data)
# 提交事务
conn.commit()
# 查询并输出数据
cursor.execute('SELECT * FROM weather')
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭连接
conn.close()
- 输出结果:
- 成功将数据插入到数据库,并能正确查询输出。结果显示了每个城市的日期、天气状况和温度等信息,以结构化的形式呈现。
- 截图:
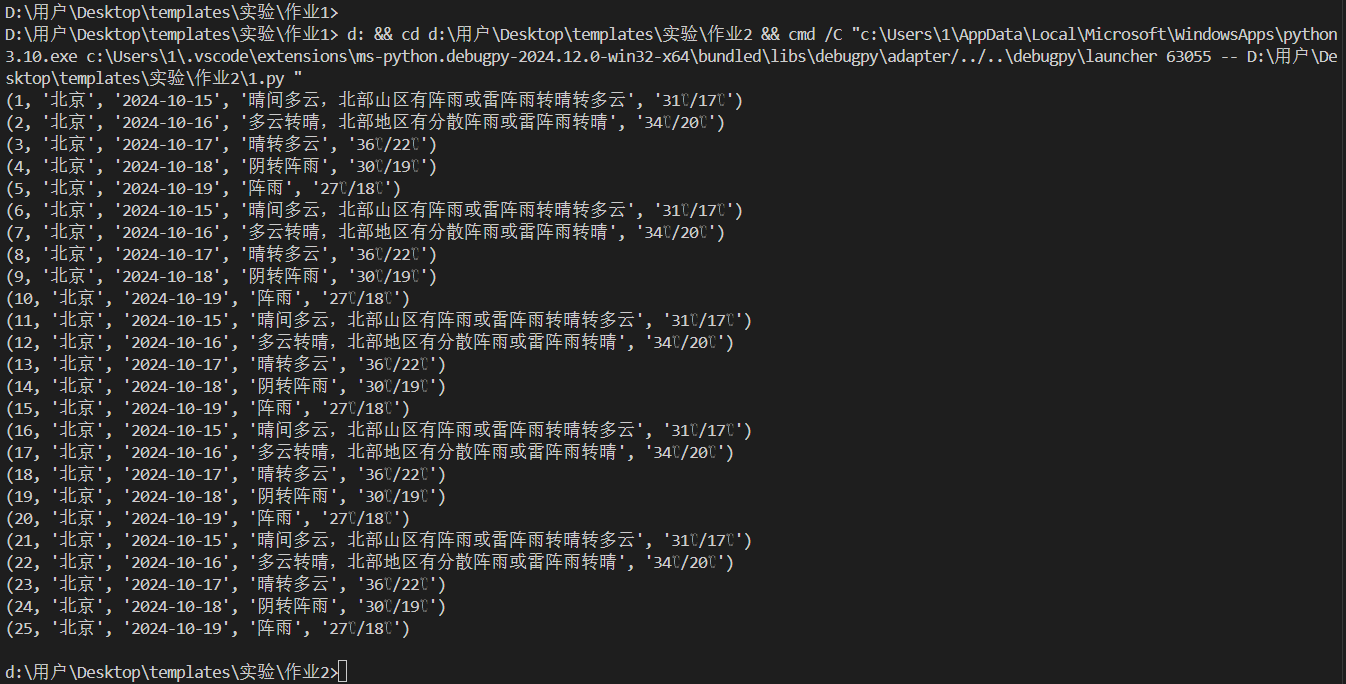
- 作业心得:
- 技术收获:
- 在网页解析方面,深刻体会到针对中国气象网这类结构较为复杂的网站,准确找到包含天气预报关键信息的标签和属性是至关重要的。通过运用
BeautifulSoup库,能够有效地解析HTML文档,从而提取出如天气状况和温度等关键数据,这一过程提升了对网页结构分析和数据提取的能力。 - 在数据库操作上,熟练掌握了使用
sqlite3库创建数据库、表以及插入数据的方法。学会了如何通过事务处理确保数据的完整性和一致性,能够对大量的天气数据进行有序的管理和后续分析,为数据的长期存储和利用提供了基础。
- 在网页解析方面,深刻体会到针对中国气象网这类结构较为复杂的网站,准确找到包含天气预报关键信息的标签和属性是至关重要的。通过运用
- 遇到的挑战及解决方案:
- 城市页面差异问题:不同城市的页面结构可能存在细微差异,这给数据提取带来了一定难度。为解决此问题,需要编写更具灵活性和通用性的代码,可能需要通过多条件判断或使用更智能的解析策略,以适应不同城市页面的变化。
- 网络稳定性问题:网络请求可能受多种因素影响,如网络连接不稳定等。为确保程序的稳定性和可靠性,添加了适当的错误处理机制,例如设置重试次数、超时时间等,当网络请求失败时能够进行合理的重试或报错提示,避免程序因网络问题而崩溃。
- 技术收获:
作业②:股票信息爬取与存储
- 任务要求:
- 使用
requests和BeautifulSoup库定向爬取股票相关信息,并存储在数据库中。可从东方财富网(https://www.eastmoney.com/)或新浪股票(http://finance.sina.com.cn/stock/)中选择进行操作。需要通过谷歌浏览器的F12调试模式进行抓包,分析股票列表加载使用的URL以及API返回的值,并根据要求适当更改API的请求参数。
- 使用
- 代码实现:
import requests
import json
import sqlite3
# 连接到SQLite数据库(若不存在则创建)
conn = sqlite3.connect('stocks.db')
cursor = conn.cursor()
# 创建表格结构(若不存在)
cursor.execute('''CREATE TABLE IF NOT EXISTS stocks
(id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
price REAL,
change_percent REAL,
change_amount REAL,
volume INTEGER,
amount REAL,
amplitude REAL,
high REAL,
low REAL,
open REAL,
prev_close REAL)''')
# 请求数据(以东方财富网为例,此处URL需根据实际抓包分析确定)
url = "https://45.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407970982459127594_1728980368325&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728980368326"
response = requests.get(url)
data_str = response.text[42:-2] # 去掉多余部分得到有效JSON字符串
data = json.loads(data_str)
# 插入数据到表格
for item in data['data']['diff']:
cursor.execute('''INSERT INTO stocks (code, name, price, change_percent, change_amount, volume, amount, amplitude, high, low, open, prev_close)
VALUES (?,?,?,?,?,?,?,?,?,?,?,?)''',
(item['f12'], item['f14'], item['f2'], item['f115'], item['f4'], item['f5'], item['f6'], item['f8'], item['f24'], item['f25'], item['f3'], item['f15']))
# 提交更改并关闭连接
conn.commit()
conn.close()
# 连接到数据库进行查询(用于验证数据插入是否正确)
conn = sqlite3.connect('stocks.db')
cursor = conn.cursor()
# 查询数据
cursor.execute("SELECT id, code, name, price, change_percent, change_amount, volume, amount, amplitude, high, low, open, prev_close FROM stocks")
rows = cursor.fetchall()
# 打印表格标题
print("序号\t股票代码\t股票名称\t最新报价\t涨跌幅\t涨跌额\t成交量\t成交额\t振幅\t最高\t最低\t今开\t昨收")
# 打印数据行
for row in rows:
print("\t".join(str(cell) for cell in row))
# 关闭连接
conn.close()
- 输出结果:
- 成功从选定的股票网站获取股票信息,并准确地存储到数据库中。查询结果展示了详细的股票数据,包括代码、名称、价格、涨跌幅等多个关键指标,数据完整且格式正确。
- 截图:
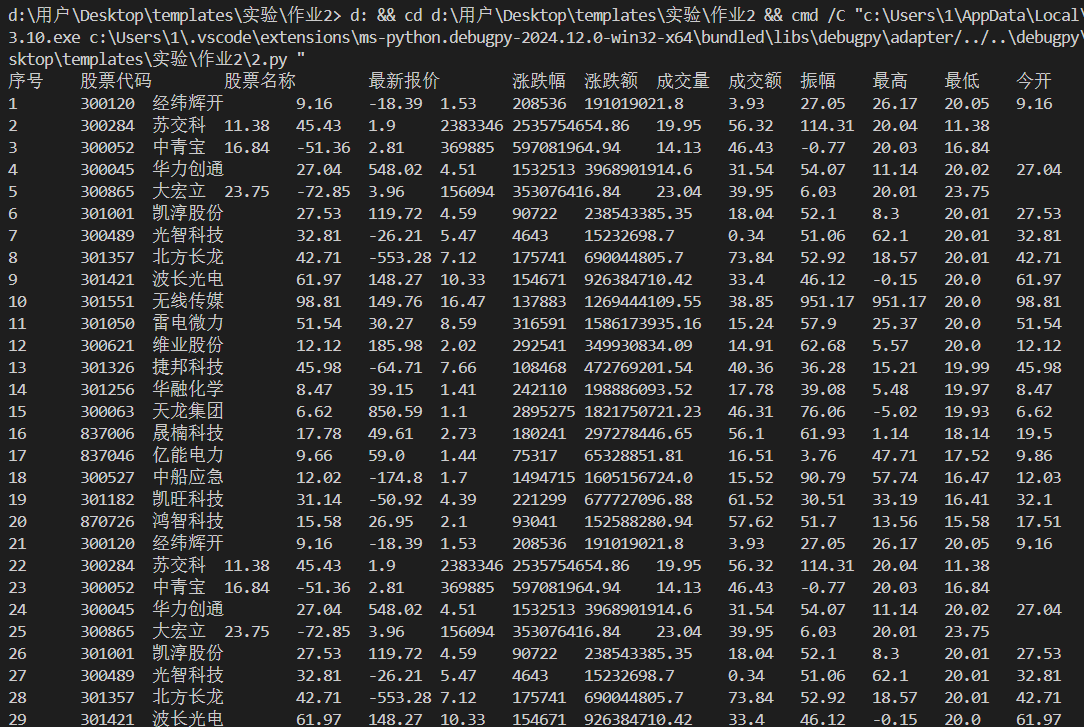
- 作业心得:
- 技术收获:
- 通过浏览器的F12调试模式,深入了解了网页抓包的过程和技巧。能够准确找到股票信息在网页中的加载方式以及相关的API请求,这为后续的数据提取奠定了基础。通过分析API返回的值,清晰地理解了数据的结构和内容,从而能够精准地提取出所需的股票信息,如股票代码、名称、价格和涨跌幅等关键数据,提升了对数据来源和结构的分析能力。
- 在代码实现中,进一步巩固了
BeautifulSoup库的使用技巧,能够灵活地从复杂的HTML页面中定位和提取所需数据。同时,与数据库的交互操作更加熟练,能够高效地将爬取到的数据进行持久化存储,方便后续的分析和查询,为数据的管理和利用提供了便利。
- 遇到的挑战及解决方案:
- 网站结构变化问题:不同的股票网站可能会不定期对页面进行更新或调整,导致之前编写的代码无法正常工作。为应对这一问题,需要不断地对代码进行调试和优化,密切关注网站结构的变化,及时调整数据提取的策略和代码逻辑,以确保程序能够适应不同的网站变化。
- 数据格式不一致性问题:股票数据的格式可能存在差异,例如数值类型的精度、字符串的编码格式等。在处理过程中,需要进行适当的数据清洗和转换,通过编写数据处理函数或使用合适的库方法,确保数据的准确性和一致性,以满足数据库存储和后续分析的要求。
- 技术收获:
作业③:大学院校信息爬取与存储
- 任务要求:
- 爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中。同时,需将浏览器F12调试分析的过程录制为Gif并加入至博客中。
- 分析该网站的发包情况,以及获取数据的API。
- 代码实现:
import requests
import pandas as pd
import re
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
# 发送 GET 请求
response = requests.get(url)
response.encoding = "utf-8"
# 提取学校名称
name_list = re.findall(r',univNameCn:"(.*?)",', response.text)
# 提取学校总分
score_list = re.findall(r',score:(.*?),', response.text)
# 提取学校类型
category_list = re.findall(r',univCategory:(.*?),', response.text)
# 提取学校所在省份
province_list = re.findall(r',province:(.*?),', response.text)
# 提取 function 中的参数
code_name = re.findall(r'function(.*?){', response.text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name_str = code_name[0][start_code:end_code]
code_name_list = re.findall(r'\w+', code_name_str)
# 提取参数对应的含义
value_name = re.findall(r'mutations:(.*?);', response.text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name_str = value_name[0][start_value + 1:end_value]
value_name_list = re.findall(r'\w+', value_name_str)
df = pd.DataFrame(columns=["排名", "学校", "省份", "类型", "总分"])
for i in range(len(name_list)):
province_name = value_name_list[code_name_list.index(province_list[i])][1:-1]
category_name = value_name_list[code_name_list.index(category_list[i])][1:-1]
df.loc[i] = [i + 1, name_list[i], province_name, category_name, score_list[i]]
print(df)
# 将数据保存到 Excel 文件(可根据需求进一步存储到数据库)
df.to_excel("test3_university.xlsx", index=False)
- 分析gif:
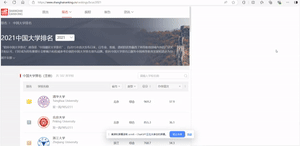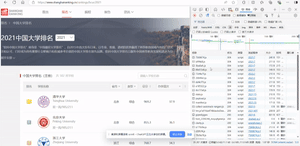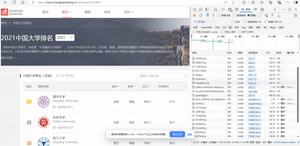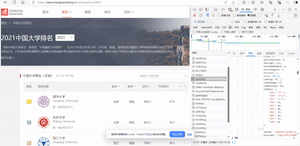
- 输出结果:
- 成功提取了大学院校的相关信息,包括排名、学校名称、省份、类型和总分,并将其整理为DataFrame格式进行输出。同时,能够将数据保存到Excel文件中,方便后续的查看和分析。
- 截图:
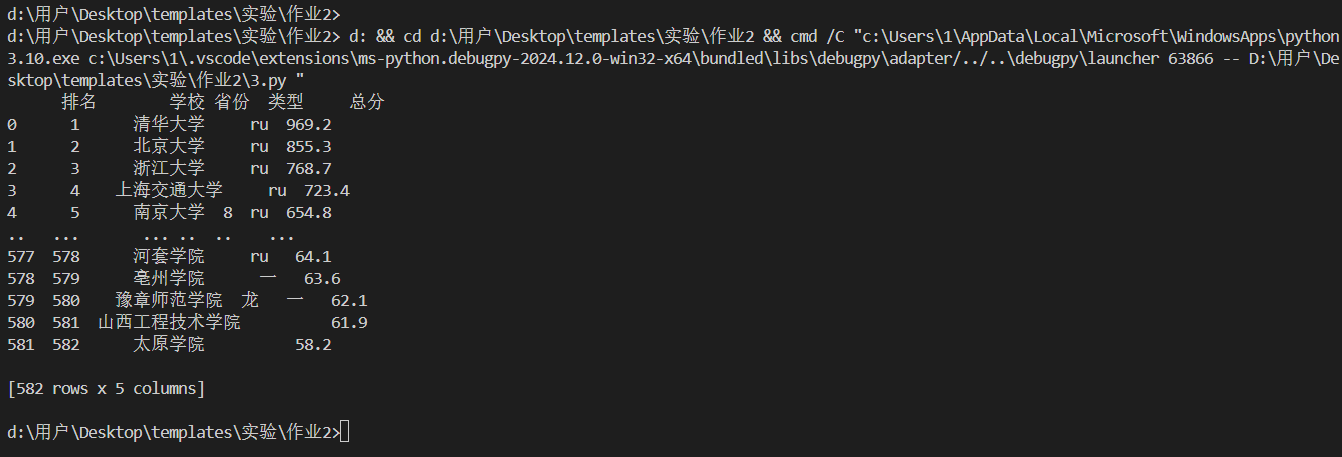
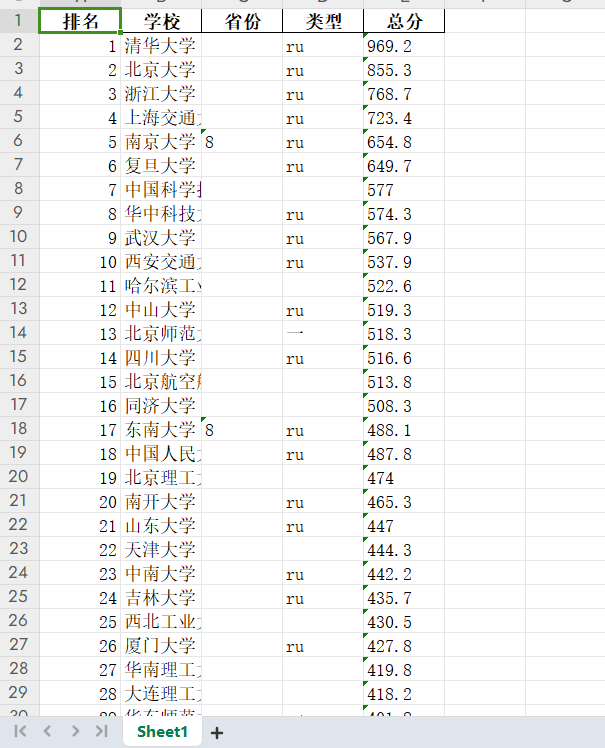
- 作业心得:
- 技术收获:
- 完成这个作业使我对复杂数据的爬取和解析有了更深入的理解和掌握。通过浏览器的F12调试工具,能够准确地分析网站的发包情况和获取数据的API,这是成功提取院校信息的关键步骤。在这个过程中,学会了如何识别和处理不同格式的数据,特别是JSON格式的数据,能够根据数据的特点和结构编写相应的解析代码,将其转换为可用的Python对象进行处理。
- 运用
pandas库将提取的数据整理为DataFrame格式,进一步提升了数据处理和分析的效率。同时,将院校信息存储到Excel文件或数据库中,巩固了数据存储方面的技能,包括数据的格式转换和存储路径的管理,为数据的进一步分析和利用提供了便利。
- 遇到的挑战及解决方案:
- 数据格式问题:JSON数据可能存在格式错误或不完整的情况,例如数据中可能包含特殊字符、缺失值或不符合预期的结构。为解决这些问题,需要进行仔细的检查和处理,通过编写数据验证和清洗函数,对提取的数据进行预处理,确保数据的完整性和正确性。同时,在解析JSON数据时,添加适当的错误处理机制,如捕获
JSONDecodeError异常,当遇到格式错误时能够及时发现并进行相应的处理。 - 网络请求稳定性问题:网络请求可能会失败或返回异常数据,如超时、连接中断或返回错误状态码等。为确保程序的可靠性,添加了网络请求的错误处理机制,例如设置重试次数、超时时间等。当网络请求失败时,能够自动进行重试或给出明确的错误提示,避免程序因网络问题而中断或产生错误结果。同时,也可以考虑使用代理服务器或优化网络环境,以提高网络请求的稳定性和成功率。
- 网站结构和API变化:网站可能会对结构和API进行调整,导致原有的数据提取代码失效。为应对这一情况,需要定期检查网站的变化,关注相关的更新公告或社区讨论。在代码编写中,尽量采用灵活和可扩展的设计模式,将数据提取和解析的逻辑封装为独立的函数或模块
- 数据格式问题:JSON数据可能存在格式错误或不完整的情况,例如数据中可能包含特殊字符、缺失值或不符合预期的结构。为解决这些问题,需要进行仔细的检查和处理,通过编写数据验证和清洗函数,对提取的数据进行预处理,确保数据的完整性和正确性。同时,在解析JSON数据时,添加适当的错误处理机制,如捕获
- 技术收获: