欧拉22.03版本openstack高可用集群部署
1.整体规划
|
host
|
service
|
remark
|
|---|---|---|
| ha01-03 | 1.haproxy 2.keepalived |
1.高可用 vip:10.167.21.96 |
| controller01-03 | 1. keystone 2. glance-api , glance-registry 3. nova-api, nova-conductor, nova-consoleauth, nova-scheduler, nova-novncproxy 4. neutron-api, neutron-openvswitch-agent, neutron-dhcp-agent, neutron-metadata-agent, neutron-l3-agent 5. cinder-api, cinder-schedulera 6. dashboard 7. mariadb, rabbitmq, memcached等 |
1.控制节点: keystone, glance, horizon, nova&neutron管理组件; 2.网络节点:虚机网络,L2(虚拟交换机)/L3(虚拟路由器),dhcp,route,nat等; 3.openstack基础服务 |
| compute01-03 | 1. nova-compute 2. neutron-openvswitch-agent, neutron-metadata-agent, neutron-l3-agent 3. cinder-volume(如果后端使用共享存储,建议部署在controller节点) |
1.计算节点:hypervisor(kvm); 2.网络节点:虚机网络 L2(虚拟交换机)/L3(虚拟路由器)等; |
| ceph01-03 | 1. ceph-mon, ceph-mgr 2. ceph-osd |
1.存储节点:调度,监控(ceph)等组件; 2.存储节点:卷服务等组件 |
配置网卡
控制节点
找到一块没有绑定内网ip的网卡
cat > /etc/sysconfig/network-scripts/ifcfg-enp4s0 <<EOFNAME=enp4s0DEVICE=enp4s0TYPE=EthernetONBOOT="yes"BOOTPROTO="none"EOF#重新加载enp4s0网卡设备nmcli con reload && nmcli con up enp4s0 |
2.环境准备
1.host文件配置
所有机器执行相关host配置
echo "# controller-node10.167.21.91 node0110.167.21.93 node0210.167.21.97 node03" >> /etc/hosts#分边每台机器设置主机名hostnamectl set-hostname node01hostnamectl set-hostname node02hostnamectl set-hostname node03 |
2.配置集群ssh信任关系
ssh-keygenssh-copy-id 10.167.21.91ssh-copy-id 10.167.21.93ssh-copy-id 10.167.21.97 |
3.优化ssh登录速度,
所有节点
sed -i 's/#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_configsystemctl restart sshd |
4.内核参数优化
所有节点
echo 'modprobe br_netfilter' >> /etc/rc.d/rc.localchmod 755 /etc/rc.d/rc.localmodprobe br_netfilterecho 'net.ipv4.ip_forward = 1' >> /etc/sysctl.confecho 'net.bridge.bridge-nf-call-iptables=1' >> /etc/sysctl.confecho 'net.bridge.bridge-nf-call-ip6tables=1' >>/etc/sysctl.confsysctl -p |
5.在控制节点添加,允许本地不存在 IP 绑定监听端口,允许运行中的 HAProxy 实例绑定端口到VIP
echo 'net.ipv4.ip_nonlocal_bind = 1' >> /etc/sysctl.confsysctl -p |
6.安装基础软件包
所有节点
1.环境准备
dnf install git python3-devel libffi-devel gcc openssl-devel python3-libselinux ansible net-tools.x86_64 -y |
安装虚拟环境依赖项
-
创建一个虚拟环境并将其激活: 使用虚拟环境是为了避免安装依赖项时和系统包出现冲突时候引发不必要的麻烦。
python3 -m venv /path/to/venvsource /path/to/venv/bin/activate |
在运行任何依赖于安装在其中的包的命令之前,应该激活虚拟环境。
-
确保pip为最新版
pip install -U pip |
配置pip源
mkdir ~/.pipcat > ~/.pip/pip.conf << EOF[global]trusted-host=mirrors.aliyun.comindex-url=https://mirrors.aliyun.com/pypi/simple/EOF |
安装Ansible。Kolla Ansible需要最低版本为4,最高版本为5。
pip install 'ansible>=4,<6' |
2.安装kolla-ansible
选取一台机器执行
1.使用pip安装kolla ansible及其依赖项。
pip install git+https://opendev.org/openstack/kolla-ansible@stable/zed |
这一步可能会出现报错,是由于服务器ssl证书没有第三方认证,可以通过此配置解决:
git config --global http.sslVerify "false" |
2.创建/etc/kolla目录。
mkdir -p /etc/kollachown $USER:$USER /etc/kolla |
3.将globals.yml和passwords.yml复制到/etc/kolla目录。
cp -r /path/to/venv/share/kolla-ansible/etc_examples/kolla/* /etc/kolla |
4.将一体化和多节点清单文件复制到当前目录(建议是/etc/kolla目录)。
cp /path/to/venv/share/kolla-ansible/ansible/inventory/* /etc/kolla |
5.对于虚拟环境中的all-in-one场景,将以下内容添加到all-in-one文件的最开始:
localhost ansible_python_interpreter=python |
修改ansible配置文件
cat << EOF | sed -i '/^\[defaults\]$/ r /dev/stdin' /etc/ansible/ansible.cfghost_key_checking=Falsepipelining=Trueforks=100EOF |
修改multinode inventory文件,其他默认即可
[control]# These hostname must be resolvable from your deployment hostnode01node02node03[network]node01node02node03[compute]node01node02node03[monitoring]node01[storage]node01node02node03 |
检查inventory配置是否正确,执行:
ansible -i multinode all -m ping |
6.安装Ansible Galaxy依赖项(Yoga版本以后):
kolla-ansible install-deps |
7.生成密码
kolla-genpwd |
修改keystone_admin_password可以修改为自定义,在登录dashboard会用到
sed -i 's#keystone_admin_password:.*#keystone_admin_password: Bjcj@123#g' /etc/kolla/passwords.yml$ cat /etc/kolla/passwords.yml | grep keystone_admin_passwordkeystone_admin_password: Bjcj@123 |
8.配置globals.yml
-
镜像选项 Kolla可以选择多种镜像版本:
-
CentOS Stream (centos)
-
Debian (debian)
-
Rocky (rocky)
-
Ubuntu (ubuntu)
-
本次部署的主机操作系统为CentOS Stream 9.按理说应该选择centos镜像。但是上面提到不会发布基于CentOS Stream 9的镜像。因此这里推荐选择rocky。(我试过centos,确实不行)
cp /etc/kolla/globals.yml{,.bak}cat >> /etc/kolla/globals.yml <<EOF#version 暂时使用rocky适配后改为欧拉kolla_base_distro: "rocky"kolla_install_type: "binary"#vipkolla_internal_vip_address: "10.167.21.96"#docker registrydocker_registry: "quay.nju.edu.cn"#docker_namespace: "kollaimage"#networknetwork_interface: "enp1s0"neutron_external_interface: "enp4s0"neutron_plugin_agent: "openvswitch"enable_neutron_provider_networks: "yes"#storageenable_cinder: "yes"enable_cinder_backend_lvm: "yes"#masakari 高可用开启配置enable_hacluster: "yes"enable_masakari: "yes"EOF |
pacemaker-remote安装在计算节点,不能同时安装pacemaker与pacemaker-remote 会造成一个起不起来,本质是一样的,remote没有投票权,主控安装pacemaker,后面kolla-ansible里面要做适配是主控跟计算同时存在只装pacemaker
参数说明:
kolla_base_distro: kolla镜像基于不同linux发型版构建,主机使用centos这里对应使用centos类型的docker镜像即可。
kolla_install_type: kolla镜像基于binary二进制和source源码两种类型构建,实际部署使用binary即可。
openstack_release: openstack版本可自定义,会从dockerhub拉取对应版本的镜像
kolla_internal_vip_address: 单节点部署kolla也会启用haproxy和keepalived,方便后续扩容为高可用集群,该地址是ens33网卡网络中的一个可用IP。
docker_registry: 默认从dockerhub拉取镜像,这里使用阿里云镜像仓库,也可以本地搭建仓库,提前推送镜像上去。但该仓库目前只有train和ussuri版本的镜像,如何自己推送镜像参考该博客的其他文章。
docker_namespace: 阿里云kolla镜像仓库所在的命名空间,dockerhub官网默认是kolla。
network_interface: 管理网络的网卡
neutron_external_interface: 外部网络的网卡
neutron_plugin_agent: 默认启用openvswitch
enable_neutron_provider_networks: 启用外部网络
enable_cinder: 启用cinder
enable_cinder_backend_lvm: 指定cinder后端存储为lvm
enable_masakari: 开启masakari服务
修改docker官方yum源为阿里云yum源,另外配置docker镜像加速,指定使用阿里云镜像加速
mkdir -p /data/docker/data-root #所有节点执行sed -i 's/^docker_yum_url/#&/' /path/to/venv/share/kolla-ansible/ansible/roles/barbican/defaults/main.ymlsed -i 's/^docker_custom_config/#&/' /path/to/venv/share/kolla-ansible/ansible/roles/barbican/defaults/main.ymlcat >> /path/to/venv/share/kolla-ansible/ansible/roles/barbican/defaults/main.yml <<EOFdocker_yum_url: "https://mirrors.aliyun.com/docker-ce/linux/{{ ansible_distribution | lower }}"docker_custom_config: {"registry-mirrors": ["https://uyah70su.mirror.aliyuncs.com"],"data-root": "/data/docker/data-root","log-opts": {"max-size": "10m","max-file": "3"}}EOF |
9.部署
#引导服务器 all-in-one 单节点模式kolla-ansible -i ./all-in-one bootstrap-servers#拉取镜像kolla-ansible -i all-in-one pull#部署前检查#kolla-ansible -i ./all-in-one prechecks开始部署kolla-ansible -i ./all-in-one deploy#multinode 多节点模式kolla-ansible -i ./multinode bootstrap-servers#部署检查kolla-ansible -i ./multinode prechecks#拉取镜像kolla-ansible -i ./multinode pull#执行部署kolla-ansible -i ./multinode deploy#生成认证文件kolla-ansible post-deploycat /etc/kolla/admin-openrc.sh |
如果precheck时发生了报错: “msg”: “Hostname has to resolve uniquely to the IP address of api_interface” ,将‘127.0.0.1 localhost’注释掉即可
报错信息:
TASK [cinder : Checking LVM volume group exists for Cinder] *************************************************************************************************************************************************
fatal: [localhost]: FAILED! => {"changed": false, "cmd": ["vgs", "cinder-volumes"], "delta": "0:00:00.045743", "end": "2020-12-07 02:27:49.501416", "failed_when_result": true, "msg": "non-zero return code", "rc": 5, "start": "2020-12-07 02:27:49.455673", "stderr": " Volume group \"cinder-volumes\" not found.\n Cannot process volume group cinder-volumes", "stderr_lines": [" Volume group \"cinder-volumes\" not found.", " Cannot process volume group cinder-volumes"], "stdout": "", "stdout_lines": []}
原因和解决方法:
未创建cinder-volumes的vg信息
如果启用cinder还需要在storage01节点额外添加一块磁盘,这里以/dev/sdc为例,在storage01节点执行 如果存在多个大盘一起创建
pvcreate /dev/sdcpvcreate /dev/sddvgcreate cinder-volumes /dev/sdc /dev/sdd |
注意卷组名称为cinder-volumes,默认与globals.yml一致。
[root@kolla ~]# cat /etc/kolla/globals.yml | grep cinder_volume_group#cinder_volume_group: "cinder-volumes" |
11.使用OpenStack
#命令行#安装CLI客户端pip install python-openstackclient -c https://releases.openstack.org/constraints/upper/zed#生成openrc文件kolla-ansible post-deploy#使用openrc文件. /etc/kolla/admin-openrc.sh#接下来就可以使用OpenStack CLI了 |
网页 浏览器中访问kolla_internal_vip_address,输入账号密码即可,账号密码可在openrc文件中查看
3.部署skyline
主控节点都需要安装
1.创建数据库
MariaDB [(none)]> CREATE DATABASE IF NOT EXISTS skyline DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;MariaDB [(none)]> GRANT ALL PRIVILEGES ON skyline.* TO 'skyline'@'localhost' IDENTIFIED BY 'skyline';MariaDB [(none)]> GRANT ALL PRIVILEGES ON skyline.* TO 'skyline'@'%' IDENTIFIED BY 'skyline';# 然后创建服务凭证source /etc/kolla/admin-openrc.shopenstack user create --domain default --password Bjcj@123 skylineopenstack role add --project service --user skyline admin |
2.配置文件
mkdir /etc/skylinevi /etc/skyline/skyline.yamldefault: access_token_expire: 3600 access_token_renew: 1800 cafile: '' cors_allow_origins: [] database_url: 'mysql://root:6LmDqfev0nU6ftvVIDWcuCd4ZDP692WPJlhGucsz@10.167.21.96:3306/skyline' debug: false log_dir: ./log log_file: skyline.log policy_file_path: /etc/skyline/policy policy_file_suffix: policy.yaml prometheus_basic_auth_password: '' prometheus_basic_auth_user: '' prometheus_enable_basic_auth: false prometheus_endpoint: http://10.167.21.96:9091 secret_key: aCtmgbcUqYUy_HNVg5BDXCaeJgJQzHJXwqbXr0Nmb2o session_name: session ssl_enabled: trueopenstack: base_domains: - heat_user_domain default_region: RegionOne enforce_new_defaults: true extension_mapping: floating-ip-port-forwarding: neutron_port_forwarding fwaas_v2: neutron_firewall qos: neutron_qos vpnaas: neutron_vpn interface_type: public keystone_url: http://10.167.21.96:5000/v3/ nginx_prefix: /api/openstack reclaim_instance_interval: 604800 service_mapping: baremetal: ironic compute: nova container: zun container-infra: magnum database: trove dns: designate identity: keystone image: glance instance-ha: masakari key-manager: barbican load-balancer: octavia network: neutron object-store: swift orchestration: heat placement: placement sharev2: manilav2 volumev3: cinder sso_enabled: false sso_protocols: - openid sso_region: RegionOne system_admin_roles: - admin - system_admin system_project: service system_project_domain: Default system_reader_roles: - system_reader system_user_domain: Default system_user_name: skyline system_user_password: 'Bjcj@123'setting: base_settings: - flavor_families - gpu_models - usb_models flavor_families: - architecture: x86_architecture categories: - name: general_purpose properties: [] - name: compute_optimized properties: [] - name: memory_optimized properties: [] - name: high_clock_speed properties: [] - architecture: heterogeneous_computing categories: - name: compute_optimized_type_with_gpu properties: [] - name: visualization_compute_optimized_type_with_gpu properties: [] gpu_models: - nvidia_t4 usb_models: - usb_cgg |
根据实际的环境修改以下参数
database_url
修改为如下,注意:ip是浮动IP,SKYLINE_DBPASS这个是数据库用户密码 可以自定义
database_url: mysql://skyline:SKYLINE_DBPASS@10.167.21.96:3306/skyline
keystone_url
将 127.0.0.1 修改为浮动IP
keystone_url: http://10.167.21.96:5000/v3/
prometheus_endpoint: http://10.167.21.96:9091
system_user_password
设置你的skyline密码
system_user_password: 'Bjcj@123'
3.初始化
docker run -d --name skyline_bootstrap -e KOLLA_BOOTSTRAP="" -v /etc/skyline/skyline.yaml:/etc/skyline/skyline.yaml --net=host 99cloud/skyline:latest# 检查日志输出结尾是否是"exit 0"docker logs skyline_bootstrap#初始化引导完成后运行 skyline 服务docker rm -f skyline_bootstrapdocker run -d --name skyline --restart=always -v /etc/skyline/skyline.yaml:/etc/skyline/skyline.yaml --net=host 99cloud/skyline:latest#查看服务root@controller:/etc/skyline# netstat -tnlp |grep 9999tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 453702/nginx: maste |
4.ceph 安装
1.集群规划
|
主机
|
角色
|
IP
|
|---|---|---|
| node-01 | mon,mgr,work,cephadm | 10.167.21.91 |
| node-02 | mon,mgr,work | 10.167.21.93 |
| node-03 | mon,mgr,work | 10.167.21.97 |
1.下载安装ceph
dnf -y install cephadmcephadm add-repo --release octopus./cephadm installcephadm bootstrap --mon-ip 10.167.21.91#使用docker安装可以用--dockermkdir -p /etc/ceph## 将 cephadm 文件拷贝到其他节点上 # for i in {2..3};do scp -rp /usr/sbin/cephadm node0$i:/usr/sbin/;done |
如果出现错误:ERROR: Distro openeuler version 22.03 not supported
## DISTRO_NAMES 这个字典中增加 openeuler 主要欧拉是在yumdnf这个类里面 7654 DISTRO_NAMES = { 7655 'centos': ('centos', 'el'), 7656 'rhel': ('centos', 'el'), 7657 'scientific': ('centos', 'el'), 7658 'rocky': ('centos', 'el'), 7659 'openeuler': ('openeuler', 'el'), ## 增加openeuler 系统的支持 7660 'almalinux': ('centos', 'el'), 7661 'ol': ('centos', 'el'), 7662 'fedora': ('fedora', 'fc'), 7663 'mariner': ('mariner', 'cm'), 7664 }## 同时修改self.major =8 否则是22找不到包 7665 self.major = 8#同时修改添加,'--skip-broken' 否则欧拉最新包不支持epel call_throws(self.ctx, [self.tool, 'install', '-y', 'epel-release','--skip-broken']) |
附录:cephadm 不使用默认安装promethes,node_exporter方法
使用自定义镜像
可以基于其他镜像安装或升级监控组件。为此,需要首先将要使用的镜像的名称存储在配置中。以下配置选项可用。
- container_image_prometheus
- container_image_grafana
- container_image_alertmanager
- container_image_node_exporter
可以使用命令ceph config设置自定义镜像:
ceph config set mgr mgr/cephadm/<option_name> <value>
例如:
ceph config set mgr mgr/cephadm/container_image_prometheus prom/prometheus:v1.4.1
如果已经有正在运行的监视堆栈守护程序的类型与您已更改其镜像的类型相同,则必须重新部署守护程序才能让它们实际使用新镜像。
例如,如果您更改了 prometheus 镜像
ceph orch redeploy prometheus
笔记: 通过设置自定义镜像,默认值将被覆盖(但不会被覆盖)。当更新可用时,默认值会更改。通过设置自定义镜像,您将无法自动更新已设置自定义镜像的组件。您将需要手动更新配置(镜像名称和标签)才能安装更新。
如果您选择使用建议,则可以重置之前设置的自定义镜像。之后,将再次使用默认值。ceph config rm用于重置配置选项:
ceph config rm mgr mgr/cephadm/<option_name>
例如:
ceph config rm mgr mgr/cephadm/container_image_prometheus
使用自定义配置文件
通过覆盖 cephadm 模板,可以完全自定义监控服务的配置文件。
在内部,cephadm 已经使用Jinja2模板为所有监控组件生成配置文件。为了能够自定义 Prometheus、Grafana 或 Alertmanager 的配置,可以为每个将用于配置生成的服务存储一个 Jinja2 模板。每次部署或重新配置此类服务时,都会评估此模板。这样,自定义配置将被保留并自动应用于这些服务的未来部署。
笔记: 当 cephadm 的默认配置更改时,自定义模板的配置也会保留。如果要使用更新后的配置,则需要在每次升级 Ceph 后手动迁移自定义模板。
选项名称
可以覆盖将由 cephadm 生成的文件的以下模板。这些是与 ceph config-key set 一起存储时要使用的名称:
- services/alertmanager/alertmanager.yml
- services/grafana/ceph-dashboard.yml
- services/grafana/grafana.ini
- services/prometheus/prometheus.yml
您可以在以下位置src/pybind/mgr/cephadm/templates查找 cephadm 当前使用的文件模板:
- services/alertmanager/alertmanager.yml.j2
- services/grafana/ceph-dashboard.yml.j2
- services/grafana/grafana.ini.j2
- services/prometheus/prometheus.yml.j2
用法
以下命令应用单行值:
ceph config-key set mgr/cephadm/<option_name> <value>
要将文件的内容设置为模板,请使用以下-i参数:
ceph config-key set mgr/cephadm/<option_name> -i $PWD/<filename>
笔记: 当使用文件作为输入时,config-key必须使用文件的绝对路径。
然后需要重新创建服务的配置文件。这是使用reconfig完成的。有关更多详细信息,请参见以下示例。
示例
# set the contents of ./prometheus.yml.j2 as template
ceph config-key set mgr/cephadm/services/prometheus/prometheus.yml \
-i $PWD/prometheus.yml.j2
# reconfig the prometheus service
ceph orch reconfig prometheus2.生成配置文件
部署完成后的提示信息中获取dashboard的账户以及密码,登陆dashboard
注意这里使用https协议https://node01:8443/
使用初始化的账号密码并且修改密码
3.配置集群
将集群的SSH公钥安装到新加主机的root用户authorized_keys文件中
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node02ssh-copy-id -f -i /etc/ceph/ceph.pub root@node03#告诉 Ceph 集群有新节点加入cephadm shellceph orch host add node02ceph orch host add node03 |
3台都加入集群后,会发现mon节点自动扩展为5节点,mgr节点扩展为2节点
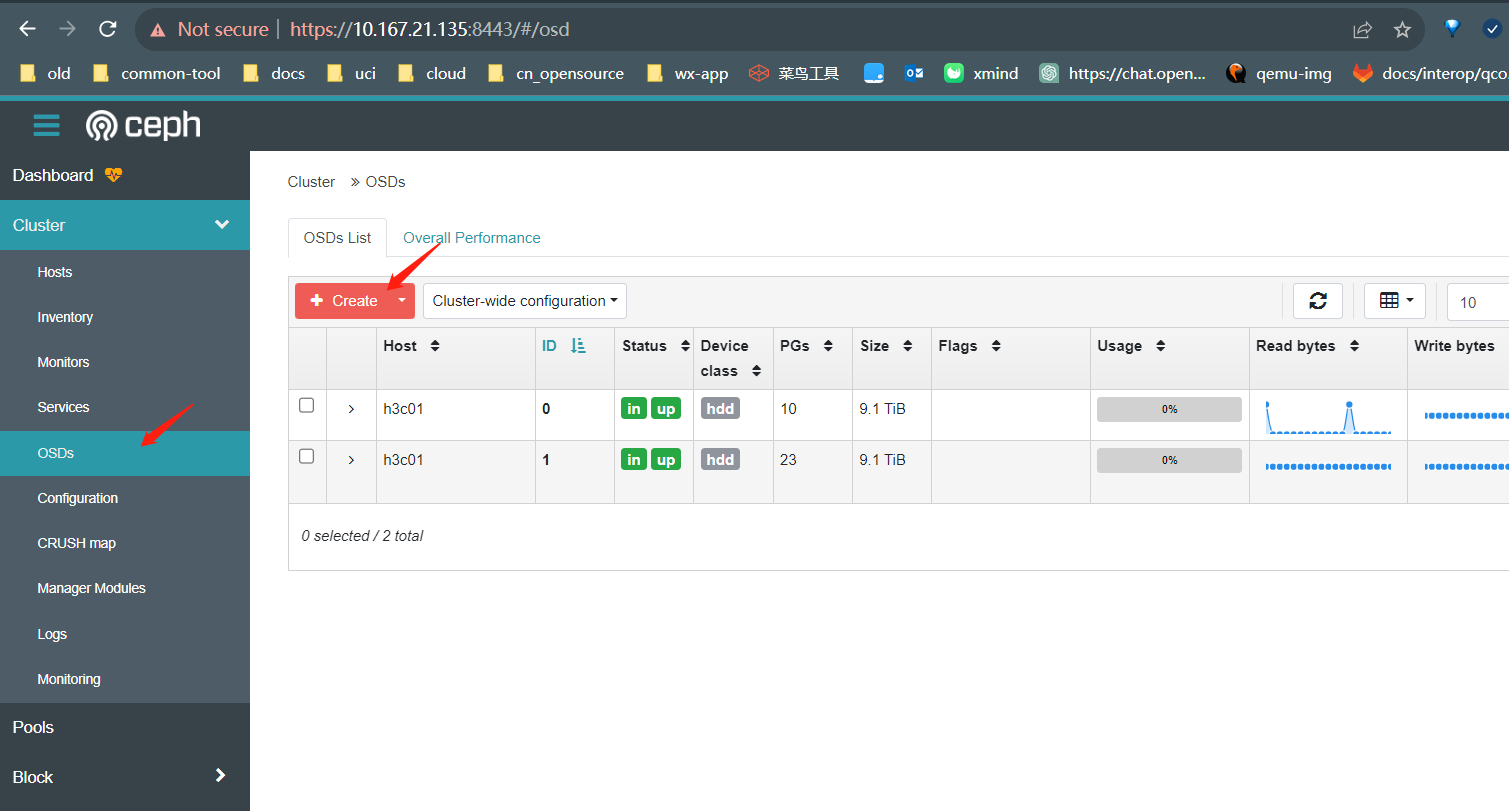
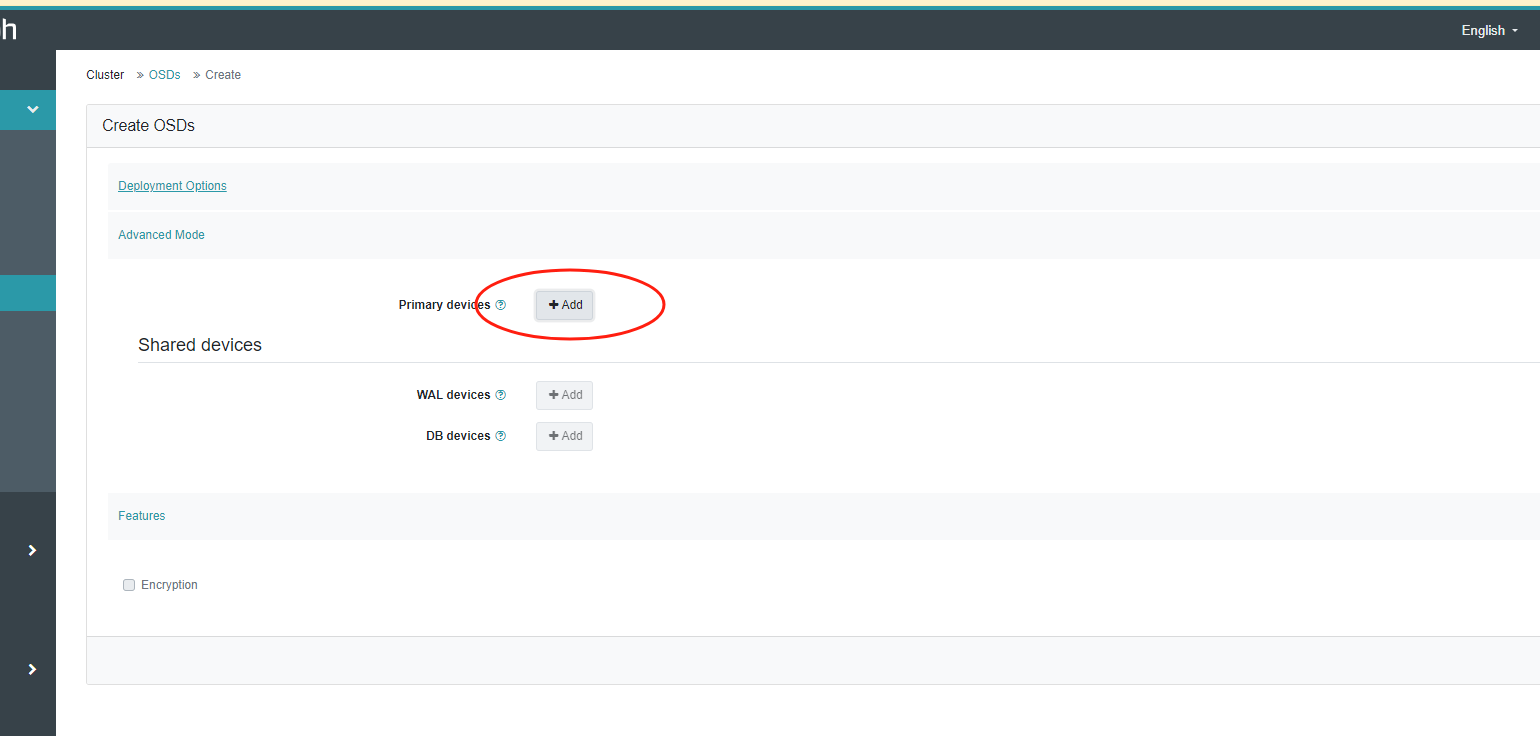
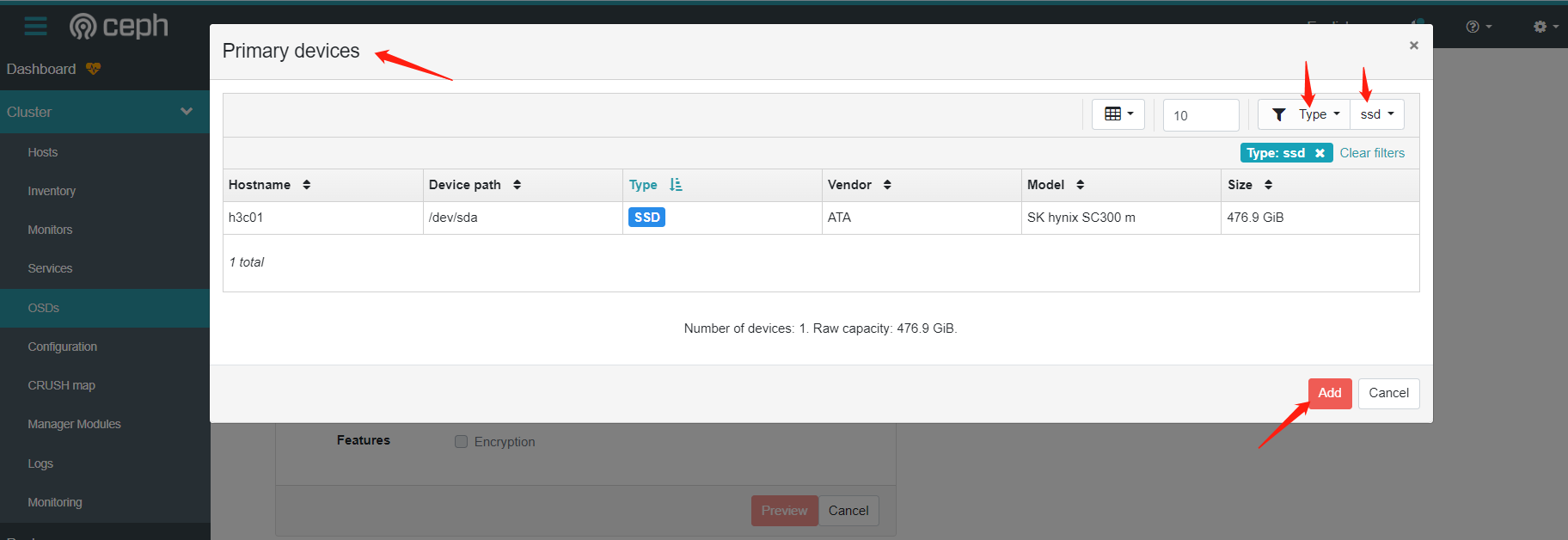
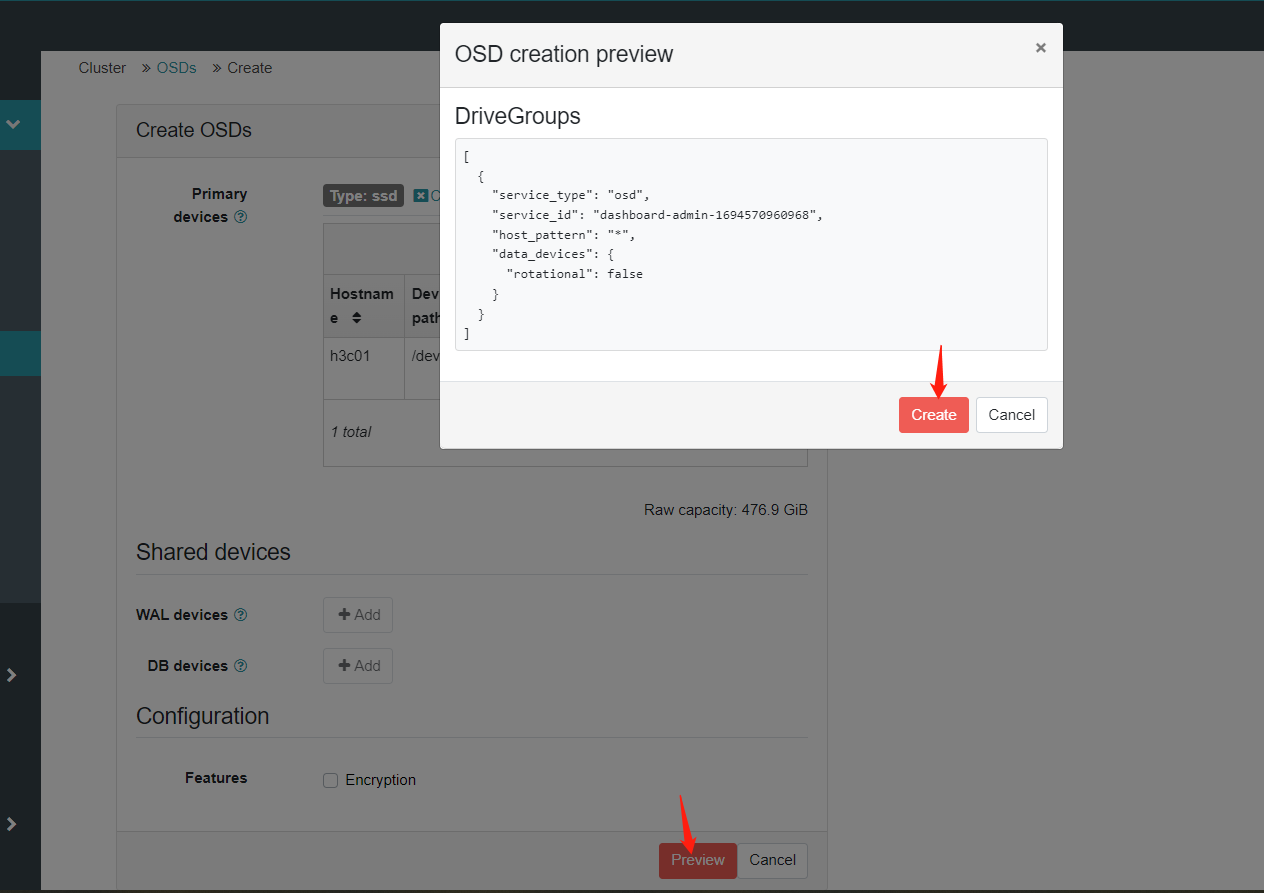
4.配置osd
5.创建存储池
在dashboard添加存储池,并将存储池的application修改为rbd
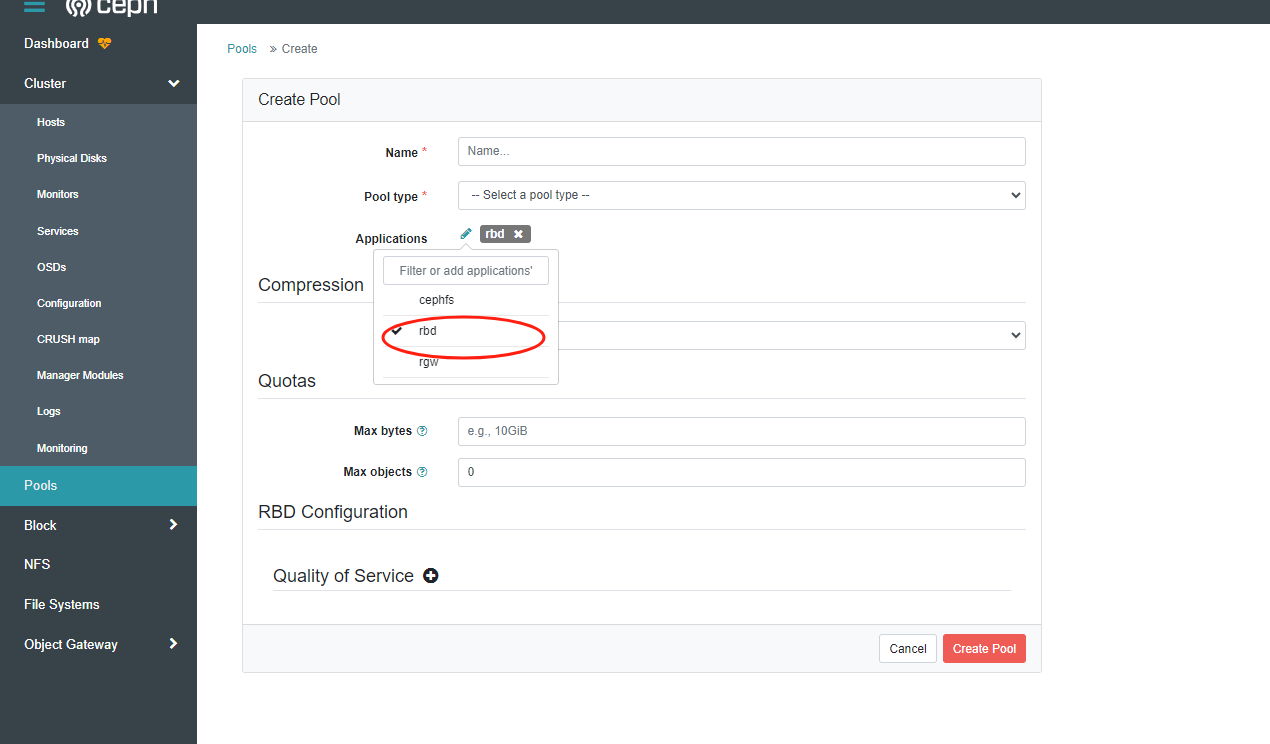
6.openstack 集成ceph
修改kolla-ansible配置 vi /etc/kolla/global.yml 增加
cinder_backend_ceph: "yes"glance_backend_ceph: "yes"nova_backend_ceph: "yes"ceph_cinder_keyring: "ceph.client.admin.keyring"ceph_cinder_user: "admin"ceph_cinder_pool_name: "Pool0"ceph_cinder_backup_keyring: "ceph.client.admin.keyring"ceph_cinder_backup_user: "admin"ceph_cinder_backup_pool_name: "Pool0"ceph_nova_keyring: "ceph.client.admin.keyring"ceph_nova_user: "admin"ceph_nova_pool_name: "Pool0"ceph_glance_keyring: "ceph.client.admin.keyring"ceph_glance_user: "admin"ceph_glance_pool_name: "Pool0" |
2 将/etc/kolla/config中将ceph相关配置文件移入或修改如下
a.cinder设置
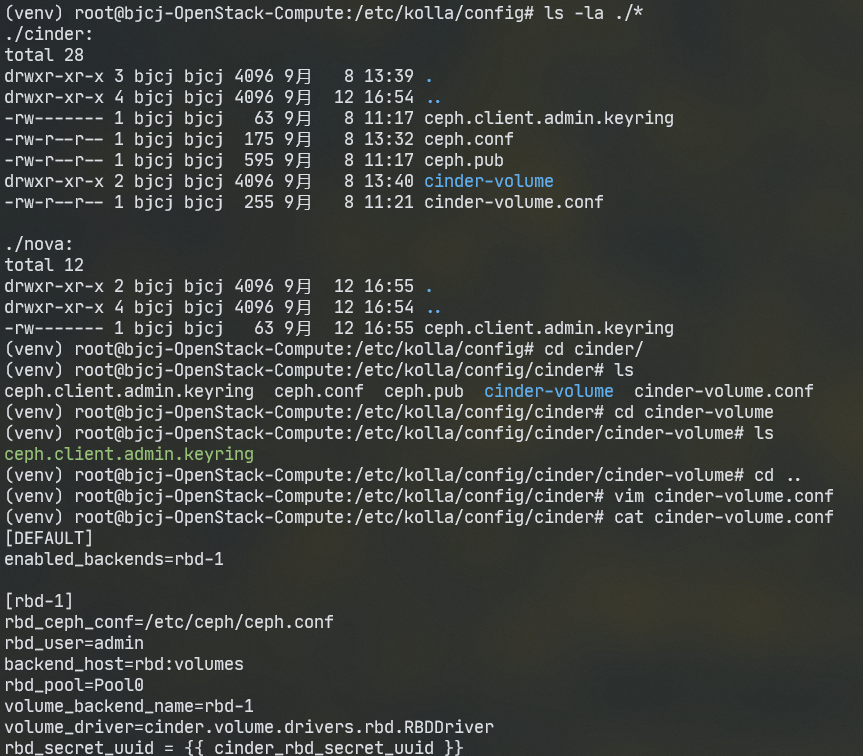
[DEFAULT]enabled_backends=rbd-1[rbd-1]rbd_ceph_conf=/etc/ceph/ceph.confrbd_user=adminbackend_host=rbd:volumesrbd_pool=Pool0volume_backend_name=rbd-1volume_driver=cinder.volume.drivers.rbd.RBDDriverrbd_secret_uuid ={{ cinder_rbd_secret_uuid }} |
b.glance设置
mkdir -p /etc/kolla/config/glance/cd /etc/kolla/config/glance/vi glance-api.confcp /etc/ceph/* /etc/kolla/config/glance/[glance_store]stores = rbddefault_store = rbdrbd_store_pool = imagesrbd_store_user = glancerbd_store_ceph_conf = /etc/ceph/ceph.conf |
同样拷贝ceph配置到glance里面
c.cinder_backup设置
mkdir -p /etc/kolla/config/cinder/cinder-backupcp /etc/ceph/ceph.client.admin.keyring /etc/kolla/config/cinder/cinder-backup/cp /etc/ceph/ceph.client.admin.keyring /etc/kolla/config/cinder/cinder-backup/ceph.client.cinder-backup.keyringvi /etc/kolla/config/cinder/cinder-backup.conf[DEFAULT]backup_ceph_conf=/etc/ceph/ceph.confbackup_ceph_user=adminbackup_ceph_chunk_size = 134217728backup_ceph_pool=Pool0backup_driver = cinder.backup.drivers.ceph.CephBackupDriverbackup_ceph_stripe_unit = 0backup_ceph_stripe_count = 0restore_discard_excess_bytes = true |
d.nova配置
mkdir -p /etc/kolla/config/novavi /etc/kolla/config/nova/nova-compute.confcp /etc/ceph/* /etc/kolla/config/nova/[libvirt]images_rbd_pool=vmsimages_type=rbdimages_rbd_ceph_conf=/etc/ceph/ceph.confrbd_user=nova |
3.安装
注意:ceph.conf自带的配置项前面有空格,要删除空格才能正常部署
#multinode 多节点模式kolla-ansible -i ./multinode bootstrap-servers#部署检查kolla-ansible -i ./multinode prechecks#执行部署kolla-ansible -i ./multinode deploy |