pandas之rank函数的使用
pandas排名函数的使用
在Pandas中,可以使用rank()函数来进行排名操作。
rank()函数可以用于为数据帧中的元素分配排名,并提供不同的排名策略,例如从小到大排名、从大到小排名等。
使用上面的一组模拟数据,介绍rank方法的使用。 其中参数method:
- average: 组内的平均排名;
- min: 最小排名方式;
- max: 最大排名方式;
- first: 根据出现顺序分配排名,首次出现的元素排名较高;
- dense: 据出现顺序分配排名,但没有间隔。
默认情况下,rank()函数是按升序排名的,你可以通过设置ascending=False参数来改为降序排名。
一、模拟数据
import pandas as pd
df = pd.DataFrame(data={'score': [100, 99, 99, 96, 95, 90, 90, 90, 90, 86]})
df
score
0 100
1 99
2 99
3 96
4 95
5 90
6 90
7 90
8 90
9 86
二、排名方式
2.1 默认方式("average")
相同值的元素将被分配平均排名。例如,如果有n个元素并列,那么它们的排名将是:并列首行所在的行数+0.5*(n-1)。
df1 = df.copy()
df1['rank'] = df1['score'].rank(method='average', ascending=False)

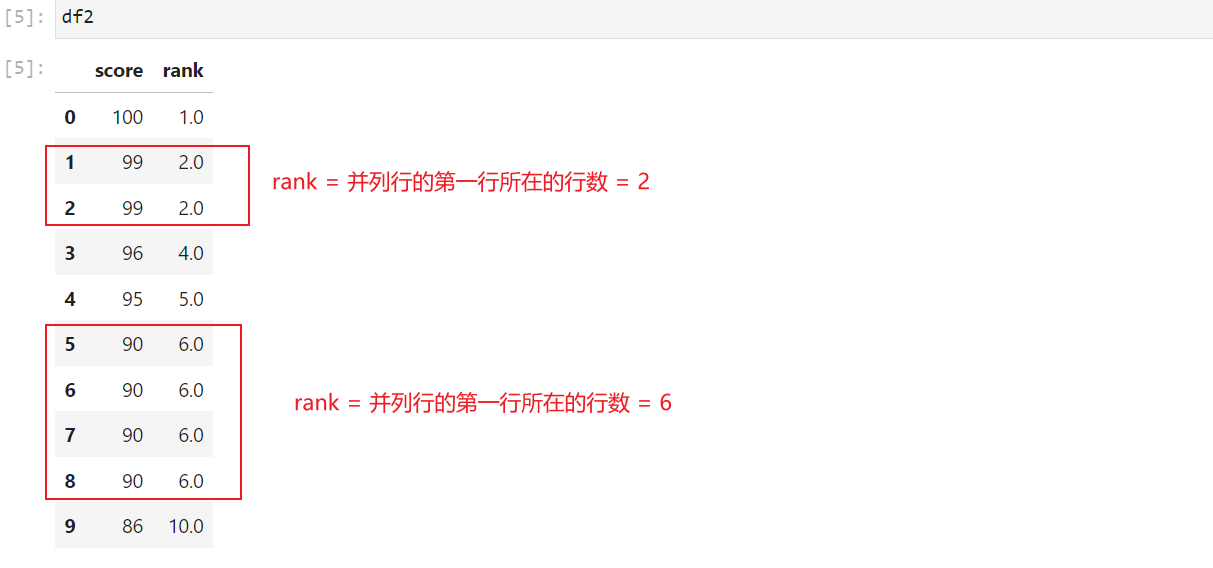
2.2 最小排名方式("min")
类似SQL中 rank。
相同值的元素将被分配最低排名。例如,如果有n个元素并列,那么它们的排名将都是并列的第1行数据所在的行数。
df2 = df.copy()
df2['rank'] = df1['score'].rank(method='min', ascending=False)
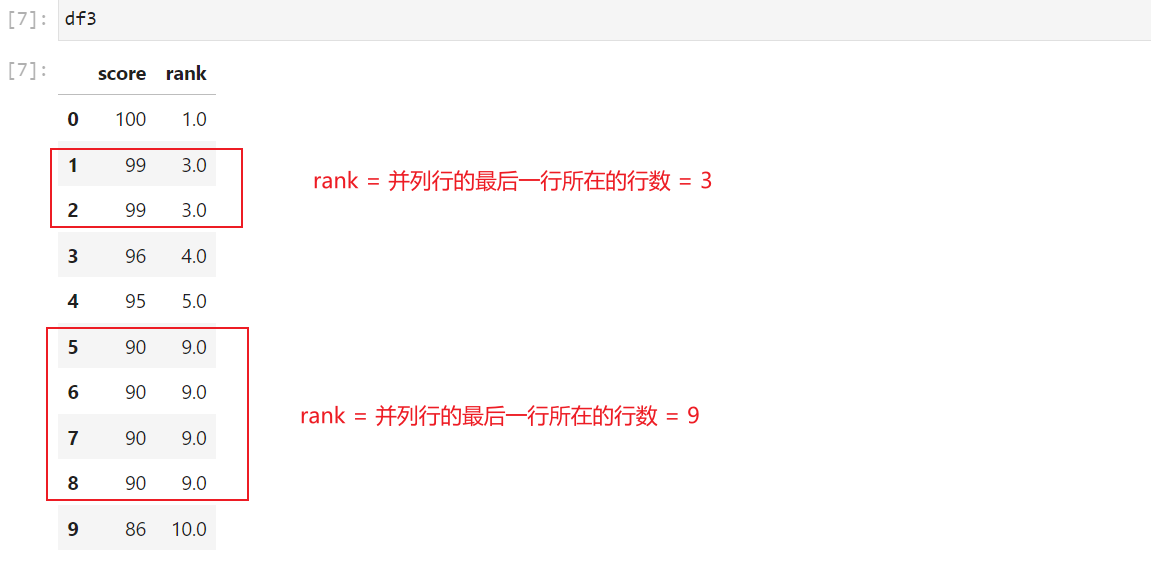
2.3 最大排名方式("max")
相同值的元素将被分配最高排名。例如,如果有n个元素并列,那么它们的排名将都是最后一个元素所在的行数。
df3 = df.copy()
df3['rank'] = df3['score'].rank(method='max', ascending=False)
2.4 连续编号不重复("first")
类似SQL中 row_number。
根据出现顺序分配排名,首次出现的元素排名较高。排名等于行所在的行数。
df4 = df.copy()
df4['rank'] = df4['score'].rank(method='first', ascending=False)

2.5 密集排名方式("dense")
类似SQL中 dense_rank。
根据出现顺序分配排名,但没有间隔。例如,如果有两个元素排名为1,下一个排名将为2,而不是3。
df5 = df.copy()
df5['rank'] = df5['score'].rank(method='dense', ascending=False)
