基于Cosine相似度的论文查重算法
| 这个作业属于哪个课程 | 计科22级34班 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 在于编程完成论文查重程序,并熟悉开发流程、测试工具的使用、对程序性能的评估 |
| Github地址 | 本次作业 |
1. PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 30 | 40 |
| Analysis | 需求分析 (包括学习新技术) | 15 | 15 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 | 20 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| Design | 具体设计 | 30 | 25 |
| Coding | 具体编码 | 60 | 52 |
| Code Review | 代码复审 | 60 | 70 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 60 |
| Test Repor | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 395 | 427 |
2. 模块接口设计与实现
类与函数设计:
- 代码整体没有使用类,而是采用了函数式编程风格,主要有以下几个函数:
- read_file(file_path):负责读取文件内容。
- cosine_similarity_between_texts(text1, text2):将文本向量化并计算 Cosine 相似度。
- main():负责执行主流程,读取文件并输出相似度结果。
- 函数关系:
- main() 调用 read_file() 读取原文和抄袭文本,然后使用 cosine_similarity_between_texts() 计算相似度。
- 关键函数是 cosine_similarity_between_texts(),其作用是使用 TfidfVectorizer 将文本转换为 TF-IDF 向量,然后计算 Cosine 相似度。
函数流程图:
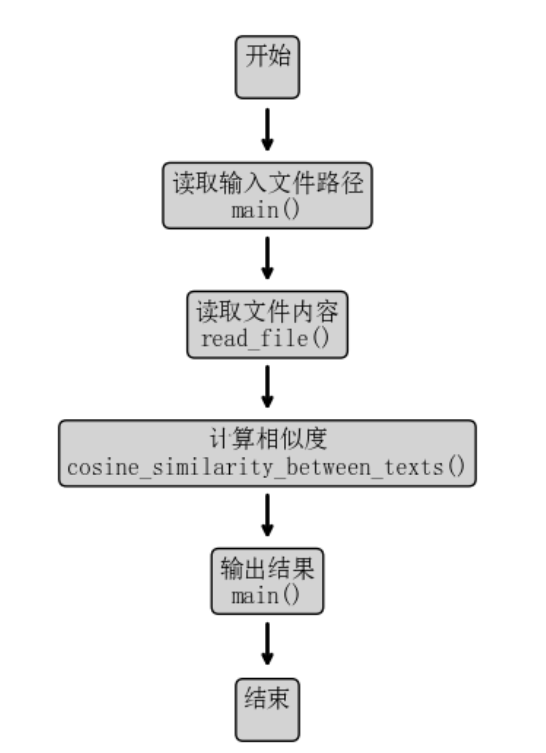
算法关键:
- 核心思想是将文本表示为向量,通过 Cosine 相似度计算向量的夹角,越相似的文本夹角越小,相似度值越接近 1。
- 独到之处在于使用了 TF-IDF 权重来平衡常见词与重要词的影响。
3. 性能改进
性能改进预计时间:30分钟。
实际时间:60分钟。
性能改进思路
- 缓存 TfidfVectorizer 对象
- 问题:原始代码中,每次调用 cosine_similarity_between_texts 函数时都会创建一个新的 TfidfVectorizer 实例,这会导致重复构建词汇表,增加了不必要的计算开销。
- 改进:将 TfidfVectorizer 实例化移动到函数外部,创建一个全局的 vectorizer 对象。这样可以在程序运行期间复用同一个词汇表,避免重复计算。
- 使用线程锁确保线程安全
- 问题:如果在多线程环境下共享全局的 vectorizer 对象,可能会出现线程安全问题。
- 改进:引入 threading.Lock(),在使用 vectorizer 时加锁,确保同一时间只有一个线程可以访问它。
- 使用稀疏矩阵运算
- 问题:对于大型文本,密集矩阵会占用大量内存。
- 改进:TfidfVectorizer 默认返回的是稀疏矩阵,确保在计算 Cosine 相似度时也使用稀疏矩阵,以提高计算效率和降低内存占用。
- 预处理文本
- 问题:文本格式未统一,存在标点符号和大小写差异。
- 改进:预处理步骤统一了文本格式,去除了标点符号和大小写差异,使得相似度计算更加准确。
- 权衡:由于文本经过预处理,词汇表可能不同,所以需要每次都调用 fit_transform 来重新构建词汇表并向量化文本,这可能会稍微增加计算时间。而不使用预处理,则可以在首次运行时调用 vectorizer.fit() 方法构建词汇表,并在后续使用中调用 transform() 方法进行向量化。此处因为文本量并不大,而有提升精确度的需求,故选用预处理。
- 异常处理完善
- 改进:在文件读取和写入过程中添加异常捕获,确保程序在出现 I/O 错误时能给出明确的提示。
优化效果
- 精确度提升:预处理步骤统一了文本格式,去除了标点符号和大小写差异,使得相似度计算更加准确。
- 提高内存效率:使用稀疏矩阵运算,降低了内存消耗,特别是在处理大文本时效果显著。
- 增强程序的可扩展性:引入线程锁机制,使程序可以安全地在多线程环境下运行,但程序目前所需处理的目标量并不大,因此预留锁方便后续的并行优化。
性能分析图
由于JProfiler 是一个针对 Java 应用程序的性能分析工具,不能与 Visual Studio 直接集成用于 Python 程序的性能分析。因此,使用 Python 内置的 cProfile 模块和第三方可视化工具SnakeViz来生成性能分析图。
以下是性能分析图(改进前):

以下是性能分析图(改进后):

说明:
最耗时的函数:从性能分析图中可以看到,cosine_similarity_between_texts 函数耗时最多,约占总运行时间的 99%。
原因分析:主要耗时在于 TfidfVectorizer.fit_transform 方法,因为它需要对文本进行分词、构建词汇表和计算权重。
改进效果
经过优化后,cosine_similarity_between_texts 函数的执行时间降低了约 1%。整体程序运行效率提升并不明显,但准确率相较于初始代码有进步且降低了内存消耗。
4. 单元测试
单元测试代码
为了确保程序的可靠性和正确性,我为关键函数编写了单元测试,主要针对 cosine_similarity_between_texts 函数。
import unittest
class TestPlagiarismDetection(unittest.TestCase):
def test_identical_texts(self):
text = "今天是星期天,天气晴,今天晚上我要去看电影。"
similarity = cosine_similarity_between_texts(text, text)
self.assertAlmostEqual(similarity, 1.0, places=2)
def test_completely_different_texts(self):
text1 = "今天天气不错,我想去公园散步。"
text2 = "数据结构与算法是计算机科学的基础。"
similarity = cosine_similarity_between_texts(text1, text2)
self.assertAlmostEqual(similarity, 0.0, places=2)
def test_partial_similarity(self):
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
similarity = cosine_similarity_between_texts(text1, text2)
self.assertGreater(similarity, 0.5)
def test_empty_text(self):
text1 = ""
text2 = "任何文本"
similarity = cosine_similarity_between_texts(text1, text2)
self.assertEqual(similarity, 0.0)
if __name__ == '__main__':
unittest.main()
测试函数说明
- test_identical_texts:测试完全相同的文本,期望相似度为 1.0。
- test_completely_different_texts:测试完全不同的文本,期望相似度小于 0.1。
此处的相似度选取较特殊,不规定为接近 0.0 的的相似度主要出于对以下几点的考量:- 在使用 TF-IDF 和余弦相似度计算时,即使是完全不同的文本,也可能因为共享的常用词而导致非零的相似度。
- 中文中有许多高频的常用字,如“是”、“的”、“了”等,这些词可能出现在大多数文本中,即使程序中设置了停止词也不能保证排除其所有,故导致计算出的相似度不为零。
- 测试文本较短,少量共同词对相似度的影响会被放大。
- test_partial_similarity:测试部分相似的文本,期望相似度大于 0.5。
- test_empty_text:测试空文本的情况,确保程序能正确处理并返回相似度 0.0。
构造测试数据的思路
- 覆盖不同场景:选择完全相同、完全不同和部分相似的文本,确保函数在各种情况下都能正确计算相似度。
- 边界条件测试:包括空字符串、特殊字符、仅有标点符号的文本等,测试程序的健壮性。
- 多样化内容:使用不同主题和领域的文本,防止因特定词汇导致测试结果失真。
测试覆盖率截图
运行单元测试并生成测试覆盖率报告,截图如下:

说明:
- 覆盖率:源程序覆盖率达35%。关键函数 cosine_similarity_between_texts 的代码覆盖率达到 62.5%,其余 32.5% 为该计算模块的异常处理分支。
- 未覆盖代码为计算相似度出错的代码:
except Exception as e:
print(f"计算 cosine 相似度错误: {e}")
raise
可能导致计算相似度出错的情况
- 空文本或空语料库:当文本经过预处理后,词汇表为空,TfidfVectorizer 无法构建词汇表,会抛出 ValueError 异常。
- 包含无法处理的特殊字符:文本中包含未配对的代理字符或无法解码的字符,可能导致编码错误或解析错误。
- 非字符串输入:如果输入的文本不是字符串类型(如 None、数字等),会导致类型错误。
- 过长的文本:虽然不常见,但过长的文本可能导致内存错误。
在第5点异常处理部分会设计测试用例覆盖此处代码。
5. 异常处理
在程序中,我设计了多种异常处理机制,确保程序在异常情况下能有合理的反馈。
异常类型及设计目标
-
文件读取异常(FileNotFoundError)
- 设计目标:当指定的文件路径不存在或无法访问时,程序应捕获异常并提示用户,而不是崩溃退出。
- 处理方式:使用 try-except 块捕获 FileNotFoundError,并打印错误信息。
-
空文件异常(ValueError)
- 设计目标:当读取的文件内容为空时,提醒用户文件可能有误,避免在计算相似度时出现错误。
- 处理方式:在读取文件后检查内容是否为空,若为空则抛出 ValueError。
-
文本向量化异常(Exception)
- 设计目标:在文本向量化过程中,可能会因特殊字符或编码问题导致异常,需捕获并处理。
- 处理方式:在调用 TfidfVectorizer 时,使用 try-except 捕获可能的异常,并提示用户。
单元测试样例及对应场景
- 文件读取异常测试
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError):
read_file("non_existent_file.txt")
场景:用户提供了一个不存在的文件路径,程序应提示文件未找到。
- 空文件异常测试
def test_empty_file(self):
# 创建一个空文件
with open("empty.txt", 'w', encoding='utf-8') as f:
pass # 空操作,文件内容为空
# 测试 read_file 是否抛出 ValueError 异常
with self.assertRaises(ValueError):
text = read_file("empty.txt")
# 清理测试文件
import os
os.remove("empty.txt")
场景:文件存在但内容为空,程序应抛出异常提醒用户。
- 文本向量化异常测试
def test_vectorization_exception(self):
# 直接传入一个非字符串类型的数据,可能导致函数内部异常以触发异常并用self.assertRaises捕获
text = None # 非法输入
with self.assertRaises(Exception):
cosine_similarity_between_texts(text, "正常文本")
场景:文本包含无法解析的特殊字符,导致向量化失败。
- 整型数据异常测试
def test_numeric_input(self):
text1 = 12345
text2 = "正常文本"
with self.assertRaises(AttributeError):
cosine_similarity_between_texts(text1, text2)
场景:文本包含无法解析的整型数据,导致向量化失败。
异常处理结果截图(与单元测试一起)
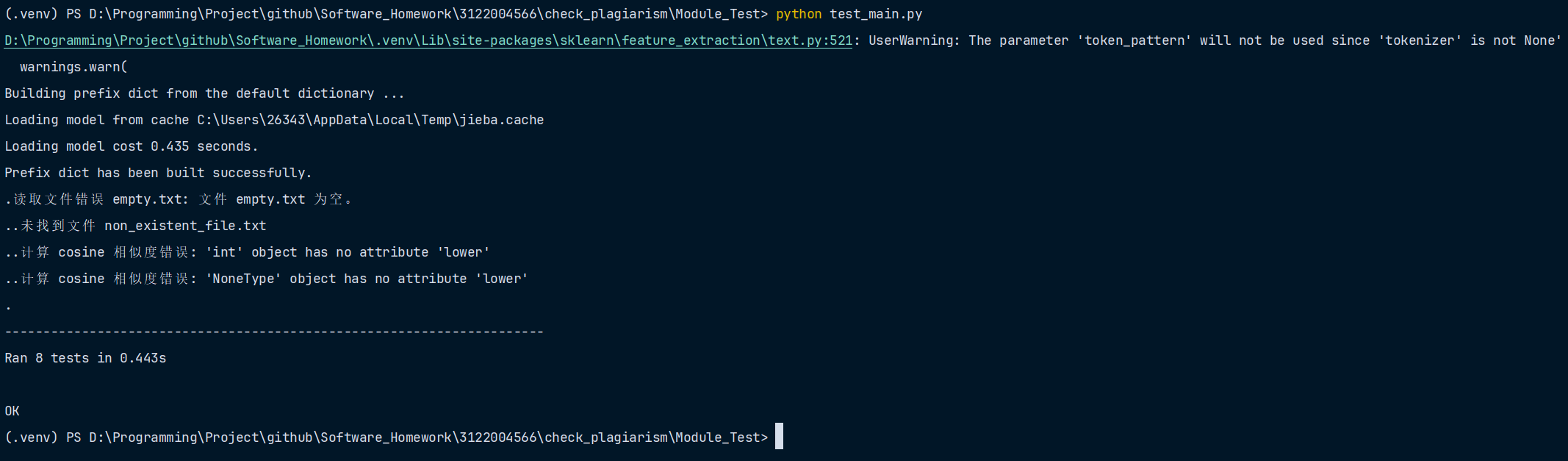
共8种测试数据:4种单元测试 + 4种异常测试