第三次”数据库原理及应用”课程大作业
作业三
一、分析说明题
信息系统的数据安全和个人隐私保护是社会与用户非常关心的热点问题,请举例说明作为数据库开发人员该如何遵从工程伦理、职业道德、国家法规开发实现数据库应用系统?
答:
系统管理员和DBA通常对大公司、金融机构、教育机构和经纪公司的计算机系统具有较高的访问权限。IT 专业人员可以在高度机密的信息成为公众知识之前访问这些信息,例如 IPO、股票评级、债务评级、测试问题和答案等等。
在工程伦理方面,数据库开发人员应遵循《工程伦理准则》,如以人为本原则、关爱生命原则和安全可靠原则等。正确识别各类责任主体的利益关注点,理解他们的价值追求及行为动机,是大数据时代下数据库开发人员必须具备的伦理责任意识。
在职业道德方面,数据库开发人员应遵从《大数据科技创新人员行为规范》,如尊重他人隐私、保护他们的个人信息和数据、不在现实和网终空间中做危害人类的事情;不用错误或恶意的方式侵害他人身体、财产、数据、名誉和聘用关系;不在网上和其他场所传播关于他人的恶意谣言、诽谤、污言秽语和物理伤害。
失德数据库开发人员的一个典型例子发生于 2015 年 9 月,美国最大的处方药管理公司之一的计算机管理员承认,他在公司的计算机系统中植入了一枚电子“炸弹”。如果这个“逻辑炸弹”被执行,它将删除重要的患者信息,从而给医疗保健公司带来重大问题和经济损失。
除此之外,数据库开发人员还可以通过不断完善信息系统安全性能,部署防火墙,入侵检测系统,防病毒系统,认证系统,采取访问过滤、动态密码保护、登录限制,网终攻击追踪方法的技术手段,强化应用数据的脱敏处理、存取管理、业务审计,确保系统中的用户个人信息得到更加稳妥的安全技术防护。
在国家法规方面,2017年以来,国家质检总局和标准化委员会、国家市监总局和国家标准化委员会和全国信息安全标准化技术委员会陆续发布了一系列与个人信息和数据保护相关的国家标准和指南。
其中,国家质检总局和标准化委员会发布的文件共有10部,目前均处于生效状态,内容涵盖了云计算服务、移动智能终端个人信息保护、大数据服务、移动终端、移动互联网应用服务器、电子政务移动办公系统、网站身份和系统、网站可信标识等领域中的信息安全技术要求。
数据开发人员要遵守这些法律法规,共同承担建设社会安全、可信、平等、可及、惠民的社会责任,避免发明伤害他人、涉嫌歧视、损害名誉、降低道德水平的产品和服务,在企业私利和社会公德之间履行好大数据科技创新人员的社会责任。
二、数据库设计与编程实现动手实践题
- 针对房屋租赁管理系统数据需求,使用Power Designer建模工具,设计房屋赁管理系统概念数据模型。
(1)首先打开Power Designer,创建概念数据模型,如图1所示。
图 1 创建CDM
(2)分析房屋租赁管理系统数据需求,从业务中抽取实体。
①对“房主”实体,其基本属性包括身份证号、房主姓名、电话和住址。其中选取“身份证号”作为标识符(Primary Identifier),“身份证号”“房主姓名”“电话”设置为强制不可为空(Mandatory),如图2所示。
注意,Code是实际转换为数据库时的字段名,Name只是做注释用的(在转化sql时,只有Code会被应用,Name只在视图显示)。
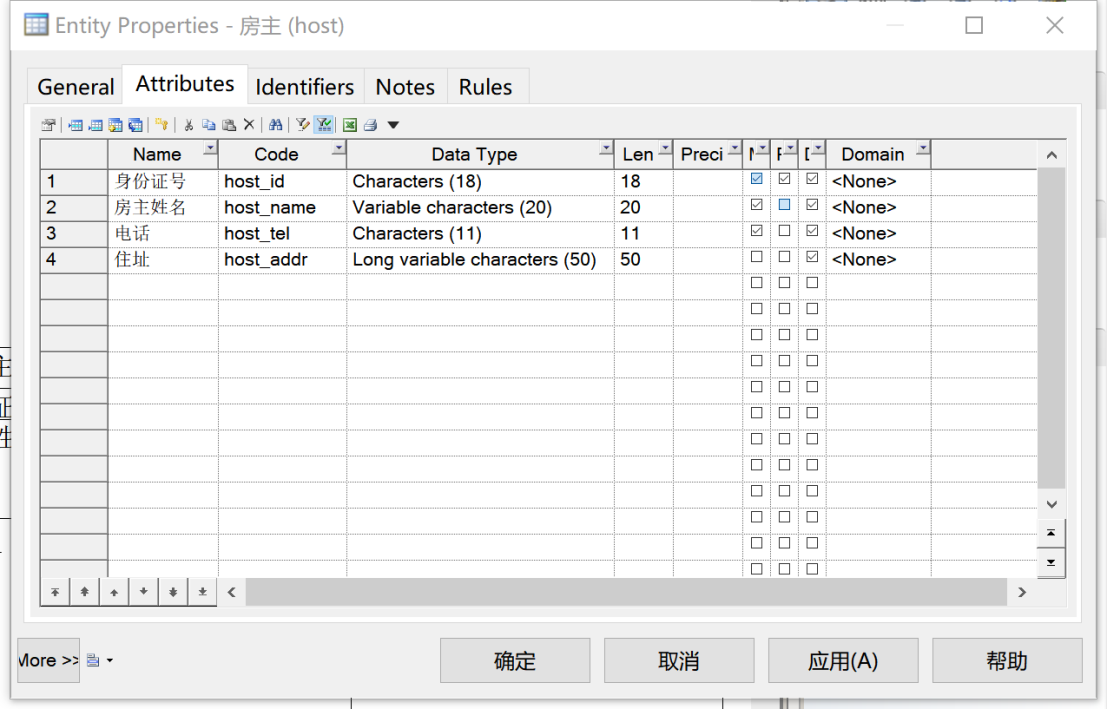
图 2 “房主”实体
②对“租户”实体,其基本属性包括身份证号、租户姓名、电话和性别。其中选取“身份证号”作为标识符(Primary Identifier),“身份证号”“租户姓名”“电话”设置为强制不可为空(Mandatory),如图3所示。
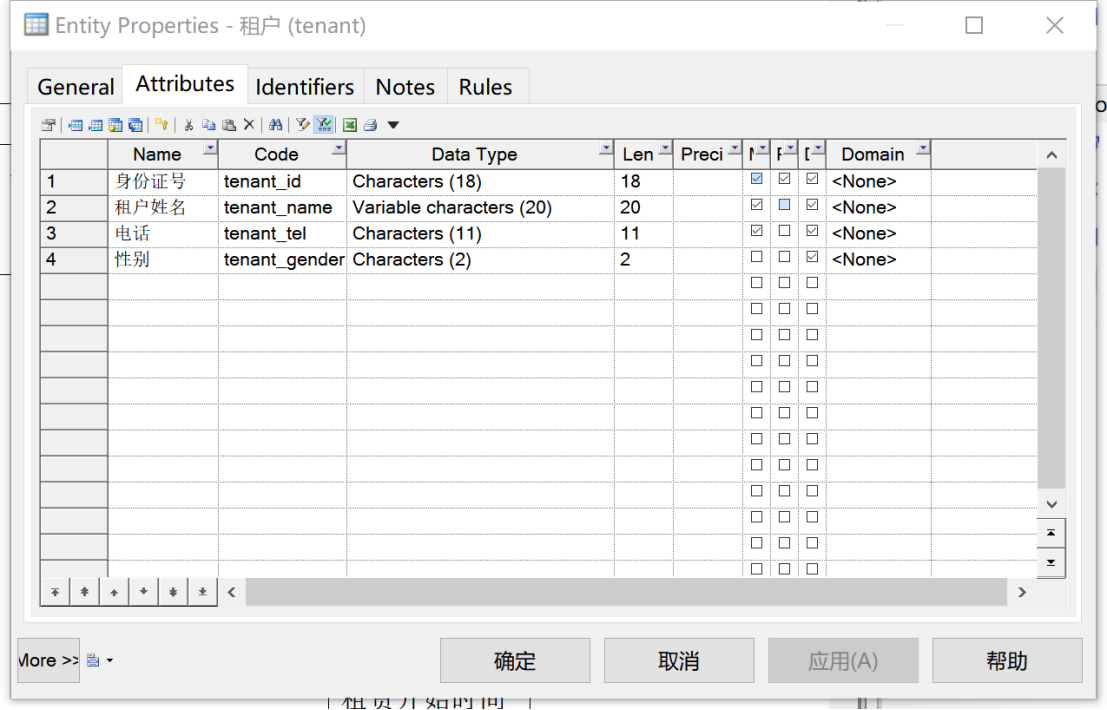
图 3 “租户”实体
③对“房屋”实体,其基本属性包括“房屋地址”“房屋面积”“每月租金”“房屋类型”“出租状态”,均设置为Mandatory。此外,引入新的属性“房屋编号”作为标识符,如图4所示。
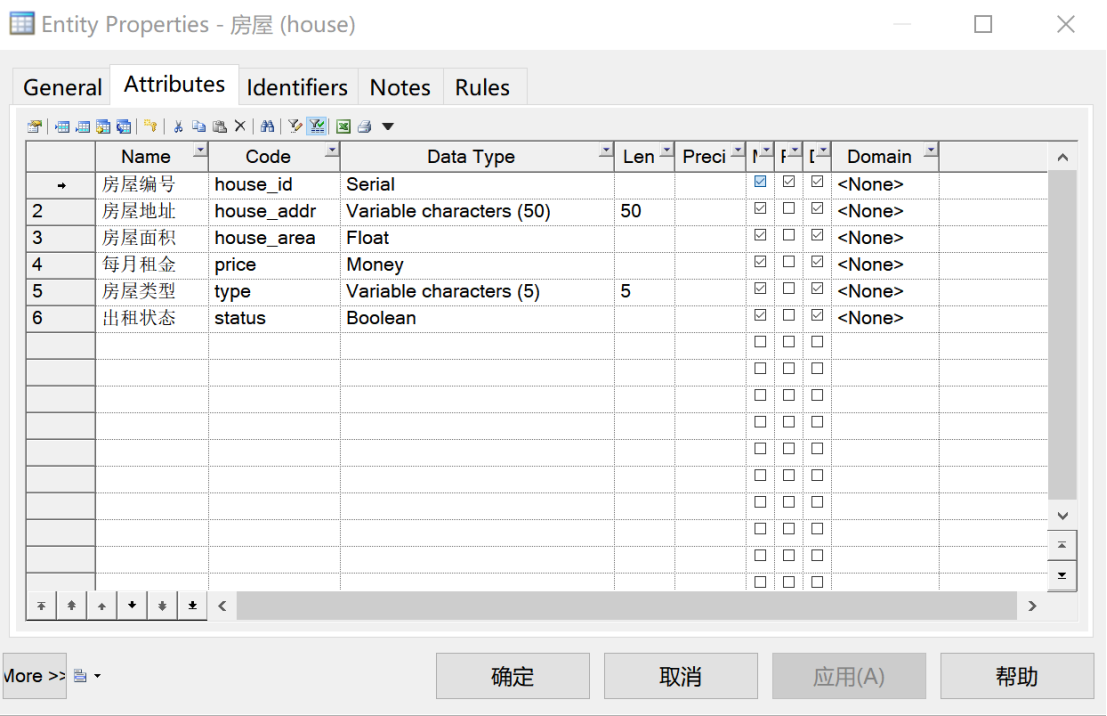
图 4 “房屋”实体
④对“租赁合同”实体,其基本属性包括“签订时间”“租赁开始时间”“租赁期限”,均设置为Mandatory。此外,引入新的属性“合同编号”作为标识符,如图5所示。
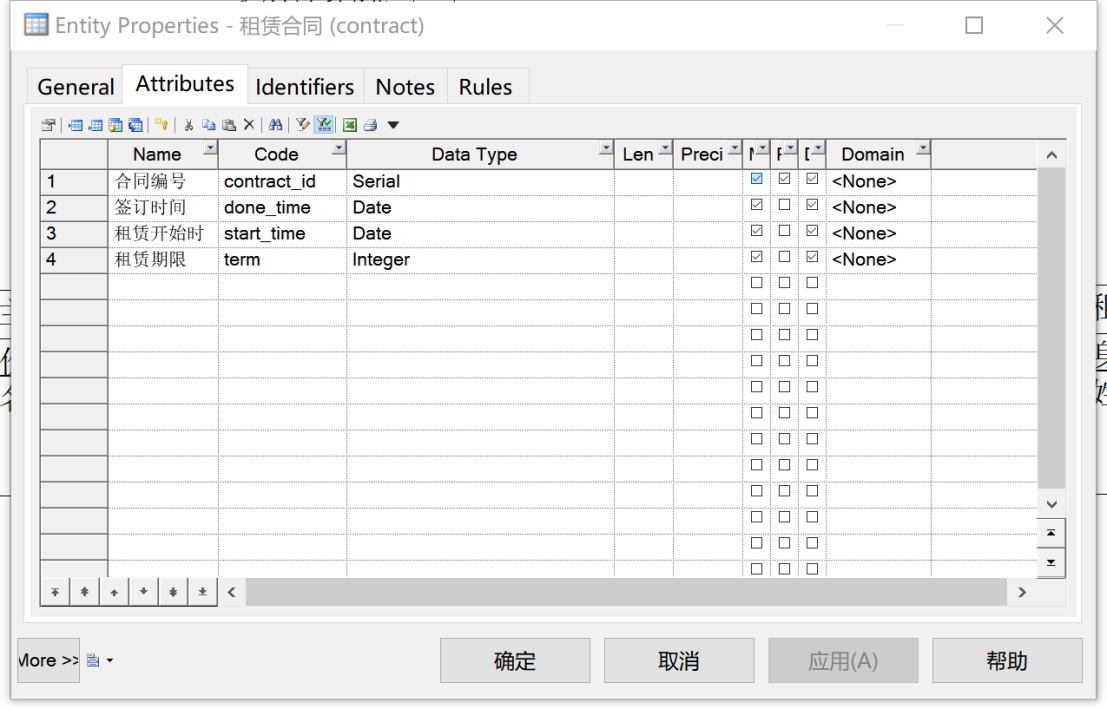
图 5 “租赁合同”实体
实体创建完成,如图6所示。
图 6 实体创建结果
(3)接下来确定实体间的联系。
“房主”和“房屋”之间是“一对多”关系:一位房主最多拥有N套房,也可以拥有零套房;一套房一定被且只能被一位房主拥有。如图7所示,定义此“拥有”关系。
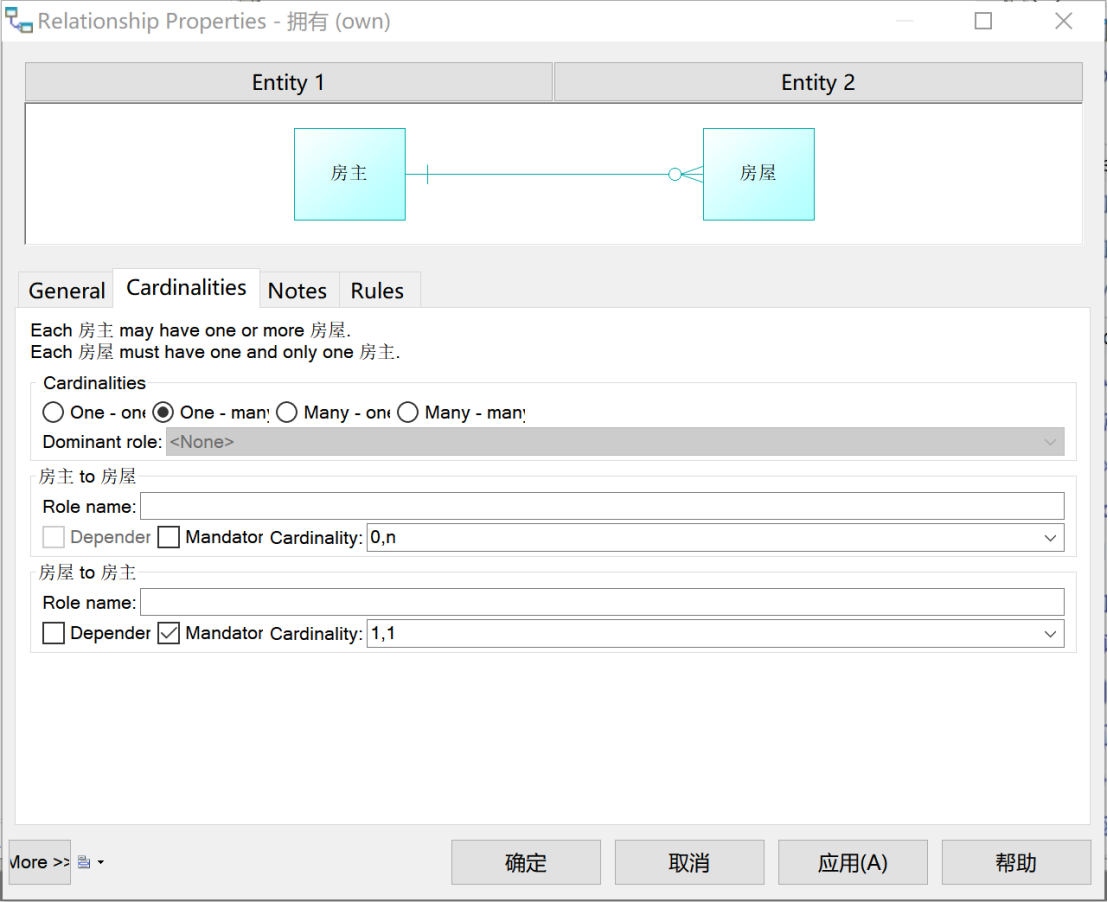
图 7 “拥有”联系
“房主”和“租赁合同”之间是“一对多”关系:一位房主最多签约N份合同,也可以不签约合同;一份租赁合同一定被且只能被一位房主签约。如图8所示,定义此“签约”关系。
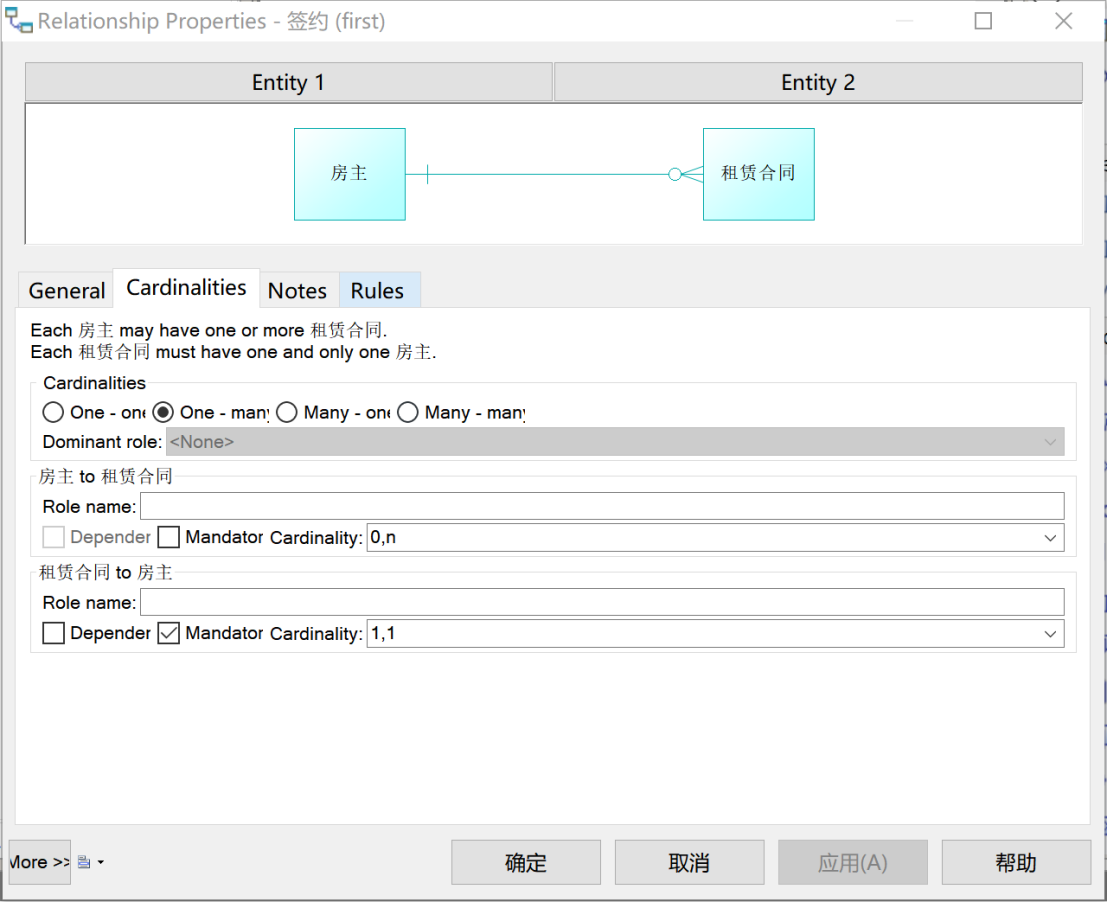
图 8 甲方“签约”关系
“租户”和“租赁合同”之间是“一对多”关系,如图9所示;“房屋”和“租赁合同”之间是“一对一”关系,如图10所示。
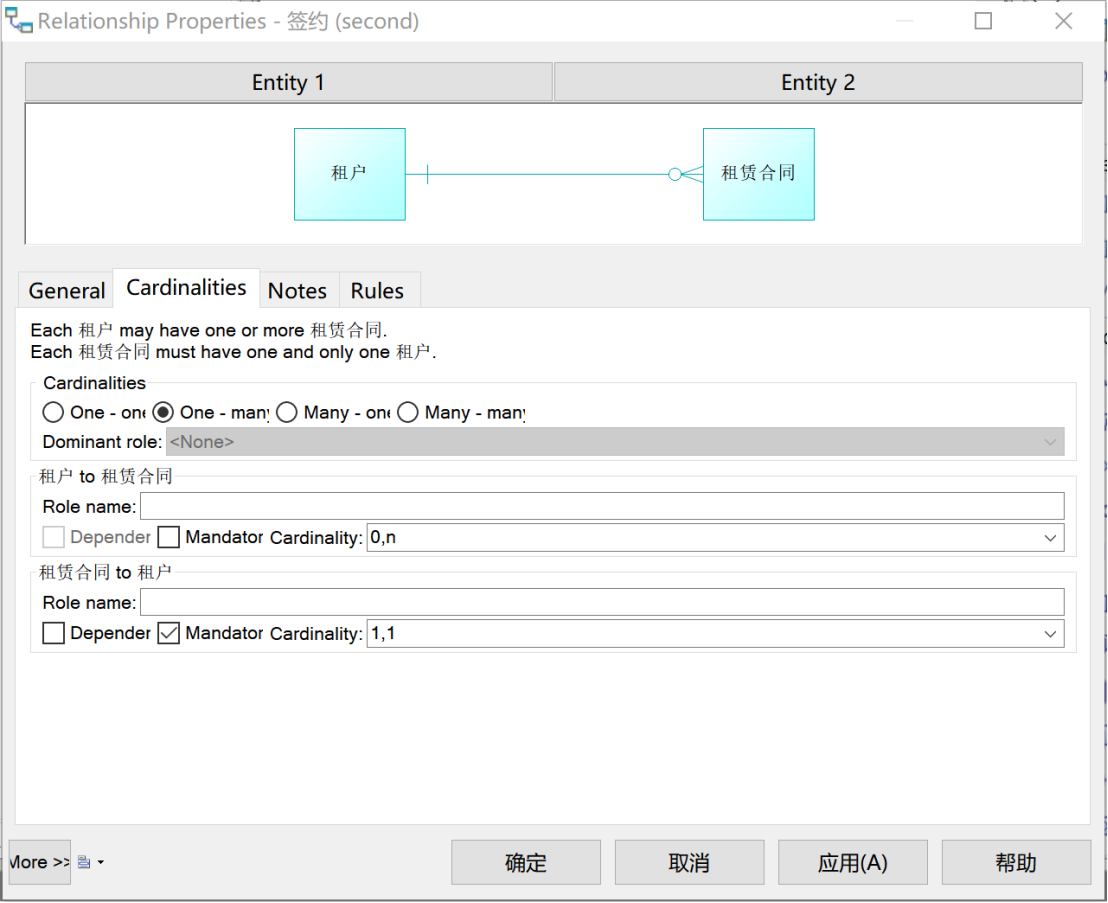
图 9 乙方“签约”关系
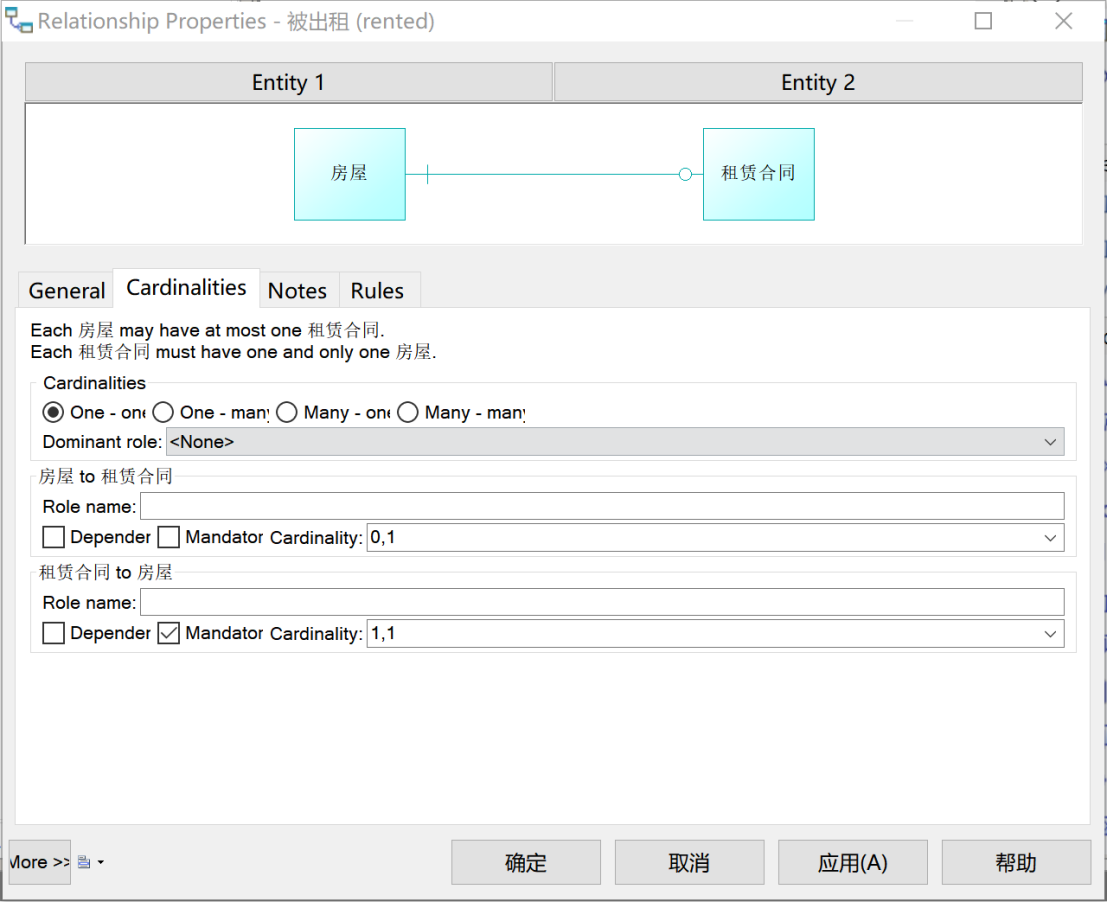
图 10 “被出租”关系
房屋租赁管理系统的概念数据模型设计完成,如图11所示。
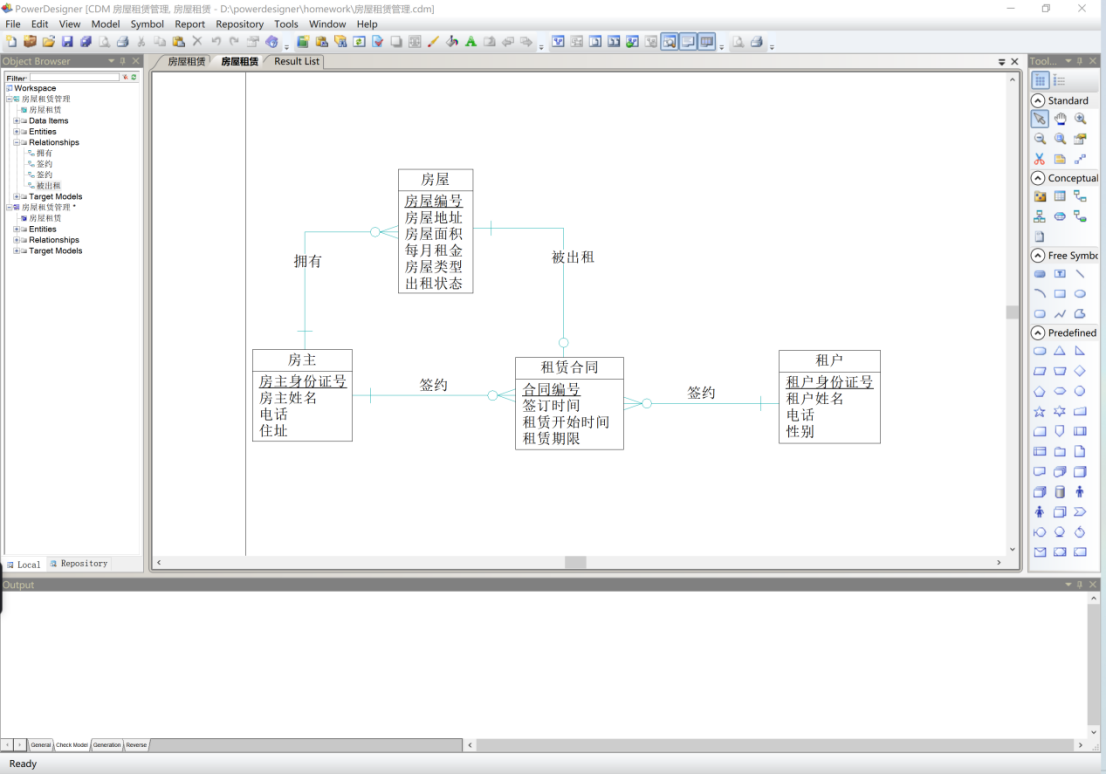
图 11 CDM
(4)对模型进行检查,确保模型定义的正确性。点击Tools->Check Model,打开检查选项设置,如图12。
图 12 检查选项设置
检查输出结果如图13,没有任何错误和警告,可以进行下一步操作。

图 13 检查输出结果
- 在概念数据模型基础上,采用关系数据库设计方式,将房屋租赁管理系统概念数据模型转换为系统逻辑数据模型设计,并进行规范化完善设计,至少满足3NF规范。
- 在Tools->Generate Logical Data Model中,选择生成一个新的LDM,如图12。
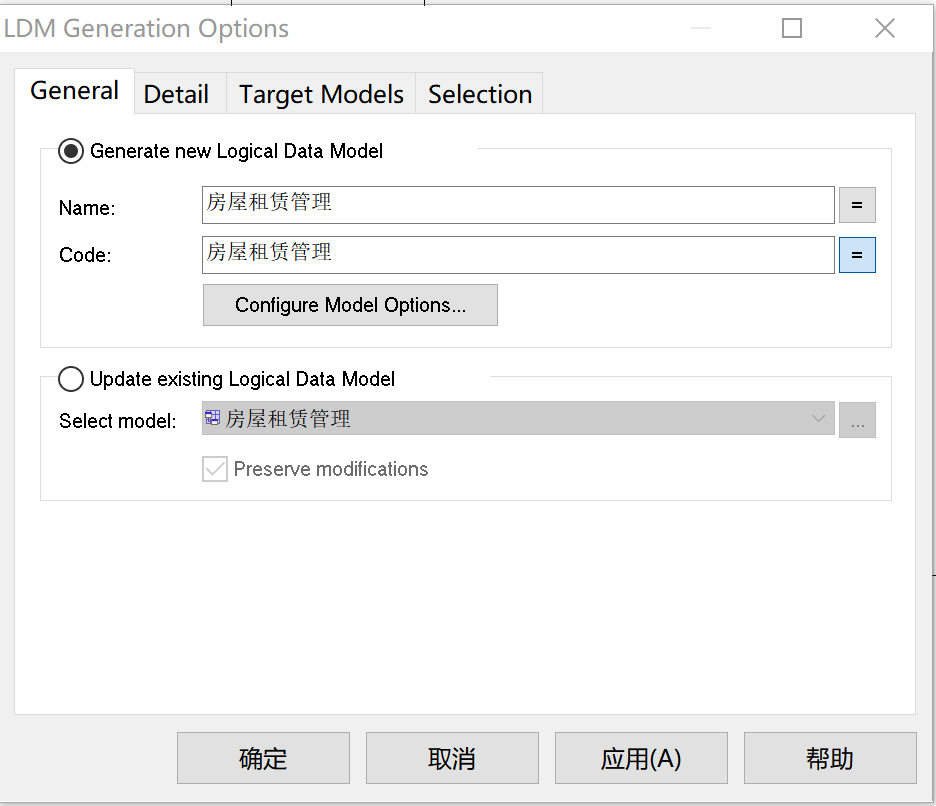
图 14 LDM Generation Options
生成结果如图13所示。
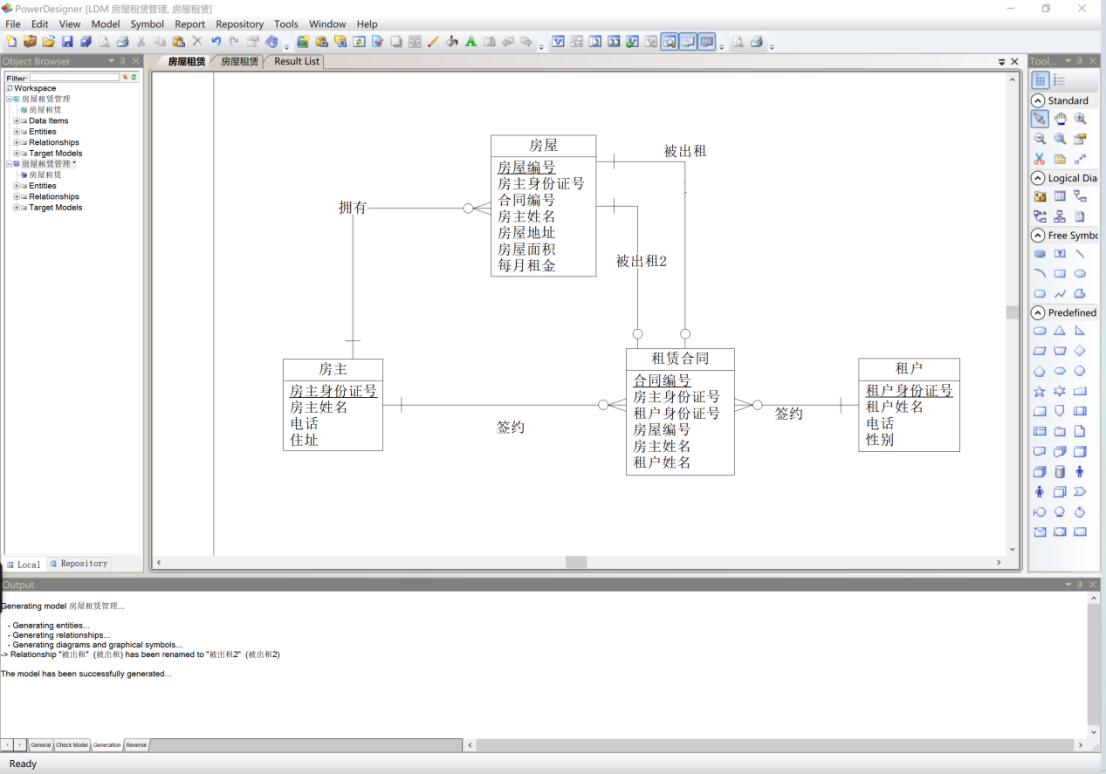
图 15 生成LDM
- 接下来对生成的逻辑数据模型进行优化。
在Tools->Display Preferencces中,对实体显示内容进行设置,如图16。
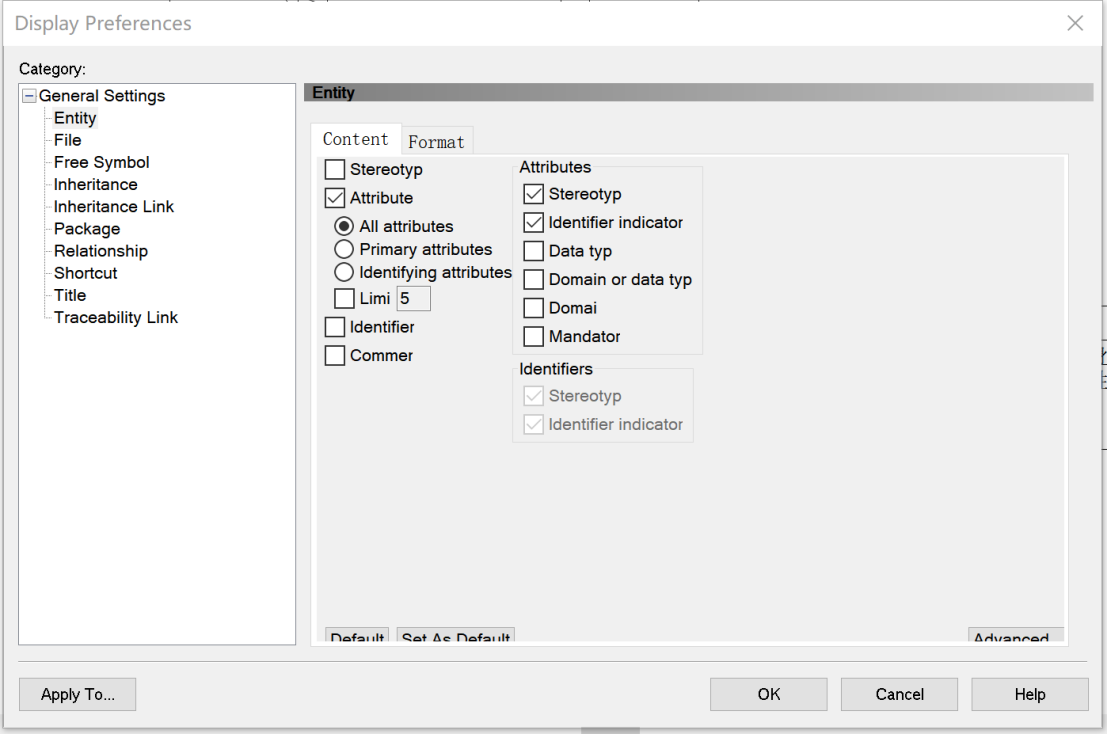
图 16 实体显示内容设置
- 对于“房屋”和“租赁合同”间的关系,在一个实体中添加另一个实体的标识符做外键标识符即可。这里删除冗余的“被出租2”关系。修改完成后如图17所示。
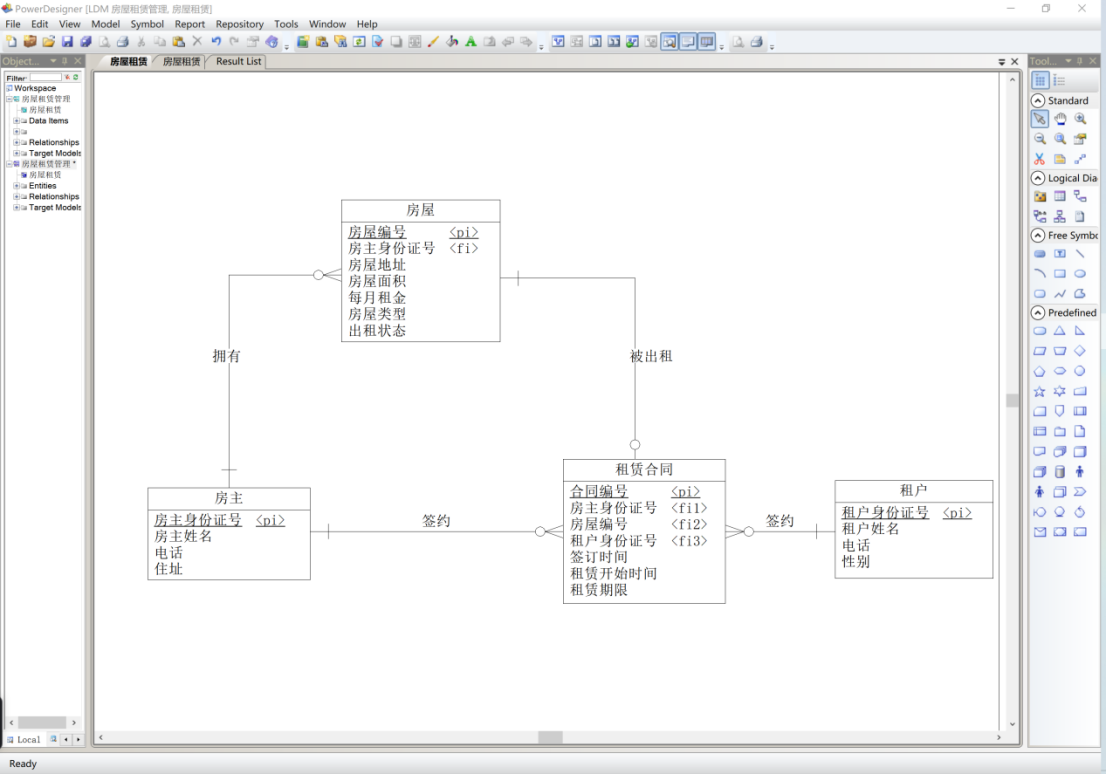
图 17 修改完成
- 第一范式是指属性列不能重复,并且每个属性列都是不可分割的基本数据项。显然,目前的LDM满足第一范式。
- 第二范式要求所有数据都要和对应的主键标识符有完全函数依赖。显然,各实体的属性列都完全依赖于对应主键标识符,满足第二范式。
- 第三范式要求满足第二范式,且所有非主键标识符属性均不存在传递函数依赖。分析可知,各实体的非主键标识符之间均不存在函数依赖,所以对主键标识符也不存在传递函数依赖,满足第三范式。
- 最终的LDM如图18所示。
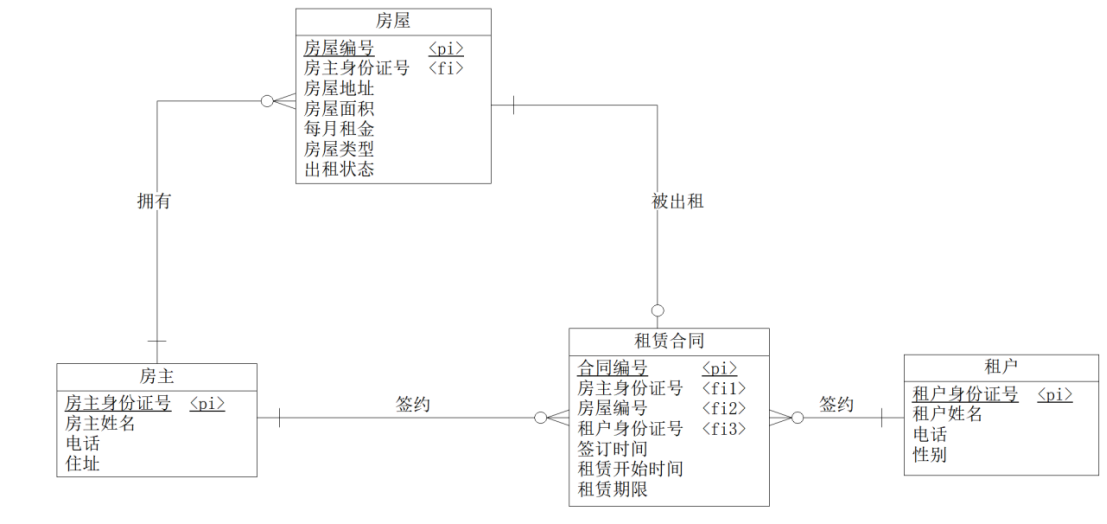
图 18 LDM
- 针对PostgreSQL数据库实现,将房屋租赁管理系统逻辑数据模型转换为系统物理数据模型设计,并进行有关索引设计、视图设计。
- 在Tools->Generate Physical Data Model中,选择生成一个新的PDM,如图19。
图 19 PDM Generation Options
- 进行模型显示设置,设置完成后图20。
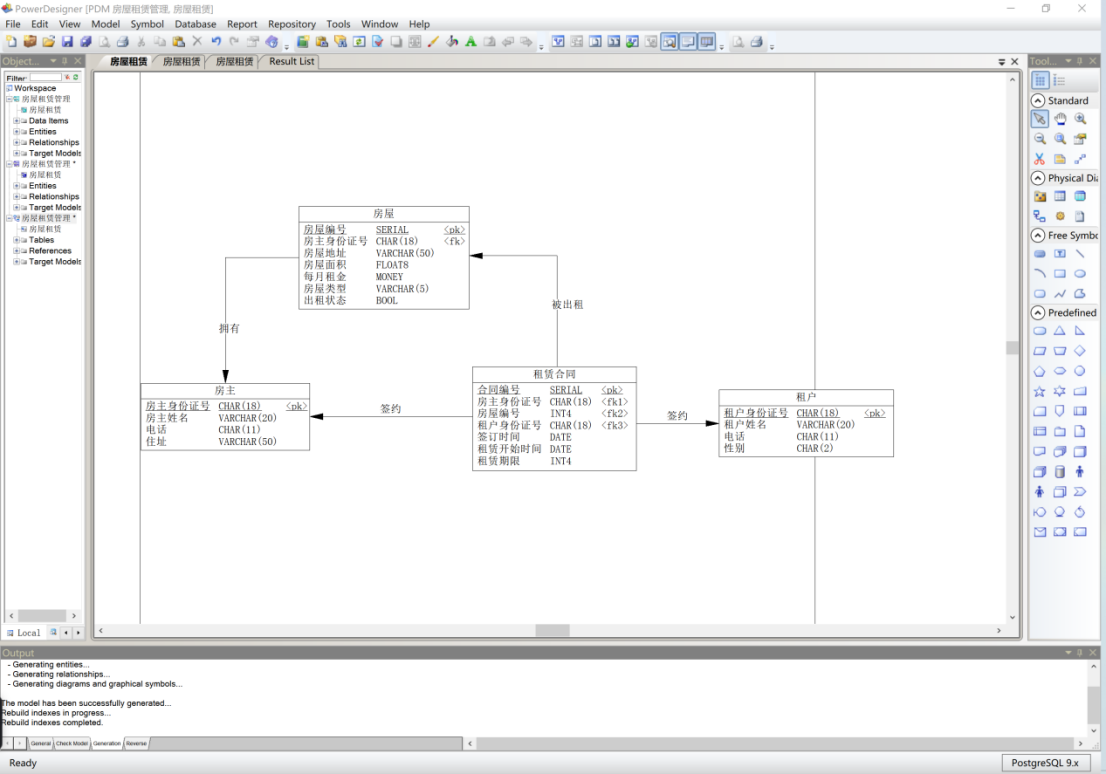
图 20 生成PDM
- 根据业务需求,为生成的物理数据模型添加索引。
在“房屋”关系表的“房屋编号”列设计索引,以便对“房屋编号”查询时,数据库有较高的查询速度。打开“Table->Indexes”设置,如图21所示。
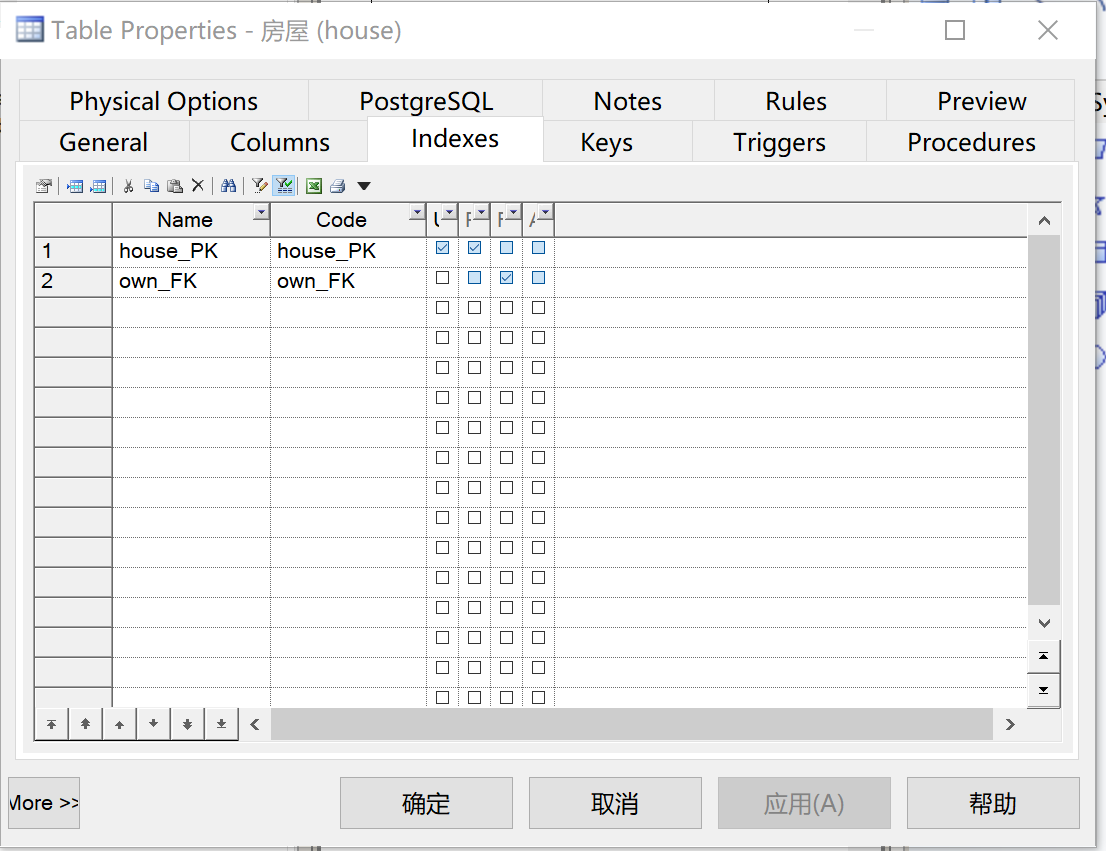
图 21 索引设置
我们发现,在生成PDM时Power Designer已自动为“房屋编号”和“房主身份证号”生成索引,这样,我们在查询时就具有较高的效率。
除此之外,在实际业务中,针对“房屋面积”查询的情况较多,应为其生成索引。如图22,新建一个索引。
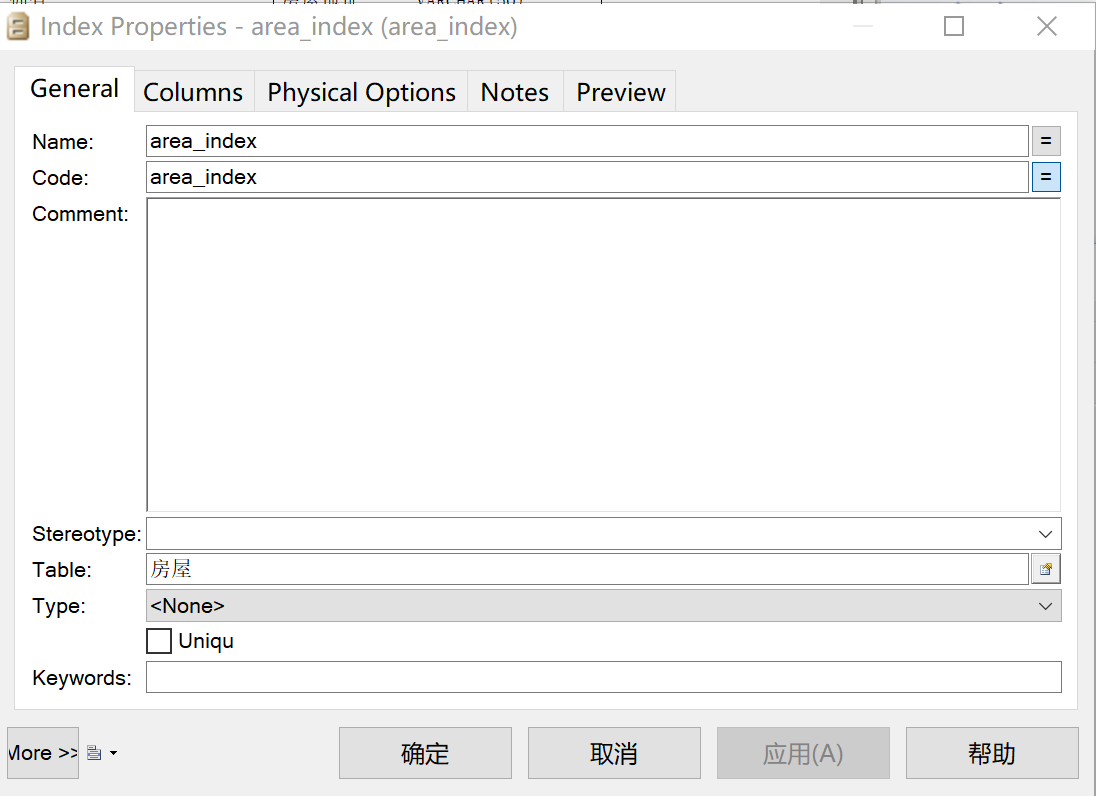
图 22 新建索引
在“Columns”选项中,勾选要作为索引的“房屋面积”列,如图23。

图 23 添加列
操作完成后,索引成功生成,如图24.
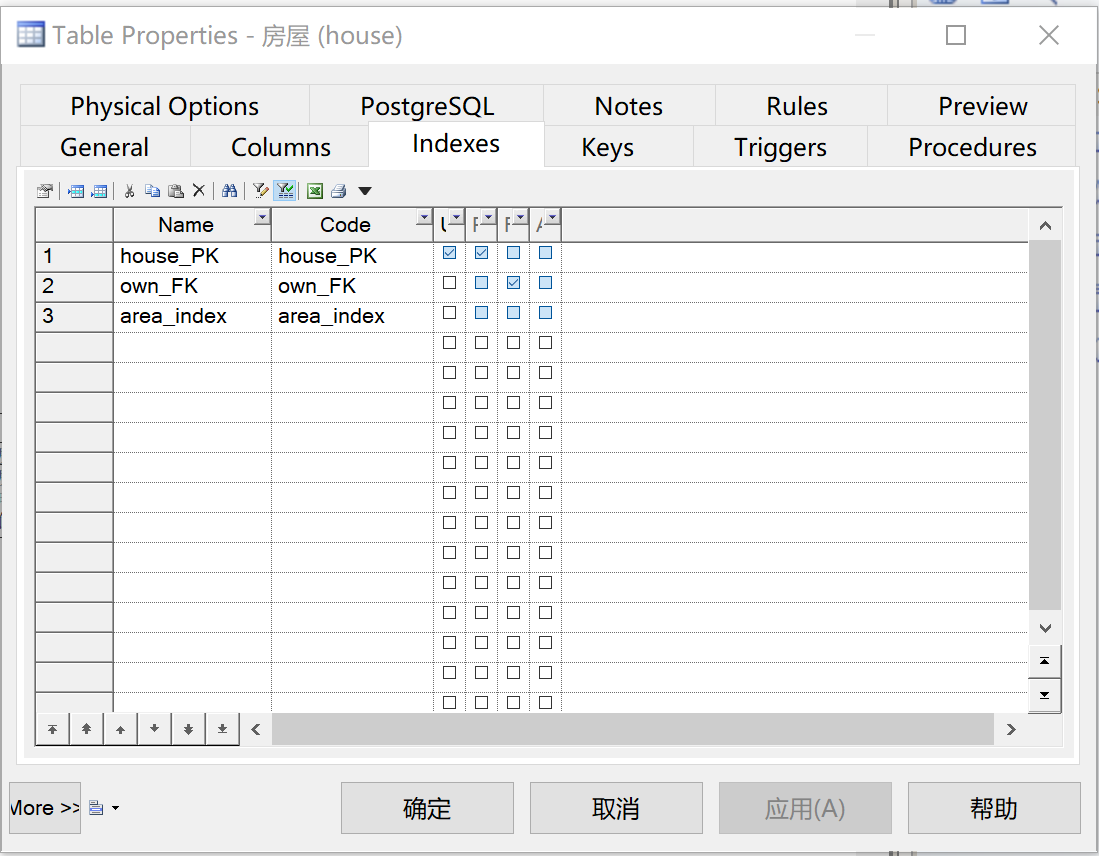
图 24 生成索引结果
- 根据业务需求,进行视图设计。
除管理用户外,其他用户在根据“合同编号”查询相应的租赁合同时,只能浏览到“合同编号”“签订时间”“租赁开始时间”“租赁期限”,敏感信息如“房主身份证号”“租户身份证号”应被隐藏。
因此创建ContractView。选择“Tools->Create View”,新建一个视图,且使用限制为“只查询(query only)”,如图25所示。
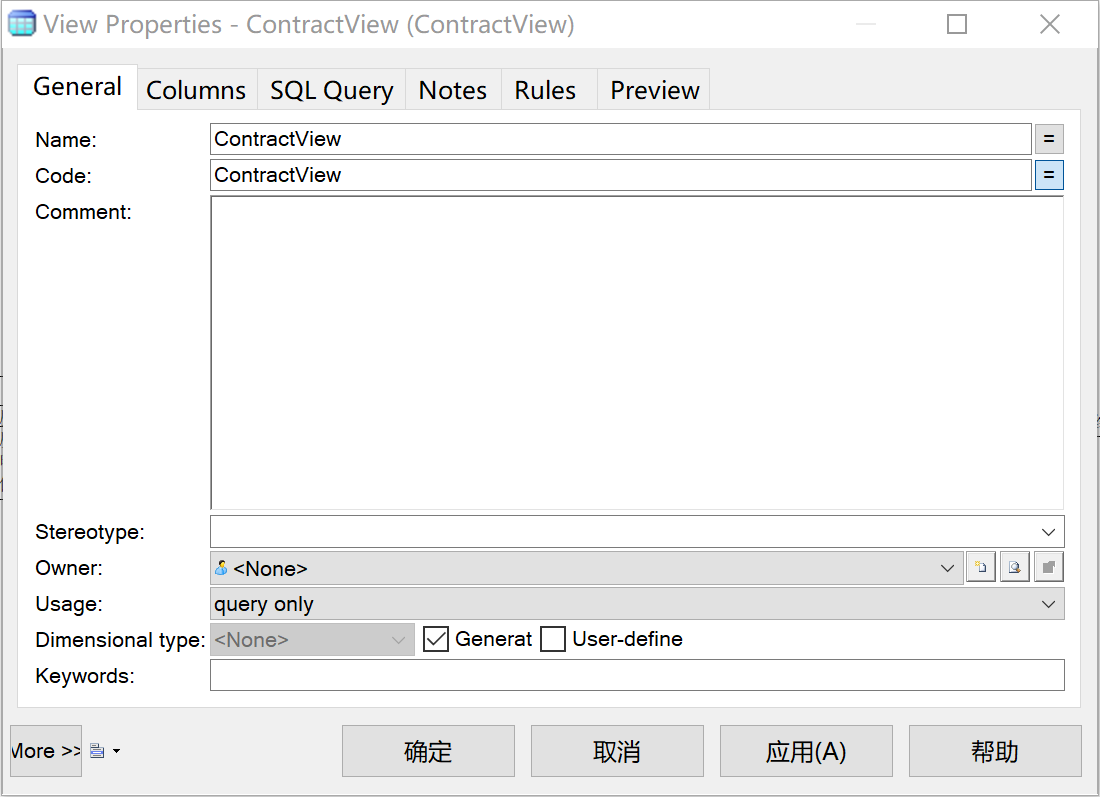
图 25 新建视图
使用SQL语句选择非敏感信息,如图26所示。
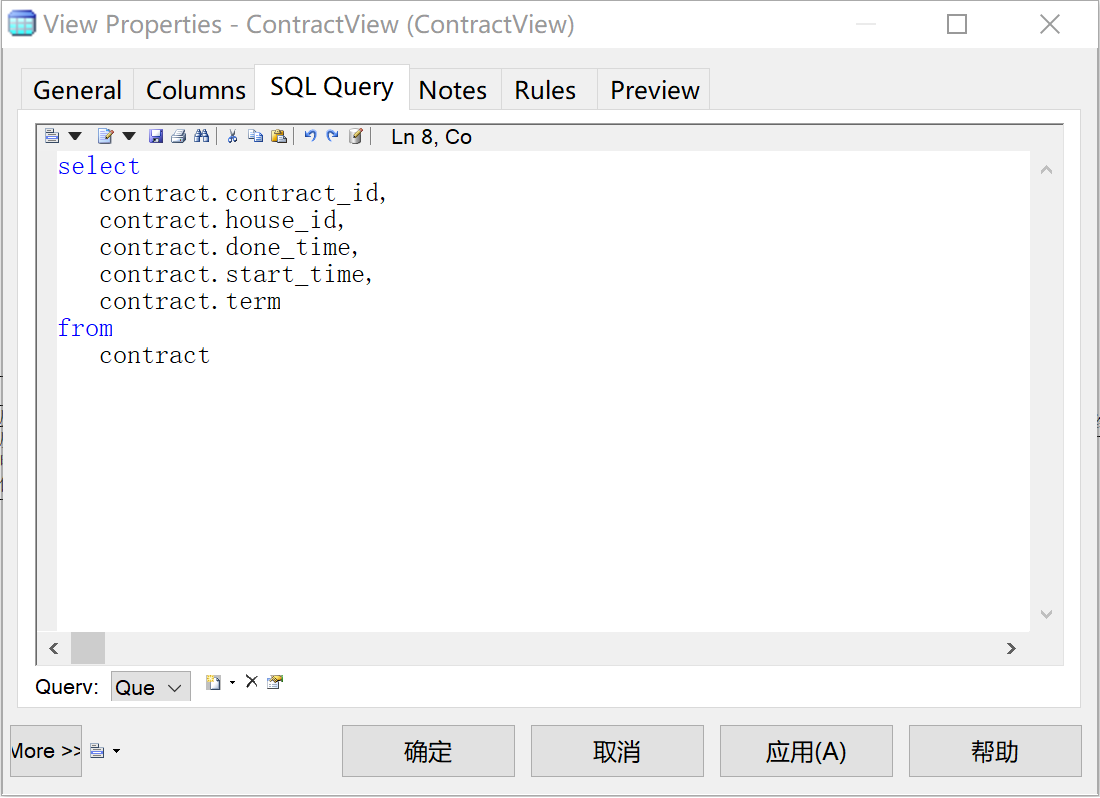
图 26 SQL语句选择列
创建结果如图27所示。
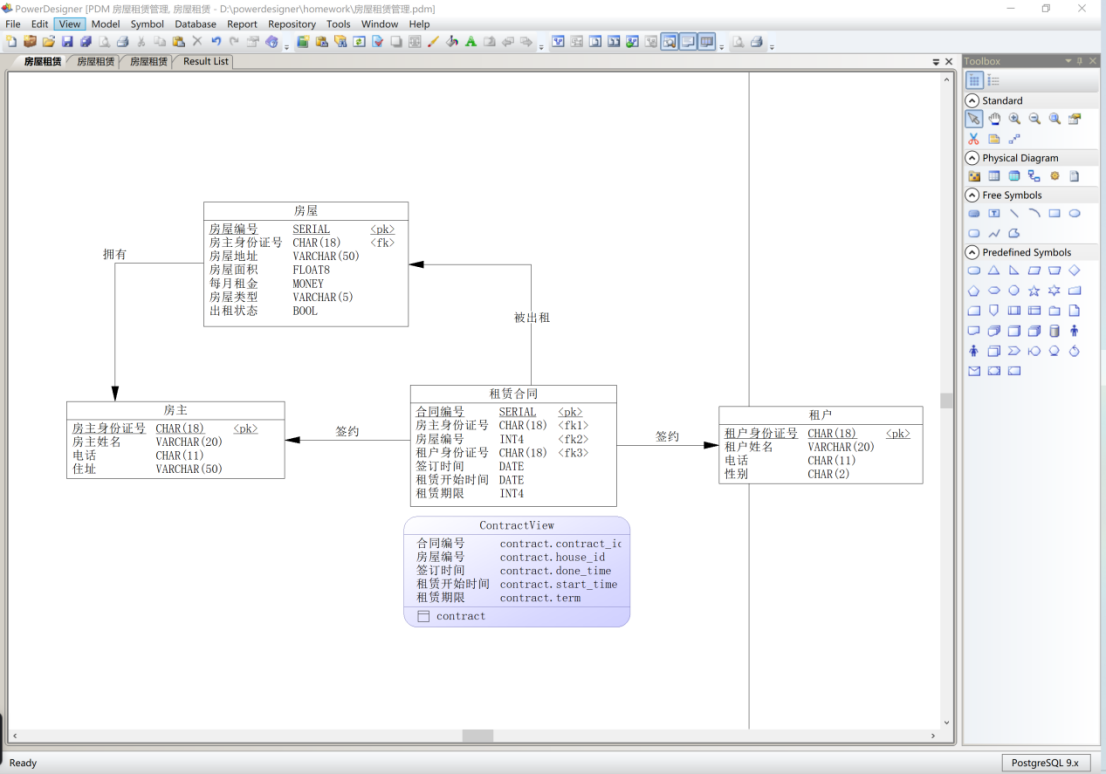
图 27 视图创建结果
- 对PDM进行设计验证检查。点击“Tools->Check Model”进行检查。检查结果没有任何错误和警告,如图28所示。

图 28 检查结果
- 最终的PDM如图29所示。
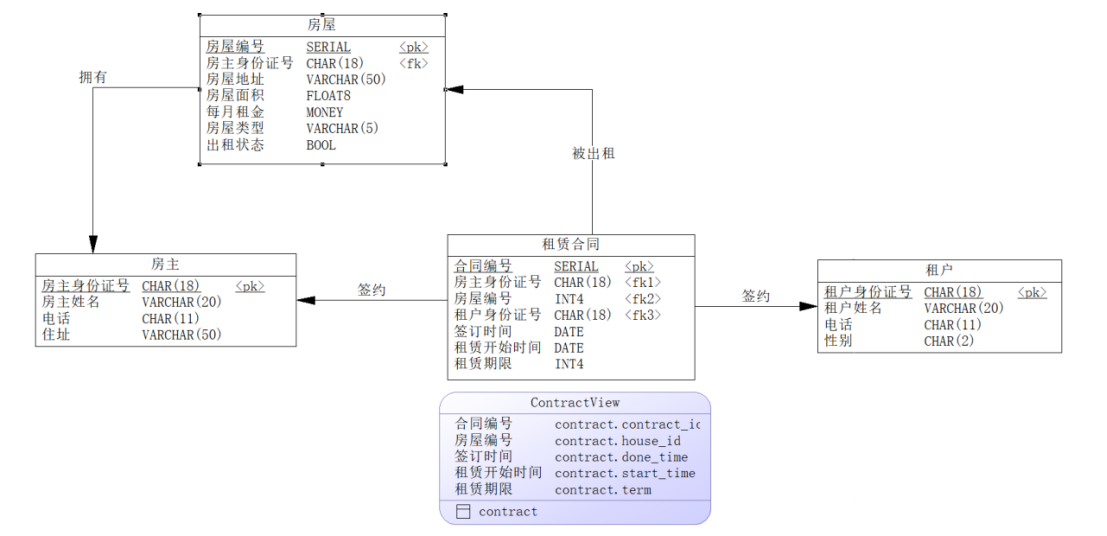
图 29 PDM
- 将房屋租赁管理系统物理数据模型转换为SQL脚本程序。
选择“Database->Generate Database”,生成SQL脚本程序,如图30。
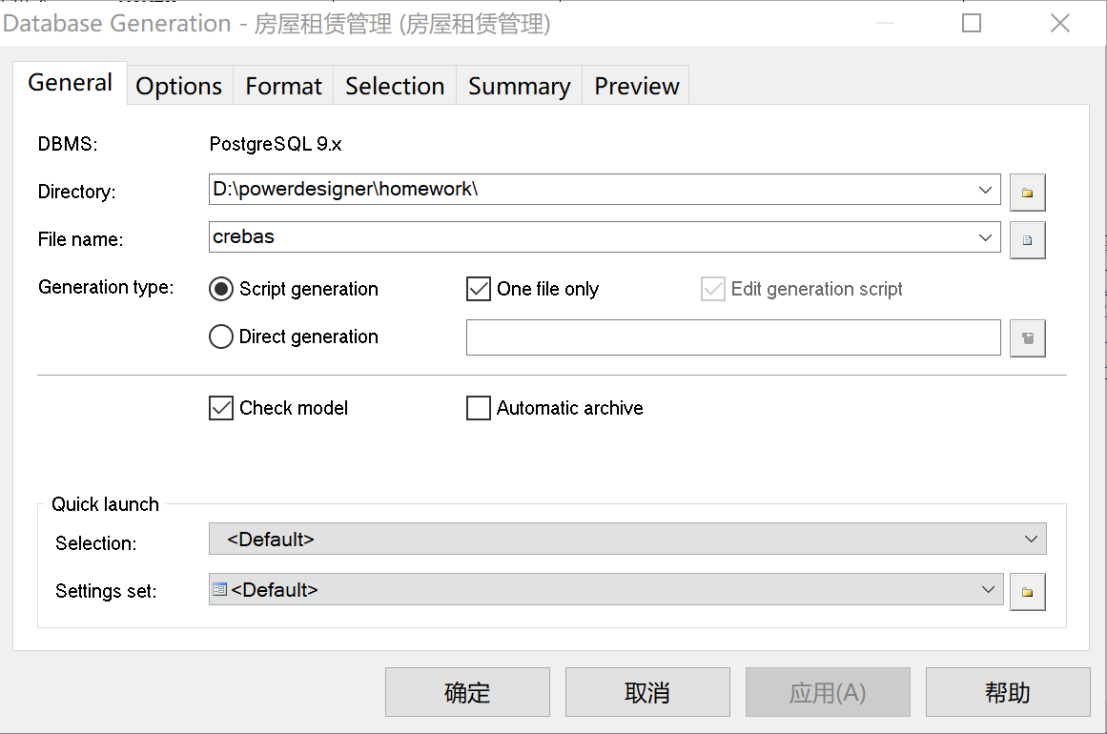
图 30 生成SQL脚本
打开脚本查看,如图31。
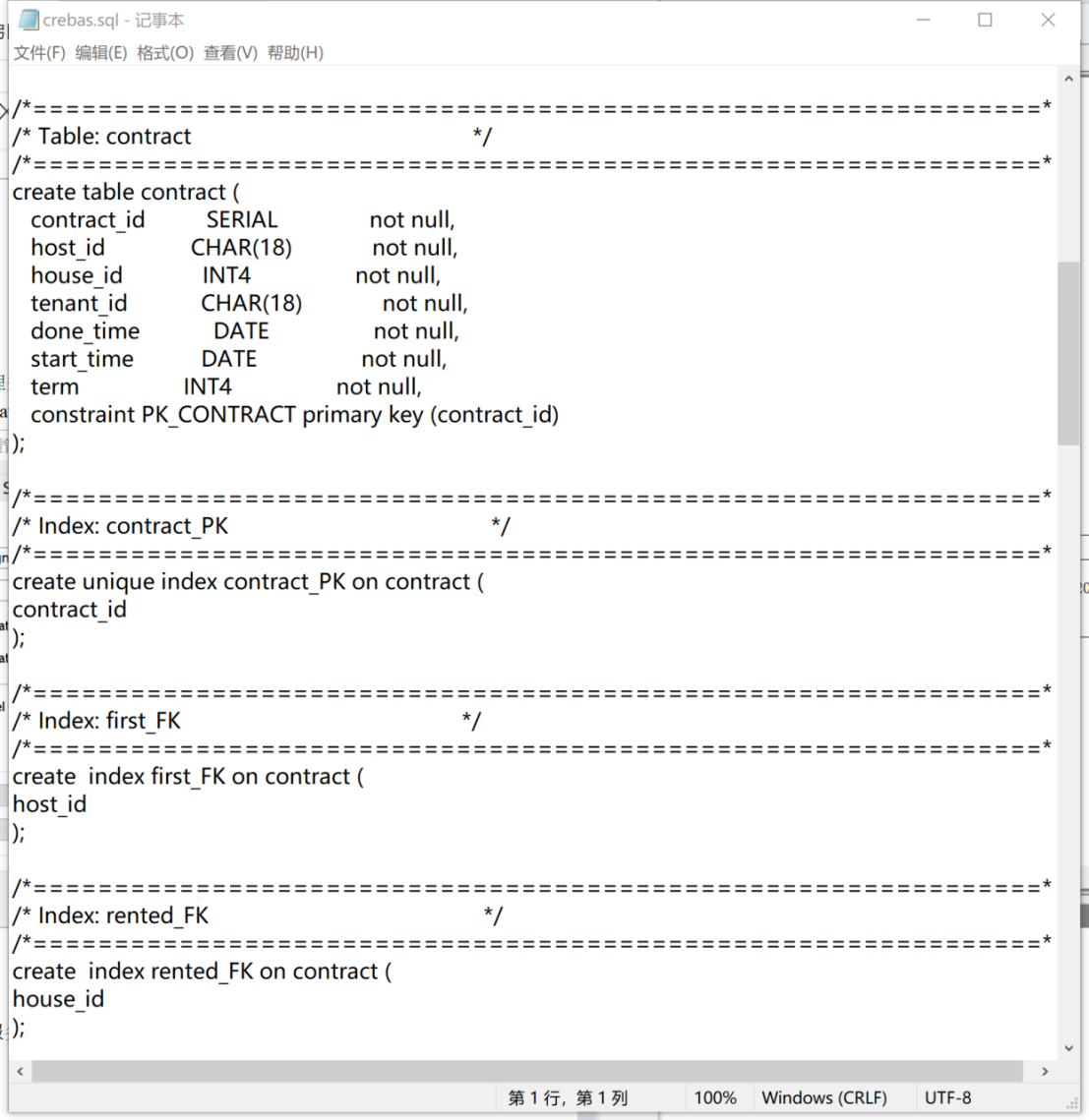
图 31 查看脚本
- 在PostgreSQL数据库服务器中,执行该SQL脚本程序,实现房屋租赁管理系统数据库对象创建实现。
首先新建一个数据库,如图32。
图 32 创建数据库
导入脚本并执行,如图33。
图 33 导入脚本
执行成功后,刷新,可以看到左侧出现相应的表和视图,如图34。
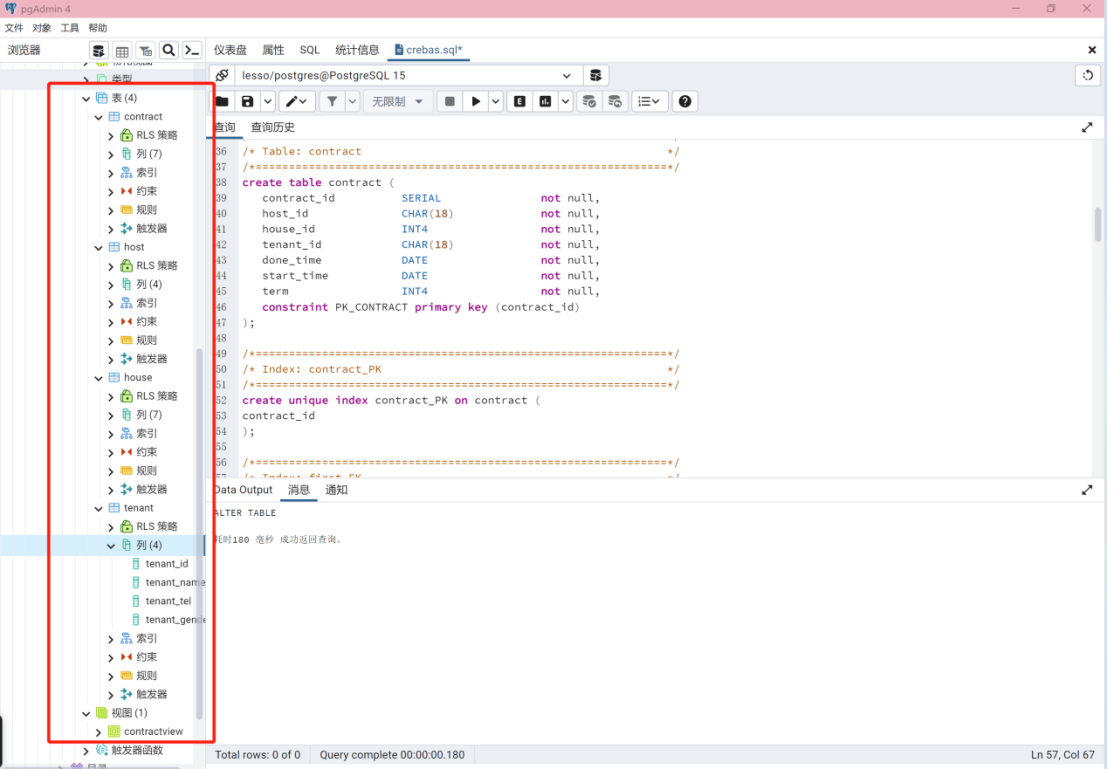
图 34 执行结果
三、挑战性问题研究
针对电商系统的高并发访问、高性能存取、可扩展应用需求,在商品销售数据库设计与实现中,该如何来应对?请给出具体解决方案。
答:
高并发是一种系统运行过程中遇到的一种“短时间内遇到大量操作请求”的情况,主要发生在web系统集中大量访问收到大量请求,例如“双十一”活动。一些情况的发生会导致系统在这段时间内执行大量操作,例如对资源的请求,对数据库的操作等。
高性能是指程序处理速度快,所占内存少,cpu占用率低。高并发和高性能是紧密相关的,提高应用的性能,是肯定可以提高系统的并发能力的。可以从计算和 I/O 两个维度考虑可能的优化点。
扩展是让我们的数据库能够提供更强的服务能力,更强的处理能力。可扩展是表明数据库系统在通过相应升级之后能够达到提供更强处理能力,意味着即使在负载增加(数据量、流量、复杂性)的情况下也有保持性能的策略。
考虑到以上需求,在商品销售数据库设计与实现的过程中,下面列出一些应对方案:
- 采用分布式数据库
现在普遍采用的分布式架构方案,通过使用更多的服务器,将这些服务器构成一个分布式集群,通过这个集群,对外统一提供服务,以此来提高系统整体的处理能力。
分布式数据库采用了横向扩展(scale-out)思路,遇到瓶颈通过加机器而不是加配置解决,这样就能实现无限水平扩展。再多的数据都能使用一定的分片策略分散到不同的机器,分而治之就是分布式的核心理念。
- 考虑NoSQL数据库的使用,如Redis
典型的NoSQL数据库有Redis、LevelDB 这样的 KV 存储。这类存储相比于传统的数据库的优势是极高的读写性能,一般对性能有比较高的要求的场景会使用。除此之外,还有Hbase、Cassandra 这样的列式存储数据库。这种数据库的特点是数据不像传统数据库以行为单位来存储,而是以列来存储,适用于一些离线数据统计的场景。
下面对Redis数据库进行一些说明。
Redis 是一个开源的、使用 C 语言编写的 NoSQL 数据库,具有极高的数据读写速度:数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
Redis一个典型的应用场景是电商网站。电子商务网站上的商品,一般都是一次上传,无数次浏览的,也就是”多读少写”。
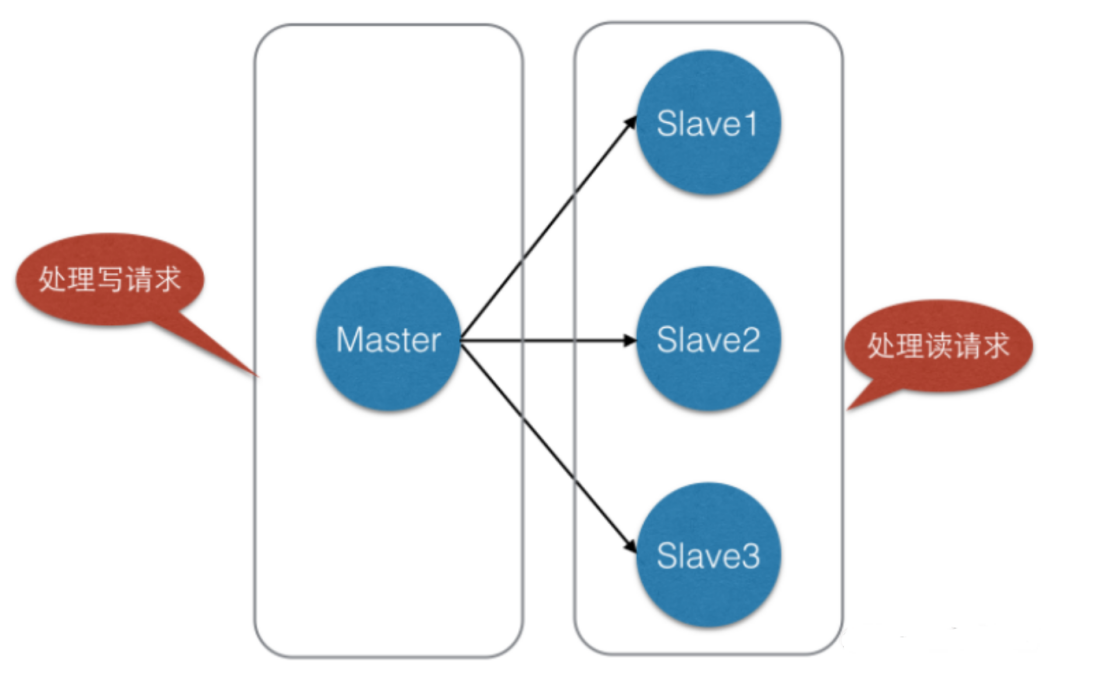
图 1 Redis典型应用场景
如图1,我们将一台Redis服务器作主库,,其他三台作为从库,主库只负责写数据,每次有数据更新都将更新的数据同步到它所有的从库,而从库只负责读数据。
这样一来,实现了读写分离,不仅可以提高服务器的负载能力,并且可以根据读请求的规模自由增加或者减少从库的数量;除此之外,数据被复制成了了好几份,就算有一台机器出现故障,也可以使用其他机器的数据快速恢复。
- 多级缓存
缓存按照存放的位置一般可分为两类:本地缓存和分布式缓存。一级缓存为本地缓存,二级缓存为分布式缓存。
一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存。一级缓存过期或不可用时,访问二级缓存的数据。如果二级缓存也没有,则访问数据库。
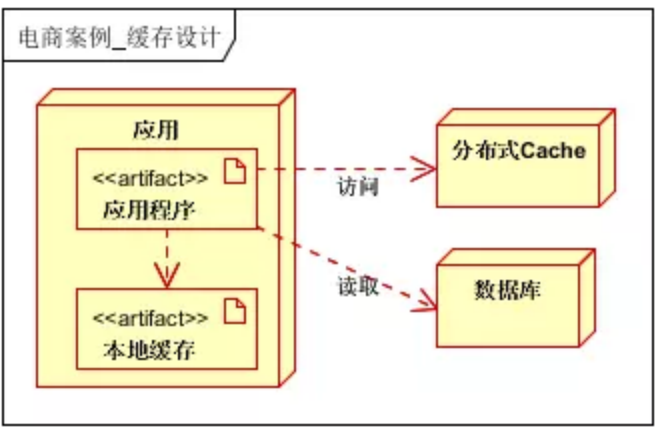
图 2 多级缓存
多级缓存在高并发低延迟要求复杂的场景,能给数据库减负,有效减少其压力。
- 分库分表
改善数据库性能常用的手段是进行分库分表。
垂直分表是指以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。
水平分表是以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
水平分库是指将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
垂直分库是按照一定业务逻辑对表进行垂直切分,比如用户相关的表放在一个数据库里,订单相关的表放在一个数据库里。它的核心理念是专库专用。高并发场景下,垂直分库一定程度地提升I/O、数据库连接数、降低单机硬件资源的瓶颈。
- 数据库分片
一台计算机或数据库服务器只能存储和处理有限数量的数据。数据库分片通过将数据拆分为更小的块并将其存储在多个数据库服务器上来克服此限制。所有数据库服务器通常都具有相同的底层技术,它们协同工作以存储和处理大量数据。
值得注意的是,数据库分片类似于水平分区。这两个进程都将数据库拆分为多组唯一的行。分区将所有数据组存储在同一台计算机上,但数据库分片将它们分布在不同的计算机上。
使用数据库分片来添加更多计算资源,以支持数据库扩展这样电商网站可以在运行时添加新的分片,而无需关闭应用程序进行维护,有效提高了可拓展性。
- 借助搜索引擎解决复杂查询问题
考虑从一个亿级数据的商品表里,寻找名字含“秋裤”的商品。使用SQL语句查询:select * from item where name like '%秋裤%';但这无法使用上索引,会在大量数据集上做一次遍历操作,查询会非常慢。
可以看出,直接在数据库上查询已经无法满足这些数据的查询性能要求,还需要部署独立的搜索引擎提供查询服务。
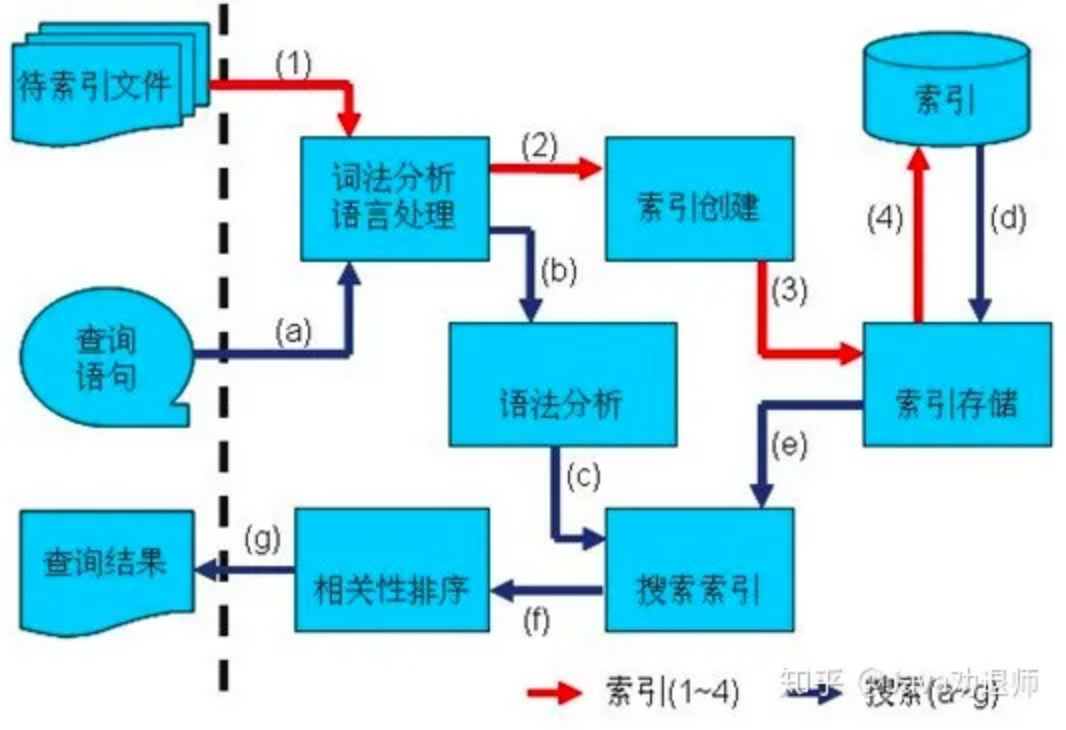
图 3 使用搜索引擎
如图3,事先 build 一个倒排索引,通过词法语法分析、分词、构建词典、构建倒排表、压缩优化等操作构建一个索引,查询时通过词典能快速拿到结果。这既能解决全文检索的问题,又能解决了SQL查询速度慢的问题。
- 优化I/O
减少I/O次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式避免RPC调用;减少 I/O 时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存 key 的大小、压缩缓存 value 等。