数据采集第一次作业
【数据采集】第一次作业
目录
- 作业①:爬取大学排名信息
- 作业②:商城商品比价定向爬虫
- 作业③:爬取网页中的JPEG和JPG文件
作业①:爬取大学排名信息
任务要求:
使用 requests 和 BeautifulSoup 库方法定向爬取给定网址 http://www.shanghairanking.cn/rankings/bcur/2020 的数据,并屏幕打印爬取的大学排名信息。
输出信息格式:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | ... | ... | ... | ... |
一、实验
1、思路
1)导入必要的库:
urllib.request用于发送HTTP请求。
BeautifulSoup用于解析HTML内容。
re用于正则表达式匹配。
2)定义school_name_get函数:
用于接收一个BeautifulSoup对象column_name作为参数,该对象代表HTML中的一个单元格(标签)。
使用正则表达式tag匹配中文字符范围,提取学校名称。
school_name_raw获取单元格中的文本内容。
re.search搜索匹配的中文字符序列,并返回第一个匹配项。返回匹配到的学校名称。
3)设置URL并获取网页内容:
使用urllib.request.urlopen(url)发送请求并读取响应内容。
4)解析网页内容:
使用BeautifulSoup(html, features='lxml')解析获取到的HTML内容。
5)打印表头:
打印出表头,包括“排名”、“学校名称”、“省市”、“学校类型”和“总分”。
2、重要代码部分
点击查看代码
def school_name_get(column_name):
tag = r'[\u4e00-\u9fff]+'
school_name_raw = column_name.get_text(strip=True)
school_name = re.search(tag, school_name_raw).group(0)
return school_name
1)school_name_get函数从给定的HTML单元格(column_name)中提取学校名称。
2)使用正则表达式匹配中文字符(Unicode范围\u4e00-\u9fff)来提取学校名称。
3、运行结果
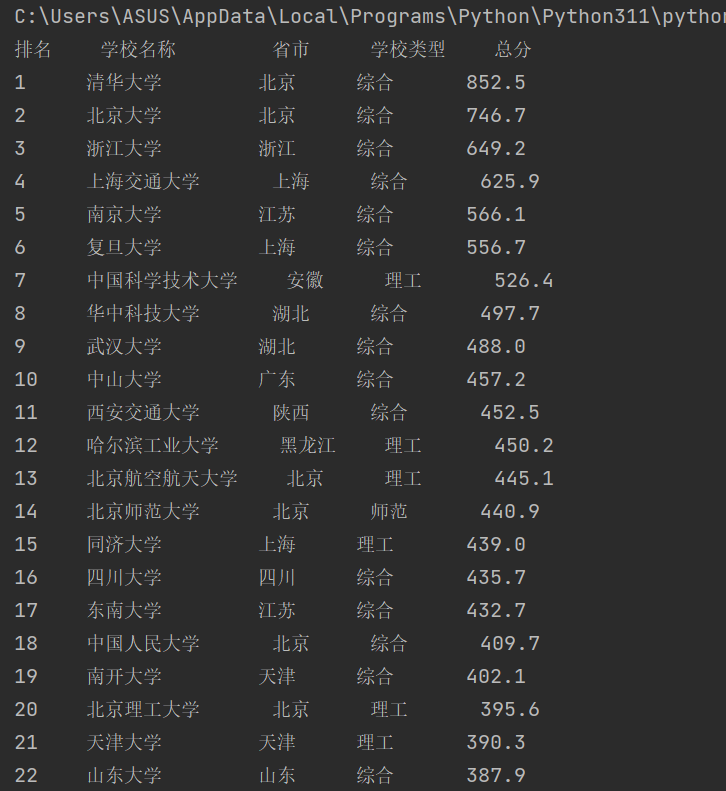
二、心得
1.HTML结构:
通过观察HTML结构,可以确定排名、学校名称、省份/城市等信息分别位于哪个标签内,准确地定位和提取所需的数据。
2.正则表达式:
在本例中,正则表达式用于匹配中文字符,但如果网页结构发生变化,可能需要调整正则表达式,同时还遇到了输出不对对齐的问题。
作业②:商城商品比价定向爬虫
任务要求:
使用 requests 和 re 库方法设计某个商城(自选)商品比价定向爬虫,爬取该商城以关键词“书包”搜索页面的数据,包括商品名称和价格。
输出信息格式:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | ... | ... |
一、实验
1、思路
1)导入必要的库:
re用于正则表达式匹配。
urllib.parse用于解析URL。
urllib.request用于发送HTTP请求。
chardet用于检测编码。
2)定义getHTMLText函数:
用于发送HTTP请求获取网页内容。
设置了用户代理(User-Agent)以模拟浏览器访问。
使用urllib.request.urlopen发送请求并读取响应。
使用chardet.detect检测响应内容的编码。
解码响应内容并返回。
3)定义parsePage函数:
用于解析HTML内容,提取商品价格和名称。
使用正则表达式匹配价格和名称。
将匹配到的价格和名称添加到列表中。
4)定义printGoodslist函数:
用于格式化打印商品信息。
使用格式化字符串tplt定义输出格式。
5)定义main函数:
作为程序的入口点。
从用户输入获取要爬取的商品和页面序列。
调用getHTMLText获取网页内容。
如果成功获取到内容,则调用parsePage解析数据,然后调用printGoodslist打印结果。
如果获取内容失败,则打印错误信息。
2、重要代码部分
点击查看代码
def getHTMLText(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
try:
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
raw_data = response.read()
encoding = chardet.detect(raw_data)['encoding']
data = raw_data.decode(encoding)
return data
except Exception as err:
print(f"请求错误:{err}")
return ""
功能:
获取指定URL的HTML文本内容。
headers:自定义请求头,模拟浏览器发送请求,避免被网站禁止。
urllib.request.Request:构建HTTP请求对象,并将自定义的请求头信息附加到请求中。
urllib.request.urlopen:发送请求并获取响应。
chardet.detect:使用chardet库检测返回的网页内容的编码格式,确保正确解码HTML内容。
decode(encoding):将二进制数据解码为字符串。
点击查看代码
def parsePage(info, data):
print("解析数据中...")
# 提取价格
prices = re.findall(r'¥([\d,]+\.\d{2})', data)
# 提取商品名称
names = re.findall(r'alt=\'(.*?)\'', data)
print(prices)
print(names)
for i in range(min(len(names), len(prices))):
price = prices[i].strip()
name = names[i].strip()
info.append([i + 1, price, name])
return info
功能:解析HTML内容,提取商品的价格和名称。
re.findall(r'¥([\d,]+.\d{2})', data):使用正则表达式提取所有商品价格。¥表示人民币符号,匹配价格形式为小数点后两位数字。
re.findall(r'alt='(.*?)'', data):使用正则表达式提取商品名称,匹配图片的alt属性中的内容。
使用strip()去除字符串前后的空格,确保商品信息清晰。
将序号、价格、商品名称添加到info列表中。
3、运行结果
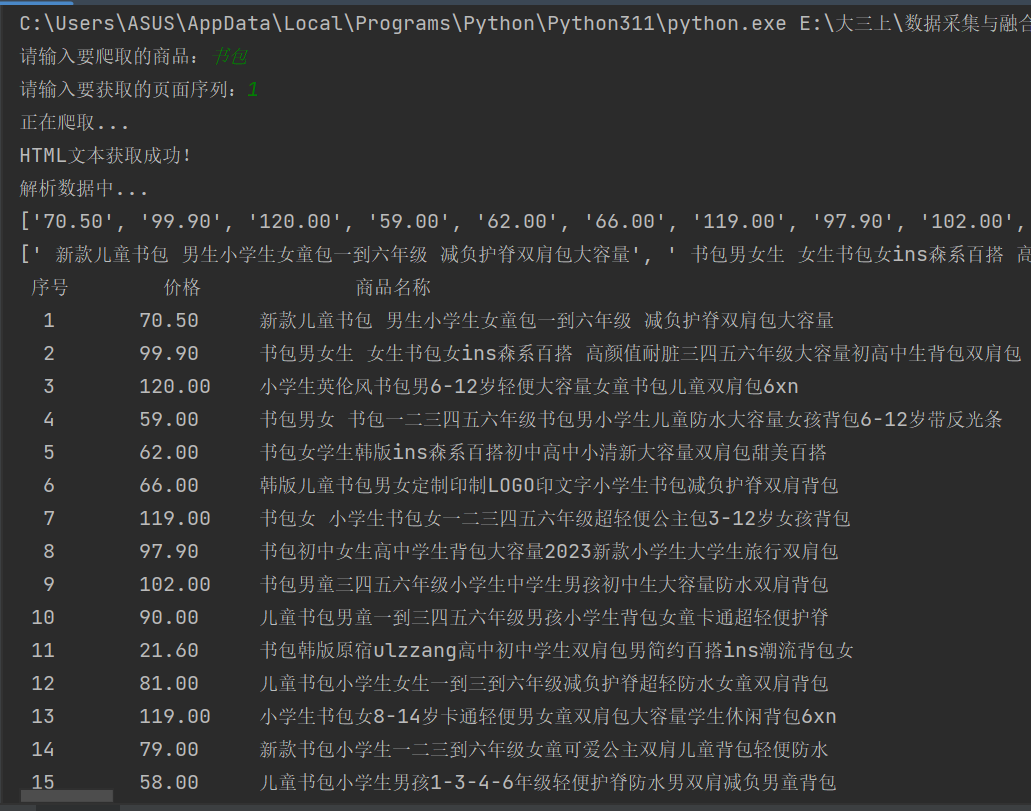
二、心得
1.编码:
由于网页可能使用不同的编码格式,如果处理不当,可能会导致乱码或解析错误。chardet库帮助我们自动检测编码,确保内容正确解码。
2.正则表达式的:
正则表达式是处理文本数据的强大工具,尤其在提取特定格式的信息时非常有效。在这段代码中,正则表达式被用来匹配价格和商品名称。然而,正则表达式需要精确设计,以匹配目标数据的格式,否则可能会导致匹配失败或错误匹配。
作业③:爬取网页中的JPEG和JPG文件
任务要求:
爬取一个给定网页 https://xcb.fzu.edu.cn/info/1071/4481.htm 或者自选网页的所有JPEG和JPG格式文件,并将其保存在一个文件夹中。
一、实验
1、思路
1)导入必要的库:
os用于文件和目录操作。
requests用于发送HTTP请求。
BeautifulSoup用于解析HTML内容。
urljoin用于生成完整的URL。
2)发送HTTP请求获取网页内容:
使用requests.get(url)发送请求获取网页内容。
response.raise_for_status()会在请求失败时抛出异常。
3)解析网页内容:
使用BeautifulSoup(response.text, 'html.parser')解析获取到的HTML文本。
4)创建文件夹保存图片:
如果不存在名为downloaded_images的文件夹,则创建它。
5)查找并下载图片:
遍历网页中所有的标签。
获取每个图片的src属性值,并确保它是完整的URL。
检查图片URL是否以.jpg或.jpeg结尾。
如果是,使用requests.get(img_url).content获取图片内容。
获取图片的文件名,并保存到downloaded_images文件夹中。
6)异常处理:
如果在下载过程中发生错误(如网络问题、文件写入错误等),捕获异常并打印错误信息。
7)完成提示:
所有图片下载完成后,打印提示信息。
2、重要代码部分
点击查看代码
# 目标网页URL
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 发送HTTP请求获取网页内容
response = requests.get(url)
response.raise_for_status() # 如果请求失败,抛出HTTPError异常
解释:
url: 目标网页的URL地址。
requests.get(url): 发送HTTP GET请求,从指定URL获取网页的内容。
raise_for_status(): 检查响应状态码。如果请求失败(如404或500错误),抛出异常并终止程序执行。
点击查看代码
# 查找所有图片标签
for img in soup.find_all('img'):
# 获取图片的URL
img_url = img.get('src')
# 确保图片URL是完整的
img_url = urljoin(url, img_url)
解释:
soup.find_all('img'): 查找HTML文档中所有的 标签。
img.get('src'): 获取每个图片标签中的 src 属性(即图片的URL)。
urljoin(url, img_url): 将相对路径的图片URL转换为完整的URL,确保下载图片时不会因为路径不完整而失败。
3、运行结果
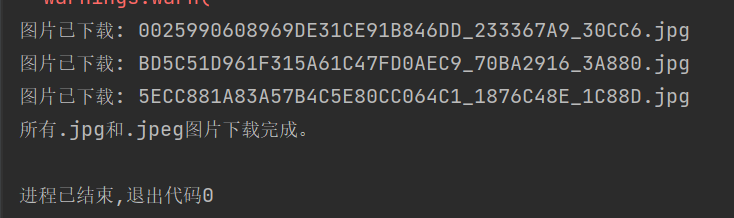

二、心得
1.理解网络请求和响应:
使用requests库提供了一个简单易用的接口来处理如何发送请求、处理响应状态码和异常是编写稳定爬虫。
2.解析HTML和提取数据:
使用BeautifulSoup库被用来查找所有的标签并获取图片的URL。