ML-特征、降维、稀疏、压缩
K-SVD:
KNN是一种监督学习的分类算法,K-Means是一种无监督学习的聚类算法。而K-SVD是一种字典学习算法,用于学习数据的稀疏表示,可以用于压缩、编码,也可以聚类。
K-SVD意在用较少的基本信号的线性组合来表达大部分或者全部的原始信号。
Y=DX,其中Y是样本集,假设Y的size为N,dimension为n,D为字典,dim也是n,size为K。
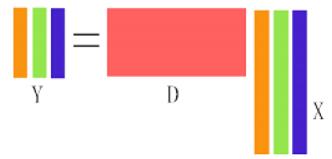
K-SVD的目的就是寻找最佳的字典D,同时使X稀疏矩阵达到稀疏最大。0越多越稀疏,目标就是用最稀疏的X的线性组合来逼近原始矩阵Y。
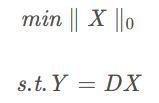
K-means主要通过计算距离来分类,并不是利用DX来十分逼近原样本矩阵Y,从而主要用于聚类,而K-SVD则由一系列原子来线性组合逼近,因此相比K-means更适用于压缩,编码等应用。
K-SVD的训练步骤分为两步,字典的优化和系数矩阵的优化,优化系数矩阵时,字典固定;优化字典时,系数矩阵一起优化。
1. 在样本集中挑选k个样本行程原子矩阵,初始化系数矩阵为0.
2. 固定字典,优化系数矩阵,可能要解超定方程(未知数小于方程个数),用最小二乘法求解距离最小的方程。
3. 字典优化,同时更新系数矩阵。
...