Redis常见的面试题
Redis的常见的面试问题总结
1.Redis的缓存穿透、缓存击穿以及雪崩?和相对应的解决方案?
- 缓存穿透是指缓存和数据库都没有的数据,而用户不断的发起请求。举个例子:我们的数据库id都是从1自增的,如果发起id=-1的数据或者id特别大不存在的数据,这样不断的进攻导致数据库压力很大,严重击垮数据库。
- 缓存击穿是指一个key非常热点,在不断的抗着大量的请求,大并发集中对这个一个点进行访问。当找个key失效的瞬间,持续的大量并发请求打到了数据库上,就在这个热点key上击穿了缓存。
- 雪崩是因为大面积的key失效,导致大量的请求瞬间落在了数据库上,打崩了数据库。如果没有特别的处理方案,重启数据库但是数据库又被新流量给打死了。
--------->对应的解决方案
对于缓存穿透有两种方案:
- 第一种是在接口层增加校验,比如用户鉴权、参数做校验,不合法的校验直接return,或者在查询的时候返回一个过期时间为300s左右的null值。
- 第二种是采用布隆过滤器,原理是利用高效的数据结构和算法快速判断出找个key是否在数据库中存在,不存在直接return;存在去数据库查完刷新ky再return。但是布隆过滤器也存在一些问题,不用的值在用hash函数计算后可能会得到相同的下标,会出现数据误判的情况。布隆过滤器无法判断一个key一定存在,但是可以判断某个key一定不存在。
对于缓存击穿:设置热点数据永不过期或者加上互斥锁。
对于雪崩:
- 过期时间打散:在存入大量的key进入redis时,把每个key的失效时间都加个随机值,保证它们不会在同一时间大面积失效。
- 热点数据不过期,直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。
- 如果是Redis是集群部署,将热点数据均匀分布在不同的Redis库中也能避免全部失效。
2.Redis是单线程的吗?为什么速度这么快?
- Redis确实单进程单线程的模型,因为Redis完全是基于内存的操作,CPU不是redis的瓶颈,redis的瓶颈可能是机器内存或网络带宽。
- Redis采用多路复用IO模型,非阻塞IO。
- 数据结构简单,同时redis是hash索引,无论是set、get、delete操作的时间复杂度永远都是O(1),并且get和set都是简单操作命令且key也是简单的,去内存中查找一个简单索引,速度是足够快的,不需要多线程。
- 采用单线程,避免了不必要的上下文切换和竞争条件,不存在多线程导致的CPU切换,不用考虑各种锁的问题。
3.Redis的淘汰策略都有哪些?
- 从设置过期时间的kv中集中优先对最近最少使用的数据淘汰。
- 从设置过期时间的kv中集中优先对剩余时间短的数据淘汰。
- 从设置过期时间的kv中随机选择数据淘汰。
- 从所有的kv中集中优先对最近最少使用的数据淘汰。
- 从所有的kv中集随机选择数据淘汰。
- 不淘汰策略,若超过最大内存,返回错误信息。
4.了解Redis的持久化机制吗?有什么区别?
Redis数据缓存在了内存中,但是会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件中,以保证数据的持久化。Redis的持久化策略有两种:
- RDB: 快照形式是直接把内存中的数据保存到一个dump的文件中,定时保存,保存策略。
- AOF: 把所有的对Redis的服务器进行修改的命令都存到一个文件里,命令的集合。
|
RDB(快照) |
AOF(全量日志保存) |
|
某个时间点redis中的数据快照 |
记录所有对redis的操作(写) |
|
体积(小) |
体积(大) |
|
恢复速度快 |
恢复速度慢 |
|
存在数据丢失 |
策略:none是不主动持久化,等待系统线程空闲持久化(会数据丢失) everysec是每秒存一次(丢失) always是理论上不存在丢失,一直执行 |
5. 如何选用持久化策略?
- 如果数据不能丢失,RDB和AOF混用。
- 如果只作为缓存使用,可以承受几分钟的数据丢失的话,可以只使用RDB。
- 如果只使用AOF,优先使用everysec的写回策略。
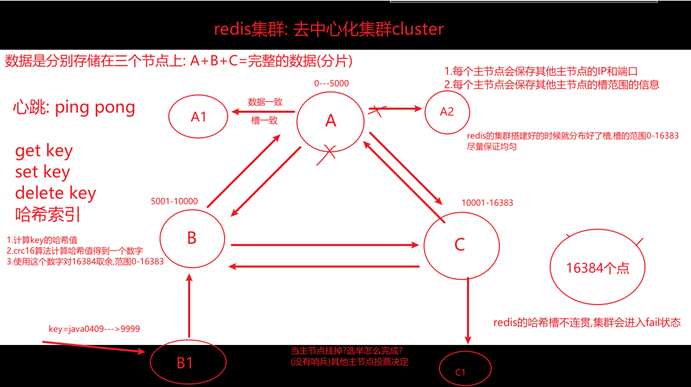
6.说说什么是Redis的哈希槽?
Redis集群中内置了16384个哈希槽,当在redis集群中存kv时,redis会对key使用crc16算法算出一个结果,然后把结果对16384取余,这样每个key都会对应在一个编号在0-16384之间的哈希槽,redis会根据节点数据大致均等的将哈希槽映射到不同的节点。
例如三个节点:槽分布
- SERVER1: 0 - 5460
- SERVER2: 05461- 10922
- SERVER3: 10923 - 16383
7.主从复制,以及哨兵 和集群之间区别?
主从复制 是redis实现高可用的一个策略。将会有主节点 和从节点,从节点的数据完整的从主节点中复制一份。
- 哨兵:当系统节点异常宕机的时候,开发者可以手动进行故障转移恢复,但是手动比较麻烦,所以通过哨兵机制自动进行监控和恢复。为了解决哨兵也会单点故障的问题,可以建立哨兵集群。
- 集群:即使使用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应。为了最大化利用内存,可以采用集群,就是分布式存储。这个时候可以使用redis集群。将不同的数据分配到不同的节点中,这样就可以横向扩展,扩容。
如下图: