SciTech-BigDataAIML-NLP- 分词之 BPE | WordPiece | Unigram | SentencePiece 以及 sentencepiece原理与实践
BERT,XLNET分词方法bpe,wordpiece, unigram, sentencepiece 等介绍
https://blog.csdn.net/ganxiwu9686/article/details/111463211
先给结论: BERT使用的是wordpiece的 分词方法,XLNET和transformer-xl使用的是sentencepiece的切分方法。
NLP分词的形式越来越多:从最开始的字切分,词切分,发展到更细粒度的BPE,WordPiece,Unigram, 以及跨语言的 SentencePiece 的切分方法。
subword层的切分是一种有效的文本切分,可有效的减小词表大小, 并都能够覆盖所有的词,且分到的 subword 都携带一定的含义,这就能有效的解决当前机器阅读文本问题。
BPE(Byte Pair Encoding)
流行的 subword 切分方法叫做BPE: 最初用于通过查找高频的字节对组合以压缩数据。也可应用于NLP,找到表示文本的最有效方法。
FloydHub is the fastest way to build? train and
deploy deep learning models. Build deep learning
models in the cloud. Train deep learning models
对于这个案例,我们可以统计每个单词出现的次数(每一单词后面</w>表示单词的结束,告诉算法识别边界):
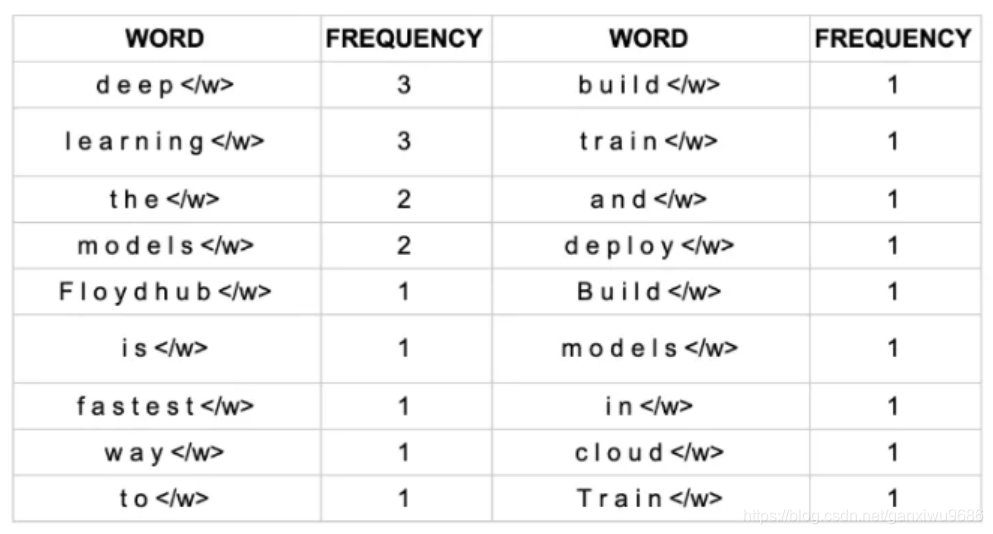
同样我们对每一个字符出现的次数做统计:
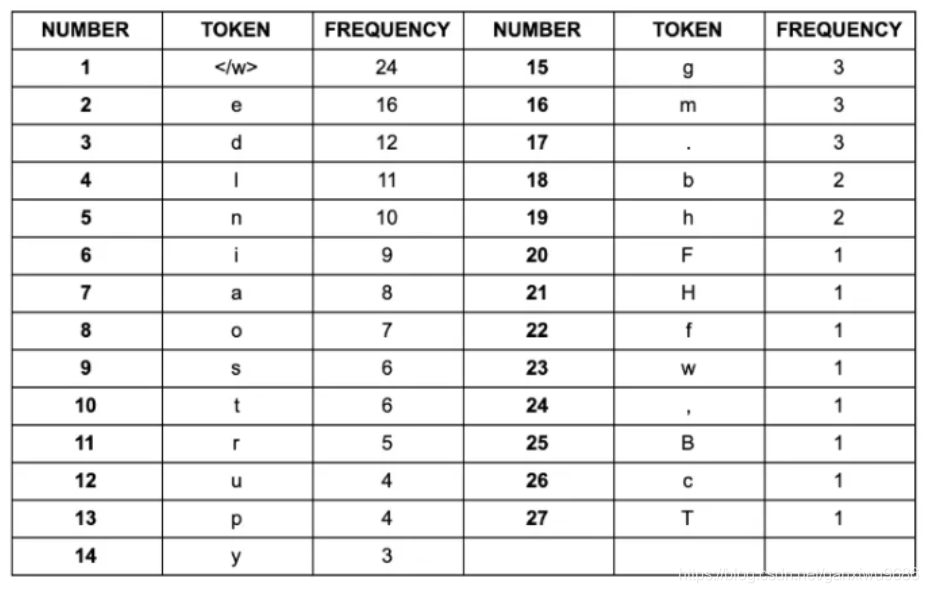
BPE算法的目标就是找到一种方法,可以用最少的token来表示你的文本。
BPE算法包含以下几步:
- 准备一个足够大的训练集
- 确定期望获得的subword词表大小
- 将单词切分成字符,并在单词后面加上
。例如"deep"变成"d e e p - 寻找最常见的成对字符例如:
- de出现7次,为最高出现频次。

- de加入字符/词 表。重新计算:
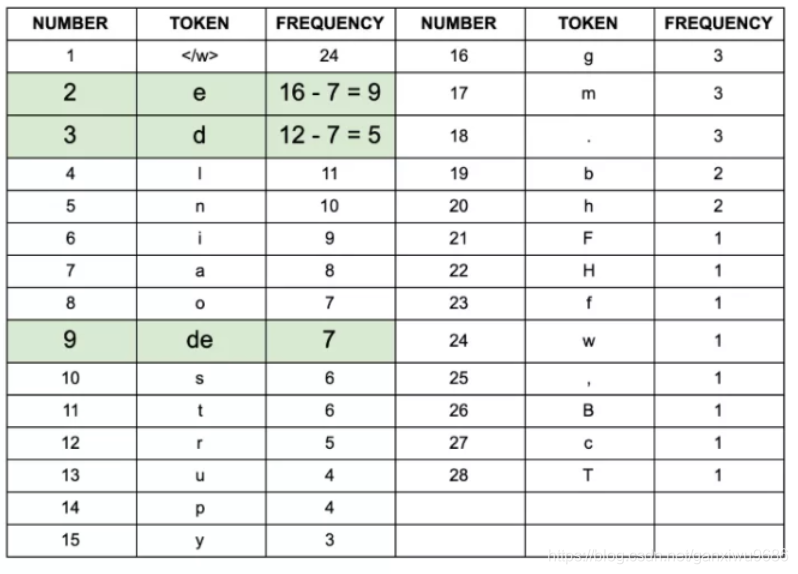
- 重复上述过程,直到达到停止条件。
- de出现7次,为最高出现频次。
Unigram(Unigram subword tokenization)
BPE算法需要最大可能的去搜索最高频共现的字符,此方法有显著缺点:就是它可能使得 最终的词表 显得存在歧义,
举个例子:倘若通过BPE我们获得如下的subword集合:
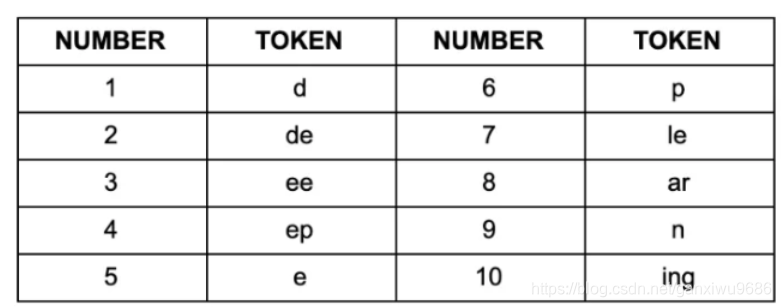
用以上 subword集合 对"deep learning"切分,你会有以下:

为了解决这个问题,我们需要 确定 subword切分的 优先级顺序,以对 相同的短语 获得相同的分词结果。
因此有人提出使用 unigram语言模型 来选择最合适的subword切分方法。
Unigram与BPE不同,该方法尝试选择最可能的切分方法,而不是去选择最好的切分方法。
Unigram子词切分方法如下所示:
- 准备一个足够的大训练语料库
- 定义期望的 subword表 大小
- 用EM算法估计每一种子词的概率
- 对于每个 subword 计算loss, 该loss表示当前subword被丢弃时似然的减少量。
按照 loss 对 subword排序,并仅保留排在前面的80%的subword - 重复以上过程,直到此表大小达到目标值,或者说在某轮迭代后词表大小不再改变。
目前为止,已经介绍两种subword切分,
但你去看当前一些流行的模型时,你还是会发现难以判断当前模型用的是哪一种子词切分算法。
但这并不代表之前的都白学,实际上大多时候,这些模型用的新方法,都以这两种模型为基础的。
例如 BERT 模型用到的 wordpiece 文本切分方法.
下面会具体介绍 WordPiece方法 与 BPE 的联系。
此外在ALBERT中用到的"SentencePiece"算法实际上是上面提到的两种算法的一种整合。
WordPiece
Word Piece方法与BPE非常的相似。
首先我们将Word Piece方法认为是BPE和unigram方法的一个trade-off方法:
- BPE 首先考察两个token并考察各token对出现的频次,然后合并拥有最高频次的两个token。它每一步仅仅考虑最常出现的token对。
- WordPiece 是考察合并特定对的token对整体的潜在影响,这是通过使用概率语言模型来实现,
每一步迭代是选择:合并 能够使得整体似然 获得最大提升的 token对(合并新的token对的概率 减去 单个token时的概率)。
尽管 WordPiece 仍是最优选择方法( 在每一次合并时候选择最优的token对合并* )。
但是 WordPiece 与 BPE 的区别在于:**WordPiece使用似然 而不 是频数 **。 - Unigram方法则不同,Unigram是纯粹基于概率的方法, 通过概率选择要合并的token, 并基于概率判断是否合并这些token。
WordPiece具体流程:
- 准备一个大的语料库
- 定义期望的subword表大小
- 将单词切分成字符
- 基于上一步构建语言模型
- 选择合并能够使得语言模型 似然增加 的字符对 作为新的subword
- 重复上一步,直到达到目标词表,或者似然増加不再明显
小结
- BPE : BPE每一次迭代用 频数 选取最优subword组合,直至最终达到设定词表大小.
- WordPiece:与BPE同用 频数 选取候选合并对象,但最终合并能够使 整体似然提升最大 的subword对.
- Unigram:完全用 概率 的模型,每一次迭代去除 subword表上一定百分比(20%)的, 使得
整体似然增加较少 的subword,直到达到设定的词表大小。
SentencePiece
SentencePiece subword切分,可以说是所有subword切分方法 的瑞士军刀。
BPE 和 Unigram 都假设 输入的带切分的文本是已经切分的,只有这样BPE才可以 统计频率,通常直接用空格切分;
但不是所有的语言都以空格分割,Unigram同样有此问题存在。
而SentencePiece则是直接输入原始文本而后可以做到所有接下来的事情。
那么SentencePiece是如何做到这点的呢?
将所有字符编码成Unicode编码(包括空格),这就避免了跨语言纠纷。
HuggingFace Tokenizers
HuggingFance这群人开发的Tokenizers包;
from tokenizers import (ByteLevelBPETokenizer, CharBPETokenizer, SentencePieceBPETokenizer, BertWordPieceTokenizer, Tokenizer)
tokenizer = SentencePieceBPETokenizer()
tokenizer.train(["/Users/abaelhe/tensorflow_datasets/aclImdb/imdb.vocab"], vocab_size=500, min_frequency=2)
output = tokenizer.encode("This is a test")
print(output.tokens)
sentencepiece原理与实践
https://zhuanlan.zhihu.com/p/159200073
1 前言
XLNET,Transformer-XL等预训练模式时,看到源代码都用到sentencepiece模型。
经过这段时间实践和应用,觉得值得在NLP领域推广和应用。
sentencepiece 开源地址为:https://github.com/google/sentencepiece
2 原理
sentencepiece由谷歌将一些 词-语言 模型有关的论文进行复现,开发开源的sentencepiece模型,可训练自己领域的模型应用,该模型可代替预训练模型(BERT,XLNET)中词表的作用。
其原理:词的四种切分方法。与中文的分词作用大体上一致,但思路上还是有区分的:
- 在中文上,把经常共现的字组合成一个词语;
- 在英文上,它会把英语单词切分更小的语义单元,减少词表的数量。
例如“机器学习领域“这个文本,按jieba会分“机器/学习/领域”,
但你想要粒度更大的切分效果,如“机器学习/领域”或不切分,这样更有利于模型提取到更多N-gram特征。
把对应的 大粒度词 加入 词汇表 也是可以去解决的。
但是智能时代,可将人力添加维护词汇表,以无需人工干预的全智能自动算法实现会更高效!精度近似人力维护。
sentencepiece 可以得到一定程度解决,甚至完美解决你的需求。
模型训练时使用统计指标,比如出现的频率,左右连接度等,还有不确定性程度来训练最终的结果。
了解算法细节可以去githup上查看相关论文。
4 训练
安装成功,就可以用自己的领域文本数据进行训练,训练的代码指令为:
spm_train --input='/home/deploy/sentencepiece/news_corpus.txt' -- model_prefix='/home/deploy/sentencepiece/mypiece' --vocab_size=320000 --character_coverage=1 --model_type='bpe'
参数说明:

5 测试
训练完模型后,可以调用模型进行效果测试。在调用模型前,先安装对应的python包:
pip install sentencepiece
我使用大小约1G的NLP相关的语料库,分别训练 unigram 和 bpe 两种模型。
另外,我还对比了XLNET开源的中文sentencepiece模型,以及jieba分词效果。
def sentence_piece():
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
text="讲解了一下机器学习领域中常见的深度学习LSTM+CRF的网络拓扑 17:了解CRF层添加的好处 18:
EmissionScore TransitionScore 19:CRF的目标函数 20:计算CRF真实路径的分数"
print("*****************text****************")
print(text)
print("*****************jieba****************")
print(' '.join(jieba.cut(text)))
print("*****************XLNET sentencepiece****************")
sp.Load("/home/deploy/pre_training/spiece.model")
print(sp.EncodeAsPieces(text))
print("***************** unigram_sentencepiece****************")
sp.Load("/home/deploy/pre_training/sentencepiece/mypiece_unigram.model")
print(sp.EncodeAsPieces(text))
print("***************** bpe_sentencepiece****************")
sp.Load("/home/deploy/pre_training/sentencepiece/mypiece_pbe.model")
print(sp.EncodeAsPieces(text))
6 结语
从测试结果可以看出:
sentencpiece 更倾向输出更大粒度的词,像把“机器学习领域中”放在一起,说明这个词语在语料库中出现的频率很高。
XLNET的别人开源的模型跨领域表现的并不好,在面向自己应用场景时,需自己训练。
jieba来对比,会发现后者切分的可能并不是一个语言词,例如“的网络”,但这个N-gram特征对模型来说影响并不是很大。
但是,它还有改进空间的,切分如“的网络”这样的结果,加一个 停用词 流程,可能会更好。