Summary Functions and Maps(pandas学习三)
Summary functions
reviews()
输出如下:
| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Italy | Aromas include tropical fruit, broom, brimston... | Vulkà Bianco | 87 | NaN | Sicily & Sardinia | Etna | NaN | Kerin O’Keefe | @kerinokeefe | Nicosia 2013 Vulkà Bianco (Etna) | White Blend |
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 129969 | France | A dry style of Pinot Gris, this is crisp with ... | NaN | 90 | 32.0 | Alsace | Alsace | NaN | Roger Voss | @vossroger | Domaine Marcel Deiss 2012 Pinot Gris (Alsace) | Pinot Gris |
| 129970 | France | Big, rich and off-dry, this is powered by inte... | Lieu-dit Harth Cuvée Caroline | 90 | 21.0 | Alsace | Alsace | NaN | Roger Voss | @vossroger | Domaine Schoffit 2012 Lieu-dit Harth Cuvée Car... | Gewürztraminer |
129971 rows × 13 columns
-
Pandas提供了许多简单的“Summary functions”(不是官方名称),它们以某种有用的方式重组数据。例如,考虑
describe()方法:reviews.points.describe()输出如下:
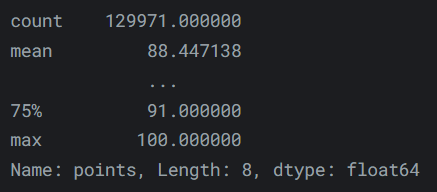
-
此方法生成给定列属性的高级摘要。它是类型感知的,这意味着其输出会根据输入的数据类型而变化。上面的输出仅对数值数据有意义;对于字符串数据,我们得到的是:
reviews.taster_name.describe()输出如下:
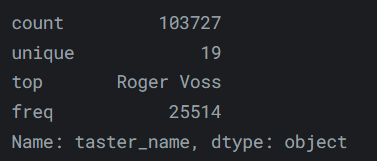
-
如果你想获得关于
DataFrame或Series中某一列的特定简单汇总统计信息,通常会有一个有用的 pandas 函数来实现。-
例如,要查看分数的平均值(例如,平均评级的葡萄酒表现如何),我们可以使用
mean()函数:reviews.points.mean()输出如下:

-
要查看唯一值列表,我们可以使用
unique()函数。reviews.taster_name.unique()输出如下:

-
要查看数据集中的唯一值列表以及它们出现的频率,可以使用
value_counts()方法:reviews.taster_name.value_counts()输出如下:
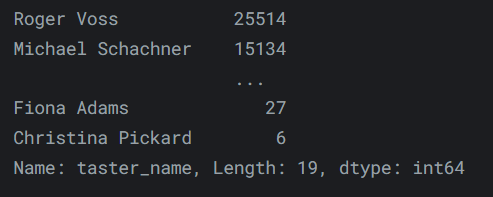
-
Maps
-
在数学中借用的术语
map指的是一种函数,它接收一组值并将其“映射”到另一组值。在数据科学中,我们经常需要从现有数据创建新的表示形式,或者将数据从当前的格式转换为我们以后想要的格式。Maps(映射)就是处理这项工作的工具,因此它们对于完成你的工作极其重要! -
有两种映射方法是你会经常使用的。
-
map()是第一个,也是稍微简单一点的那个。例如,假设我们想将葡萄酒获得的分数重新调整为 0。我们可以如下操作:review_points_mean = reviews.points.mean() reviews.points.map(lambda p: p - review_points_mean)输出如下:
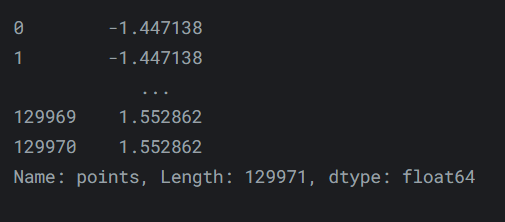
传递给map()的函数应该是Series中的单个值(在上面的示例中是point值),并返回该值的转换版本。map()返回一个新的Series,其中所有值都已由您的函数转换。 -
如果我们想通过在每一行上调用自定义方法来转换整个
DataFrame,则apply()是等效的方法。def remean_points(row): row.points = row.points - review_points_mean return row reviews.apply(remean_points, axis='columns')输出如下:
country description designation points price province region_1 region_2 taster_name taster_twitter_handle title variety winery 0 Italy Aromas include tropical fruit, broom, brimston... Vulkà Bianco -1.447138 NaN Sicily & Sardinia Etna NaN Kerin O’Keefe @kerinokeefe Nicosia 2013 Vulkà Bianco (Etna) White Blend 1 Portugal This is ripe and fruity, a wine that is smooth... Avidagos -1.447138 15.0 Douro NaN NaN Roger Voss @vossroger Quinta dos Avidagos 2011 Avidagos Red (Douro) Portuguese Red ... ... ... ... ... ... ... ... ... ... ... ... ... 129969 France A dry style of Pinot Gris, this is crisp with ... NaN 1.552862 32.0 Alsace Alsace NaN Roger Voss @vossroger Domaine Marcel Deiss 2012 Pinot Gris (Alsace) Pinot Gris 129970 France Big, rich and off-dry, this is powered by inte... Lieu-dit Harth Cuvée Caroline 1.552862 21.0 Alsace Alsace NaN Roger Voss @vossroger Domaine Schoffit 2012 Lieu-dit Harth Cuvée Car... Gewürztraminer 129971 rows × 13 columns
-
如果我们使用
axis='index'调用reviews.apply(),那么我们就不需要传递一个函数来转换每一行,而是需要提供一个函数来转换每一列。 -
请注意,
map()和apply()分别返回新的、转换后的Series和DataFrame。它们不会修改调用它们的原始数据。如果我们查看第一行评论,我们可以看到它仍然具有其原始分数值。reviews.head(1)输出如下:
country description designation points price province region_1 region_2 taster_name taster_twitter_handle title variety winery 0 Italy Aromas include tropical fruit, broom, brimston... Vulkà Bianco 87 NaN Sicily & Sardinia Etna NaN Kerin O’Keefe @kerinokeefe Nicosia 2013 Vulkà Bianco (Etna) White Blend
-
-
Pandas 内置了许多常见的映射操作。
-
例如,下面是一种更快速地重新定义point列的方法:
review_points_mean = reviews.points.mean() reviews.points - review_points_mean输出如下:
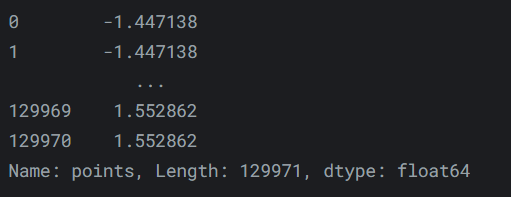
在这段代码中,我们在左侧的许多值(series中的所有内容)和右侧的单个值(平均值)之间执行操作。Pandas 查看这个表达式并推断出我们是想从数据集中的每个值中减去那个平均值。 -
如果我们在等长
series之间执行这些操作,Pandas 也会理解该怎么做。例如,在数据集中组合国家和地区信息的一种简单方法是执行以下操作reviews.country + " - " + reviews.region_1输出如下:
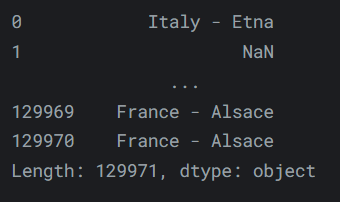
-
这些运算符比
map()或apply()更快,因为它们使用了 pandas 内置的加速功能。所有标准 Python 运算符(>、<、== 等)都以这种方式工作。 -
但是,它们不像
map()或apply()那样灵活,后者可以执行更高级的操作,例如应用条件逻辑,而这无法仅通过加法和减法来完成。
-