Indexing, Selecting & Assigning(pandas学习二)
Native accessors(原生访问器)
-
原生 Python 对象为索引数据提供了很好的方法。Pandas 继承了所有这些方法,这有助于轻松上手。
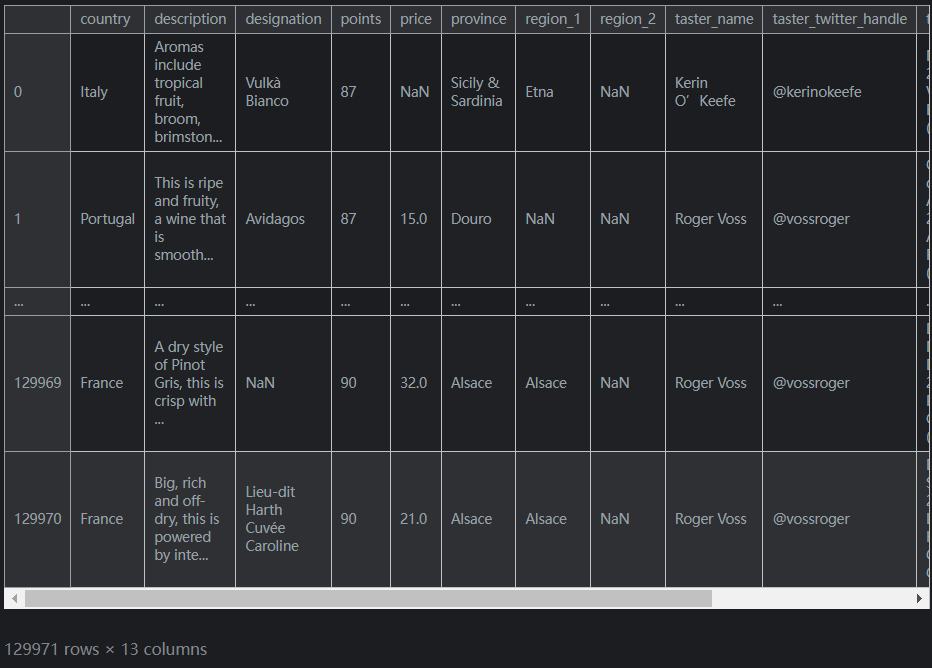
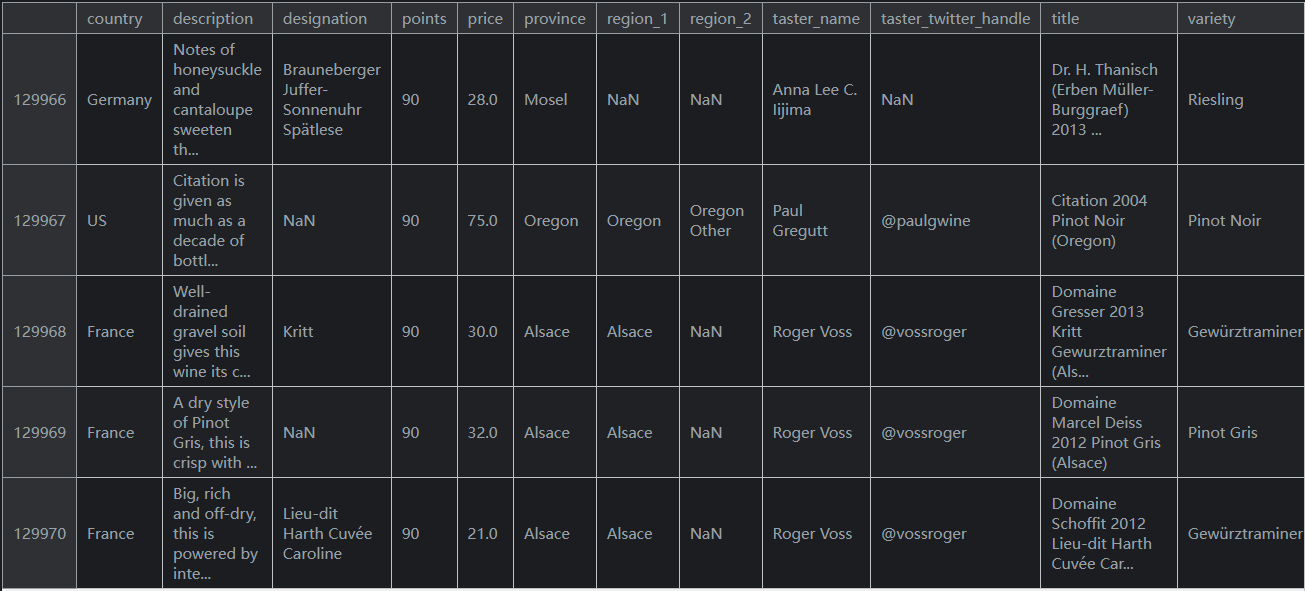
考虑这个DataFramereviews输出如下(未截全):
-
在Python中,我们可以通过将对象作为属性访问来访问它的属性。例如,book对象可能有一个title属性,我们可以通过调用book. title来访问它。DataFrame中的列的工作方式大致相同。
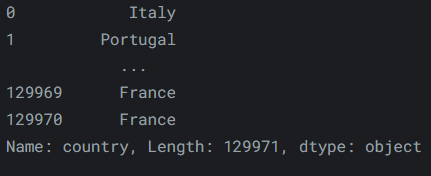
因此,要访问“reviews”的“country”属性,我们可以使用:reviews.country输出如下:
-
如果我们有Python字典,我们可以使用索引运算符
[]运算符访问它的值。我们可以对DataFrame中的列执行相同的操作:reviews['country']输出如下:
-
这些是从
DataFrame中选择特定序列的两种方法。它们在语法上没有谁比谁更正确,但是索引运算符[]确实有一个优势,即它可以处理包含保留字符的列名(例如,如果我们有一个“country providence”列,“reviews.country providence”将不起作用)。
- pandas看起来是不是有点像花哨的字典?几乎是这样,所以毫不奇怪,要深入到一个特定的值,我们只需要再次使用索引运算符
[]:
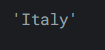
输出如下:reviews['country'][0]
-
Indexing in pandas(pandas 中的索引)
- 索引运算符和属性选择很不错,因为它们的工作方式与 Python 生态系统中的其他部分一样。对于新手来说,这使得它们易于掌握和使用。然而,Pandas 有自己的访问器运算符
loc和iloc。对于更高级的操作,这些是应该使用的运算符。
Index-based selection(基于索引的选择)
- Pandas索引工作在两种范式之一。第一个是基于索引的选择:根据数据中的数字位置选择数据。
iloc遵循这个范式。-
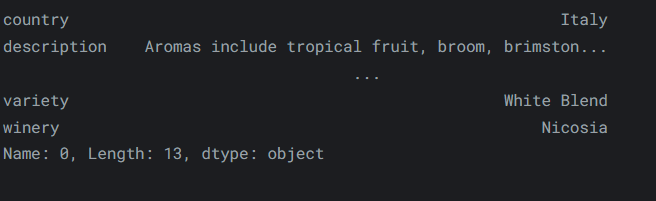
要选择
DataFrame中的第一行数据,我们可以使用以下方法:reviews.iloc[0]输出如下:
-
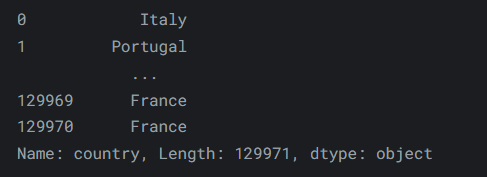
loc和iloc都是先行后列。这与我们在原生 Python 中的做法相反,原生 Python 是先列后行。这意味着检索行稍微容易一些,而检索列稍微困难一些。要使用iloc获取一列,我们可以执行以下操作:reviews.iloc[:, 0]输出如下:
-
单独来看,同样来自原生 Python 的“:”运算符表示“所有内容”。然而,当与其他选择器结合使用时,它可以用于表示一系列值。
-
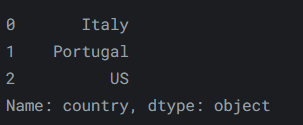
例如,要仅从第一行、第二行和第三行中选择“country”列,我们可以这样做:
reviews.iloc[:3, 0]输出如下:
-
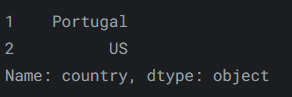
或者,若仅选择第二个和第三个条目,我们可以这样做:
reviews.iloc[1:3, 0]输出如下:
-
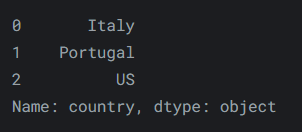
也可以传递一个列表。
reviews.iloc[[0, 1, 2], 0]输出如下:
-
最后,值得知道的是负数可以用于选择。这将从值的末尾开始向前计数。例如,这是数据集的最后五个元素。
reviews.iloc[-5:]输出如下(列方面没截全):
-
-
Label-based selection(基于标签的选择)
- 属性选择的第二个范例是
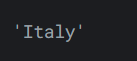
loc运算符遵循的范例:基于标签的选择。在这个范例中,重要的是数据索引值,而不是它的位置。- 例如,要获取 reviews 中的第一个条目,我们现在可以按如下方式进行:
输出如下:reviews.loc[0, 'country']
- 例如,要获取 reviews 中的第一个条目,我们现在可以按如下方式进行:
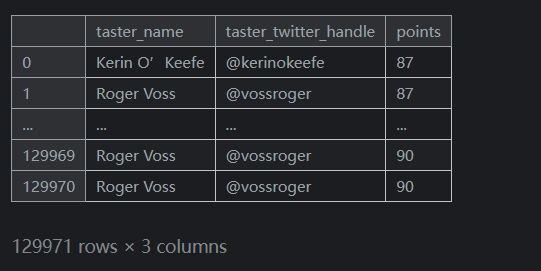
iloc在概念上比loc简单,因为它忽略了数据集的索引。当我们使用iloc时,我们将数据集视为一个大矩阵(列表的列表),我们必须按位置索引。相比之下,loc使用索引中的信息来完成其工作。由于您的数据集通常具有有意义的索引,因此使用loc通常更容易做事。例如,这里有一个使用loc更容易的操作:
输出如下:reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
Choosing between loc and iloc(在loc和iloc之间选择)
-
在
loc和iloc之间选择或转换时,有一个“明白”值得记住,那就是这两种方法使用略有不同的索引方案。 -
iloc使用 Python 标准库的索引方案,范围的第一个元素被包含在内,而最后一个元素被排除在外。所以 0:10 将选择条目 0,……,9。同时,loc是包含性索引。所以 0:10 将选择条目 0,……,10。 -
为什么会有这种变化呢?请记住,
loc可以对任何标准库类型进行索引,例如字符串。如果我们有一个DataFrame,其索引值为Apples, ..., Potatoes, ...,并且我们想要选择“在‘Apples’和‘Potatoes’之间所有按字母顺序排列的水果选项”,那么使用df.loc['Apples':'Potatoes']进行索引比使用类似df.loc['Apples', 'Potatoet'](在字母表中t在s之后)要方便得多。 -
当
DataFrame的索引是一个简单的数字列表时,这尤其令人困惑,例如 0,…,1000。在这种情况下,df.iloc[0:1000]将返回 1000 个条目,而df.loc[0:1000]将返回 1001 个条目!要使用loc获取 1000 个元素,你需要将范围缩小一个,请求df.loc[0:999]。
Manipulating the index(操纵索引)
- 基于标签的选择依靠索引中的标签。关键是,我们使用的索引并非不可变的。我们可以以任何我们认为合适的方式操作索引。
set_index()方法可用于完成这项工作。以下是当我们将索引设置为“title”字段时会发生的情况:
输出如下:reviews.set_index("title")
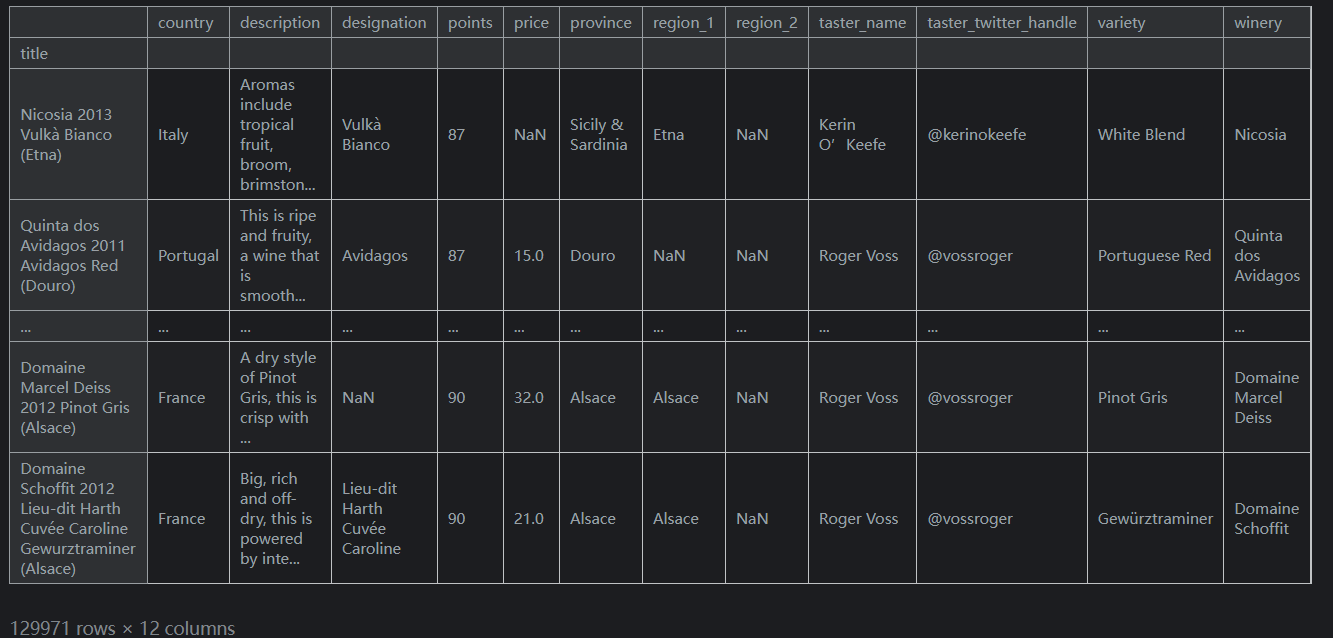
如果您能为数据集提出比当前索引更好的索引,这将很有用。
Conditional selection(条件选择)
- 到目前为止,我们一直在使用
DataFrame本身的结构属性索引各种数据。然而,要对数据做有趣的事情,我们经常需要根据条件提出问题。-
例如,假设我们特别对意大利生产的高于平均水平的葡萄酒感兴趣。
-
我们可以先检查每一种葡萄酒是否是意大利产的:
reviews.country == 'Italy'输出如下:
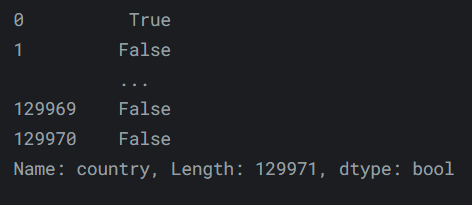
-
此操作根据每条记录的国家/地区生成一系列
True/False布尔值。然后可以在loc内部使用此结果来选择相关数据:reviews.loc[reviews.country == 'Italy']输出如下:
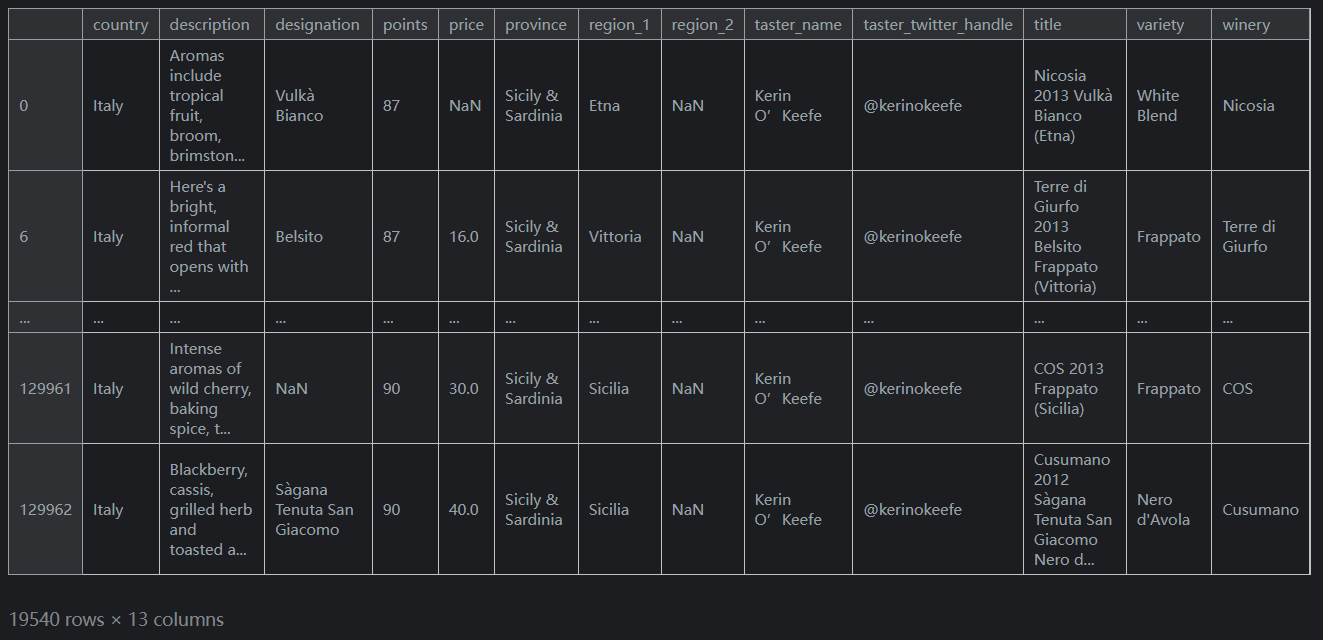
-
这个
DataFrame有大约20,000行。原来有大约130,000行。这意味着大约15%的葡萄酒来自意大利。
我们也想知道哪些葡萄酒比平均水平更好。葡萄酒的评分范围是 80 到 100 分,所以这可能意味着至少获得 90 分的葡萄酒。
我们可以使用&符号将这两个问题结合起来。reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]输出如下:
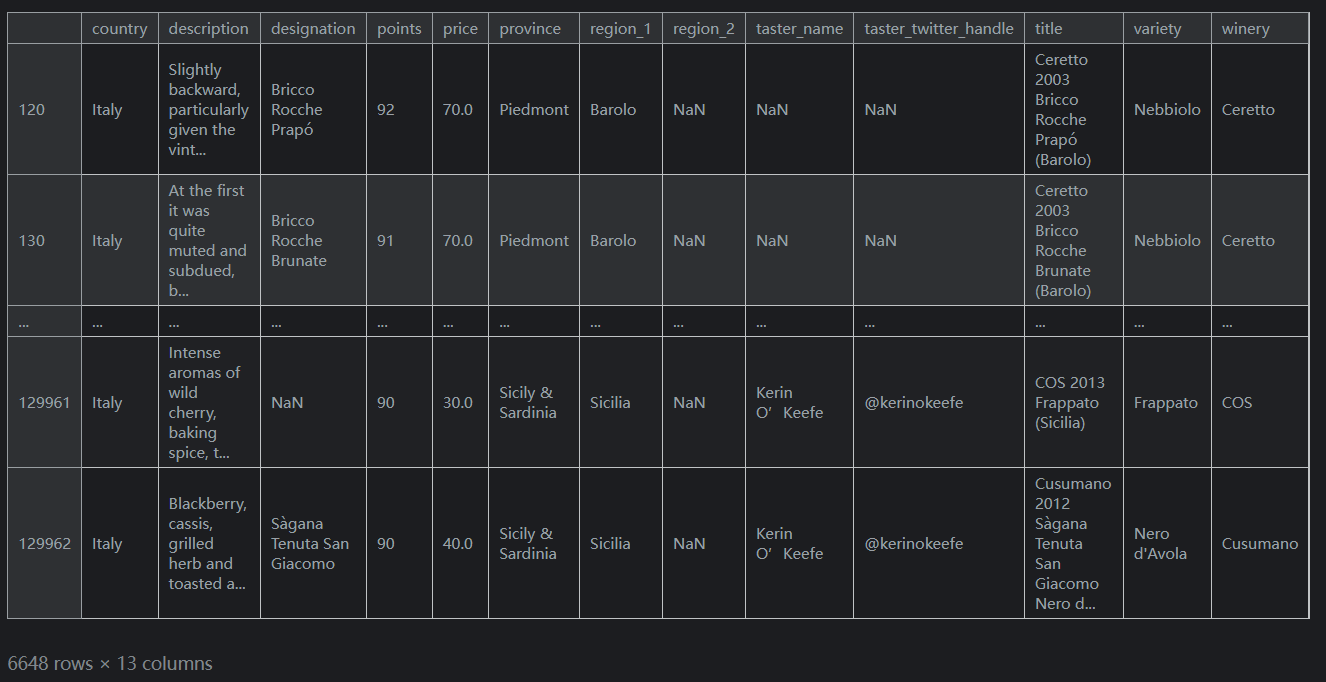
-
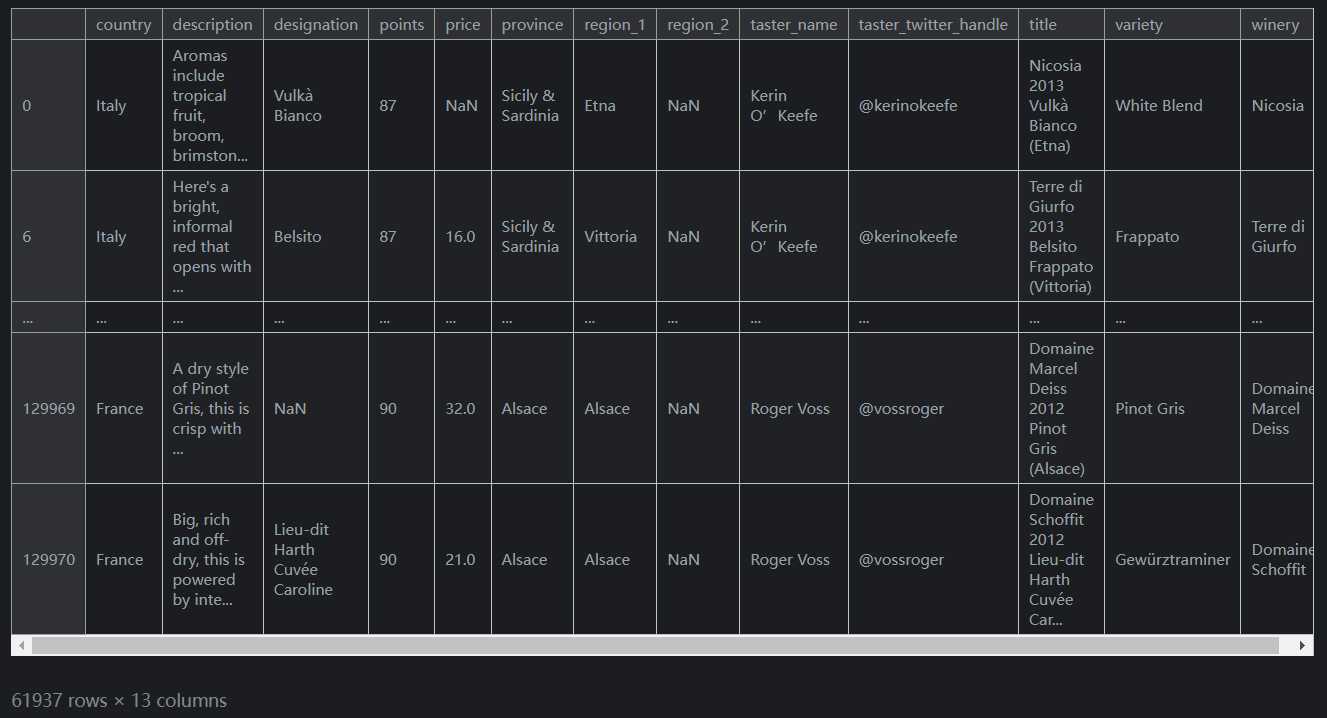
假设我们将购买任何意大利制造的葡萄酒或评级高于平均水平的葡萄酒。为此,我们使用
|符号:reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]输出如下:
-
-
Pandas 带有一些内置的条件选择器,我们将在这里重点介绍其中两个。
-
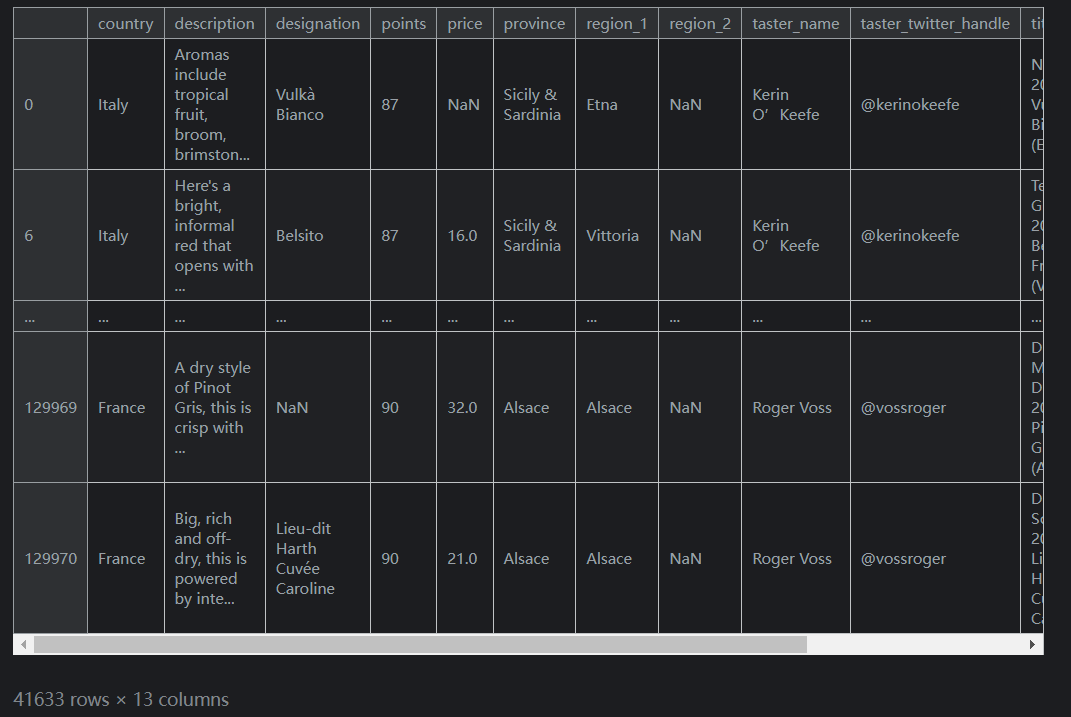
第一个是
isin。isin允许您选择其值“在”值列表中的数据。例如,以下是我们如何使用它来选择仅来自意大利或法国的葡萄酒:reviews.loc[reviews.country.isin(['Italy', 'France'])]输出如下(列未截全):
-
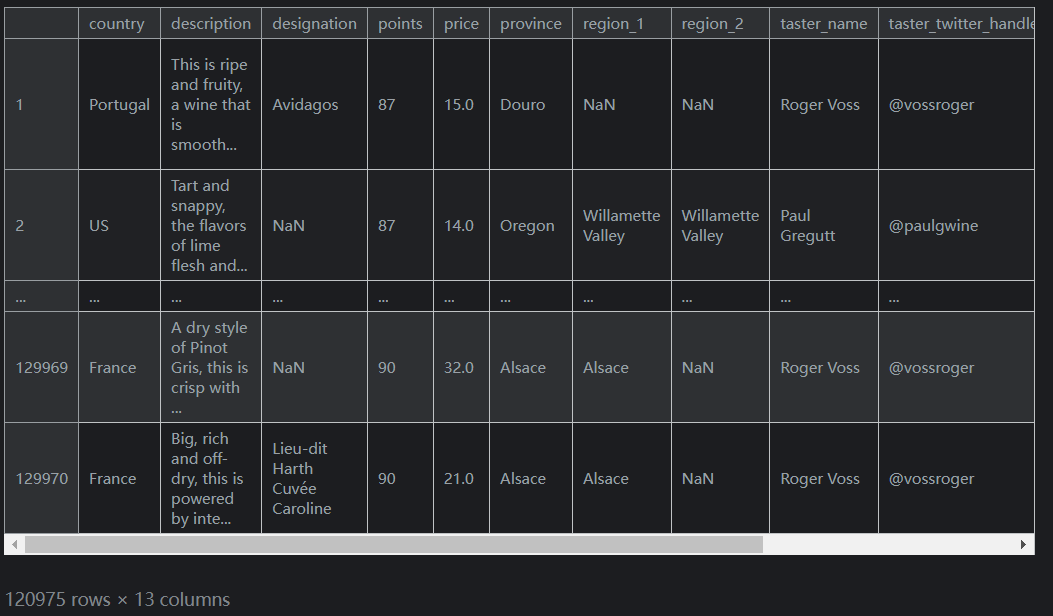
第二个是
isnull(及其配套的notnull)。这些方法允许您突出显示为(或不为)空(NaN)的值。例如,要过滤掉数据集中没有价格标签的葡萄酒,我们会这样做:reviews.loc[reviews.price.notnull()]输出如下(列未截全):
-
-
Assigning data(分配数据)
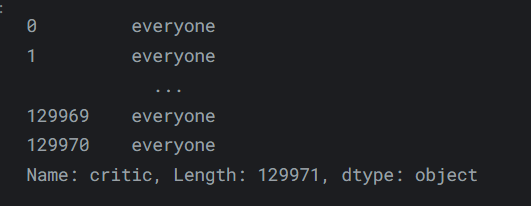
- 反过来,向
DataFrame分配数据很容易。你可以分配一个常量值:
输出如下:reviews['critic'] = 'everyone' reviews['critic']
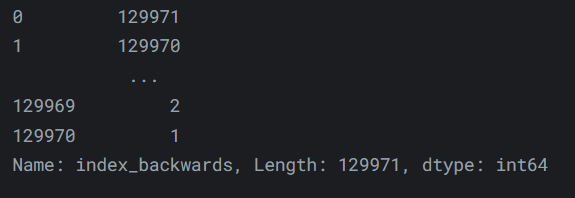
- 或者使用一个值的可迭代对象:
输出如下:reviews['index_backwards'] = range(len(reviews), 0, -1) reviews['index_backwards']