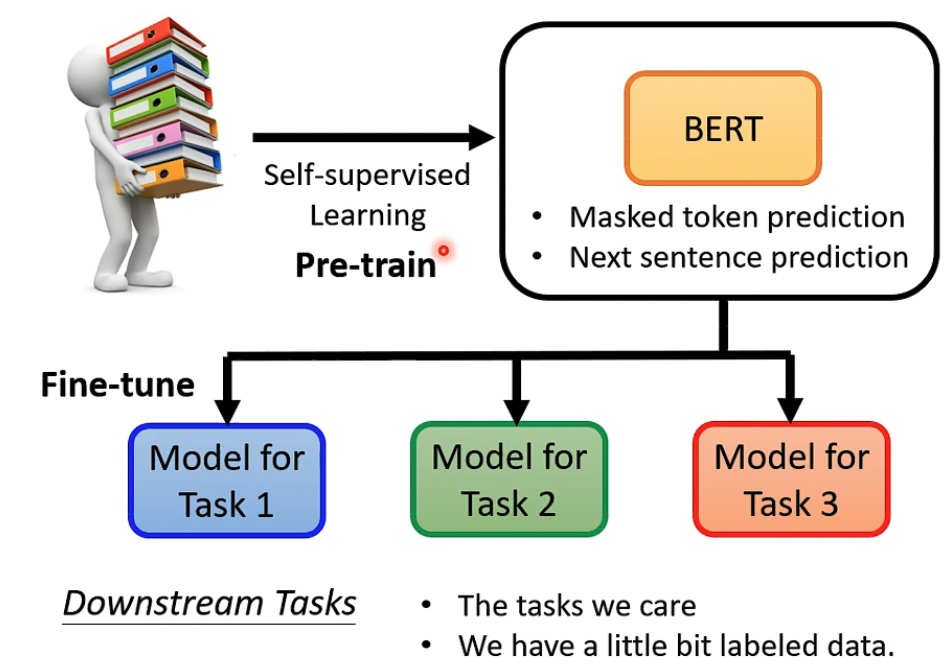
李宏毅BERT笔记
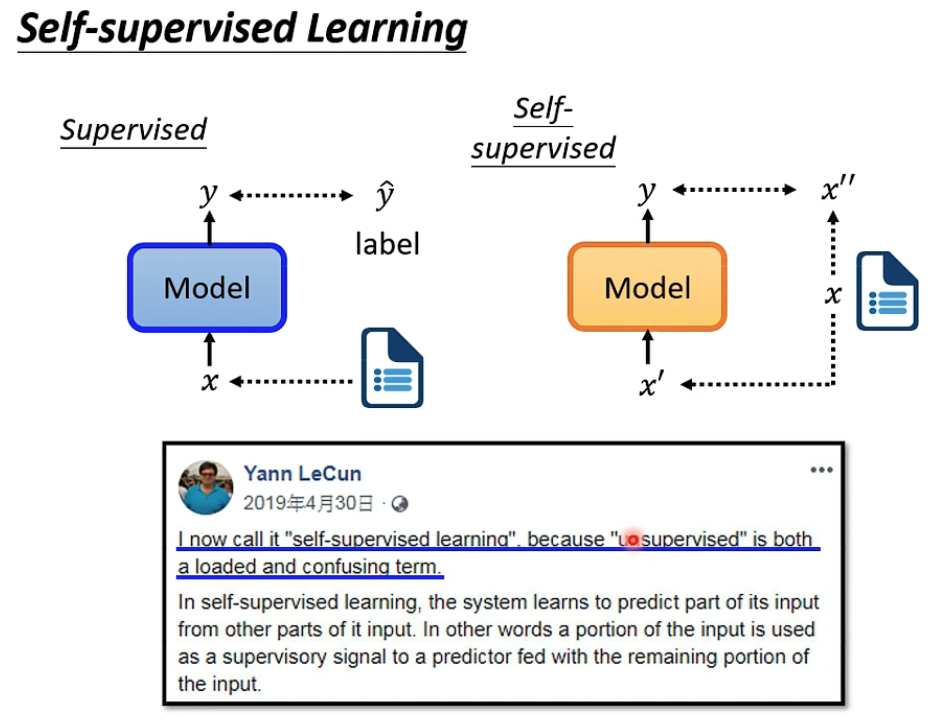
Self-supervised是LeCun提出的
常用于NLP,一段文字分成两部分,用第一部分来预测第二部分
BERT有两种训练的方式,
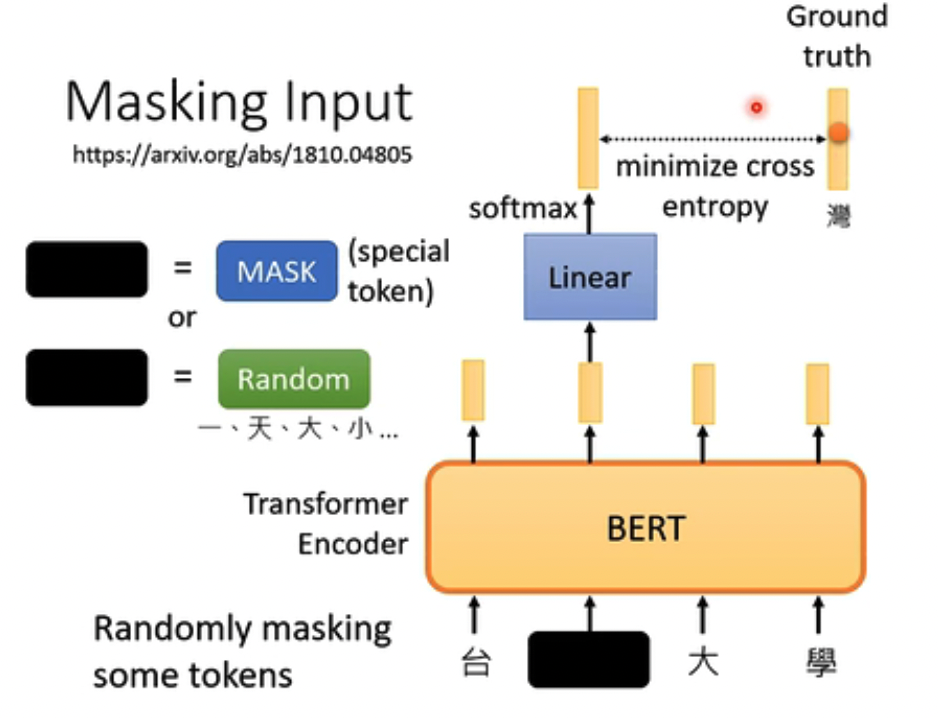
第一种是Masking Input,可以用特殊的MASK token或是Random token来替换原有的,经过BERT模型后,输出为原先的token
第二组是判断两段文字是否相接的,但是后来验证这种训练的方法不是很有效
所以BERT的主要的方式,是完形填空

BERT的架构很像Transformer的Encoder,
所以Pre-train的model无法直接使用,需要加外挂,进行Fine-tune才能用于Downstream Tasks,注意BERT fine-tune的时候是要更新参数的
GPT模型,更像decoder,更适合于生成任务,但GPT使用中,使用的in-context learning是不会改变模型参数的
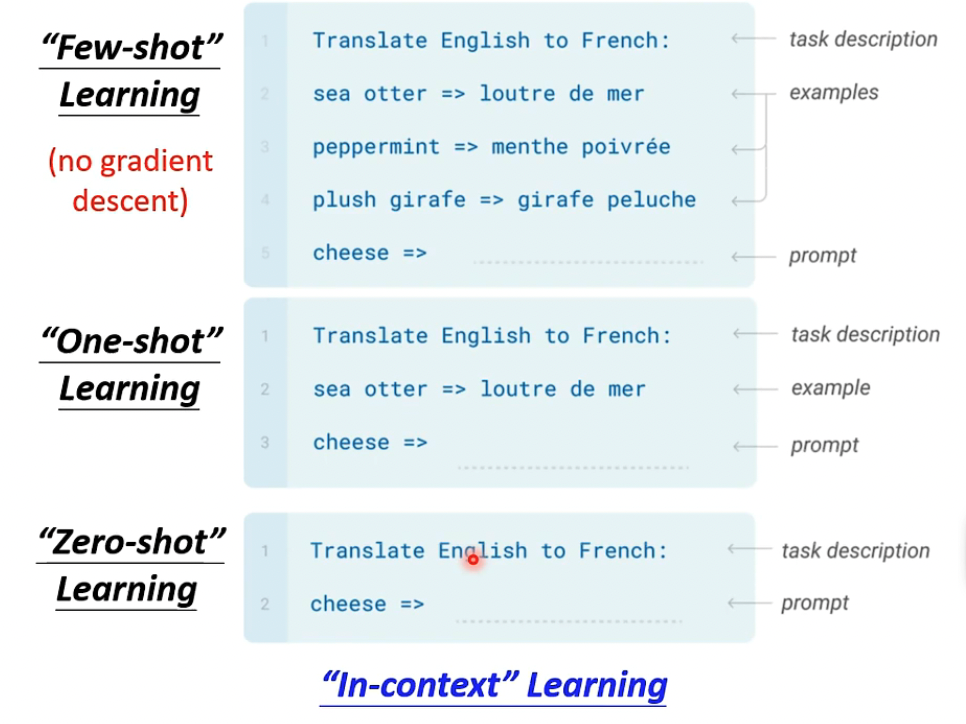
用于验证BERT这样模型的标准叫GLUE


看下如何Fine tune BERT来生成可使用的模型
BERT的Pre-train是self-supervised学习,但是fine-tune是supervised学习,需要大量的训练集的
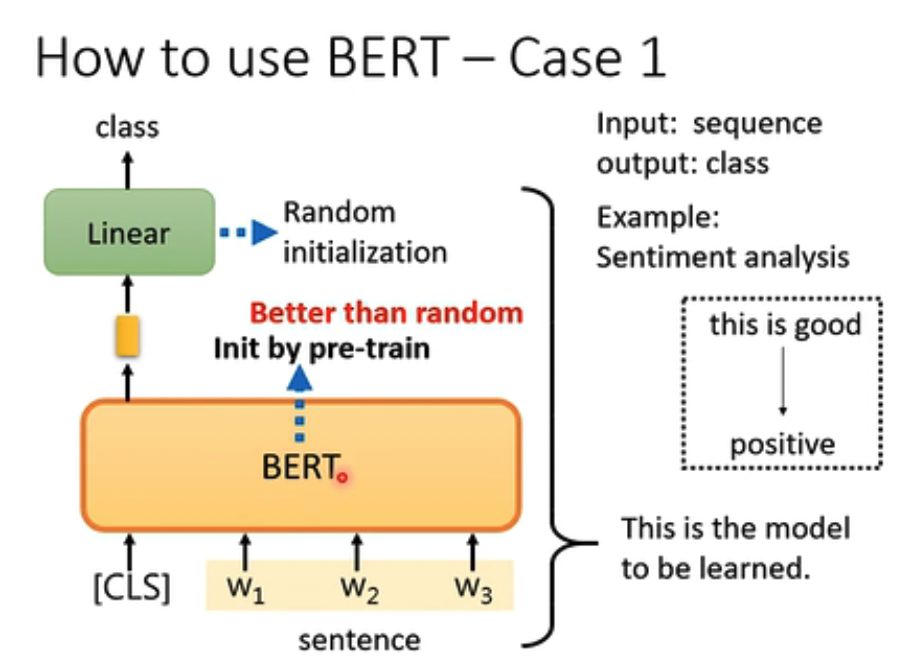
第一个例子是,情感分析
这里注意,BERT的参数是在Pre-train时init的,而Linear是随机init的
Fine-tune的时候,Linear和BERT的参数都是要进行调整的
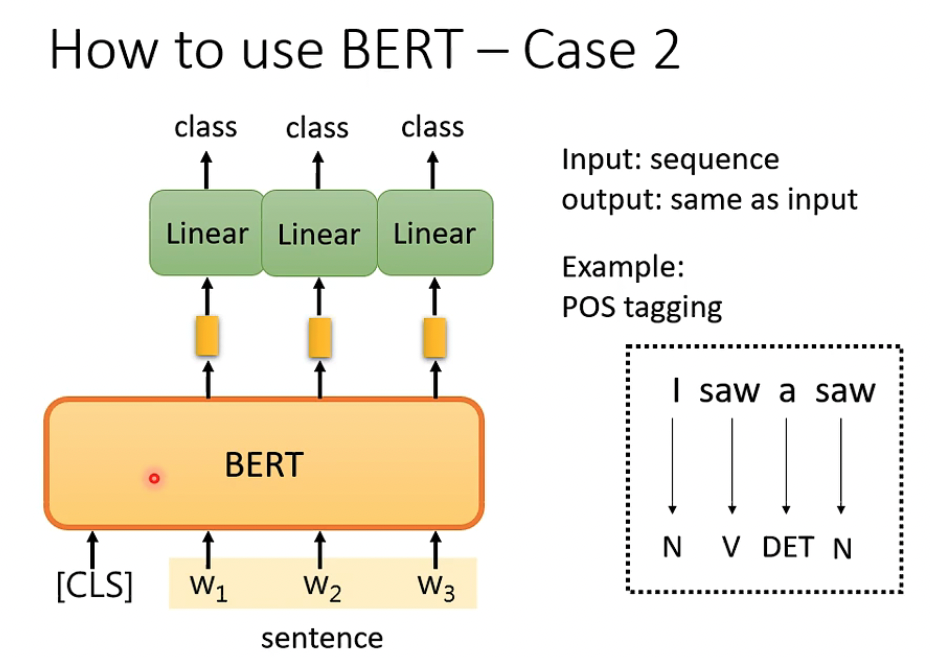
第二个例子比较简单,n to n
第三个例子,NLI,一个前提,一个假设,判断是否符合
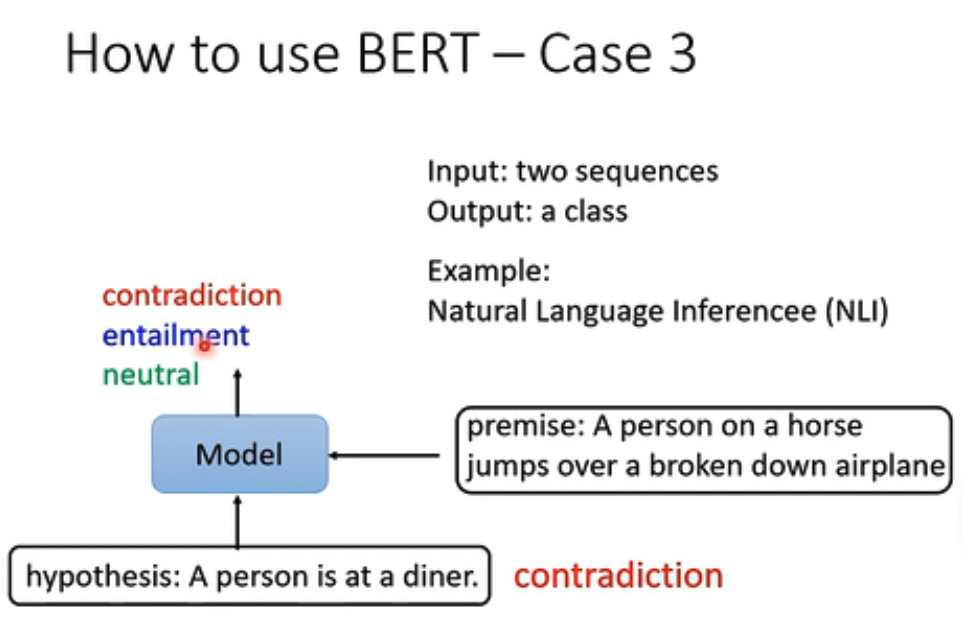
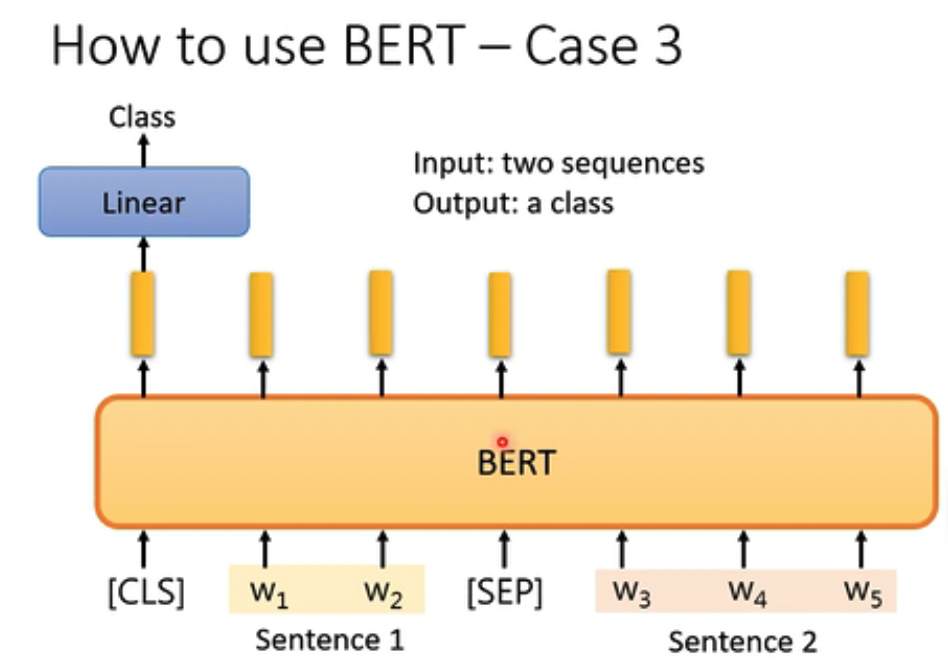
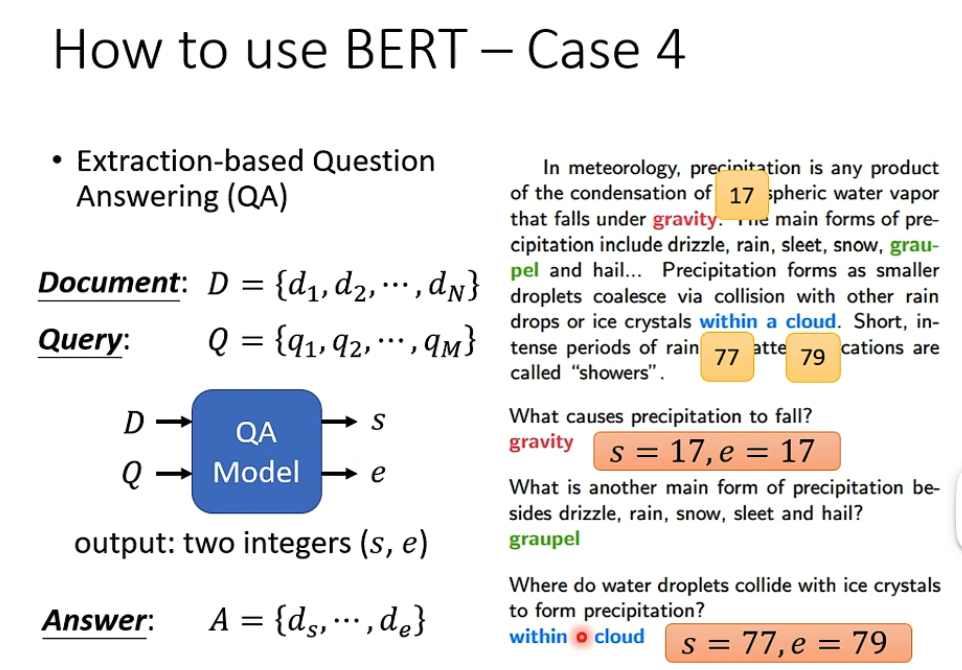
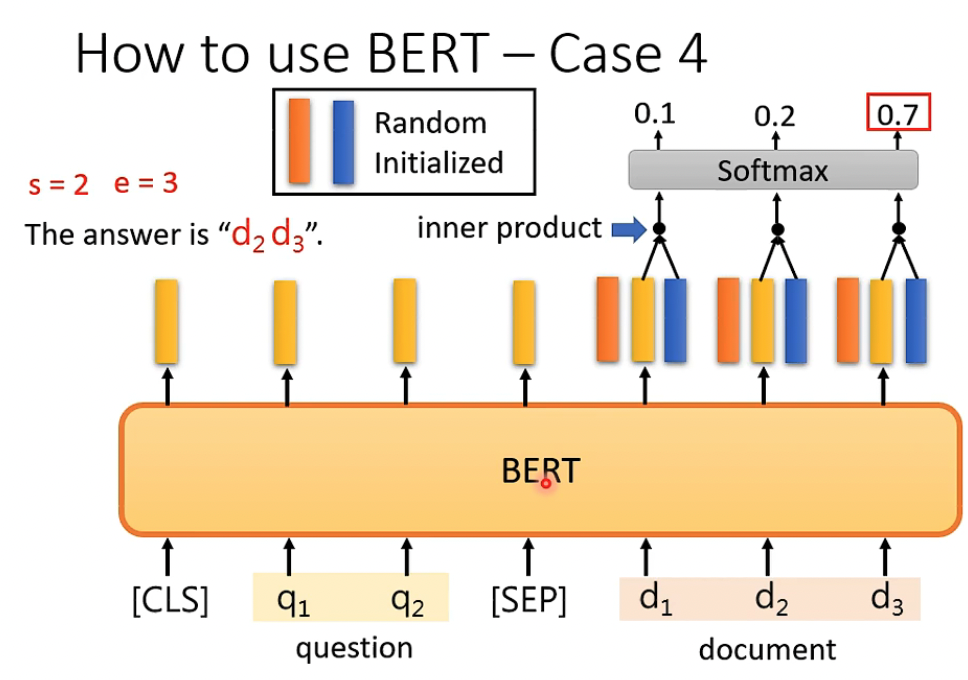
第四个例子比较复杂,QA
给出Document和Query,输出答案的index