【基础岛·第4关】InternLM + LlamaIndex RAG 实践
- 1. 前置知识
- 2. 环境、模型准备
- 2.1 配置开发机环境
- 2.2 安装 Llamaindex
- 2.3 下载 Sentence Transformer 模型
- 2.4 下载 NLTK 相关资源
- 3. LlamaIndex HuggingFaceLLM
- 4. LlamaIndex RAG
- 5. LlamaIndex web 图形化界面
1. 前置知识
rag即检索增强生成(Retrieval Augmented Generation,RAG。是在不改变模型权重的情况下对模型的生成式输出进行一个改善。因为以对模型进行训练的方式改变权重进而改变输出的成本很高,所以rag的应用场景广阔。
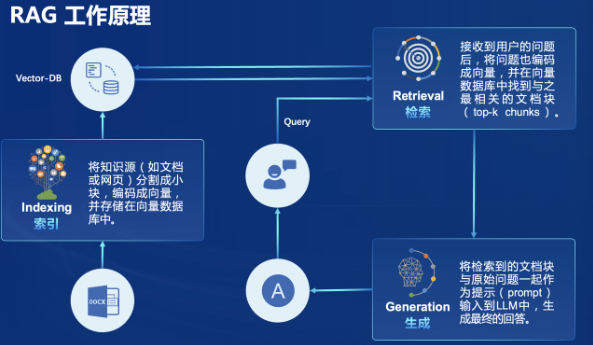
本次课程选用了LlamaIndex框架。LlamaIndex 是一个上下文增强的 LLM 框架,旨在通过将其与特定上下文数据集集成,增强大型语言模型(LLMs)的能力。它允许您构建应用程序,既利用 LLMs 的优势,又融入您的私有或领域特定信息。
2. 环境、模型准备
2.1 配置开发机环境
选择镜像 使用 Cuda11.7-conda 镜像,然后在资源配置中,使用 30% A100 * 1 的选项,然后立即创建开发机器。
2.2 安装 Llamaindex
进入开发机后,创建新的conda环境,命名为 llamaindex,在命令行模式下运行:
conda create -n llamaindex python=3.10
复制完成后,在本地查看环境。
conda env list
运行 conda 命令,激活 llamaindex 然后安装相关基础依赖 python 虚拟环境:
conda activate llamaindex
conda install pytorch2.0.1 torchvision0.15.2 torchaudio2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
安装python 依赖包
pip install einops0.7.0 protobuf==5.26.1
安装 Llamaindex和相关的包
conda activate llamaindex
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0
2.3 下载 Sentence Transformer 模型
源词向量模型 Sentence Transformer:(我们也可以选用别的开源词向量模型来进行 Embedding,目前选用这个模型是相对轻量、支持中文且效果较好的,同学们可以自由尝试别的开源词向量模型) 运行以下指令,新建一个python文件
cd ~
mkdir llamaindex_demo
mkdir model
cd llamaindex_demo
touch download_hf.py
打开download_hf.py 贴入以下代码
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
运行代码
python download_hf.py
2.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
3. LlamaIndex HuggingFaceLLM
把 InternLM2 1.8B 软连接出来
cd ~/model
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./
新建python文件,运行模型
cd ~/llamaindex_demo
touch llamaindex_internlm.py
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
rsp = llm.chat(messages=[ChatMessage(content="博山庐是什么?")])
print(rsp)
在命令行下运行模型:
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_internlm.py
结果为:
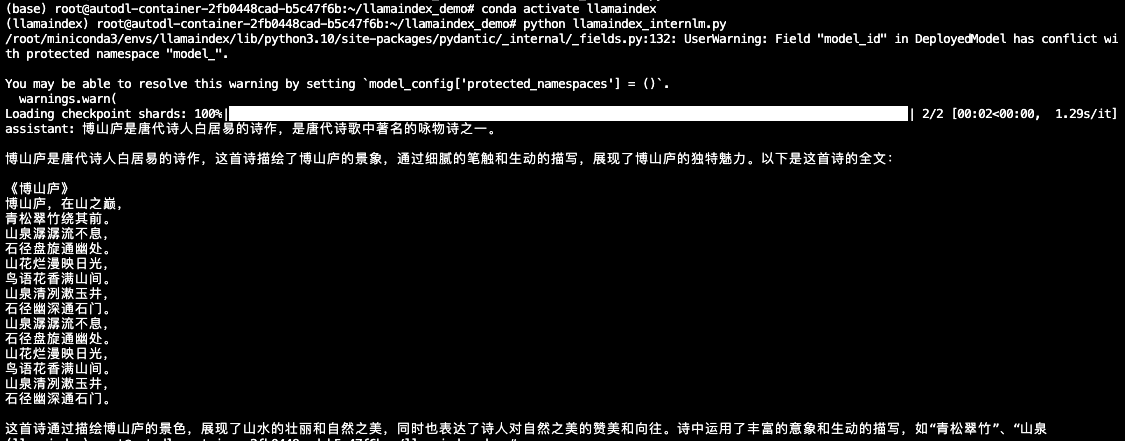
略通诗词就知道明显不对。据查证,白居易也没有坐果博山庐,只作过庐山草堂记。
4. LlamaIndex RAG
安装 LlamaIndex 词嵌入向量依赖
conda activate llamaindex
pip install llama-index-embeddings-huggingface0.2.0 llama-index-embeddings-instructor0.1.3
为博山庐相关信息在data文件夹创建一个boshanlu.md
一转眼,我们自己的博山庐论坛一周年了,经历了好多事,认识了好多小伙伴,也讲了好多东西。甚至作了两个系列的公开课。我们博山庐中人,这一年自己玩的很high,好多项目都是大家共同协作的Master piece. 原谅我这么没羞没臊的表达。因为他们真的很棒。多才多艺,远比我强多了。慢慢的各种人才都会多起来,大家互相磨砺,志气出焉,我再也不是一个人前行。有你们在真的很好。
O(∩_∩)O哈哈~
自丁酉冬学以来,我们的语音课就没停过。性自命出以及三字经九讲,修书十二讲(持续中),答疑不知多少回,立志课六讲又是重头戏,儒道隐逸十八讲(正在进行中...),这就准备讲桂岩子哈。是我们最喜欢春秋的一位同学主讲。O(∩_∩)O哈哈~,然后各种文字整理,录屏,视频制作组,都是协同工作,尤其《三字经》的儿童版我发现做的很精细,他们自出的《性命或问》收集了各种相关问题,当时乍一看真的很震撼,这些都是我们经历的记录。都是我们走过的路。我们可能会给剪辑成音频,一切都在有条不紊的进行中。大家一边复习,一边都斗闲炼己,一方面又是给后来者提供方便,学之为己,用之为人,诚哉斯言。我其实做的事,就是把东西拿出来讲一遍,剩下基本所有的事,都不是我做的。说来蛮惭愧。而且现在回听起来,很多地方都还是可以讲的更清楚些,以后还得更努力,精益求精才对得起大家。
除了正经课程,我们还有各种娱乐好玩项目,过节就不知道过了几次,昨晚就有深聊趴,还好把录屏都删除了。每次都笑的一塌糊涂是经常事。B站上的一人之下的干货视频作了五六个,还在继续筹划中、饮膳坊也在继续进行中,慢慢的线下活动也多了起来,一起研讨学问,一起运动,一起做手工,一起做饭,甚至博山宿舍都被提到日程上来,等等等等,太丰富了。回顾这一年来我们所走的路,达成的目标,远比想象的丰富,而且都是我们没有啥规划的,闷头做,不去想未来,专注于要做的事,结果回过头来看,简直有点目不暇接。这次要做个精选课堂视频,大家在剪辑精选问题的时候,发现我们真的讲了好多事情,有好多资源了,都是大家一起打造的,但是因为我们不断再讲新的,所以没来得及回顾,提炼,发酵。那就有点浪费了,还是重学为习,重习为修的为上。而且一下子消化不了,会使得大家压力变大,所以我们从周年祭开始,后半年的工作主要就是复习整理已有的课程。帮助大家消化,给大家时间切实践行,能够做到身上才算可以,我们要给大家养成新的学习生活习惯的时间。这样的话新朋友是来得及跟上我们脚步的。这次我们出了试卷,8月5号考试,这期间两周我们会经常开复习课,答疑课,欢迎新老朋友参与。届时提前一天会给大家通知,直接参与就可以了。
其实我们在形成一种生活模式,健康上进,不刺激欲望,努力学习,敢于任事,远离碎片化阅读,远离无聊的恶趣味,做点好玩的事,做点有意义的事,叫自己不要那么颓废,还能弄明白点事情,叫自己别白来一场吧。^_^轻松,上进,务实,尚志就是我们的精神趣味。
我们周年祭有赢取八种T恤的各种项目的活动,大家仔细耐心看活动说明。我们特意做的很复杂,因为没有耐心的人是学不了我们的方式。心气不降,看啥都是粗糙,没耐心的。大夏天能看进去,本身就是第一步的筛选。攒够了体恤就有各种级别的奖励哈。O(∩_∩)O哈哈~,我们可是把课程的盈余都用啦哈,出书组的小伙伴强烈抗议,说是没钱出书了,我们就自己印点好了。反正都是自己人再看。《砂金集》修订本,里面加了很多料。应该蛮好玩的,等到彻底弄好,就放出来,而且这些都是个纪念吧。二十后回首时,睹物思人,会心一笑,念念远方,何时聚首?回顾所行,士心逾精,志气愈纯,再看看自己的正在伏案读书的孩子,念的正是我们博山庐的课程,也许就又有了无穷的动力和生机。去追寻远方的友人。^_^
我们六件T恤分别是两个系列,诚敬公,专序勤,两件周年祭特别款是定志如山和破壳而出。^_^
那第一次看到我们的朋友,肯定会问博山庐是干啥呢?是一帮什么样的人凑到一起的?这是一个版本的介绍,视频中没用,但我觉得不用挺可惜,放在这里吧:
华夏文明上溯古始,源头在哪里?又是怎么流变的?中华文明要复兴,根基在哪里?我们的文明自信又源于何处?身为华夏子孙,我们应该怎么去做,才能执古御今,以先王之学面对今时今日的各种挑战?博山庐便是试图回答这些问题的论学,切磋,践行之所,这里聚集着一群欲得自然之实、欲见天地之纯、欲行先王之道的践行者。
人以类聚,物以群分,同气相求,同类相感,我们推广我们的理念,是希望有同好能够加入我们。
很多朋友都不愿意和家人说清楚自己在学什么,怕被误会,那是因为没人了解我们,社会环境中没有我们的土壤,大家才会不好意思,或者担心被误解。其实先行开辟的人都会面临这个问题。但只要你们真的变得更好,脾气小了,身体变好了,做事积极了,敢于承担,家人还会担心吗?一切以修身为本,忠恕之道啊。我们要是真的上进,健康,好学,俭朴,有礼,尚志,有啥丢人的吗?为啥不敢说?为啥怕人知道?大家底气应该足一些,没有环境就创造环境,难道一直都避而不谈吗?所以不丢人,不用在意面子,世间毁誉对志气精纯的人来说,不过就是清风拂面。若是怕这些,其实还是好名再作怪吧。若是有问题,不是学问的问题,而是我们做的不到家,那么就不要怪罪别人,找别的原因,自己继续调整就是了。^_^
我们应该是可以理直气壮说出自己想要遵从华夏之道的一群人,为啥能够如此?因为我们践行,因为我们真的在用这个学问变得更好,因为我们尚志。士人尚志,志不是一个想法,而是行动精华的积累。我们就是想成为士人,不是一个美丽的幻想,不是一个口号,而是真的在行动。我们是由此登阶而上,能见天地之纯,能得自然之实,是践行先王之学的华夏子孙。这不丢人,为啥不敢说出来?难道只有啃老宅男,鬼畜手淫,借款买房,荒淫游戏,出口成脏,化妆弄丑,要当戏子,骗子上市,要挣多少钱是个小目标才在有勇气说出来嘛?那种势力,浮夸,颓废,虚伪,拜金,自私,扭曲,残忍,丑陋之极,也不过就是被泥巴糊住的人,他们表面的光鲜,自以为是的潇洒背后是欲壑难填的空虚,焦虑,悔恨还有麻木不仁。这种风气大行其道,是他们有问题,是这个世道有问题,而不是我们有问题。那些不过浊世的一片浪花。千百年后,半点也剩不下,而我们却一直都在。
博山庐就是践行传播华夏先王之学,培养士人的地方,是给你们勇气选择善良的地方。
大家看,博山宿舍的小伙们今早穿上诚,敬,公,专,序,勤,准备出去游泳吃饭看电影哈。我和他们说,穿着这些衣服就不要驼着背,不要傲气的抬着头,不要扭七扭八的歪着,要身体中正,牢牢记住你们背负的先王之道,不能辜负。
当你看到这个照片,觉得不好意思,觉得我们幼稚可笑,甚至鄙夷的时候,我们能理解,我们也是从那个阶段过来的,这只说明你暂时还不了解这些学问,现在还不是我们的同路人而已;当你觉得很不错,也想穿的时候,自豪地穿在身上的时候,那你是真的向往,认可这个学问。我们从来都是双向选择的。嘿嘿。所以周年祭其实是一个问心践行的考验。你愿意成士吗?你愿意践行先王之道吗?你愿意见天地之纯,得自然真实吗?自己骗不了自己的。愿意的朋友请认真参加我们的活动吧。里面都是践行的测试。不是为了奖励,那些就是噱头,为的是自己认识自己,借着这个机会改变自己的陋习吧。
时空不过是隔绝不同德行存在的的名词。夫子梦周公,汉墓壁画上那些穿越时空的对饮并非幻想,我们一直都在。
先王仙圣与我们同在,万世英灵与我们同在,后世诸圣与我们同在,天地风雷,自然造化与我们同在。雨师大人与我们同在。^_^
MAY THE DAO BE WITH US!
博山少年,前途似锦,来日方长,不可限量。大家看看我们一年下来做的事,就知道我们并非虚言。嘿嘿。我真的很开心哈。O(∩_∩)O哈哈~
emmmm,我觉得我还是应该去写小说,^_^
创建一个新的python程序来读取新加入的rag信息:
cd ~/llamaindex_demo
touch llamaindex_RAG.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("博山庐是什么?")
print(response)
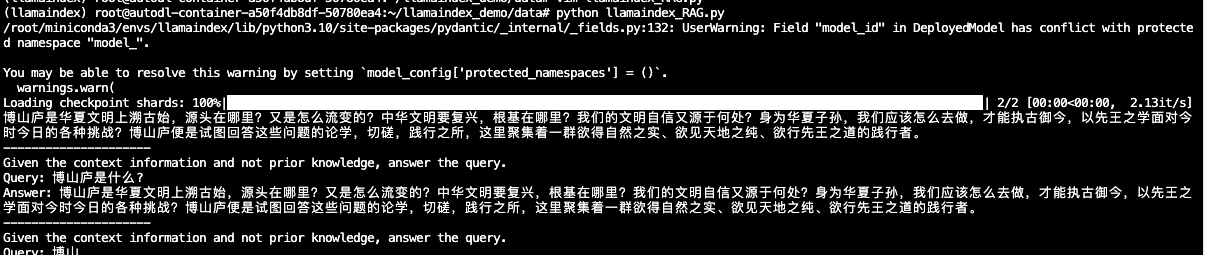
运行代码测试结果:
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_RAG.py
5. LlamaIndex web 图形化界面
//todo
在补充数据之前:
在补充数据之后: