PyTorchStepByStep - Chapter 2: Rethinking the Training Loop





def make_train_step_fn(model, loss_fn, optimizer): def perform_train_step_fn(x, y): # Set model to TRAIN mode model.train() # Step 1 - Compute model's predictions - forward pass yhat = model(x) # Step 2 - Compute the loss loss = loss_fn(yhat, y) # Step 3 - Compute the gradients for both parameters "b" and "w" loss.backward() # Step 4 - Update parameters using gradients and the learning rate optimizer.step() optimizer.zero_grad() # Return the loss return loss.item() return perform_train_step_fn
%%writefile model_configuration/v1.py device = 'cuda' if torch.cuda.is_available() else 'cpu' # Set learning rate lr = 0.1 torch.manual_seed(42) model = nn.Sequential(nn.Linear(1, 1)).to(device) # Define an SGD optimizer to update the parameters (now retrieved directly from the model) optimizer = torch.optim.SGD(model.parameters(), lr=lr) # Define an MSE loss function loss_fn = nn.MSELoss(reduction='mean') # Create the train_step function for model, loss function and optimizer train_step_fn = make_train_step_fn(model, loss_fn, optimizer)

%%writefile model_training/v1.py n_epochs = 1000 losses = [] for epoch in range(n_epochs): # Perform one train step and return the corresponding loss loss = train_step_fn(x_train_tensor.reshape(-1, 1), y_train_tensor.reshape(-1, 1)) losses.append(loss)
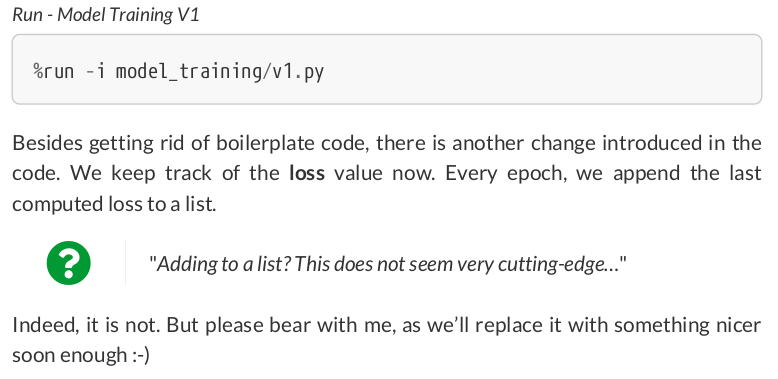



class CustomDataset(Dataset): def __init__(self, x_tensor, y_tensor): self.x = x_tensor self.y = y_tensor def __getitem__(self, index): return (self.x[index], self.y[index]) def __len__(self): return len(self.x) # Wait, is this a CPU tensor now? Why? Where is .to(device)? x_train_tensor = torch.from_numpy(x_train).float() y_train_tensor = torch.from_numpy(y_train).float() train_data = CustomDataset(x_train_tensor, y_train_tensor) print(train_data[0]) # (tensor(0.8446), tensor(2.8032))

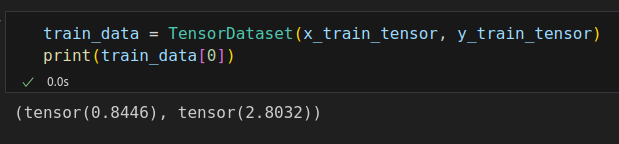



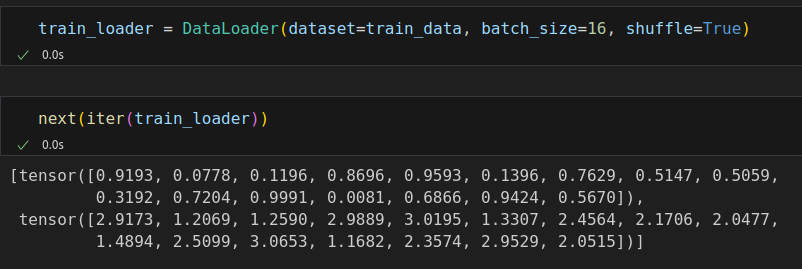


%%writefile data_preparation/v1.py x_train_tensor = torch.from_numpy(x_train).float().reshape(-1, 1) y_train_tensor = torch.from_numpy(y_train).float().reshape(-1, 1) # Build Dataset train_data = TensorDataset(x_train_tensor, y_train_tensor) # Build DataLoader train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)

%%writefile model_training/v2.py n_epochs = 1000 losses = [] for epoch in range(n_epochs): mini_batch_losses = [] for x_batch, y_batch in train_loader: # the dataset "lives" in the CPU, so do our mini-batches therefore, # we need to send those mini-batches to the device where the model "lives" x_batch = x_batch.to(device) y_batch = y_batch.to(device) # Perform one train step and return the corresponding loss for this mini-batch mini_batch_loss = train_step_fn(x_batch, y_batch) mini_batch_losses.append(mini_batch_loss) # Computes average loss over all mini-batches - that's the epoch loss loss = np.mean(mini_batch_losses) losses.append(loss)



def mini_batch(device, data_loader, step_fn): mini_batch_losses = [] for x_batch, y_batch in data_loader: x_batch = x_batch.to(device) y_batch = y_batch.to(device) mini_batch_loss = step_fn(x_batch, y_batch) mini_batch_losses.append(mini_batch_loss) loss = np.mean(mini_batch_losses) return loss

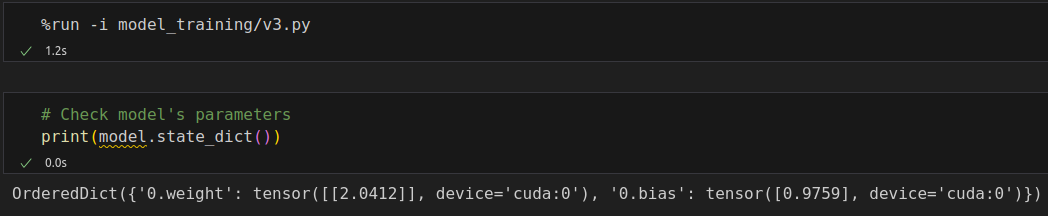
%%writefile model_training/v3.py n_epochs = 200 losses = [] for epoch in range(n_epochs): loss = mini_batch(device, train_loader, train_step_fn) losses.append(loss)




%%writefile data_preparation/v2.py torch.manual_seed(13) # Build tensors from numpy arrays BEFORE split x_tensor = torch.from_numpy(x).float().reshape(-1, 1) y_tensor = torch.from_numpy(y).float().reshape(-1, 1) # Build dataset containing ALL data points dataset = TensorDataset(x_tensor, y_tensor) # Perform split ratio = .8 n_total = len(dataset) n_train = int(n_total * ratio) n_val = n_total - n_train train_data, val_data = random_split(dataset, [n_train, n_val]) # Build a loader for each set train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True) val_loader = DataLoader(dataset=val_data, batch_size=16)

def make_val_step_fn(model, loss_fn): # Build function that performs a step in the validation loop def perform_val_step_fn(x, y): # Set model to EVAL mode model.eval() # Step 1 - Compute model's predictions - forward pass yhat = model(x) # Step 2 - Compute the loss loss = loss_fn(yhat, y) # There is no need to compute Steps 3 and 4, since we don't update parameters during evaluation return loss.item() return perform_val_step_fn

%%writefile model_configuration/v2.py device = 'cuda' if torch.cuda.is_available() else 'cpu' # Sets learning rate - this is "eta" ~ the "n" like Greek letter lr = 0.1 torch.manual_seed(42) # Now we can create a model and send it at once to the device model = nn.Sequential(nn.Linear(1, 1)).to(device) # Defines a SGD optimizer to update the parameters (now retrieved directly from the model) optimizer = optim.SGD(model.parameters(), lr=lr) # Defines a MSE loss function loss_fn = nn.MSELoss(reduction='mean') # Creates the train_step function for our model, loss function and optimizer train_step_fn = make_train_step_fn(model, loss_fn, optimizer) # Creates the val_step function for our model and loss function val_step_fn = make_val_step_fn(model, loss_fn)


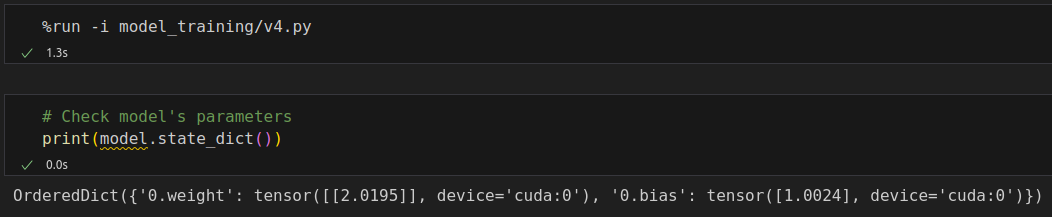
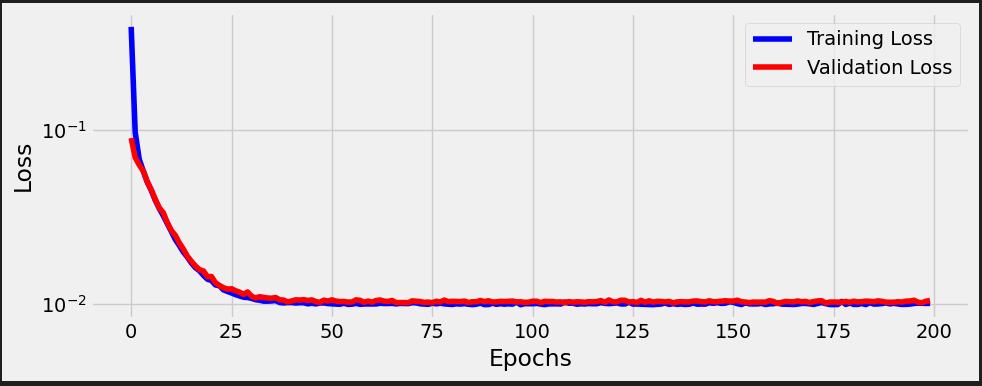
%%writefile model_training/v4.py n_epochs = 200 losses = [] val_losses = [] for epoch in range(n_epochs): loss = mini_batch(device, train_loader, train_step_fn) losses.append(loss) # VALIDATION # no gradients in validation! with torch.no_grad(): val_loss = mini_batch(device, val_loader, val_step_fn) val_losses.append(val_loss)