从零学习大模型——使用GLM-4-9B-Chat + BGE-M3 + langchain + chroma建立的本地RAG应用(六)——最终实战:带有依照会话进行记忆功能的对话api
经过上一篇教程,我们已经成功构建出全本地的问答检索功能,现在我们需要通过api访问云服务器,并且使用fastapi定义一个接口,从而使功能可以通过api被访问。
在/root/autodl-tmp路径下新建api-Langchain-withUser.py文件
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoModel
from glm4LLM import ChatGLM4_LLM
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts.chat import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from testEmbeddings import BGEM3Embeddings
from langchain_community.vectorstores import Chroma
from langchain.chains.question_answering import load_qa_chain
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
import re
import uvicorn
import json
import datetime
import torch
# 设置设备参数
DEVICE = "cuda" # 使用CUDA
DEVICE_ID = "0" # CUDA设备ID,如果未设置则为空
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE # 组合CUDA设备信息
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否可用CUDA
with torch.cuda.device(CUDA_DEVICE): # 指定CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
torch.cuda.ipc_collect() # 收集CUDA内存碎片
# 创建FastAPI应用
app = FastAPI()
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
global llm, tokenizer,prompt_template,retriever # 声明全局变量以便在函数内部使用模型和分词器
json_post_raw = await request.json() # 获取POST请求的JSON数据
json_post = json.dumps(json_post_raw) # 将JSON数据转换为字符串
json_post_list = json.loads(json_post) # 将字符串转换为Python对象
question=json_post_list.get('question')
chat_info=json_post_list.get('chatInfo')
is_new=json_post_list.get('isNew')
other_params=json_post_list.get('otherParams')
# prompt = json_post_list.get('prompt') # 获取请求中的提示
# history = json_post_list.get('history') # 获取请求中的历史记录
# max_length = json_post_list.get('max_length') # 获取请求中的最大长度
# top_p = json_post_list.get('top_p') # 获取请求中的top_p参数
# temperature = json_post_list.get('temperature') # 获取请求中的温度参数
# 定义记忆功能
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
if is_new:
# 加载会话历史
for entry in chat_info:
inputs = {"input": entry["message"]}
outputs = {"output": entry["response"]}
memory.save_context(inputs, outputs)
# 调用模型进行对话生成
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
combine_docs_chain_kwargs={"prompt": prompt_template},
memory=memory
)
response=qa({"question":question})["answer"]
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间为字符串
# 构建响应JSON
answer = {
"response": response,
"status": 200,
"time": time,
"otherParams":other_params
}
# 构建日志信息
log = "[" + time + "] " + '", response:"' + repr(response) + '"'
print(log) # 打印日志
torch_gc() # 执行GPU内存清理
return answer # 返回响应
# 主函数入口
if __name__ == '__main__':
# 加载预训练的分词器和模型
# tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/ZhipuAI/glm-4-9b-chat", trust_remote_code=True)
# model = AutoModelForCausalLM.from_pretrained(
# "/root/autodl-tmp/ZhipuAI/glm-4-9b-chat",
# torch_dtype=torch.bfloat16,
# trust_remote_code=True,
# device_map="auto",
# )
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
# 加载本地LLM模型
llm = ChatGLM4_LLM(model_name_or_path="/root/autodl-tmp/ZhipuAI/glm-4-9b-chat", gen_kwargs=gen_kwargs)
# 加载本地向量数据库与embeddings模型
model_name = "bge-m3"
save_directory = "/root/autodl-tmp/bge-m3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
embedding = BGEM3Embeddings(model, tokenizer)
persist_directory='/root/autodl-tmp/vectorDatabase/chroma'
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embedding
)
# 定义模版
template = """请结合上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
上下文:{chat_history}
问题: {question}
"""
# 定义提示词
prompt_template = PromptTemplate(input_variables=["context","question","chat_history"],
template=template)
# 定义检索功能
retriever=vectordb.as_retriever()
# 启动FastAPI应用
# 用6006端口可以将autodl的端口映射到本地,从而在本地使用api
uvicorn.run(app, host='0.0.0.0', port=6006, workers=1) # 在指定端口和主机上启动应用执行该py文件,出现以下结果表示服务启动成功:

此时打开AutoDL的容器实例页面,点击运行该服务的服务器实例右边的自定义服务按钮
然后会弹出一个新的窗口,该窗口的url就是服务的接口。我们可以使用postman访问该接口。
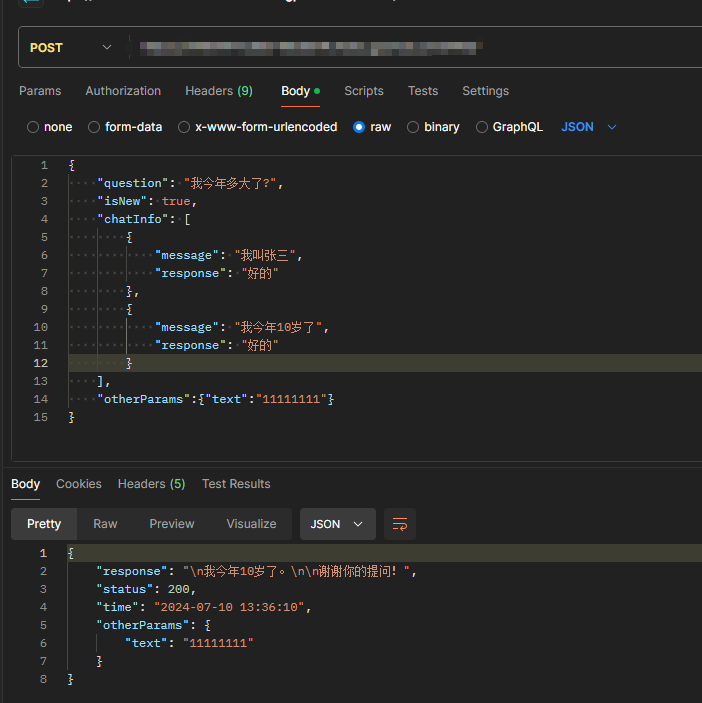
返回如下数据表示该服务成功运行。