神经网络压缩
Network Compression(神经网络收缩)
- 把硕大的模型缩小,因为很多时候需要把这些模型运用在有资源约束的环境下(例如:智能手表、无人机、自驾车)
把资料传在云端,在云端做运算,最后再把结果回传:这种方法的局限性就是传输会有时间差,如果需要做非常及时的回应,中间的时间差可能无法接收,并且这种方法也无法保障隐私
既然小的Network也能有很高的正确率,为什么不训练小的Network?
大的Network比较好训练,因为大的Network包含了很多小的Network,某个小的Network不一定包含结果好的函数,直接训练大的Network相当于训练了很多小的不同模型的Network;直接训练某个小的Network,往往没有办法得到和大的Network同样的正确率,通过大Network裁剪剩下的小的Network都的那些有较好结果的小的Network
Network Pruning(神经网络裁剪)
- 把Network中一些参数减掉,一个巨大的Network中不一定全部参数都有用,Network Pruning的概念就是把一个巨大的Network中没用的参数找出来,并去除掉
- 评估每个参数的重要性:看参数的绝对值(越接近0的参数越不重要)
- 评估每个神经元的重要性:看神经元输出不为0的次数
- 裁剪之后模型的正确率就会降低,需要再重新训练一下,通过微调使正确率回升
- 一次裁剪不可以去除太多参数,但可以进行多次裁剪
Weight Pruning(以参数为单位裁剪)
- 由于裁剪会导致Network不规则,在实做中,GPU加速运算时不能把其看做矩阵乘法运算,所以可以对去掉的参数补0,实际上这样并没有将Network变小
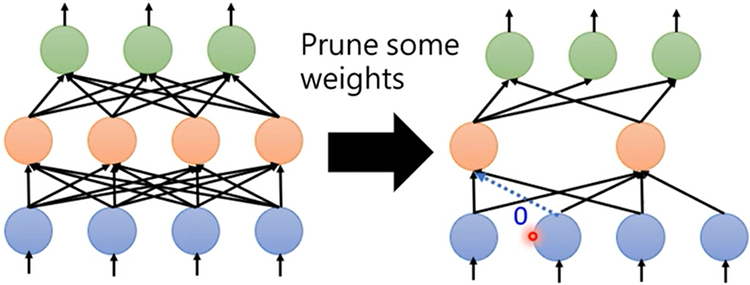
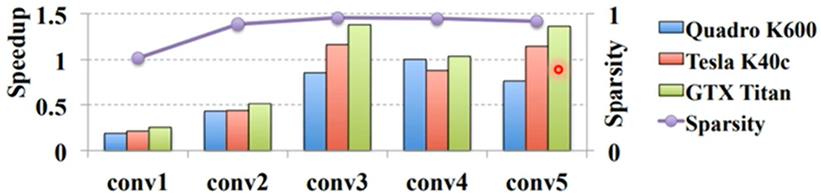
这种方法往往可以裁剪95%的参数,并且正确率只掉1%~2%,但计算时间并没有明显减少
Neuron Pruning(以神经元为单位裁剪)
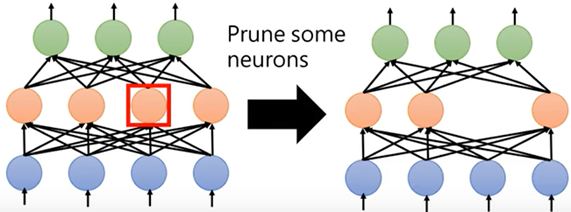
- 这种方法裁剪之后并不会导致Network不规则
Knowledge Distillation(知识净化)
- 先训练一个大的Network,这个大的Network当做老师,再根据这个大Network去训练一个小的Network,学生Network训练时,直接拿老师的输出当成正确答案,这样可以让学生Network学到更多的东西(Ensemble:取多个老师输出的平均结果当成正确答案学习)
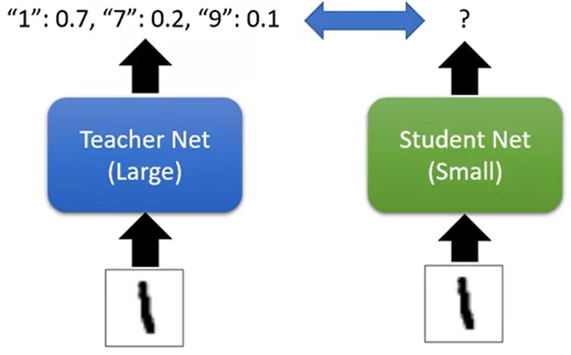
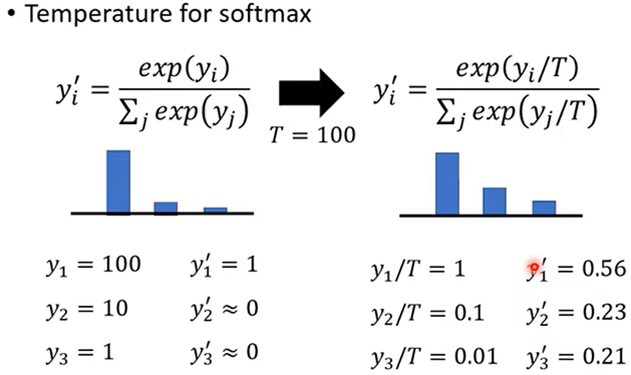
当老师Network输出比较集中时,通过Softmax后可能和标注一样,所以可以Temperature的技巧使输出更加平滑
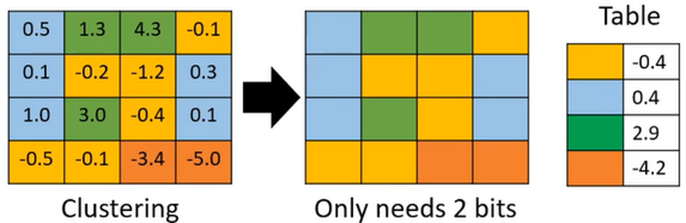
Parameter Quantization(参数量化)
- 只用比较少的空间来储存一个参数
- 16Bit存储一个参数改为4Bit存储
- 把值相近的参数设置为公共参数,这样便只需保存一次
Architecture Design(系统结构设计)
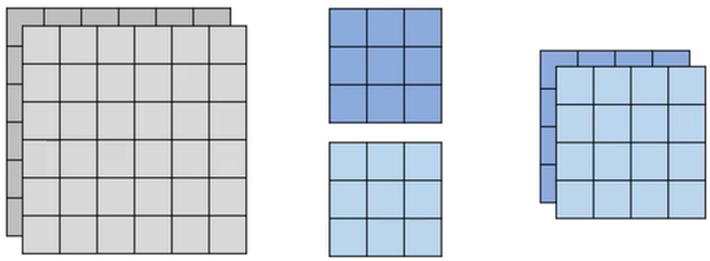
1、Depthwise Convolution(切除卷积):有几个Channel就有几个Filter,一个Filter只管一个Channel(主要用于缩减特征值),不像CNN(卷积卷积神经网络),Filter数量和Channel数量没有关系;这样的缺陷是,缩小后的特征值中,Channel之间没有任何互动
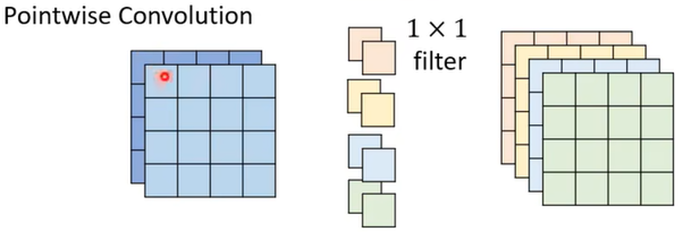
2、 pointwise convolution(逐点的卷积):用1*1的Filter去扫过缩小的特征值求和,建立不同Channel之间的联系(与CNN中一样,只强制了filter的大小)
Dynamic Computation(动态计算)
- 希望Network可以自由的调整计算量,因为有时候同样的模型需要在不同的设备上运行,不同设备的运算资源是不同的,并且同一设备在不同状态的计算资源也不同
- 让Network可以自由的调整他的深度:训练一个很深的Network
方法:
- 在中间某些层中加入一些额外的层,用于根据这层的输出直接得到结果;当运算资源充足时,可以运行全部的层得到最终结果,当运算资源不充足时,Network就自行决定在某个层直接输出结果
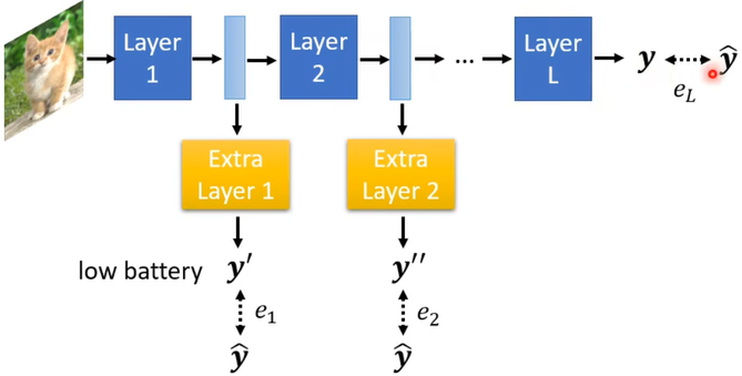
- 让Network根据当前的机器状态自由的决定他的宽度
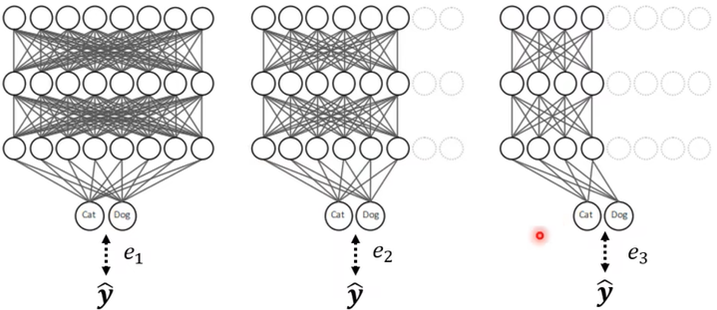
然后训练时所有的状况都考虑,例如:![]() 最小化(不唯一)
最小化(不唯一)
结:前4中技术并不是互斥的,可以同时使用