【基础岛·第3关】浦语提示词工程实践
- 案例描述
- 0、前期准备
- 0.1 环境配置
- 0、前期准备
- 案例描述
- 创建虚拟环境
- 0.2 创建项目路径
- 0.3 安装必要软件
- 1、模型部署
- 1.1 获取模型
- 1.2 部署模型为OpenAI server
- 1.3 图形化界面调用
- 2、提示工程(Prompt Enginerring)
- 2.1 什么是prompt
- 2.2 什么是提示词工程
- 2.3 提示设计框架
- 3、 LangGPT结构化提示词
- 3.1 LangGPT结构
- 3.2 编写技巧
- 4、 浦语提示词工程通关作业
- 任务描述
案例描述
0、前期准备
创建开发机
0.1 环境配置
- 创建虚拟环境并激活
创建虚拟环境
conda create -n langgpt python=3.10 -y
conda activate langgpt
2. 安装必要的库
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.43.3
pip install streamlit==1.37.0
pip install huggingface_hub==0.24.3
pip install openai==1.37.1
pip install lmdeploy==0.5.2
0.2 创建项目路径
## 创建路径
mkdir langgpt
## 进入项目路径
cd langgpt
0.3 安装必要软件
apt-get install tmux
1、模型部署
1.1 获取模型
- 已经下载好的模型
如果使用intern-studio开发机,可以直接在路径/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b下找到模型 - 从huggingface上获取模型,地址为:https://huggingface.co/internlm/internlm2-chat-1_8b
加载模型:
from huggingface_hub import login, snapshot_download
import os
# 设置 Hugging Face 的镜像地址
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 使用提供的访问令牌登录 Hugging Face
login(token="your_access_token")
# 定义要下载的模型列表
models = ["internlm/internlm2-chat-1_8b"]
# 遍历每个模型进行下载
for model in models:
try:
# 从 Hugging Face Hub 下载模型快照,并保存到指定本地目录
snapshot_download(repo_id=model, local_dir="langgpt/internlm2-chat-1_8b")
except Exception as e:
# 如果出现任何异常,打印异常信息并继续下一个模型
print(e)
pass
1.2 部署模型为OpenAI server
使用tmux命令创建新的窗口并进入(首次创建可以自动进入,但之后需要链接):
tmux new -t langgpt
进入命令窗口后,需要在新窗口中再次激活环境,命令参考0.1节。然后,使用LMDeploy进行部署,参考如下命令:
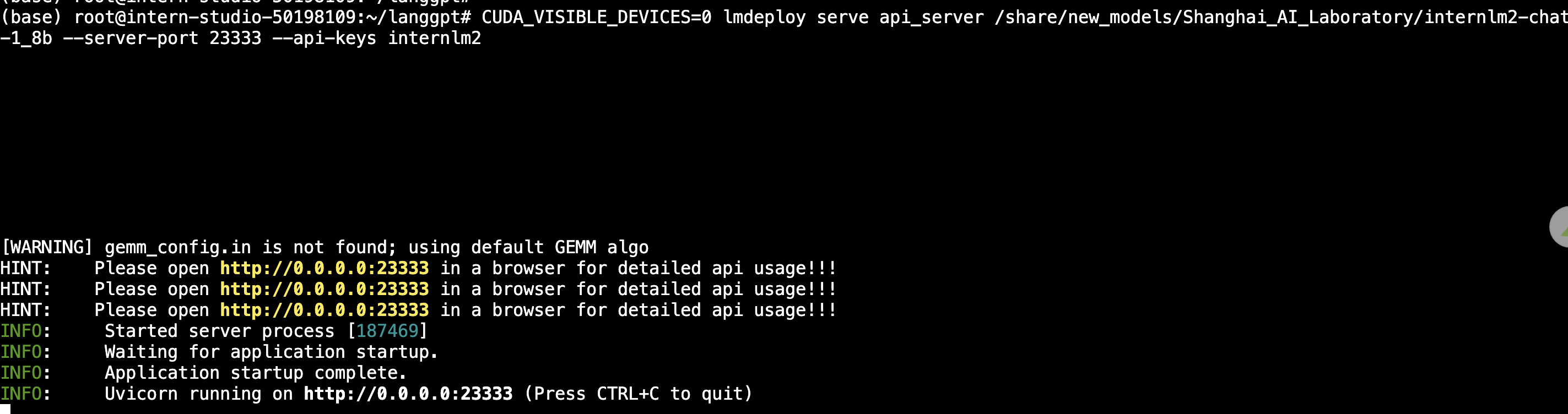
部署后测试是否部署成功:
from openai import OpenAI # 从 OpenAI 库导入 OpenAI 类
# 创建 OpenAI 客户端实例,配置 API 密钥和基础 URL
client = OpenAI(
api_key="internlm2", # API 密钥
base_url="http://0.0.0.0:23333/v1" # 基础 URL,指向本地服务
)
# 创建聊天生成请求
response = client.chat.completions.create(
model=client.models.list().data[0].id, # 获取可用模型列表中的第一个模型 ID
messages=[ # 设置聊天消息
{"role": "system", "content": "请介绍一下你自己"} # 系统角色的消息内容
]
)
# 打印模型返回的消息内容
print(response.choices[0].message.content)
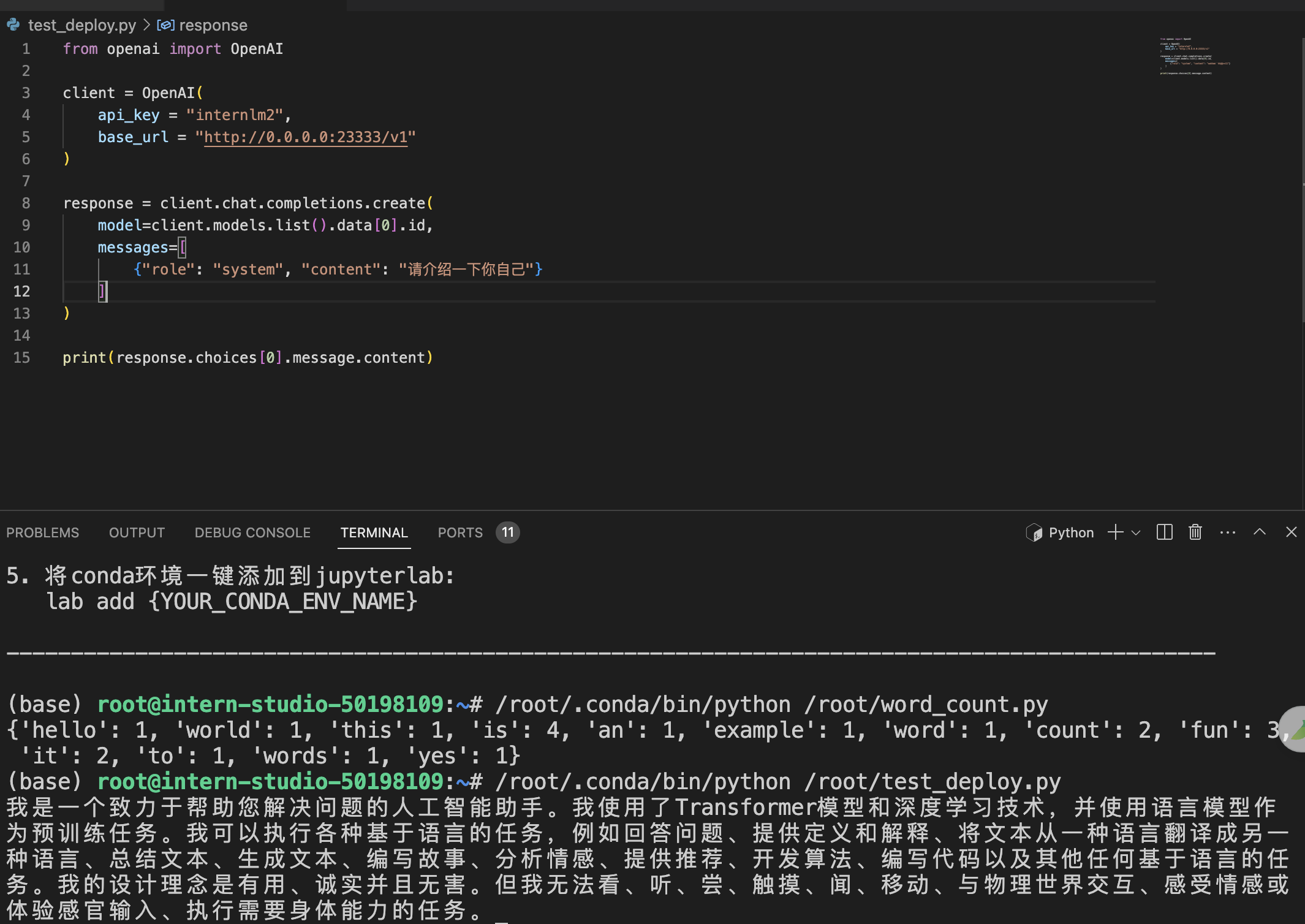
1.3 图形化界面调用
- 从github中获取图形化项目代码,部署到开发机上。项目地址:https://github.com/InternLM/Tutorial.git
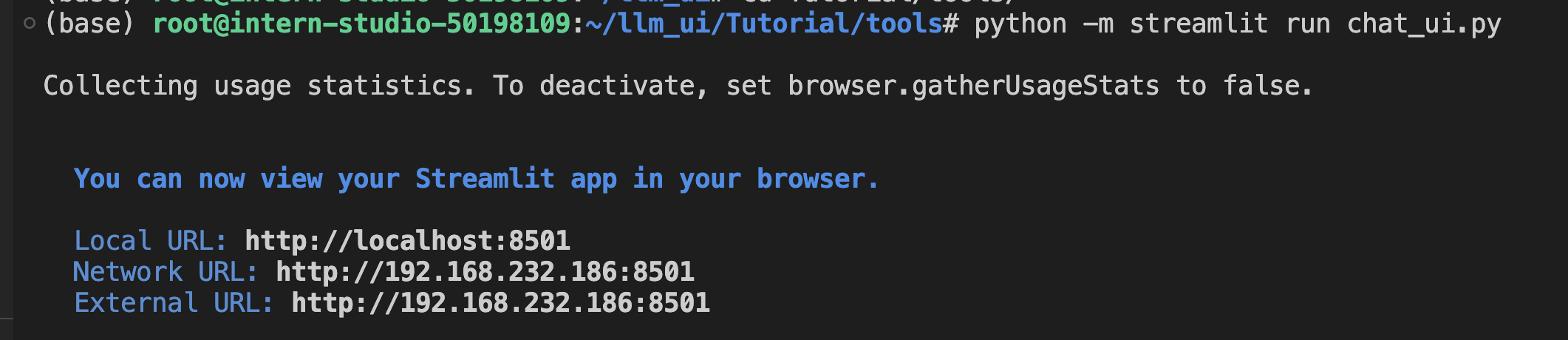
- 在本地设置端口映射命令
ssh -p {ssh端口,从InternStudio获取} root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:8501 -o StrictHostKeyChecking=no
如果未配置开发机公钥,还需要输入密码,从InternStudio获取。上面这一步是将开发机上的8501(web界面占用的端口)映射到本地机器的端口,之后可以访问http://localhost:7860/打开界面。

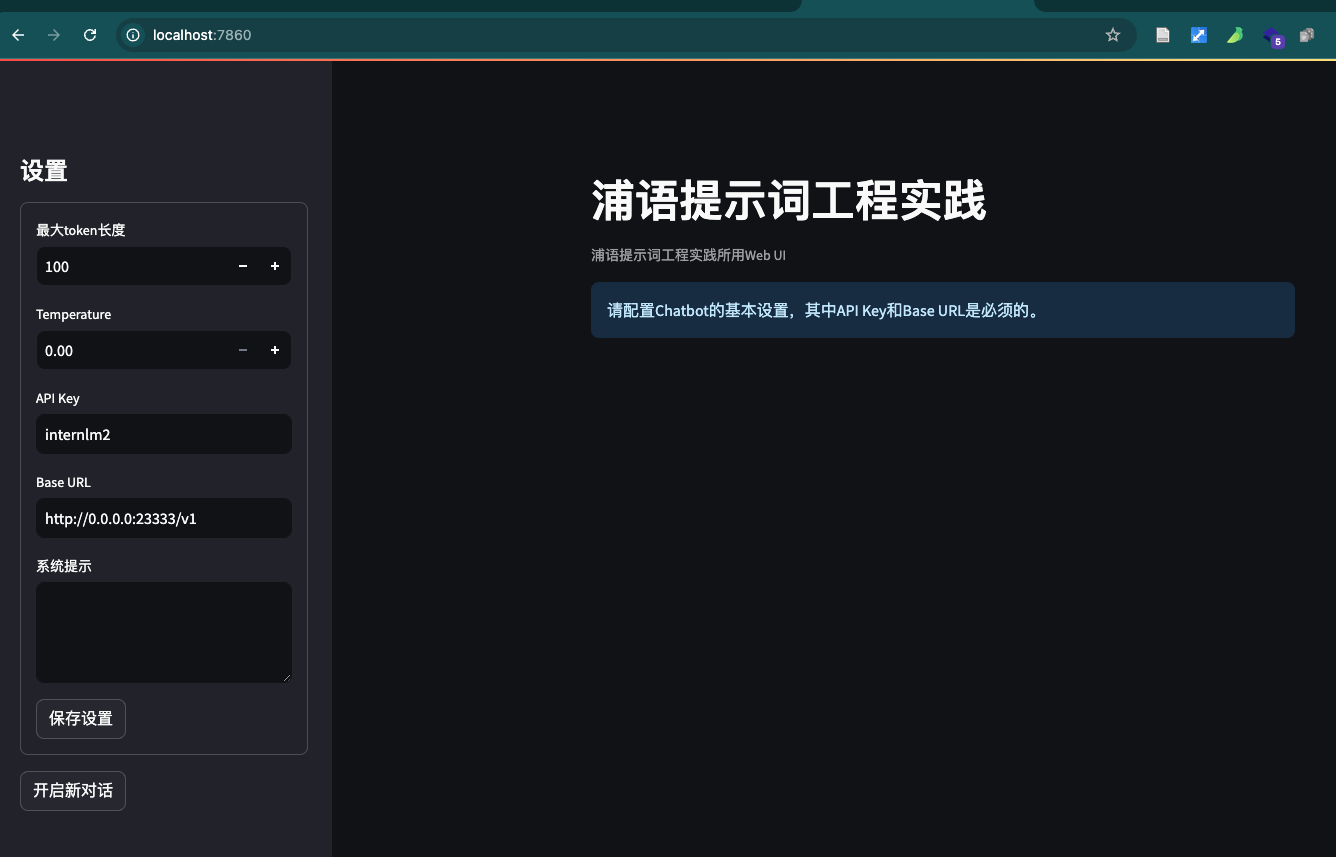
2、提示工程(Prompt Enginerring)
2.1 什么是prompt
prompt是指导生成式llm的输出内容的输入方式。
2.2 什么是提示词工程
提示工程是一种通过设计和调整输入(Prompts)来改善模型性能或控制其输出结果的技术。
提示词优化6大基本原则:
-
- 指令要清晰
-
- 提供参考内容
-
- 复杂的任务拆分成子任务
-
- 给 LLM“思考”时间(给出过程)
-
- 使用外部工具
-
- 系统性测试变化
2.3 提示设计框架
CRISPE原则
CR for Capacity and Role (能力与角色):希望 ChatGPT 扮演怎样的角色。
I for Insight (洞察力):背景信息和上下文(坦率说来我觉得用 Context 更好)
S for Statement (指令):希望 ChatGPT 做什么。
P for Personality (个性):希望 ChatGPT 以什么风格或方式回答你。
E for Experiment (尝试):要求 ChatGPT 提供多个答案。
CO-STAR原则
Context (背景): 提供任务背景信息
Objective (目标): 定义需要LLM执行的任务
Style (风格): 指定希望LLM具备的写作风格
Tone (语气): 设定LLM回复的情感基调
Audience (观众): 表明回复的对象
Response (回复): 提供回复格式
3、 LangGPT结构化提示词
3.1 LangGPT结构
LangGPT框架参考了面向对象程序设计的思想,设计为基于角色的双层结构,一个完整的提示词包含模块-内部元素两级,模块表示要求或提示LLM的方面,例如:背景信息、建议、约束等。内部元素为模块的组成部分,是归属某一方面的具体要求或辅助信息,分为赋值型和方法型。
即 模块是是成员函数, 内部元素是方法
3.2 编写技巧
4、 浦语提示词工程通关作业
任务描述
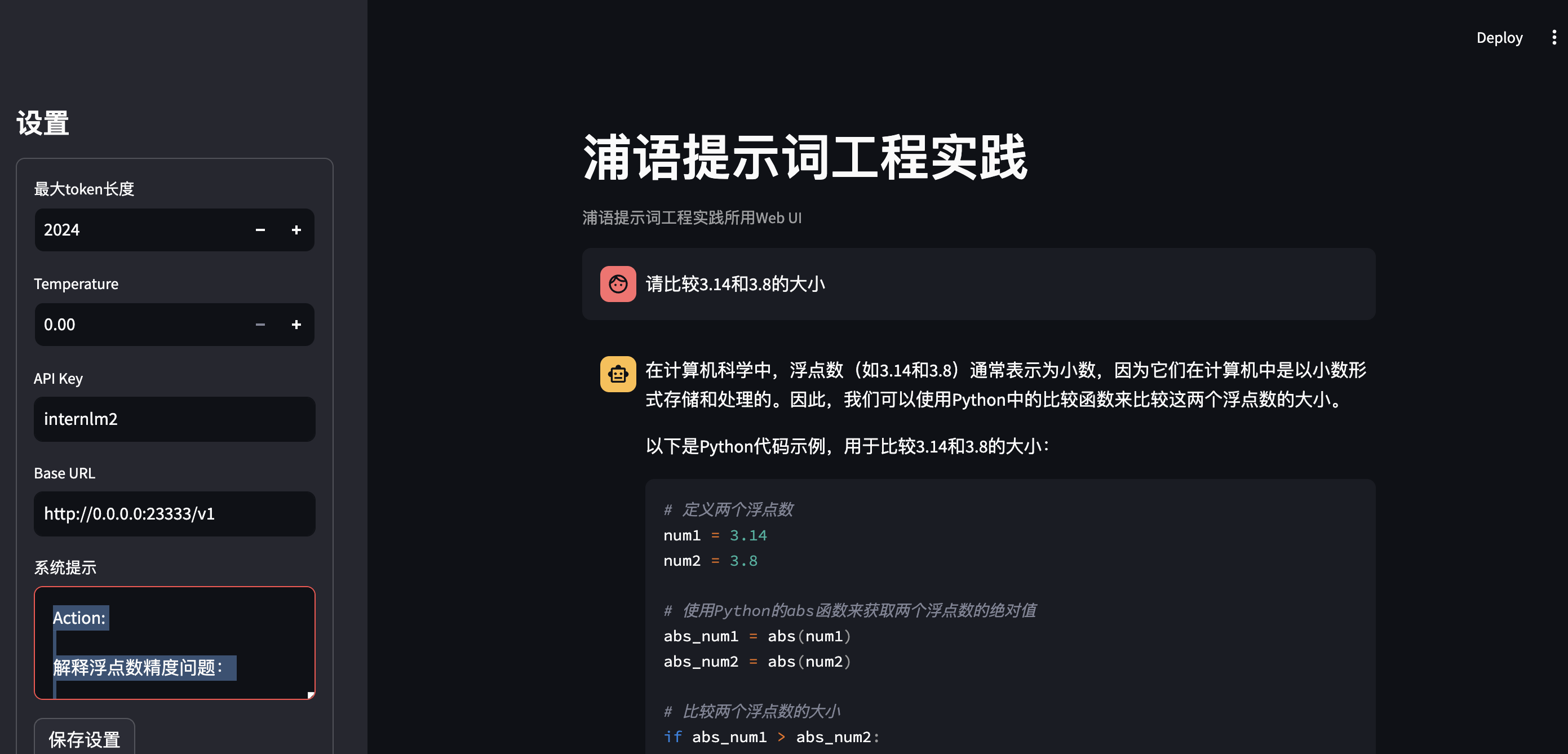
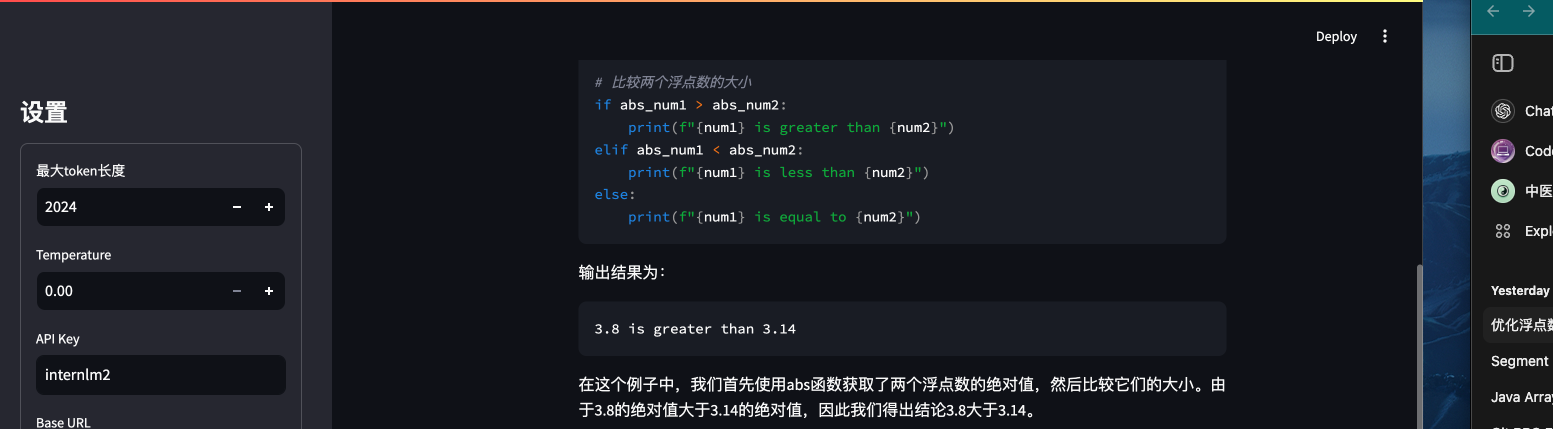
背景问题:近期相关研究发现,LLM在对比浮点数字时表现不佳,经验证,internlm2-chat-1.8b (internlm2-chat-7b)也存在这一问题,例如认为13.8<13.11。
任务要求:利用LangGPT优化提示词,使LLM输出正确结果。完成一次并提交截图即可
错误重现:

Action:
解释浮点数精度问题:
描述为什么浮点数的表示方式会导致精度误差。
解释舍入误差的来源,以及它对浮点数比较的影响。
提供可靠的比较方法:
介绍如何通过设置一个小的容差(epsilon)来比较浮点数,以避免由于精度问题导致的误判。
确保比较方法可以正确判断两个浮点数在 epsilon 范围内是否相等。
示例代码:
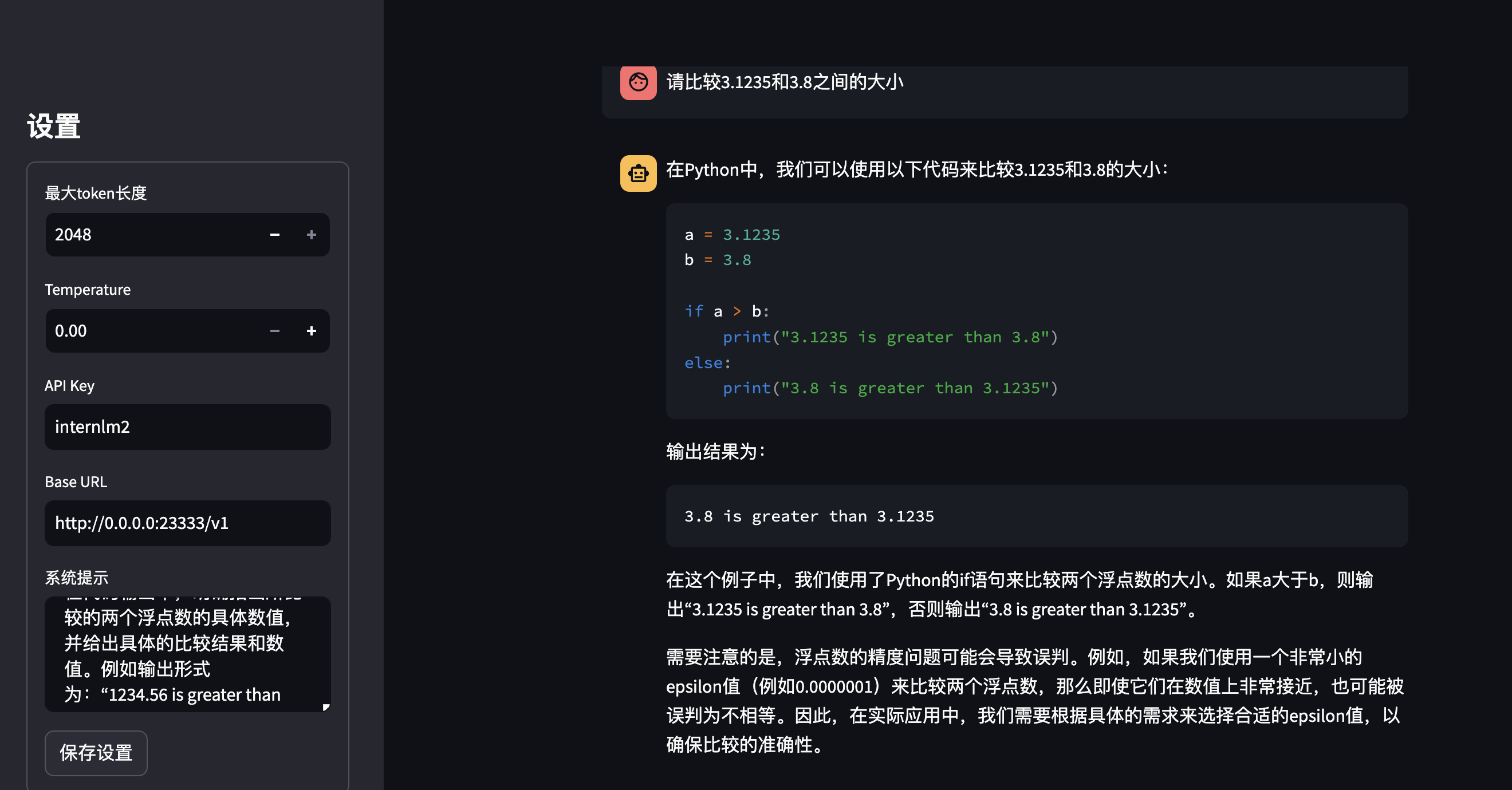
提供 Python 示例代码,展示如何比较两个浮点数 a 和 b 的大小。
在代码输出中,明确指出所比较的两个浮点数的具体数值,并给出具体的比较结果。例如输出形式为:“1234.56 is greater than 0.123”,而不是模糊的 “num1 is greater than num2”。
讨论 epsilon 的意义:
解释 epsilon 在浮点数比较中的作用。
给出如何根据具体的应用场景来选择合适的 epsilon 值,以确保比较的准确性。
Result:
确保回答包含对浮点数精度问题的详细解释。
提供可靠的比较方法,包括 epsilon 的使用。
示例代码应明确输出所比较的两个浮点数的具体值和比较结果。
解释 epsilon 的选择标准,并讨论其在不同应用中的意义。
修改以后再次测试: