My_Blog1_第一次
一、前言
第一次大作业 7-5 答题判题程序-1
知识点
这是设计的第一个答题判题程序,要求我们模拟一个小型测试。程序输入包括题目数量、题目内容和答题信息,输出题目内容、答题结果和判题信息。其主要的知识点是题目类封装题目编号、内容和标准答案;试卷类管理题目列表和判题;答卷类记录答案和判题结果。设计的程序需要解析输入字符串,存储题目信息,判定答案正确性并输出结果。难度较低,是第一个面向对象编程的大作业,我主要的实现方法有:字符串处理、数据结构处理和集合操作。
题量
题目量较小
难度
难度较小
第二次大作业 7-4 答题判题程序-2
知识点
这是从第一次大作业迭代的新的第二次大作业,答题判题程序-2在答题判题程序-1的基础上增加了对试卷信息的处理,要求输入题目信息、试卷信息和答题信息,并根据标准答案判断答题结果。程序输入包括题目信息、试卷信息和答题信息,输出试卷总分警示、答题信息和判分信息。涉及的知识点有:面向对象的类的封装、类的职责划分思想、String类的处理、数据结构处理以及集合处理。
题量
题目量适中
难度
难度一般
第三次大作业 7-3 答题判题程序-3
知识点
第三次大作业需要前两次大作业进行一个综合迭代,增加了学生信息和删除题目的信息,由于删除题目的要求增加,我的类的设计需要细微改变,且题目要求的输入格式也变化了很多,所以这个大作业涉及到了一个新的知识点:正则表达式。此外,这个大作业还涉及到了其它的知识点,如:异常处理、文件操作、类的组合、类的职责划分思想、String类的处理、数据结构处理以及集合处理。
题量
题目量适中
难度
难度中等
二、设计与分析(答题判题程序)
7-5 答题判题程序-1
第一次的答题判题程序,我主要实现了题目类、试卷类和答卷类,下面直接通过类图和顺序图简单介绍,重点实现过程的介绍放在第三次大作业中
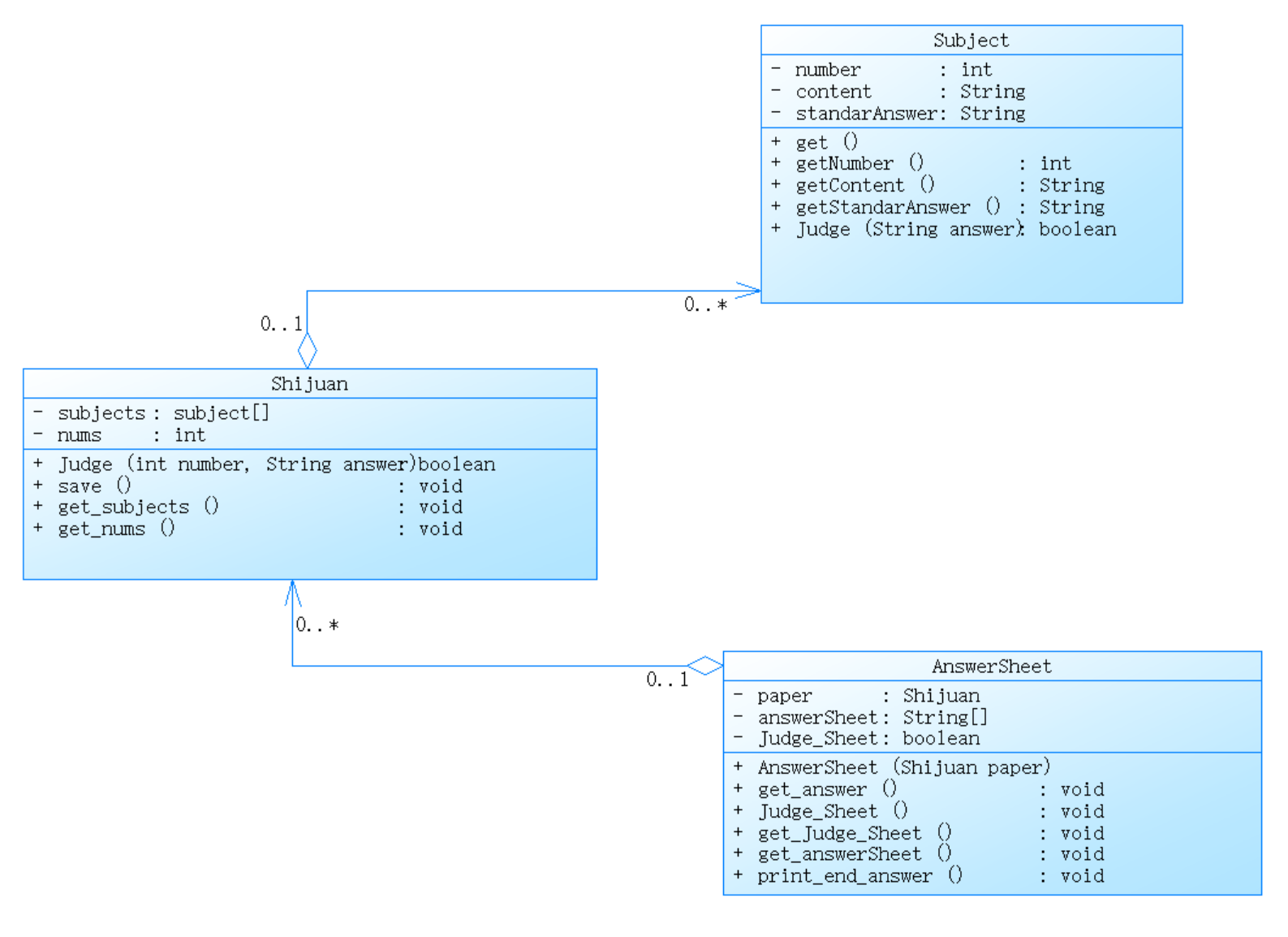
类的设计:
整体设计思路(简单分析):
- 题目类(subject):用于存储题目的编号、内容和标准答案,并提供相应的访问和判分方法。
- 试卷类(Shijuan):用于管理试卷,包括题目列表和题目数量。提供保存题目和判分的方法。
- 答题卡类(AnswerSheet):用于存储答题卡的答案列表和判分结果,并提供获取答案、判分和输出结果的方法。
整体类图:
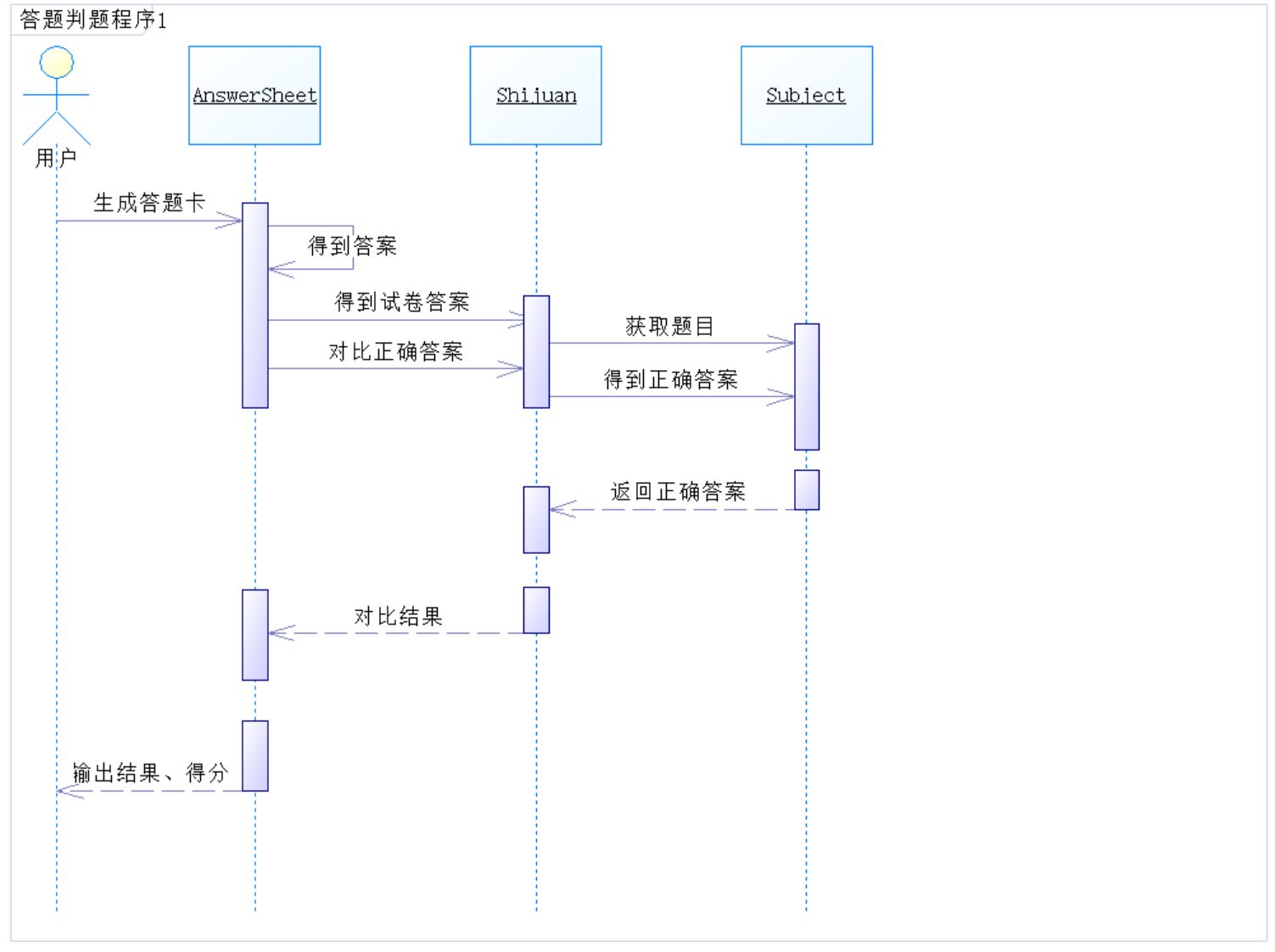
顺序图:
圈复杂度和整体程序结构数据分析:
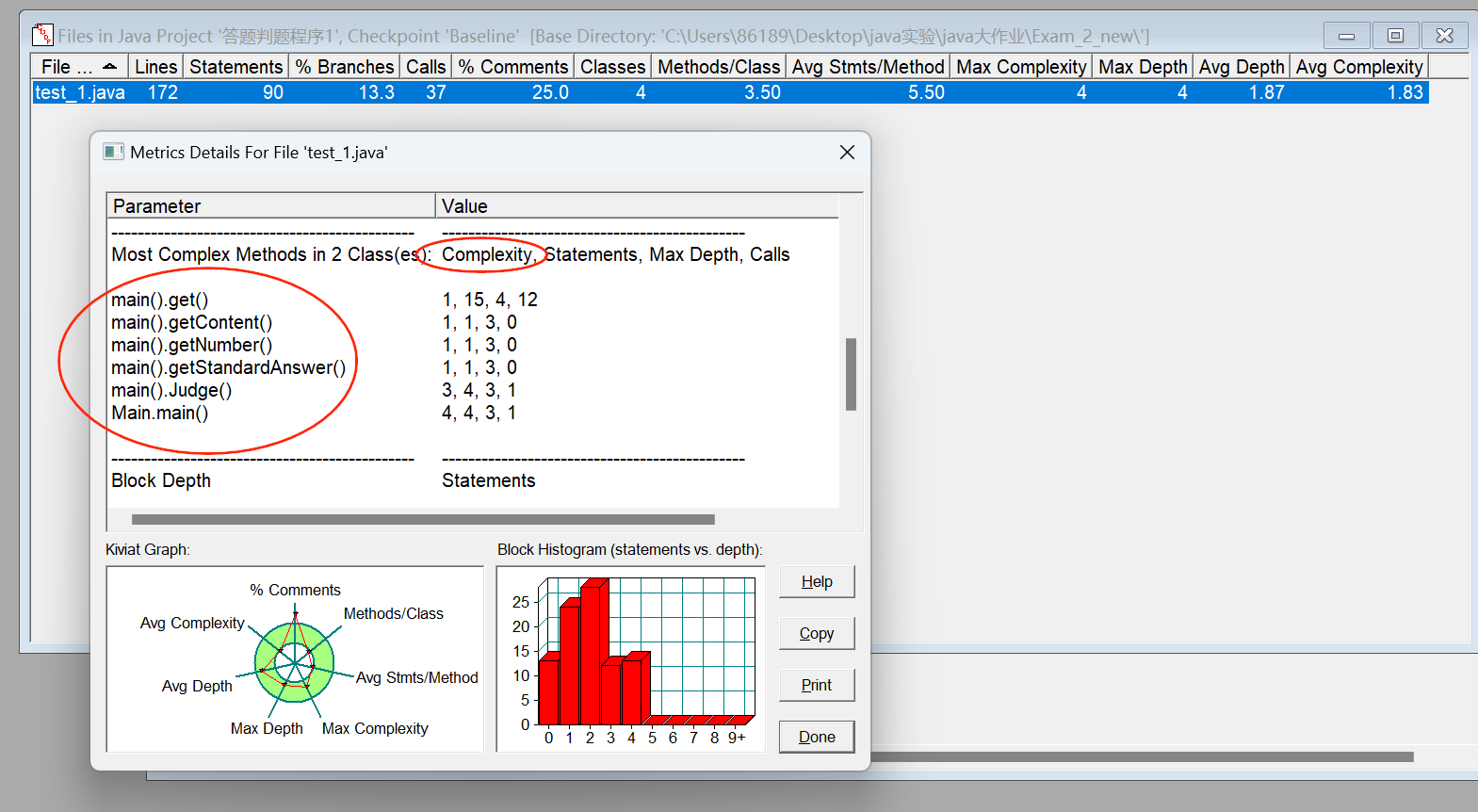
- 虽然我写的代码量比较大,其实实际上圈复杂度也不会特别高
7-4 答题判题程序-2
第二次的答题判题程序,我增加了考试管理类并稍微改变了类的结构,下面也是直接通过类图和顺序图说明,重点实现过程的介绍放在第三次大作业中
类的设计:
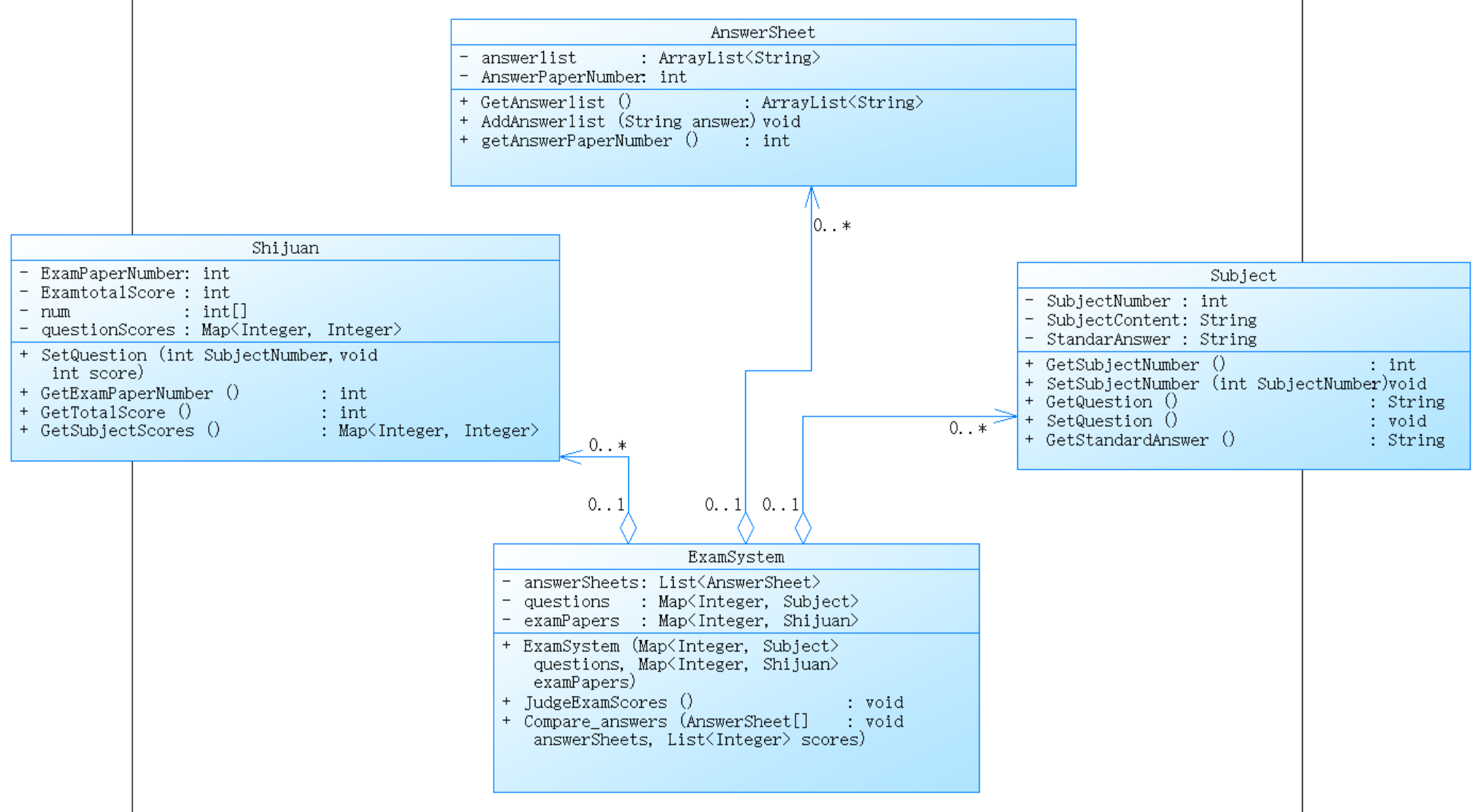
整体设计思路(简单分析):
- 题目类(Subject):用于存储题目的编号、内容和标准答案,并提供相应的访问和修改方法。
- 试卷类(Shijuan):用于管理试卷,包括试卷编号、总分、题目编号数组和每个题目的分值。提供添加题目、获取试卷总分和题目分值等方法。
- 答题卡类(AnswerSheet):用于存储答题卡编号和答案列表,并提供添加和获取答案的方法。
- 考试系统类(ExamSystem):用于管理题目、试卷和答题卡,提供判断试卷分数是否等于或不等于100分和比较答题卡答案的方法。
整体类图:
顺序图:
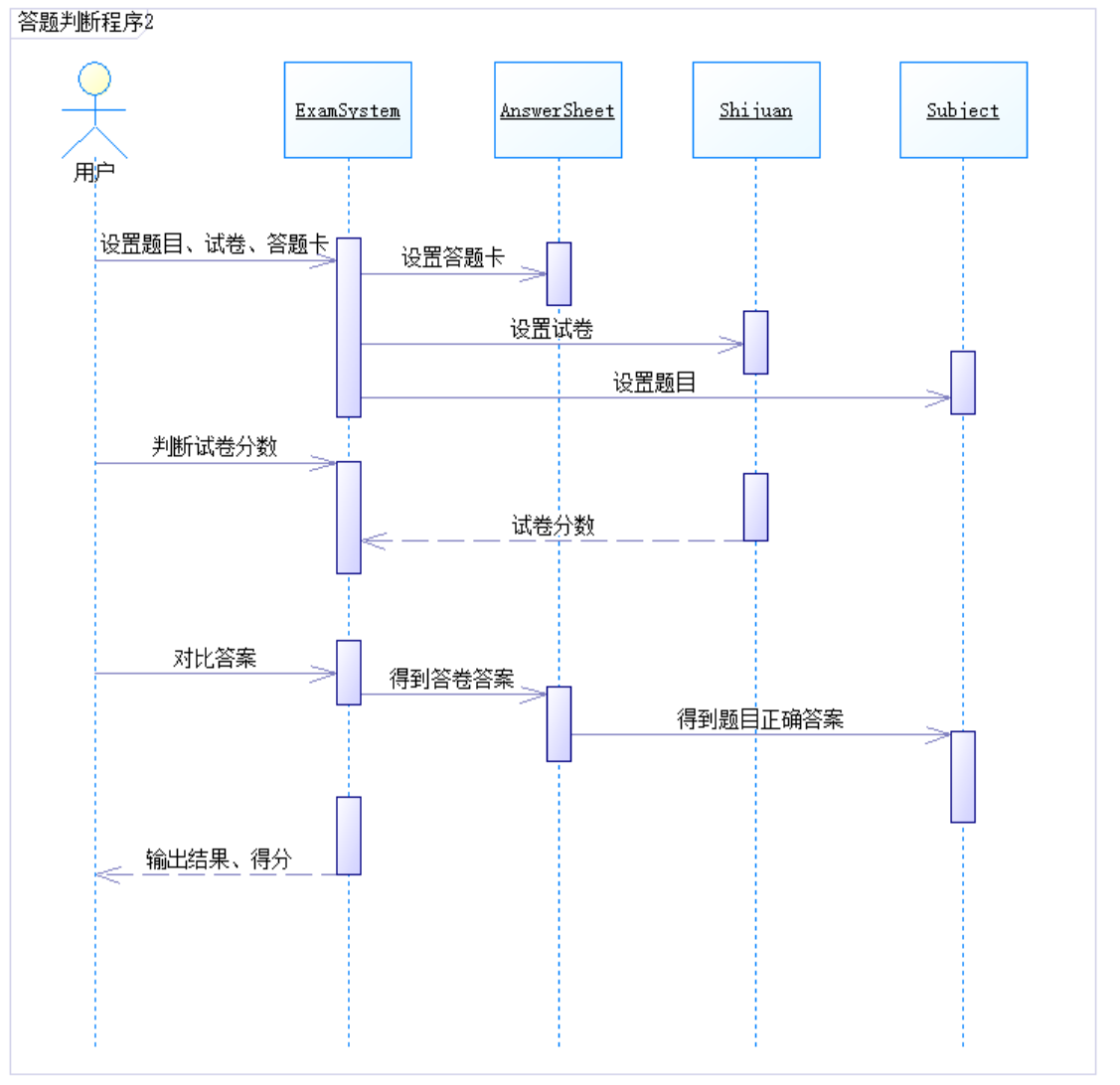
圈复杂度和整体程序结构数据分析:
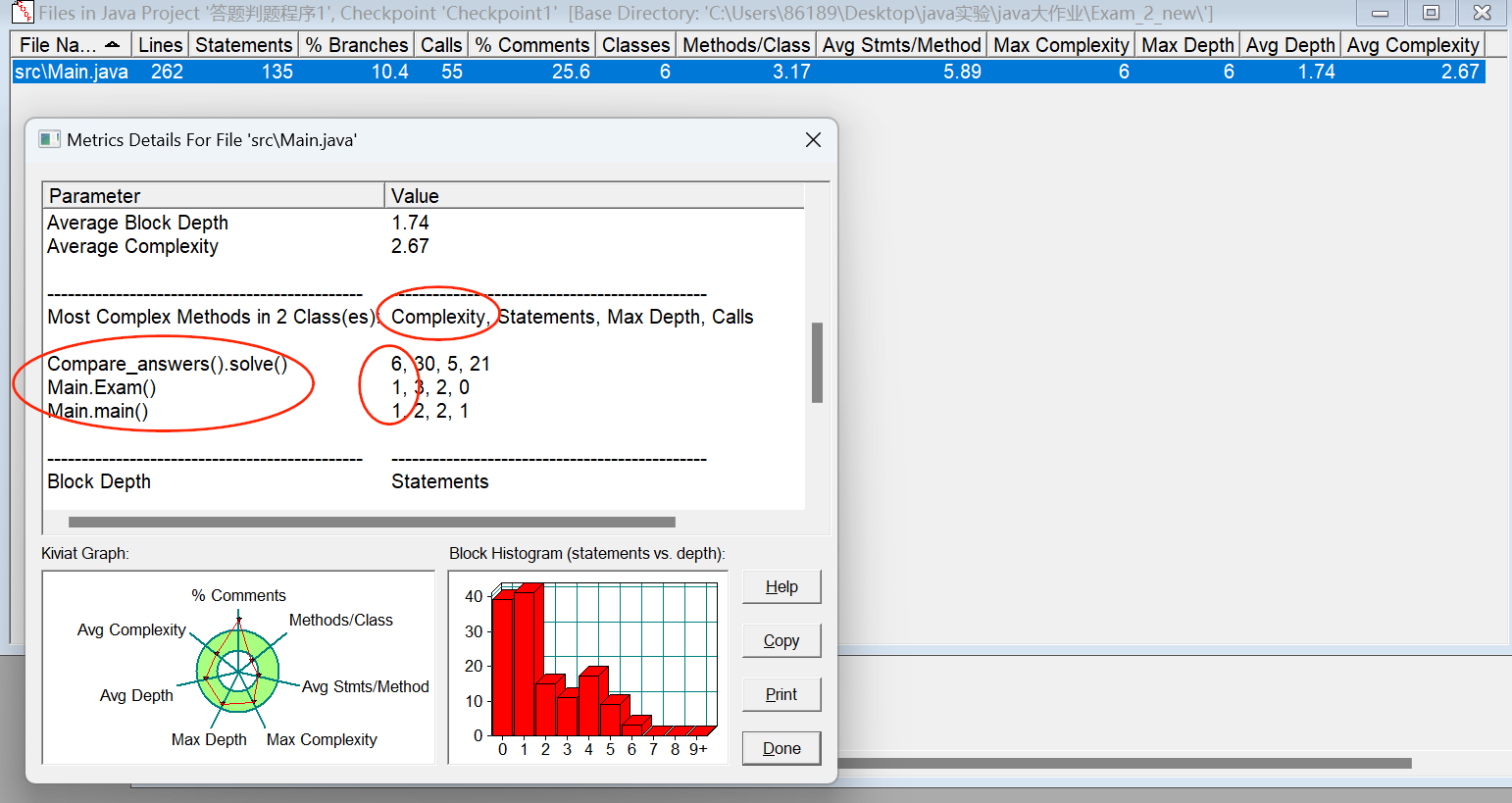
- 这个大作业的solve()入口的圈复杂度相对较高,因为我把很多功能集成在了上面
7-3 答题判题程序-3 (重点分析)
这道题在前面的基础上添加了学生类、判断输入信息是否错误的类、考试管理类以及管理系统类,下面分别介绍:
类的设计:
新增类:
(1)学生类:

(2)判断输入信息是否错误的类:

(3)考试管理类:

(4)管理系统类:

整体类图:
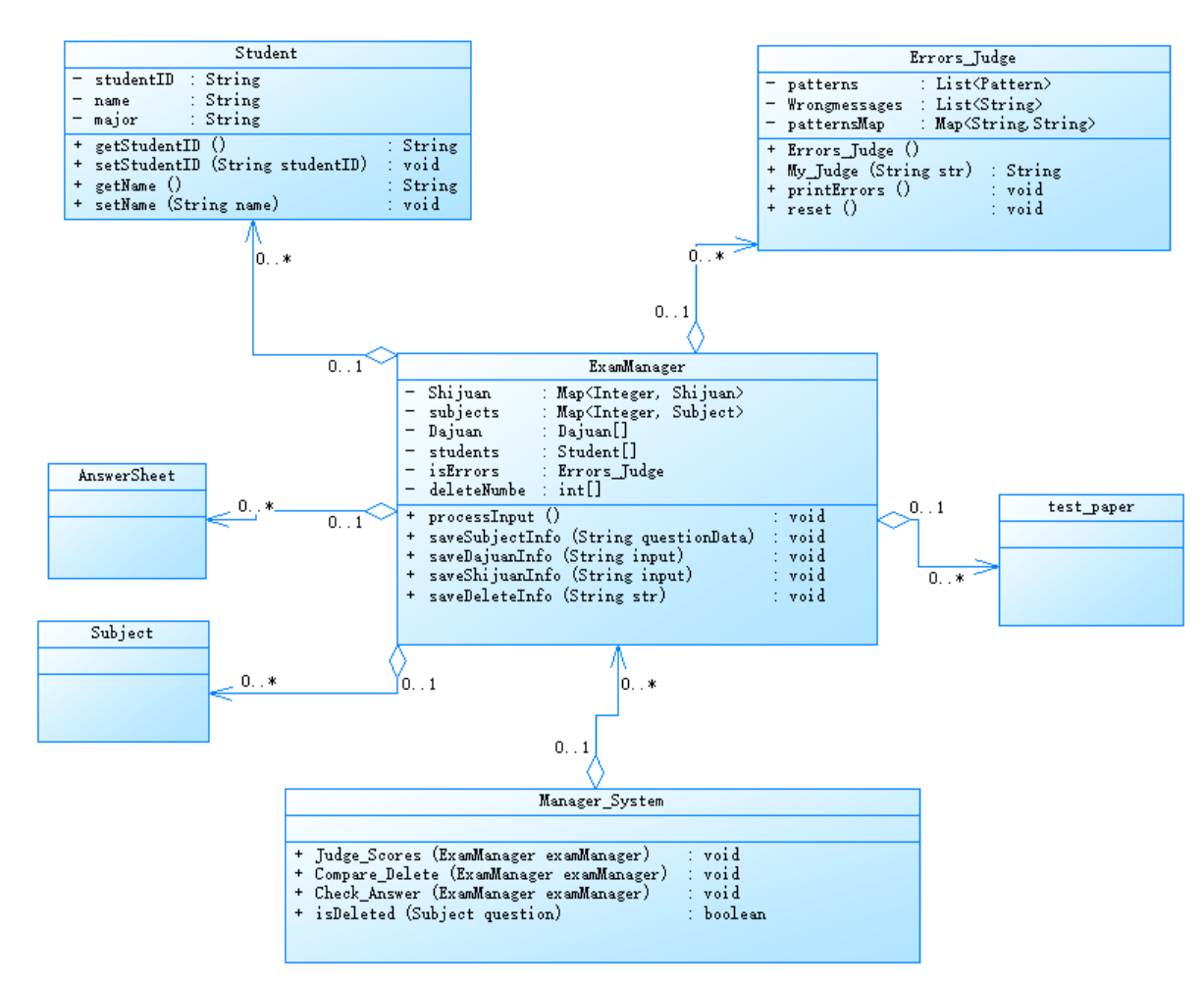
顺序图:
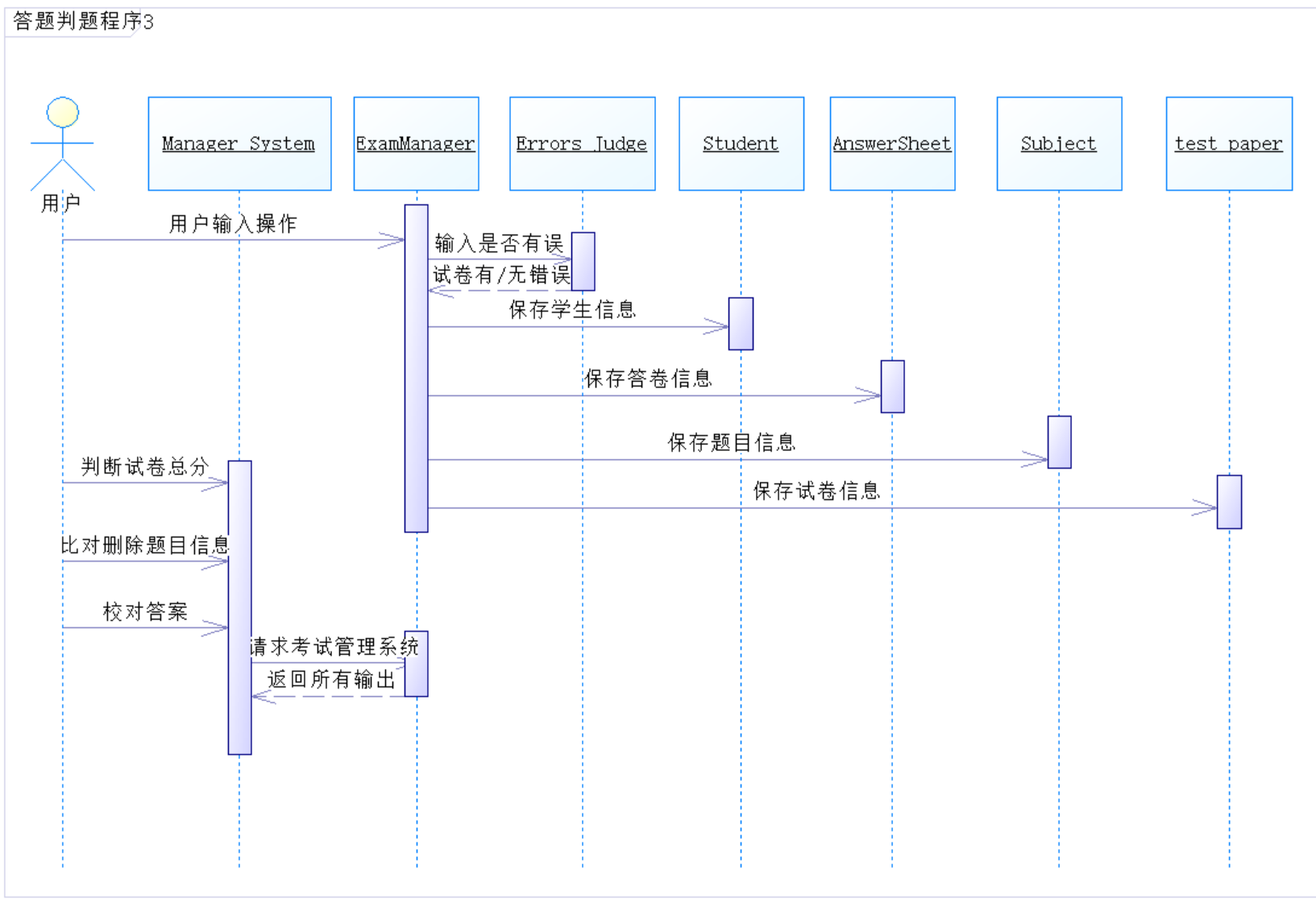
圈复杂度和整体程序结构数据分析:
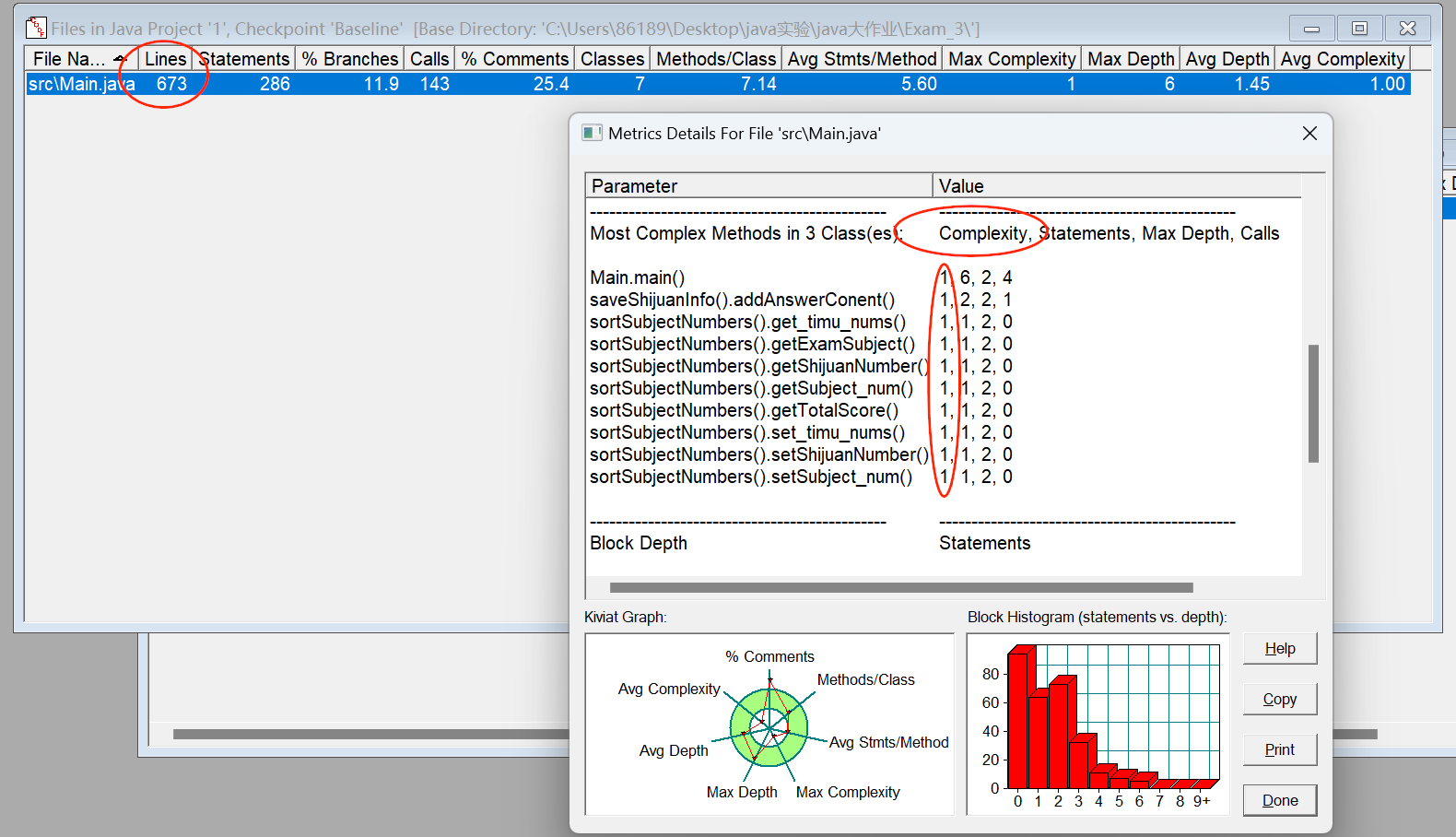
- 虽然第三次大作业我写了六百多行代码,但是我每个方法、函数的圈复杂度都比较低,所以整体程序结构还是相对清晰的
判断类
对于新迭代的判断类,我采用了正则表达式进行模式匹配,对于输入的字符串,如果符合正则表达式,则返回true,否则返回false:
1. 创建一个List<>的有序集合,该集合可以包含重复元素,其中,这个集合里面的所有元素是Pattern类型,即正则表达式类型
- 正则表达式模式匹配列表
private List<Pattern> patterns = new ArrayList<>();
2. 我们还需要一个字符串集合来存储错误信息,这个集合里面的元素是String类型,即字符串类型
- 错误信息列表
private List<String> Wrongmessages = new ArrayList<>();
3. 这里我设置了一个小巧思,为了让我的正则表达式能够顺利地对应输入信息,我创建了一个Map键值对
- 正则表达式模式匹配对应模式,例如:#N是输入题目信息、#D是删除题目信息
private Map<String,String> patternsMap = new HashMap<>();
4. 接下来,也是最核心的一步,创建正则表达式,用一个好的正则表达式可以直接规避用户输入格式错误的问题(下面只列出用户输入信息为创建题目的正则表达式,其他同理):
String pattern1 = "#N:\\s*(\\d+)\\s*#Q:\\s*(.*?)\\s*#A:\\s*(.*?)\\s*"
5. 那我们应该设计一个方法,判断输入是否合法,于是我创建了一个方法: public String My_Judge(String str)
- 其中,str是用户输入的字符串,我们遍历patterns集合
for(int i=0;i<patterns.size();i++),当字符串匹配模式,我们就返回键值对中对应的值,这样在主程序中就能判断输入的这条语句是属于啥了,如果字符串不匹配,那就得存储错误信息在Wrongmessages集合中
6. 在主函数中处理用户输入时,调用上面的方法简洁明了:

反思:
为啥要用正则表达式?
如果不用正则表达式,那么在处理 #N:1 +1= #A:2 这种错误输入时,我们得判断输入的字符串是否包含“#N:”和“#A:”,然后分别判断“#N:”和“#A:”后面是否是数字和数字,这样太麻烦了,容易出错,而正则表达式可以很方便地处理这种输入,而且不容易出错。(不用正则真的会匹配的很不舒服。。。。。。)
学生类
对于新增加的学生类,每一个新对象是学号-姓名,所以对于类的属性和方法设计相对简单
1. 属性的设计,只需要一个学号和姓名即可
- 学生学号
private String studentID; - 学生姓名
private String studentName;
2. 方法没有什么好说的,直接get和set即可
- 获取学生学号、姓名
public String getStudentID();和public String getStudentName(); - 设置学生学号、姓名
public void setStudentID(String studentID);和public void setStudentName(String studentName);
反思:
我整体的设计思想是,不要把每个类的功能放的太大,我喜欢类越简洁越好,具体的操作我们可以放在管理系统类中实现,这样代码看起来会简洁很多,而且也方便我后续的维护和修改,这是基于算法中分治的思想,把一个大的问题分解成多个小问题,这样每个小问题都很好解决,最后再把所有小问题整合起来,就能解决大问题,这也是我后续代码的思路。
考试管理类
对于考试管理类,我设置的方法中,首先是处理用户输入,当用户输入不等于end的时候,任何输入都有可能改变题目、试卷、答卷、学生信息,也有可能输入错误不能存入数据。把用户输入处理完之后,我分别利用保存题目信息方法、保存学生信息方法、保存试卷信息方法、保存答卷信息方法以及删除题目方法
1. 处理用户输入
- 利用
String类中的String.equals()方法,判断用户输入是否等于end,如果等于,则结束循环,否则继续循环
2. 保存题目信息,经典分割法,利用String类中的String.split()方法,把用户输入的字符串分割成字符串数组,然后根据字符串数组中的元素,判断用户输入的是啥,然后存入题目信息
- 分割用户输入的字符串
String[] segments = questionData.split("#"); - 得到题目的答案
if (segments.length > 3 && segments[3].contains(":"))
{
answer = segments[3].substring(segments[3].indexOf(':') + 1).trim();
}
- 存入题目信息
subjects.put(subjectNumber, question);
3. 保存学生信息,经典分割法存入学生信息
- 存入学生对象,将学生对象添加到学生数组中-学生库
students[student_nums++] = student;
4. 保存答卷信息,经典分割法存入答卷信息,这里有个我们班很多人犯的错误,其实 #A:题目之后的都属于答案,所以需要利用正则表达式进行匹配
- 匹配
#A:后的题目和答案的正则表达式:
"#A:\\s*(\\d+)\\s*-\\s*(.*?)\\s*(?=#A:|\\n|$)" - 存入答卷信息
responseSheet.addAnswerConent(questionId, response);
5. 保存试卷信息,经典分割法存入试卷信息
- 存入试卷信息,添加题目与其对应分数到试卷
newPaper.addExamSubject(Integer.parseInt(details[0]), Integer.parseInt(details[1]));
6. 删除题目信息,这个需要好好讲一下,实际上,我的删除功能并没有真正意义上的"删除",我是定义了一个删除数组,当我们识别了用户删除题目的需求时,记录下被删除的题目编号,存入数组中。最后,我们在输出答卷信息时,遍历删除数组,如果题目编号在删除数组中,则不会有该题目信息,这样就能实现删除题目的功能
- 通过分割、转换为整数后,得到题目编号
int number = Integer.parseInt(deleteMessage.trim()); - 将题目编号存入删除数组中
deleteNumber[delete_nums++] = number;
反思:
这样做的方式可以简单清晰处理删除的功能,不然如果真的执行内存中的删除操作,那么结构就复杂多了,删一个题目,试卷要调整,答卷要调整,所以,不如我在处理到对应题目的时候,跳过被删除的题目,这样规避了很多麻烦。当然,这样写也有弊端,因为删除题目没有在内存中删除它的存储空间,如果一开始存入的题目量非常大,且删除的也非常多,那么就会消耗大量的内存空间,降低程序处理的效率,这点需要以后改进
管理系统类
对于我的管理系统类的设计,我将几乎所有的类的功能集合在一起,大部分的实现方法都在这个类中,这个类负责判断试卷总分、比对删除题目信息并处理被删除的题目、校对答案、检查并打印无效试卷等等
1. 判断试卷总分,这个方法比较简单,就是遍历试卷中的题目,将题目对应的分数加起来即可,当分数总分不等于100的时候,输出试卷总分不等于1000
- 遍历试卷中的题目,将题目对应的分数加起来
examManager.getShijuans().forEach((answerSheetNumber, examPaper)-> - 当分数总分不等于100的时候,输出试卷总分不等于1000
if (examPaper.getTotalScore() != 100) //判断试卷总分是否为100
{
System.out.println("alert: full score of test paper" + answerSheetNumber + " is not 100 points");
}
2. 比对删除题目信息,当我们获取到需要删除的题目编号数组时,遍历该数组,如果题目编号在试卷中,则将题目类中被删除的属性设置成true
- 检查题目是否在试卷中
if (subjects.containsKey(deleteNum)) - 如果题目存在,将题目类中被删除的属性设置成
true
question.setDelete(true);
3. 校对答案,这个方法实现起来比较复杂,首先,我们需要遍历所有答题卡,从答题卡角度出发,找对应的卷子,然后将卷子中出的题的答案与答卷中答案相匹配,匹配成功后输出正确答案并获取该道题的小题分,加入总分后继续执行这个步骤,直到遍历完所有答题卡,当然,如果不是正确答案则输出错误且不需要加上小题分
- 如果答题卡答的试卷不存在,需要输出错误信息
System.out.print(examPaper_shijuan != null ? "" : "The test paper number does not exist\n"); - 如果试卷错误引用一道不存在的题号的题目,需要输出错误信息
System.out.print(question != null ? "" : "non-existent question~0\n"); - 如果题目被删除,直接跳过
if (isDeleted(question_timu))
{
handleDeletedSubject(shijuan_timu_number[j], inputsores);
continue;
}
- 比对题目和答卷答案是否正确,正确,输出正确信息并加上小题分,错误,输出错误信息且不用加上小题分
处理正确答案(点击展开)
if(answer.get(j+1).equals(examManager.getSubjects().get(shijuan_timu_number[j]).getStandardAnswer())) //判断答案是否正确
{
TotalPoints += title_score.get(shijuan_timu_number[j]); //计算总分
inputsores.add(title_score.get(shijuan_timu_number[j])); //将得分添加到得分列表中
System.out.println(examManager.getSubjects().get(shijuan_timu_number[j]).getSubjectContent() + "~" +answer.get(j+1) + "~" + true);//答案正确
}
处理错误答案(点击展开)
else
{
inputsores.add(0);
System.out.println(examManager.getSubjects().get(shijuan_timu_number[j]).getSubjectContent() + "~" +answer.get(j+1) + "~" + false);//答案错误
}
4. 最终的输出,学号 + 姓名 + 总分 + 每道题的得分
最终输出(点击展开)
answerID += " " + examManager.getStudents()[i].getName() + ": ";
System.out.print(answerID); //输出学生学号
System.out.println(scoresBuilder.toString().trim() + "~" + TotalPoints); //输出总分
反思:
上文我曾提过分治的思想,分而治之,当我的类已经分配好各个职责了以后,我就可以设计一个管理系统类来统一处理,这是分治法中"合并"的步骤,这样设计类的好处是,当我的类职责分配好以后,我只需要修改这个类,而不需要修改其他类,这样就可以降低修改类的风险,提高代码的可维护性。
三、踩坑分析
1. 正则表达式
-
第三次大作业中,一开始对于用户输入的处理没有用正则表达式,直接用分割在那暴力拆解,拆着拆着发现,一个测试点就是不同的可能,这不就意味着我得写一大堆
if-else语句?后来上课听老师讲这次的大作业得用正则表达式我才在网上学习了之后利用了这种方法。正则表达式是处理字符串的利器,但是正则表达式也是一把双刃剑,如果正则表达式写的不好,那么就会导致程序出错,我一上手写的正则表达式一堆语法错误,后面将自己的正则表达式放在菜鸟教程中调试才得到正确的匹配模式,所以,正则表达式需要反复调试,反复修改,才能写出好的正则表达式。 -
这是当时用
if-else写的分割法一直做不出来后面几个测试点的情况:
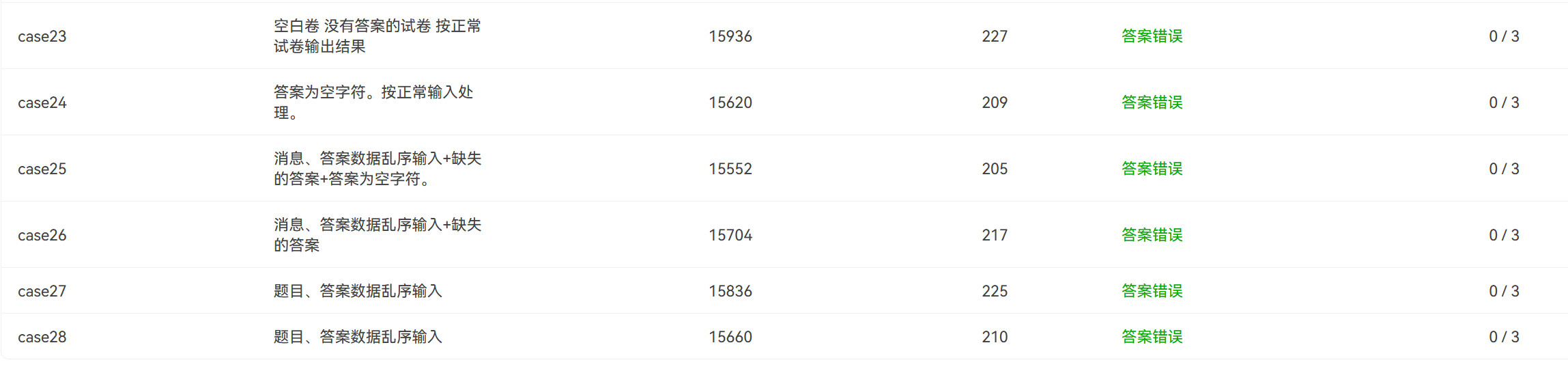
-
这是使用正则表达式挣扎的过程:

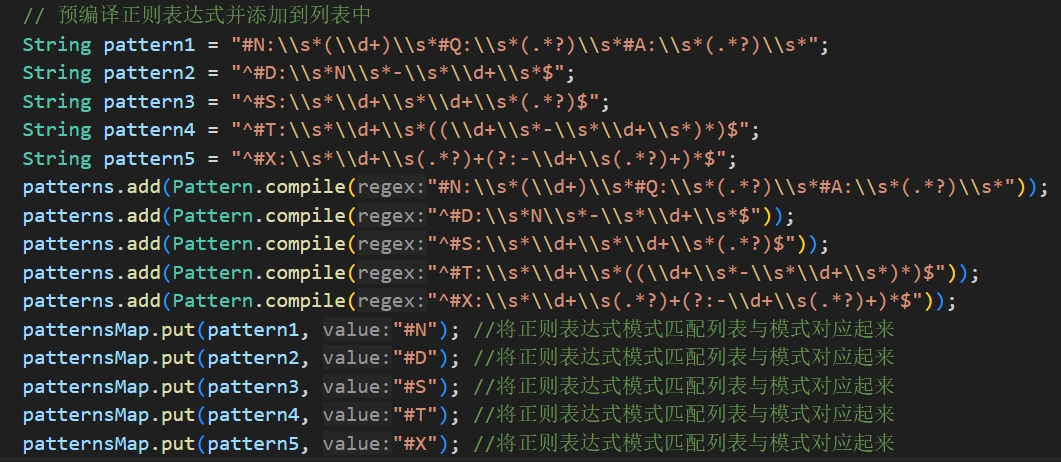
-
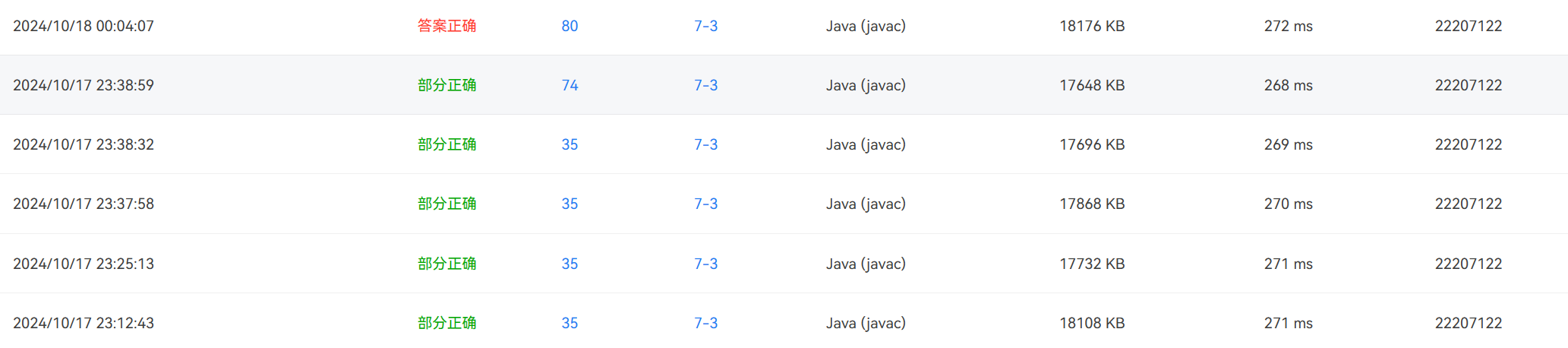
这是最终使用正则表达式匹配成功的情况(迅速过了最后几个测试点):
2. 分割字符串
- 分割字符串是处理字符串的常用方法,但是分割字符串也需要注意,如果分割的字符串中包含特殊字符,那么就需要使用转义字符,否则分割的结果可能不是我们想要的,比如说我想以
\来分割字符串,那么我需要使用\\来分割字符串,否则分割的结果是会出错的。 - 在第二次大作业的时候,我在以空格来分割字符串中,出现了问题,一开始直接写的是
String[] parts = str.split("\s");,但是这样写是错误的,因为\s是正则表达式中的特殊字符,所以需要使用转义字符,即\\s,所以正确的写法是String[] parts = str.split("\\s");。错误的写法导致了我很多测试点出现了问题: - 当输入第八组测试样例时:

- 得出来的结果是非零返回:
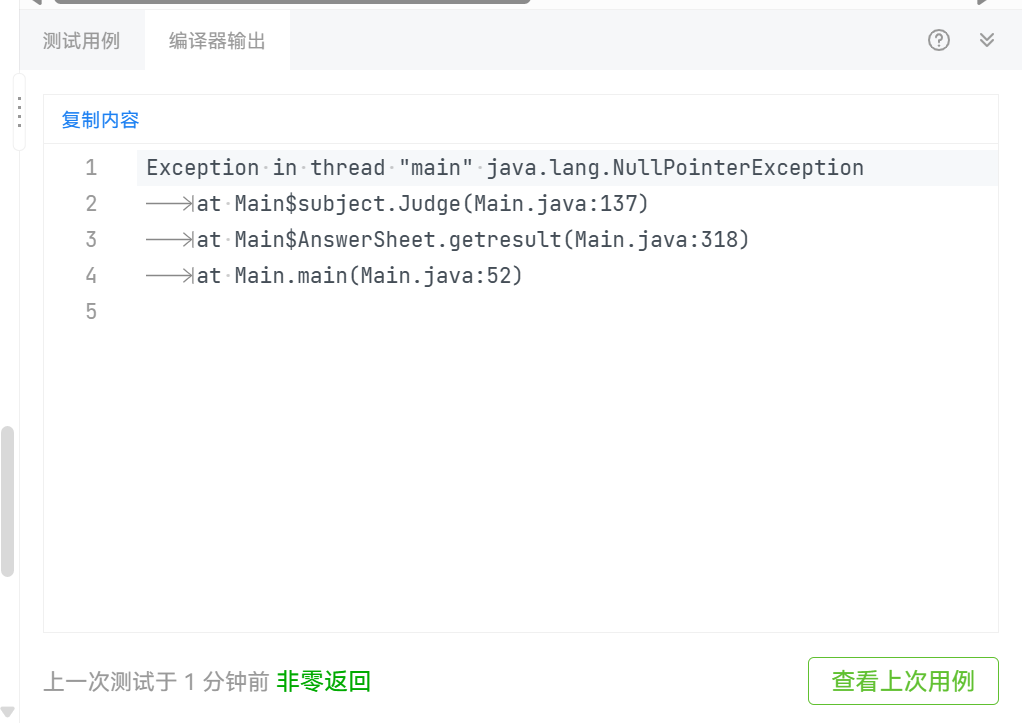

- 修改正确后,测试点通过:

3. 第三次大作业的小瑕疵
- 第三次大作业中,题目要求中有"如果答案输出时,一道题目同时出现答案不存在、引用错误题号、题目被删除,只提示一种信息,答案不存在的优先级最高",我的程序设计中没有考虑到这一点,导致在同班同学给的样例中我是过不了的:
- 精彩瞬间:

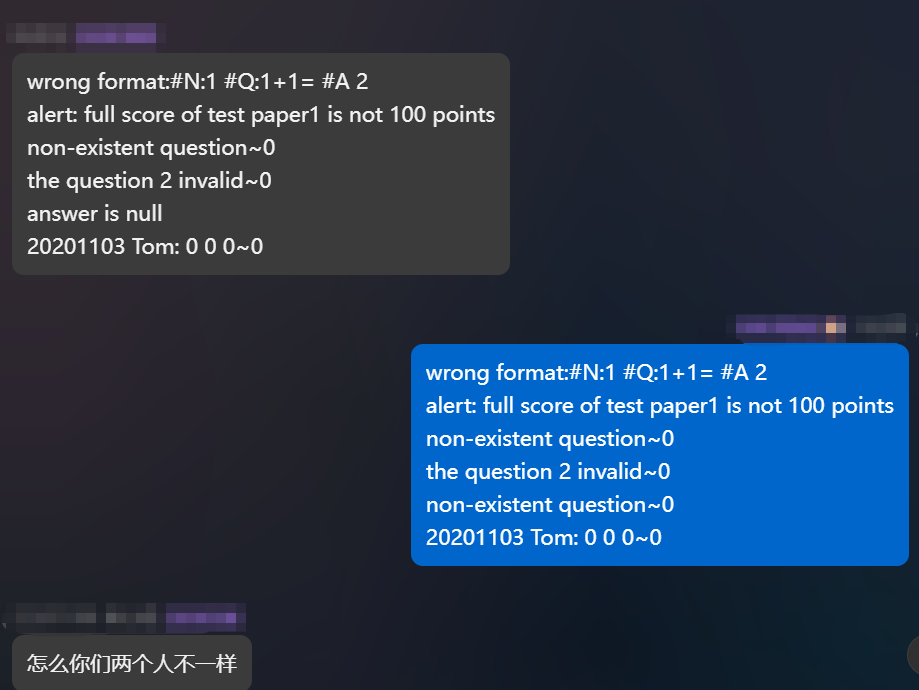
- 实际上,上面那个答案才是正确的,而我自己发的是错误的,因为我忽略了优先级的问题,把这个优先级的问题修改过后,我的程序又通过了很多测试点
四、改进建议
- 在第一次大作业中,我的类的设计不够好,类与类之间关联性和耦合性太强,这样就会导致修改一个类的时候,其他类也需要修改,使得代码的可维护性降低,这直接导致了我的第二次大作业写题的时候不断进行大改,国庆节的时候被自己的代码硬控了3天,后来,狠下决心重新再写,重新写之后我的类就相对清晰很多了,也方便了我第三次大作业的迭代。所以,在以后的设计中,我需要将类与类之间的耦合性降低,提高代码的可维护性。
- 在第三次大作业中,我的代码中有很多冗余,比如在判断答案是否存在的时候,我使用了三个
if-else语句,但是实际上,这三个if-else语句可以合并成一个,这样就可以减少代码的冗余,提高代码的可读性。此外,如果if-else的这中结构是用于用户输入的字符串进行匹配的话,可以使用正则表达式进行模式匹配。所以,在以后的设计中,我需要将代码中的冗余部分进行优化并多用正则表达式,提高代码的可读性。 - 整体的代码风格需要改进,比如在三次大作业中,我的代码中有很多注释,但是注释的格式不统一,有的注释是中文,有的注释是英文,有的注释是中文和英文混合,这样就会导致代码的可读性降低,所以,在以后的设计中,我需要将代码的注释格式统一,提高代码的可读性。
五、总结
- 通过这次大作业,我学到了很多,比如如何使用正则表达式,如何分割字符串,如何优化代码,如何提高代码的可读性等等,这让我获得了宝贵的学习和成长。这些技能的积累,无疑为我日后的编程之路打下了坚实的基础。但是,我还有很多不足,比如在三次大作业中,我的类的结构设计的不理想,写代码的时候还是有按照过程方式的思维去写代码,想到什么写什么,而且设计一个类并没有先画类图和顺序图就直接上手了,这样子的做法非常不可取,此外,我的代码中有很多冗余,代码风格也需要改进。这只是前三次大作业,实际上,这三次大作业的难度并不是很高,只是考察了类的封装和类的职责分工的思想,以后的大作业会涉及到类的继承和多态,如果我的做题方式不是先设计好类的整体结构的话,今后的迭代会越来越困难。
- 当然通过这几次大作业我也收获了很多意外的学习技巧和方法,例如,对于正则表达式的验证,我可以登录菜鸟教程中进行实时的字符串模式匹配。还有,因为大作业中有许多的测试点,有些测试点我并不知道我错在了哪里,这时候,我会在班级的QQ群中询问我们班的大佬,他们在调试的过程中自己想到了很多的测试样例,通过这些测试样例,我就可以找到自己的错误,从而修改自己的代码。第三次大作业的时候,我一直被最后几个点卡着,非常的不舒服,多亏了同学造出来的样例我才知道是自己的优先级没有设置。还有,在写代码的过程中,我有时候会卡壳,这时候,我会去询问我们班的大佬,他们有时候会给我提供一些思路,从而帮助我解决问题。这些方法都是我在这次大作业中学到的,我会将这些方法应用到今后的学习中,提高我的编程能力。
- 最后,我还是希望我自己能够多多看书,看视频学习,多练练自己的代码能力,为以后的大作业迭代打下基础。
- 对于老师的教学方法和改进,我非常感谢老师在课上提的建议,例如:写大作业前一定要先画类图和顺序图,这样写代码才不会乱。