SAS - 正则表达式
SAS - 正则表达式
正则表达式(Regular Expression)是一种文本模式,可用于文本的匹配、查找和替换。Base SAS 内置了正则表达式的实现,并提供了一系列 PRX 函数及 CALL 子程序,便于对文本进行更为灵活的处理。
正则表达式的结构
正则表达式由普通字符和元字符组成。元字符用于匹配符合特定规则的字符集合,例如:数字、字母、标点符号等字符集合。
元字符又分为:基本元字符、定位符、限定符等。
基本元字符
常用的基本元字符如下:
- \d : 匹配数字0-9
- \n : 匹配换行符
- \num : 匹配第 num 个捕获的缓冲
- \s : 匹配空白字符,包括空格、制表符等
- \t : 匹配制表符
- \w : 匹配任何单词字符、数字字符、下划线
例如:\d\d 将匹配两个连续的数字。
定位符
定位符用于限定匹配字符串的边界。
- ^ : 匹配字符串的开头
- $ : 匹配字符串的结尾
- \b : 匹配一个单词的边界
- \B : 匹配一个单词的非边界
例如:^apple$ 只能匹配单词 apple,这是因为使用了定位符,^ 限制匹配的单词只能以 a 开头,$ 限制匹配的单词只能以 e 结束。如果不加定位符,apple 不仅可以匹配单词 apple,还可以匹配单词 pineapple 中的 apple。
限定符
限定符用于限制某个匹配模式的重复次数。
- * : 匹配 0 次或更多次
- + : 匹配 1 次或更多次
- ? : 匹配 0 次或 1 次
- {n} : 匹配 n 次
- {n,} : 匹配至少 n 次
- {n,m} : 匹配至少 n 次,至多 m 次
例如:\d+ 表示匹配至少一个数字; ^app\w{0,2}$ 表示匹配以 app 开头的长度不超过 5 的字符串,包括 apple、apply 等。
限定符的匹配默认是贪婪(Greedy)的,即尽可能匹配更多的字符,但这种默认行为有时候并不是我们想要的。这时候可以使用非贪婪(Lazy)匹配,只需要在贪婪匹配的限定符后添加一个 ? 即可。
例如:fo{1, 3}? 会匹配字符串 foooooo 中的 fo,而 fo{1, 3} 则会匹配到 fooo,因为这是一个贪婪模式,会尽可能匹配更多的字符。
其他元字符
- | : 匹配两个模式之一
- . : 匹配任何字符,除了换行符
- () : 括号内部是一个匹配模式,表示一个组合
- ** : 匹配一个特殊字符
例如:
dog|t表示匹配字符串 dog 或 tdo(g|t)表示匹配字符串 dog 或 dot;.*表示匹配任意多个字符,不包括换行符\.表示匹配字符 "." 本身
集合
如果需要匹配多个字符中的一个,连续使用多个 | 是一种解决办法,但更推荐的是使用集合。使用 [] 表示一个集合,其中包含的字符表示需要匹配的字符。例如:[abcde] 表示匹配字母 a~e,等价于 (a|b|c|d|e)。如果需要进行反向匹配,只需要在开头加上 ^ 符号,例如:[^abcde] 匹配任何字母 a~e 之外的字符。
- [...] : 匹配集合中的任意字符
- [^...] : 匹配集合外的任意字符
对于常见的集合,SAS 提供了更为简洁的表达方式:
- [a-z] : 匹配小写字母 a~z
- [A-Z] : 匹配大写字母 A~Z
- [0-9] : 匹配数字 0~9
- [[:alpha:]] : 匹配单个字母
- [[:alnum:]] : 匹配单个字母或数字
- [[:blank:]] : 匹配单个空白字符
- [[:digit:]] : 匹配单个数字
- [[:lower:]] : 匹配单个小写字母
- [[:upper:]] : 匹配单个大写字母
- [[:punct:]] : 匹配单个标点符号
例如:[A-Za-z_0-9_][A-Za-z0-9]{0, 7} 可以匹配一个 SAS V5 下的合法的变量名。
字符串匹配
通过构建合适的正则表达式,可以实现复杂规则的字符串匹配。SAS 提供了 PRXMATCH 函数用于正则表达式的匹配。
正则表达式本身也是一个字符串,在 SAS 中进行匹配的时候,为了与普通字符串区分,需要在正则表达式两端添加斜杠 / 以示区分。例如:/\d{4}/。
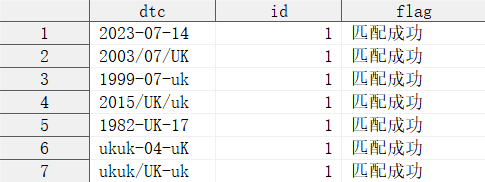
例如:匹配文本类型的日期,其中日期可能包含缺失值。
data test;
input dtc $10.;
cards;
2023-07-14
2003/07/UK
1999-07-uk
2015/UK/uk
1982-UK-17
ukuk-04-uK
ukuk/UK-uk
run;
观察数据,可以发现,这些文本类型的日期有共同的规律,即按年、月、日的格式存储,使用 “-” 或 “/” 作为分隔符。使用普通的字符串函数对这类数据进行处理是较为困难的,正则表达式更为合适。
首先,使用 d{4} 和 \d{2} 可以匹配非缺失的年、月、日;使用 (\/|\-) 可以匹配年、月、日之间的分隔符;因此,可以用以下正则表达式匹配非缺失的日期:
\d{4}(\/|\-)\d{2}(\/|\-)\d{2}
由于日期存在缺失,因此匹配年、月、日的时候还需要使用 [Uu][Kk] 对缺失值进行匹配,上述正则表达式进一步演变为:
(\d{4}|([Uu][Kk]){2})(\/|\-)(\d{2}|[Uu][Kk])(\/|\-)(\d{2}|[Uu][Kk])
加上定界符,限制匹配的开头和结尾:
^(\d{4}|([Uu][Kk]){2})(\/|\-)(\d{2}|[Uu][Kk])(\/|\-)(\d{2}|[Uu][Kk])$
再加上与普通字符串区分的斜杠 /:
/^(\d{4}|([Uu][Kk]){2})(\/|\-)(\d{2}|[Uu][Kk])(\/|\-)(\d{2}|[Uu][Kk])$/
至此,一个用于匹配含缺失的文本型日期的正则表达式就构建完成了。我们可以在函数 PRXMATCH 中使用它,可以先使用函数 PRXPARSE 进行解析,获得解析后的解析 ID,然后在函数 PRXMATCH 中直接使用这个解析 ID。
data match;
set test;
id = prxparse("/^(\d{4}|([Uu][Kk]){2})(\/|\-)(\d{2}|[Uu][Kk])(\/|\-)(\d{2}|[Uu][Kk])$/");
if prxmatch(id, dtc) then do;
flag = "匹配成功";
end;
else do;
flag = "匹配失败";
end;
run;