平衡堆栈
理解并观测函数调用母函数做什么,子函数做什么
cdecl调用约定
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int __cdecl method(int x, int y)
{
return x + y;
}
int main()
{
__asm mov eax, eax; // 此处设置断点
method(1, 2);
return 0;
}
可以看出__cdecl就是C语言默认的调用约定。
二、_stdcall调用约定
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int __stdcall method(int x, int y)
{
return x + y;
}
int main()
{
__asm mov eax, eax; // 此处设置断点
method(1, 2);
return 0;
}
和__cdecl一样都是从右往左入栈参数,不过该调用约定使用的平栈方式是内平栈,从下图可以看到,这里已经看不到堆栈的处理了。
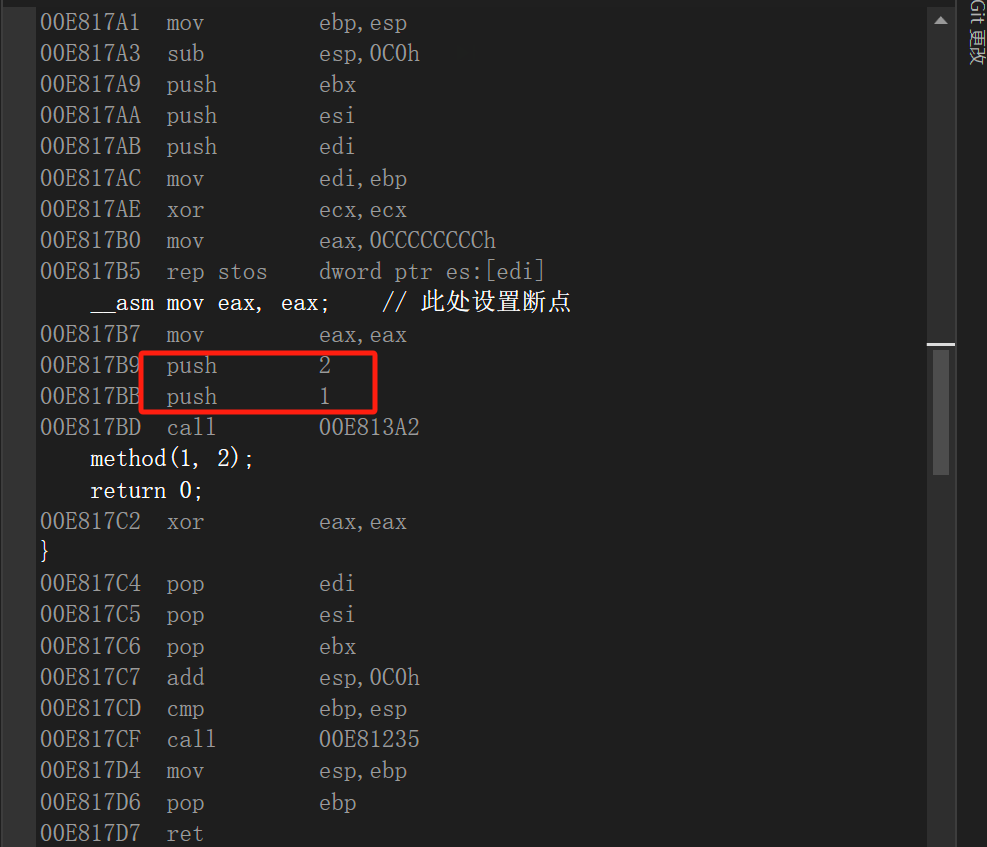
F11不断执行,直到进入call指令调用的method函数中:
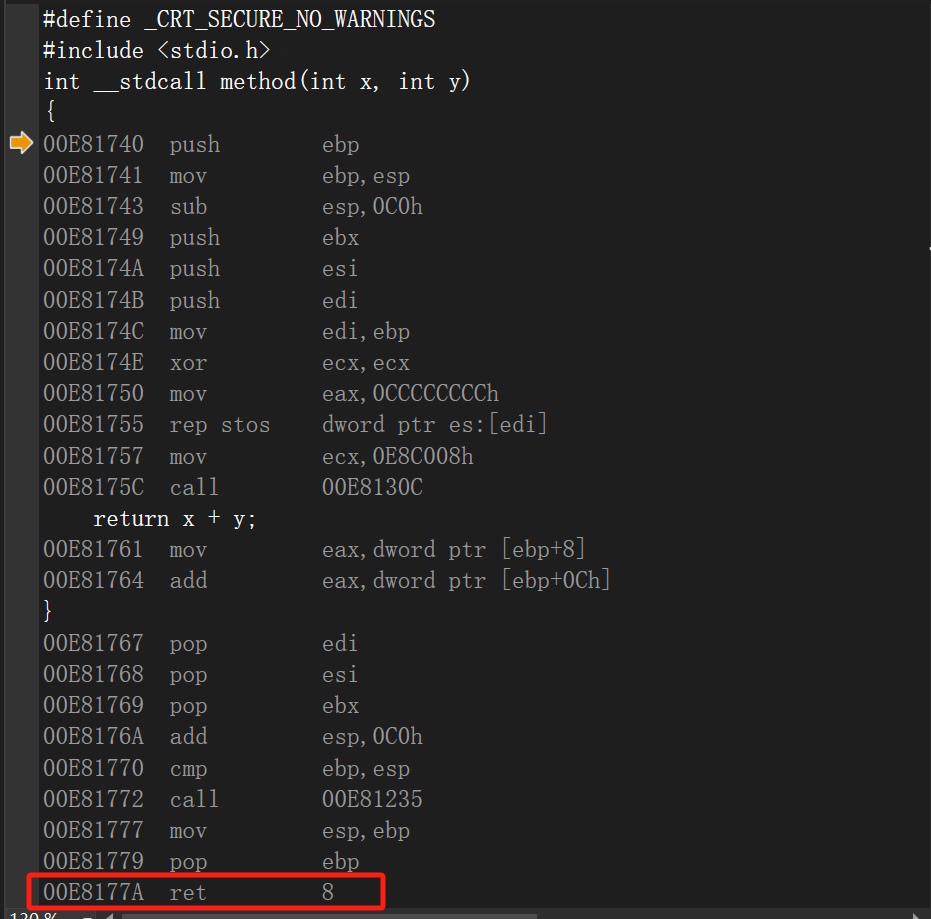
平栈操作跑到函数内部了,__cdecl约定是调用者(main)函数进行平栈,而__stdcall约定是函数内部自身进行平栈。
三、_fastcall调用约定
这是一个比较特殊的调用约定,当函数参数为两个或者以下时,该约定的效率远远大于上面两种,当然随着参数越来越多,该约定与上面两种约定的差距逐渐缩小。
证明如下:
首先,我们使用__fastcall调用约定并传入两个参数。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int __fastcall method(int x, int y)
{
return x + y;
}
int main()
{
__asm mov eax, eax; // 此处设置断点
method(1, 2);
return 0;
}
可以看出函数内部和外部都没有清理堆栈的操作。这也就是__fastcall效率高的原因。因为寄存器就是属于CPU的,然后堆栈是内存,使用CPU进行操作的效率肯定会大于使用内存,所以我们使用寄存器的效率肯定比push传参效率高很多。
那么为什么没有平栈操作呢?因为我们没有使用堆栈,我们只是用了寄存器,并没有使用堆栈操作。但是当我们传入更多的参数的时候就需要用到堆栈了,因为__fastcall他只给我们提供了两个寄存器ECX/EDX可以用来传参。
使用四个参数:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int __fastcall method(int x, int y,int t,int u)
{
return x + y + t +u;
}
int main()
{
__asm mov eax, eax; // 此处设置断点
method(1, 2, 3, 4);
return 0;
}
F11进入函数内部查看:
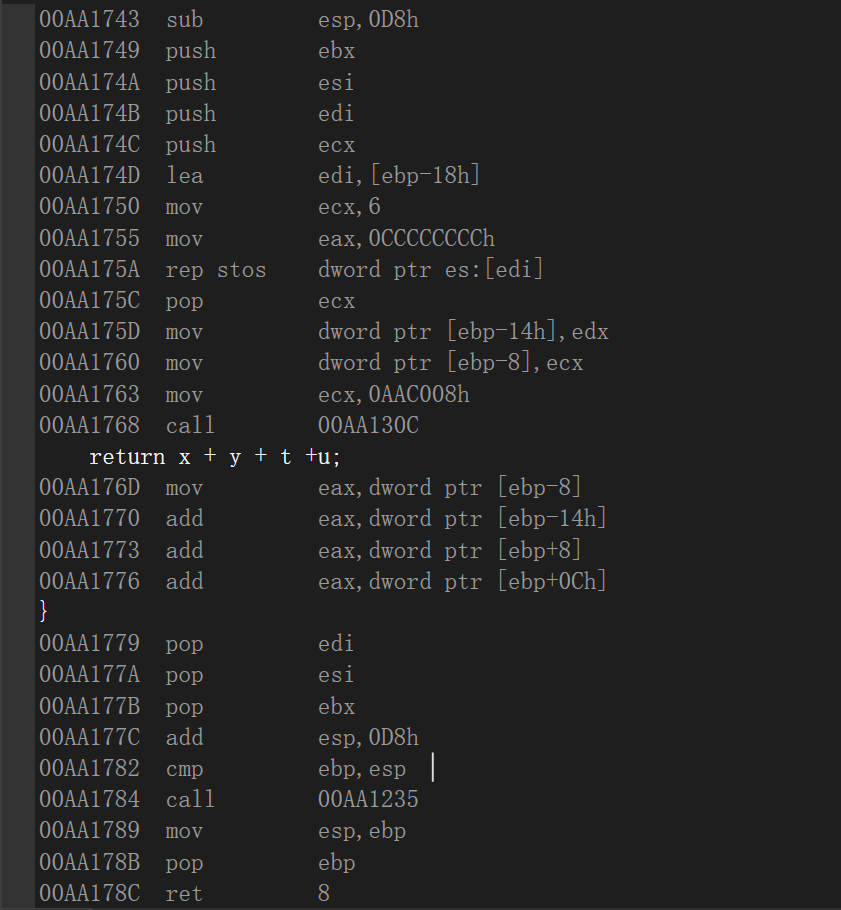
通过四个参数的传递,证明了:
函数参数除了前两个参数使用寄存器、其他的依旧使用堆栈从右往左传参,并且是自身清理堆栈,不是调用者清理。
当参数越来越多的时候,__fastcall与其他调用约定的差距越来越小的原因是使用寄存器(CPU)的效率远远大于使用堆栈(内存),然而__fastcall约定也只能使用两个寄存器,当函数参数只有两个时,__fastcall可以完全使用寄存器进行函数传参,所以这个时候他和__cdecl和__stdcall的差距最大。随着参数越来越多,__fastcall依旧只能使用两个寄存器,这样一来参数越多,__fastcall使用内存的占比就越大,所以性能差距也就越来越小。
2.平衡堆栈的3种模式,谁释放参数空间
堆栈平衡是指在函数调用过程中,保证堆栈的栈顶指针(ESP)在函数返回前恢复到调用前的状态,以避免堆栈的混乱或溢出1。堆栈平衡的三种模式分别是:
外平栈:在函数外部使用 add esp, xx 指令来清理堆栈中的参数,其中 xx 是参数所占用的字节数。这种模式的优点是可以适应不同的调用约定,缺点是需要额外的指令来调整堆栈。
; 外平栈模式
push param3 ; 将参数3推入堆栈
push param2 ; 将参数2推入堆栈
push param1 ; 将参数1推入堆栈
call myFunction ; 调用函数
add esp, 12 ; 清理堆栈
myFunction:
push ebp ; 保存旧的基址
mov ebp, esp ; 设置新的基址
; 在函数内部使用 [ebp+xx] 来访问参数
; 在函数内部执行一些操作
pop ebp ; 恢复旧的基址
ret ; 返回
内平栈:在函数内部使用 ret xx 指令来返回并清理堆栈中的参数,其中 xx 是参数所占用的字节数。这种模式的优点是可以节省一条指令,缺点是需要函数的定义和调用都遵循相同的约定。
; 内平栈模式
push param3 ; 将参数3推入堆栈
push param2 ; 将参数2推入堆栈
push param1 ; 将参数1推入堆栈
call myFunction ; 调用函数
myFunction:
push ebp ; 保存旧的基址
mov ebp, esp ; 设置新的基址
; 在函数内部使用 [ebp+xx] 来访问参数
; 在函数内部执行一些操作
pop ebp ; 恢复旧的基址
ret 12 ; 返回并清理堆栈
平衡堆栈:在函数内部使用 push 和 pop 指令来平衡堆栈的变化,使得函数返回前堆栈的状态和调用前一致。这种模式的优点是可以保证堆栈的平衡,缺点是需要更多的指令来操作堆栈。
; 平衡堆栈模式
push param3 ; 将参数3推入堆栈
push param2 ; 将参数2推入堆栈
push param1 ; 将参数1推入堆栈
call myFunction ; 调用函数
myFunction:
push ebp ; 保存旧的基址
mov ebp, esp ; 设置新的基址
; 在函数内部使用 [ebp+xx] 来访问参数
; 在函数内部执行一些操作
; 在函数内部使用 pop 指令来平衡堆栈
pop ebp ; 恢复旧的基址
ret ; 返回
根据不同的模式,释放参数空间的责任也不同。在外平栈模式中,调用者负责释放参数空间;在内平栈模式中,被调用者负责释放参数空间;在平衡堆栈模式中,调用者和被调用者都不需要释放参数空间,因为堆栈已经平衡
3.debug模式下ebp寻址,release模式下esp寻址(工具Ida)
ebp寻址与esp寻址
源码:
#define _CRT_SECURE_NO_WARNINGS
// Function.cpp : Defines the entry point for the console application.
//
#include<stdio.h>
typedef void (*p)();
// ebp 与 esp访问
void InNumber()
{
// 局部变量定义
int nInt = 1;
scanf("%d", &nInt);
char cChar = 2;
scanf("%c", &cChar);
printf("%d %c\r\n", nInt, cChar);
}
// 两数交换
void AddNumber(int nOne)
{
nOne += 1;
printf("%d \r\n", nOne);
}
int GetAddr(int nNumber)
{
int nAddr = *(int*)(&nNumber - 1);
return nAddr;
}
struct tagTEST
{
int m_nOne;
int m_nTwo;
};
tagTEST RetStruct()
{
tagTEST testRet;
testRet.m_nOne = 1;
testRet.m_nTwo = 2;
return testRet;
}
void AsmStack()
{
__asm
{
push eax
pop eax
}
int nVar = 0;
scanf("%d", &nVar);
printf("AsmStack %\r\n", nVar);
}
void main()
{
AsmStack();
tagTEST test;
test = RetStruct();
int nAddr = GetAddr(1);
int nReload = (nAddr + *(int *)(nAddr - 4)) - (int)GetAddr;
int nNumber = 0;
scanf("%d", &nNumber);
AddNumber(nNumber);
InNumber();
}
main proc near ArgList=byte ptr -0Ch Arglist=byte ptr -5var_4=dword ptr -4argc=dword ptr 8argv=dword ptr echenvp=dword ptr10h push ebp mov ebp,esp sub esp,0ch mov eax, security_cookie xor eax,ebp mov [ebp var_4],eax push eax pop eax lea eax,[ebp ArgList] mov dword ptr [ebp ArgList],e push eax ;Arglist push offset aD ;"%d" call sub401050 push dword ptr [ebp ArgList]ArgList push offset Format"AsmStack %r\n" call sub401626 lea eax,[ebp ArgList] mov dword ptr [ebp ArgList],1 push eax ;Arglist push offset aD ;"%dn call sub401050 lea eax,[ebp Arglist] mov [ebp Arglist],2 push eax ;Arglist push offset ac ;"%c" call sub 401050 movsx eax,[ebp Arglist] push eax push dword ptr [ebp ArgList]ArgList push offset aDC ;"%d%c\r\n" call sub401826 mov ecx,[ebp var_4] add esp,2Ch xor ecx,ebp call sub_4010FE
在使用了esp寻址后,不必在每次进人函数后都调整栈底ebp,这样既减少了ebp的使用又省去了维护ebp的相关指令,因此可以有效提升程序的执行效率。但是,缺少了 ebp 就无法保存进入函数后的栈底指针,也就无法进行栈平衡检测。
在每次访向变量都需要计算,如果在函数执行过程中 esp 发生了改变,再次访问变量就需要重新计算偏移,这真是个令人头疼的问题。为了省去对偏移量的计算,方便分析,IDA在分析过程中事先将函数中的每个变量的偏移值计算出来,得出了一个固定偏移值,使用标号将其记录。IDA是采用负数作为偏移值,将其作为标号,参与变量寻址计算。