6. 字符编码
1. 引入
字符串类型、文本文件的内容都是由字符组成的,但凡涉及到字符的存取,都需要考虑字符编码的问题
2. 知识储备
2.1 三大核心硬件
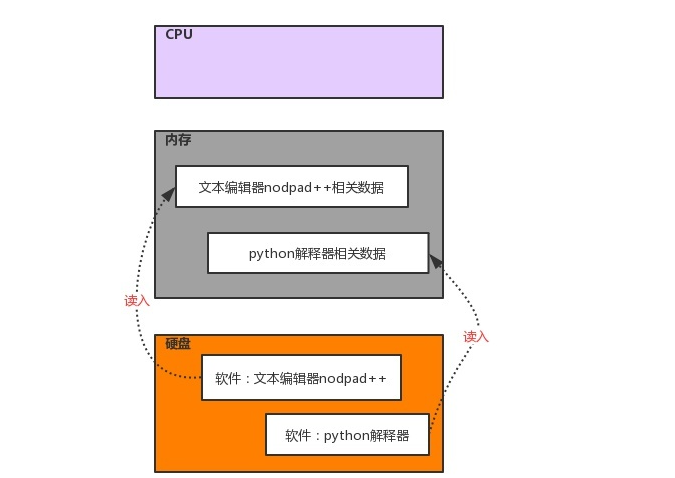
所有软件都是运行硬件之上的,与运行软件相关的三大核心硬件为cpu、内存、硬盘,需要明确三点
1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
2.2 文本编辑器读取文件内容的流程
阶段1、启动一个文件编辑器(文本编辑器如nodepad++,pycharm,word)
阶段2、文件编辑器会将文件内容从硬盘读入内存
阶段3、文本编辑器会将刚刚读入内存中的内容显示到屏幕
2.3 python解释器执行文件的流程
以python test.py为例,执行流程如下
阶段1、启动python解释器,此时就相当于启动了一个文本编辑器
阶段2、python解释器相当于文本编辑器,从硬盘上将test.py的内容读入到内存中
阶段3、python解释器解释执行刚刚读入的内存的内容,开始识别python语法
2.4 总结
python解释器与文件本编辑的异同如下
#1、相同点:前两个阶段二者完全一致,都是将硬盘中文件的内容读入内存,详解如下
python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
#2、不同点:在阶段3时,针对内存中读入的内容处理方式不同,详解如下
文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,
可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法)
3. 编码和解码的过程
内存中固定使用的是unicode,我们能改变的只是存入到内存以后,以什么样的编码存入到磁盘中
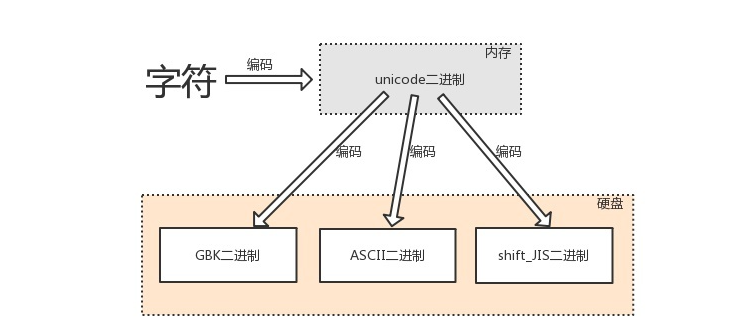
3.1 编码的过程
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
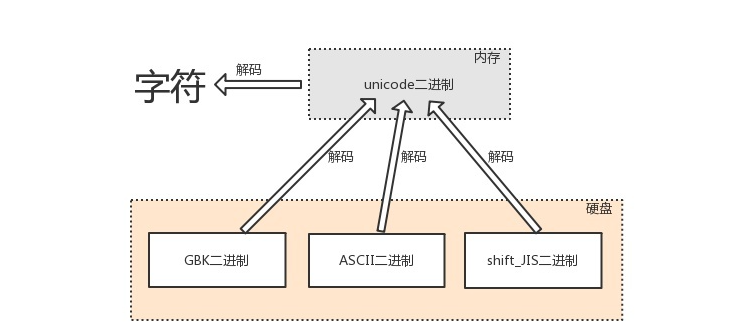
3.2 解码的过程
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
3.3 文本文件存取乱码的问题
存乱了: 解决方法,编码格式应该设置成支持文件内字符串的格式
取乱了: 解决方法,文件是以什么编码格式存入硬盘的,就应该以什么编码格式取出来
4. python解释器默认读文件的编码
python2 默认使用的是ASCII
python3 默认使用的是utf-8
4.1 修改读取文件的默认编码
在Py文件的首行写如下格式
# conding:文件存入硬盘时,所采用的编码格式
例如:
# conding:gbk
注意:这里的#不是注释的意思,是一种固定格式
4.2 文件存入的时候,指定编码格式的用法
例如:
编码:
res = x.encode('gbk')
编码的结果为bytes类型
解码:
res = x.decode('gbk')
如果不写,python3中默认就是用utf-8来进行编码和解码的