2023.7.17-2023.7.24暑假第二周博客
2023.7.17 实操 使用命令操作HDFS文件系统
拷贝HDFS文件
hadoop fs -cp [-f] <src> ... <dst>
-f同样表示的是强制覆盖
hdfs dfs+的内容是一样的
[root@node3 ~]
# hadoop fs -cp /small/1.txt /itcast
[root@node3 ~]
# hadoop fs -cp /small/1.txt /itcast/666.txt # 重命名
[root@node3 ~]
# hadoop fs -ls /itcast
Found 4 items
-rw-r--r-- 3 root supergroup 2 2021-08-18 17:58 /itcast/1.txt
-rw-r--r-- 3 root supergroup 2 2021-08-18 17:59 /itcast/666.txt
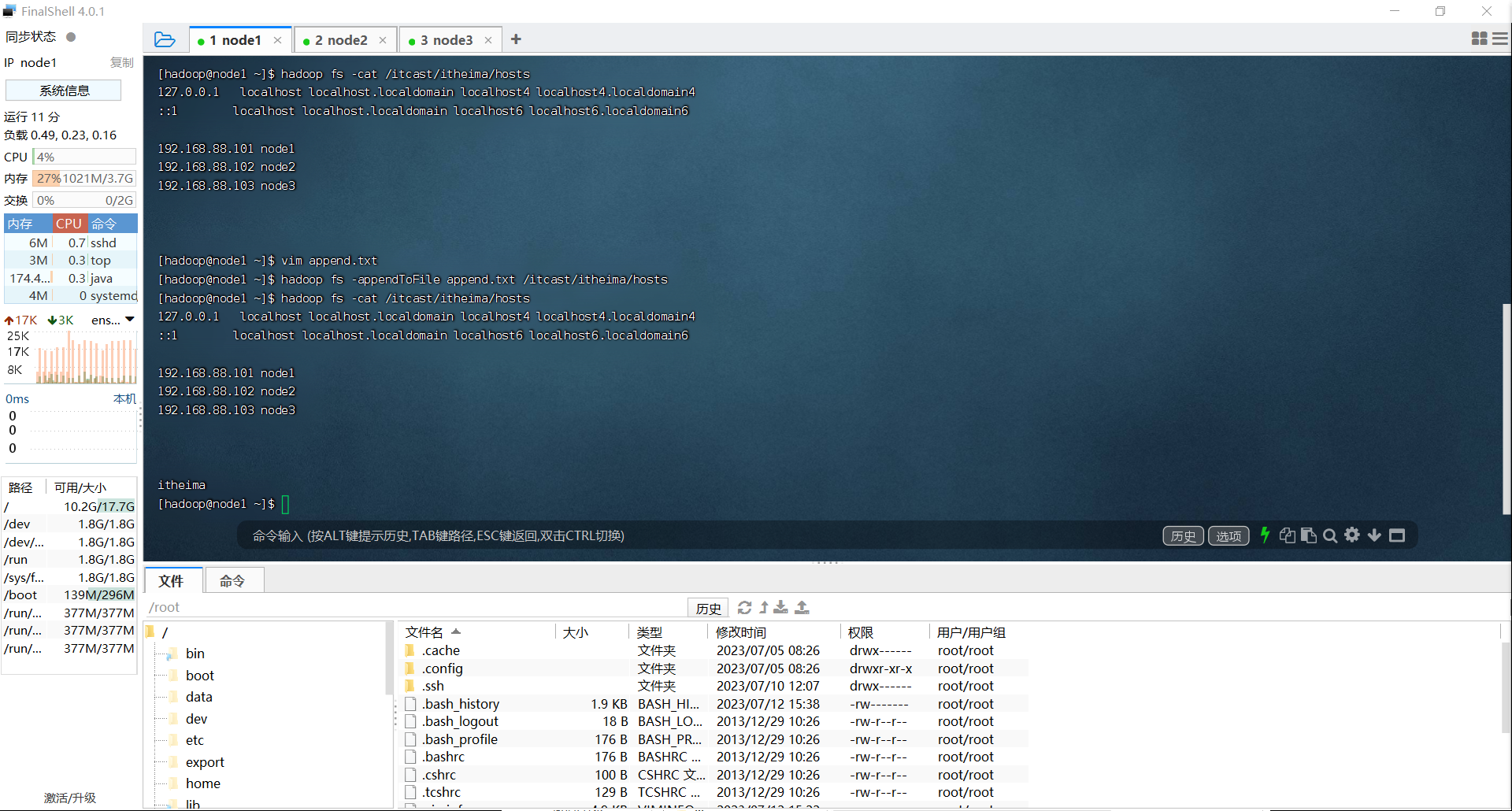
追加数据到HDFS中
hadoop fs - appendToFile <localsrc> ... <dst>
hdfs dfs -appendFile <localsrc> ... <dst>
[root@node3 ~]
# echo 1 >> 1.txt
[root@node3 ~]
# echo 2 >> 2.txt
[root@node3 ~]
# echo 3 >> 3.txt
[root@node3 ~]
# hadoop fs -put 1.txt /
[root@node3 ~]
# hadoop fs -cat /1.txt
1
[root@node3 ~]
# hadoop fs -appendToFile 2.txt 3.txt /1.txt
[root@node3 ~]
# hadoop fs -cat /1.txt
HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
HDFS删除命令
hadoop fs -rm -r
hdfs fs -rm -r
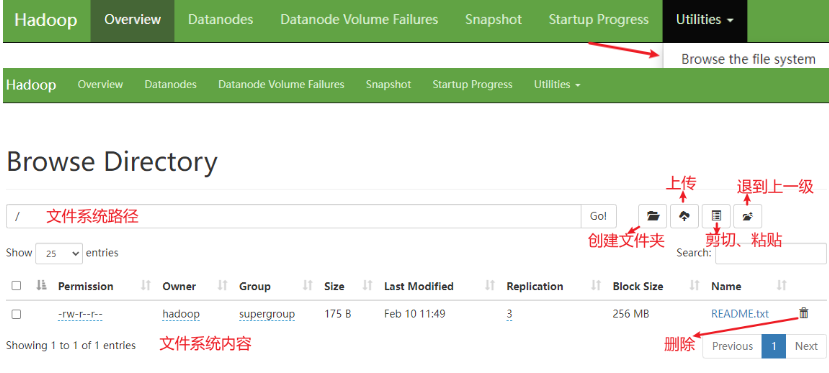
同样,在web页面也能查看HDFS文件系统的内容
2023.7.18 HDFS Shell命令权限不足问题的解决方案
HDFS的权限控制的控制逻辑和Linux的文件系统是完全一致的
但是对于Linux中的超级用户是root
而HDFS的超级用户不是固定 ,它取决于启动namenode的用户,也就是我当前所用的hadoop用户
修改文件权限
hadoop fs -chown [-R] root:root /xxx.txt
hadoop fs -chmod [-R] 777 /xxx.txt
2023.7.19
HDFS客户端之Jetbrians插件
Big Data Tools插件可以帮我们方便的操作HDFS,相当于IDEA/Pycharm等等
对于HDFS文件操作系统进行了可视化,操作起来更加便捷而省去了敲命令的过程
以下是安装过程
1.在IDEA是settings中的plugin中搜索Big Data Tools 会出现对应的插件,安装后需要进行配置
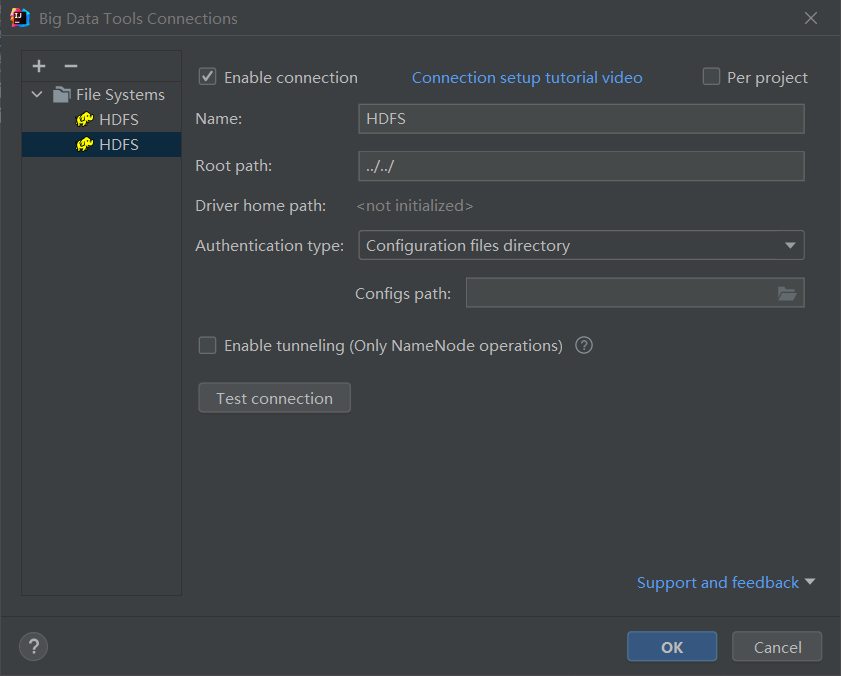
这里我直接选了用端口号进行配置,如果采用文件位置的方式需要替换和切换,相对来说比较麻烦,开启虚拟机后,用finalshell开启HDFS文件系统(start-dfs.sh)
然后配置端口号(101 102 103),:8020即可
点击Test connection后进行测试,显示绿色即为成功
然后在这个可视化的页面中,就像windows一样可以对内容进行增删改查,十分的方便,比起之前命令行来说更加人性化了
2023.7.20
HDFS的存储原理
1.数据是如何在HDFS中储存的
把一个大的文件划分成不同的部分,分别存储到不同的服务器中
把文件从HDFS中取回来,需要组装回来
即分布式存储:每个服务器存储文件的一部分,多个文件也一样
但是这样会出现一个问题:文件大小不一,不利于统一管理,因此不管多大,都划为一个统一的单位,即 一个block块,每个256MB
也就是说,一个1GB的文件想要存储到HDFS中,需要划分为四个block块,当然,block的大小可以通过配置文件进行修改
这样存储虽然方便,但是存在一个致命的问题——block块丢失了该怎么办
而且block块越多,损坏的几率越大
解决方案:通过多个副本(备份)解决
把某一个块复制几个备份放到别的服务器中,把每个块都复制几份,存储到其他的服务器中,这样安全性就大大提高了
一般来说,可以在hdfs-site.xml中的dfs.replication进行值的修改,如果需要自定义这个属性,则需要修改每一台服务器的hdfs-site.xml文件,并设置这个属性
除了提前配置,可以在上传文件的时候,临时决定被上传文件以多少个副本储存
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
这样做是临时配置,对于已经存在的HDFS文件,这个修改不会生效,如果要修改已经存在的文件
hadoop fs -setrep [-R] 2 path
-R表示递归,对子目录的内容也生效
2023.7.21
从21号开始要去上海,预计24日回来,因此博客会停23、24日两天,其他我都会在旅途过程中进行撰写
今日学习,fsck命令检查文件的副本数
利用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
fsck可以检查指定路径是否正常
-files可以列出路径内的文件状态
-files -blocks 输出文件块报告(有几个块,多少副本)
-files -blocks -locations 输出每一个block的详情
在显示出的内容中有两个
一个是Default replication factor 表示系统默认设置(文件里的分块数)
一个是Average block replication 表示当前查询的分块数
通过fsck命令查询了文件的副本数,默认是256MB一个,当然 也可以进行修改
块大小可以通过参数:
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description> 设置 HDFS 块大小,单位是 b</description>
</property>
如上,设置为 256MB
配置副本数: dfs.replication ,默认 3
配置 block 大小: dfs.blocksize ,单位为 b ,一般配置为 256MB
2. 副本和 block 相关命令
• 上传文件临时修改副本数: hadoop dfs -D dfs.replication=2 -put
test.txt /tmp/
• 修改已存在文件副本数: hadoop fs -setrep [-R] 2 path
• 检查文件系统: hdfs fsck path [-files [-blocks [-locations]]]