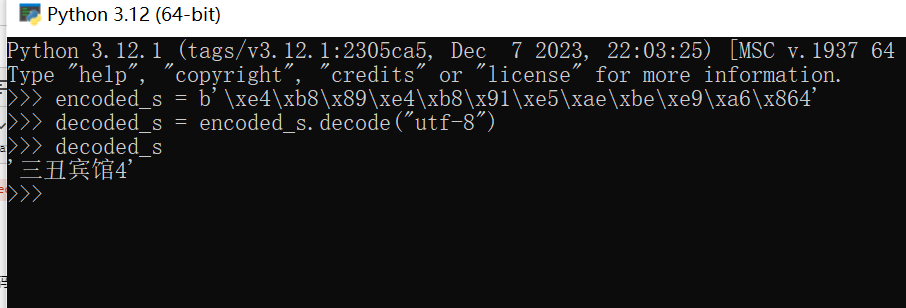
\x 开头编码的数据解码成中文
在宾馆让单片机连wifi,可惜不能显示汉字,显示都是utf-8码:
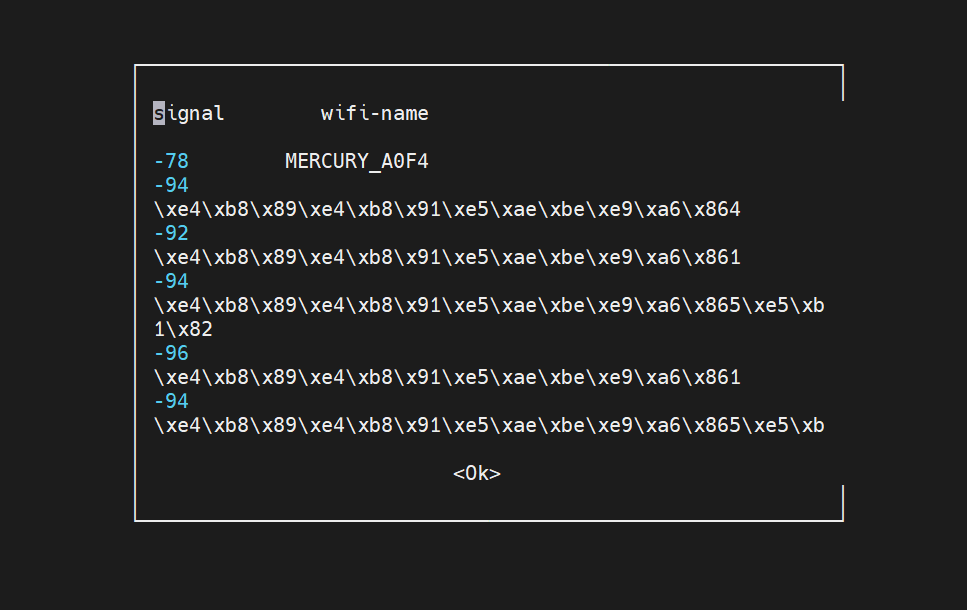
可以用python解读这些 \x开头的字符串,比如第一个 \xe4\xb8\x89\xe4\xb8\x91\xe5\xae\xbe\xe9\xa6\x864
可以在python 输入以下命令:
先把错误的方式展示给你:
# 错误的使用方式
s = "你好世界"
decoded_s = s.decode("utf-8") # 这里会抛出错误
'str' object has no attribute 'decode'. Did you mean: 'encode'?这个错误表明你试图在一个字符串('str' object)上调用decode方法,但是字符串类型没有decode方法。decode方法通常用于字节串(byte string),即类型bytes。这个错误提示还建议你可能想要调用的是encode方法,该方法用于将字符串转换为字节串。
解决方法:
-
如果你的目的是将字节串转换为字符串(通常用于解码操作),确保你在一个字节串上调用
decode方法。 -
如果你的目的是将字符串转换为字节串(通常用于编码操作),确保你在一个字符串对象上调用
encode方法。
正确的方式
# 正确的使用方式
# 将字符串转换为字节串
encoded_s = s.encode("utf-8")
# 将字节串解码为字符串
decoded_s = encoded_s.decode("utf-8")所以正确的办法应该是:
# 以文章的案例,测试
encoded_s = b'\xe4\xb8\x89\xe4\xb8\x91\xe5\xae\xbe\xe9\xa6\x864' #字节串以 b开头
decoded_s = encoded_s.decode("utf-8")结果如下: