19--Scarpy05:增量式爬虫、分布式爬虫
19--Scarpy05--增量式爬虫、分布式爬虫
一. 增量式爬虫
顾名思义:可以对网站进行反复抓取,然后发现新东西了就保存起来,遇到了以前抓取过的内容就自动过滤掉即可
其核心思想:去重,并且可以反复去重。随时运行一下,将不同的数据保存出来,相同的数据去除掉(不保存)即可
增量爬虫的核心:去除重复
-
去除url的重复
-
去除数据的重复
1.1 scrapy调度器去重源码分析
### 0 调度器是默认带去除重复的
用的是python的集合
### 1 scrapy 默认配置
# scrapy/settings/defalut_settings.py
# 默认的去重类
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'
### 2 调度器的核心源码
# scrapy/core/scheduler.py
class Scheduler:
...
# enqueue v.入队
def enqueue_request(self, request):
"""
解读:
如果请求对象request的dont_filter(不过滤)参数 为False # 就是请求要过滤
且去重类的request_seen(request)方法为True # 见过该请求,表示请求重复
则 返回False # 表示该请求,不进入请求队列
"""
if not request.dont_filter and self.df.request_seen(request): ### 核心代码
self.df.log(request, self.spider)
return False
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
### 3 默认去重类的源码
# scrapy/dupefilters.py
class RFPDupeFilter(BaseDupeFilter):
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set() # 采用的是集合
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
...
# 函数名的意思是 request对象 是否见过
def request_seen(self, request):
"""
:return为True,就不爬了 若为False,则继续爬取
"""
fp = self.request_fingerprint(request)
if fp in self.fingerprints: # 请求对象,如果在指纹集合,就返回True 表示见过该请求
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + '\n')
### 4 指纹生成 原理 request_fingerprint(request)
生成指纹,会把下面两种地址生成一样的指纹 # 本质是把?后面的参数排序,再生成指纹
www.baidu.com?name=lqz&age=18 --指纹--> '4asda232' 长字符串
www.baidu.com?age=18&name=lqz --指纹--> '4asda232' 长字符串
# 上面两个地址,若是直接放进集合中,会判定成两个地址,但实质,这两个是同一个地址请求
1.2 自定义去重类 实现去重
### 0 原理
自定义去重类,替换掉内置的去重类
### 1 新建文件 my_filters.py,自定义去重类MyFilter
from scrapy.dupefilters import BaseDupeFilter
from scrapy.utils.request import request_fingerprint
class MyFilter(BaseDupeFilter) # 继承BaseDupeFilter
# 重写 request_seen()
def request_seen(self, request):
fp = request_fingerprint(request) # 将请求进行生成指纹,一堆长字符串
# 根据指纹,进行判断
若已经有该指纹,返回True,就不爬了
若没有该指纹,返回False,就继续爬取
### 2 配置自定义的去重类 settings.py
DUPEFILTER_CLASS = 'scrapy.my_filters.MyFilter'
1.3 使用redis实现去重
方案是用redis的集合,进行去重,还可以选择使用数据库、mongodb进行过滤,原理都一样
连接redis的两个方案:
1.在spider中,重写__init__()方法,在爬虫类实例化对象时,连接数据库
2.在pipeline中,open_spider()中,在爬虫执行前,连接数据库
去重的两个方案:
1.url去重 优点: 简单 缺点:若有新的数据产生,无法提取到最新的数据了
2.数据内容去重 优点: 保证数据的一致性 缺点: 需要每次都把数据从网页中提取出来
案例:天涯为目标,来尝试一下增量式爬虫
- spider.py:
import scrapy
from redis import Redis
from tianya.items import TianyaItem
class TySpider(scrapy.Spider):
name = 'ty'
allowed_domains = ['tianya.cn']
start_urls = ['http://bbs.tianya.cn/list-worldlook-1.shtml']
def __init__(self, name=None, **kwargs):
"""
连接redis的方案1:重写init方法,连接redis数据库
"""
self.red = Redis(password="123456", db=6, decode_responses=True)
super().__init__(name, **kwargs)
def parse(self, resp, **kwargs):
tbodys = resp.css(".tab-bbs-list tbody")[1:]
for tbody in tbodys:
hrefs = tbody.xpath("./tr/td[1]/a/@href").extract()
for h in hrefs:
### 去重的两个方案:
url = resp.urljoin(h)
# 判断在该set集合中是否有url数据
r = self.red.sismember("tianya:details", url)
# 1.url去重. 优点: 简单 缺点: 如果有人回复了帖子.就无法提取到最新的数据了
if not r:
yield scrapy.Request(url=resp.urljoin(h), callback=self.parse_details)
else:
print(f"该url已经被抓取过{url}")
next_href = resp.xpath("//div[@class='short-pages-2 clearfix']/div[@class='links']/a[last()]/@href").extract_first()
yield scrapy.Request(url=resp.urljoin(next_href), callback=self.parse)
def parse_details(self, resp, **kwargs):
title = resp.xpath('//*[@id="post_head"]/h1/span[1]/span/text()').extract_first()
content = resp.xpath('//*[@id="bd"]/div[4]/div[1]/div/div[2]/div[1]/text()').extract_first()
item = TianyaItem()
item['title'] = title
item['content'] = content
# 提取完数据. 将该url,添加到redis
self.red.sadd("tianya:details", resp.url)
return item
- pipelines.py
from itemadapter import ItemAdapter
from redis import Redis
import json
class TianyaPipeline:
def process_item(self, item, spider):
# 2.数据内容去重. 优点: 保证数据的一致性. 缺点: 需要每次都把数据从网页中提取出来
print(json.dumps(dict(item)))
r = self.red.sadd("tianya:pipelines:items", json.dumps(dict(item)))
if r:
# 进入数据库
print("存入数据库", item['title'])
else:
print("已经在数据里了", item['title'])
return item
def open_spider(self, spider):
"""连接redis的方案2"""
self.red = Redis(password="123456", db=6)
def close_spider(self, spider):
self.red.close()
二. 分布式爬虫
分布式爬虫:就是搭建一个分布式的集群,让其对一组资源进行分布联合爬取
# 思考:既然要集群来抓取,意味着会有好几个爬虫同时运行。此时产生一个问题, 如果有重复的url怎么办?
在原来的程序中,scrapy中会由调度器来自动完成这个任务。
但是,此时是多个爬虫一起跑,不同的机器之间是不能直接共享调度器的,怎么办?
# 解决:
可以采用redis来作为各个爬虫的调度器
此时引出一个新的模块叫scrapy-redis,在该模块中提供了这样一组操作
它重写了scrapy中的调度器,并将调度队列和去除重复的逻辑,全部引入到了redis中
安装scrapy-redis
pip install scrapy-redis==0.7.2
2.1 scrapy-redis工作流程
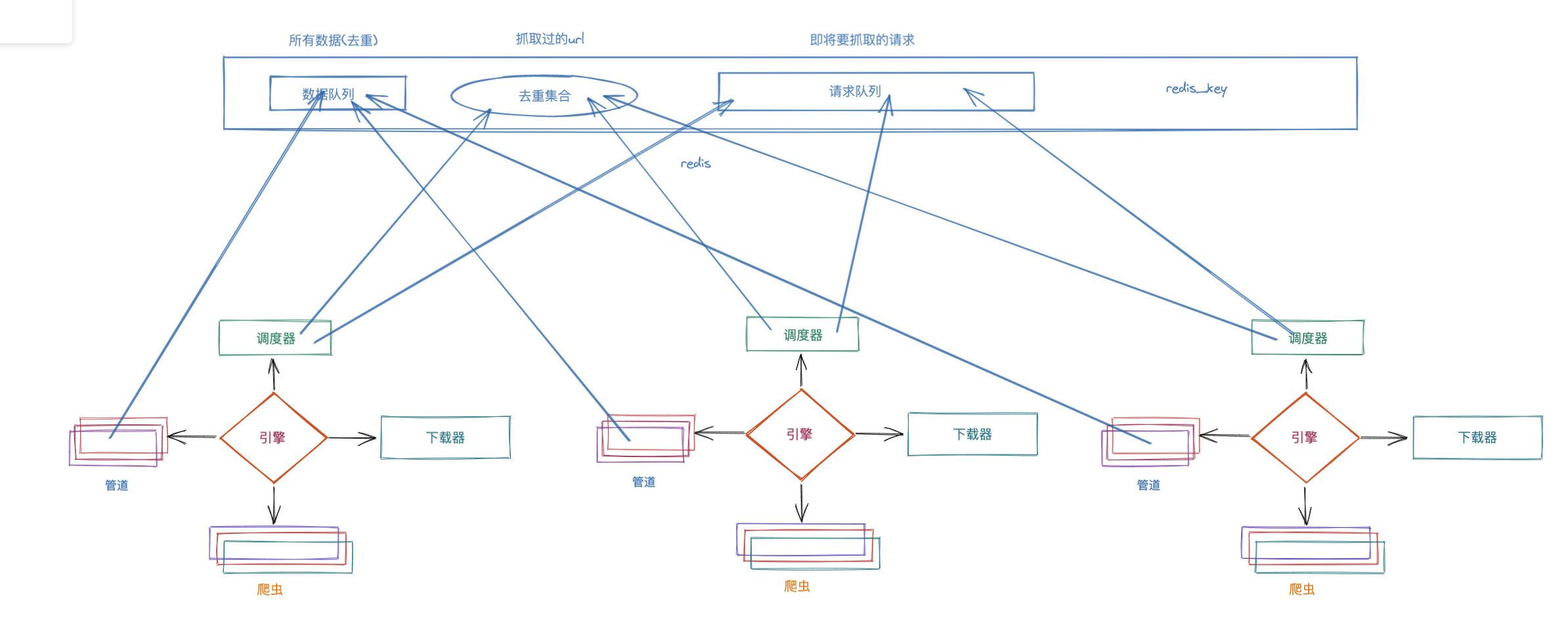
1.某个爬虫从redis_key获取到起始url,传递给引擎, 到调度器
然后把起始url直接丢到redis的请求队列里,开始了scrapy的爬虫抓取工作
2.若抓取过程中产生了新的请求,不论是哪个节点产生的
最终都会到redis的去重集合中,进行判定是否抓取过
3.若抓取过,直接就放弃该请求
如果没有抓取过,自动丢到redis请求队列中
4.调度器继续从redis请求队列里,获取要进行抓取的请求,完成爬虫后续的工作
2.2 scrapy-redis实现分布式爬虫
接下来用scrapy-redis完成上述流程
1.首先,创建项目 和以前一样,该怎么创建还怎么创建
2.修改Spider. 将start_urls注释掉. 更换成redis_key
3.在配置文件中,添加 redis、scrapy_redis 配置
### 1 redis配置信息
REDIS_HOST = "127.0.0.1" # 主机和端口,默认就是本地(可以不写)
REDIS_PORT = 6379
# Redis默认数据库
REDIS_DB = 8
# Redis数据库的连接密码
REDIS_PARAMS = {
"password":"123456"
}
### 2 scrapy-redis配置信息 # 固定的
# 使用scrapy_redis的Scheduler,替换掉原来的Scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True # 在关闭时,是否自动保存请求信息 persist v.存留
# 使用scrapy_redis的RFPDupeFilter,替换原来的去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 将分布式存储到redis中
ITEM_PIPELINES = {
'tianya2.pipelines.Tianya2Pipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 301 # 配置redis的pipeline
}
4.在不同机器上启动
2.3 布隆过滤器
2.3.1 数据去重的方案
1.直接用set集合来存储url # 最low的方案
2.用set集合存储hash过的url # scrapy默认
3.用redis来存储hash过的请求 # scrapy-redis默认 如果请求非常非常多,redis压力是很大的 实际已经够了
4.用布隆过滤器
2.3.2 布隆过滤器的原理
布隆过滤器:极小内存,快速校验是否重复。其实它里面就是一个改良版的bitmap,何为bitmap?
假设提前准备好一个数组,首先把源数据经过hash计算,计算得出一个数字,然后按照该数字,来找到数组下标对应的位置,设置成1
但这样有个不好的现象,容易误判。若hash算法选的不够好,很容易搞错,那怎么办?多选几个hash算法
a = 李嘉诚
b = 张翠山
[0],[0],[0],[0],[0],[0],[0],[0],[0],[0]
hash1(a) = 3
hash2(a) = 4
hash1(b) = 2
hash2(b) = 5
[0],[0],[1],[1],[1],[1],[0],[0],[0],[0]
# 查找的时候:
重新按照hash函数的顺序, 再执行一遍,依然会得到多个值,
分别去这多个位置看是否是1
若全是1, 就存在 若有一个是0, 就没有
2.4 scrapy-redis使用布隆过滤器
在scrapy-redis中,想要使用布隆过滤器是非常简单的.
可以自定义实现布隆过滤器的逻辑,但建议直接用第三方,就可以了
# 1.安装布隆过滤器
pip install scrapy_redis_bloomfilter
# 2.settings.py 配置
# 去重类,要使用 BloomFilter 请替换 DUPEFILTER_CLASS
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# 哈希函数的个数 默认为 6 可自行修改
BLOOMFILTER_HASH_NUMBER = 6
# BloomFilter的bit参数 默认为30 占用 128MB空间 去重量级1亿
BLOOMFILTER_BIT = 30