Google Deepmind RT-2论文解读
RT-2: New model translates vision and language into action 2023.07
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action
https://robotics-transformer2.github.io/
Google Deepmind
(把我的论文笔记放在这儿,如果有人看就接着写)
背景
- 语言模型从broad web-scale datasets中pretrain,为下游任务提供了非常强大的能力
- 视觉语言模型则支持开放词汇视觉识别,甚至可以对图像中的对象-代理交互做出复杂的推断
- 这种语义推理、problem solving和视觉解释能力对现实世界的通用机器人很有帮助
- 强大的语言和视觉语言模型是在来自互联网的billions of标记和图像上进行训练的。短期内机器人数据还难以赶上这个规模。而且,直接将这样的模型应用于机器人任务也很困难:因为这样的模型可以在语义、label和textual prompts方面推理,而机器人需要基础的low-level action,如笛卡尔末端执行器命令。
- 之前的一些工作试图将语言模型(LLM)和视觉语言模型(VLM)整合到机器人中,比如saycan, Palm-e, ChatGPT for Robotics,这些方法通常只解决机器人的high-level planning问题,本质上是充当状态机的角色,解释命令并将其解析为单个原语(例如拾取和放置对象),然后由单独的low-level controller执行。这些low-level controller在训练期间不会从互联网规模的丰富语义知识中受益。因此,本文就是针对这个问题来应对: 能否将大型预训练VLM直接集成到机器人的low-level control中,从而促进泛化并实现语义推理的涌现
- VLM方面:两种方式:
- representation-learning models,比如CLIP
- visual language models of the form {vision, text} → {text}:比如图像字幕、视觉问答(VQA)
- robot learning的泛化方面:
- 从large and diverse datasets中学习,之前一些工作表明可以泛化到
- novel object instances
- 涉及物体和技能的新组合的任务
- 新的目标或语言指令
- tasks with 物体类别语义也是新的
- 没见过的环境
- 从large and diverse datasets中学习,之前一些工作表明可以泛化到
做了什么
- 一个端到端的模型,源自对大型VLM的co-finetuning
- 既学习state/observation -> action 的映射
- 也能够从网上语言、视觉语言数据的大规模预训练中获益(Internet-scale training)
- 为了把语言和action拟合到相同的格式,把action表示成文本tokens,变成multimodal sentences放到训练集中。训出VLA模型(vision-language-action models)
- 比如 a grey donkey walks down the street那里,就用311 423...的tokens连接了action和文本
- 做的事情和大致的思路其实和以前的RT-1, VIMA等模型没啥区别,不过从VLM finetune、action token对齐text token是比较新的点
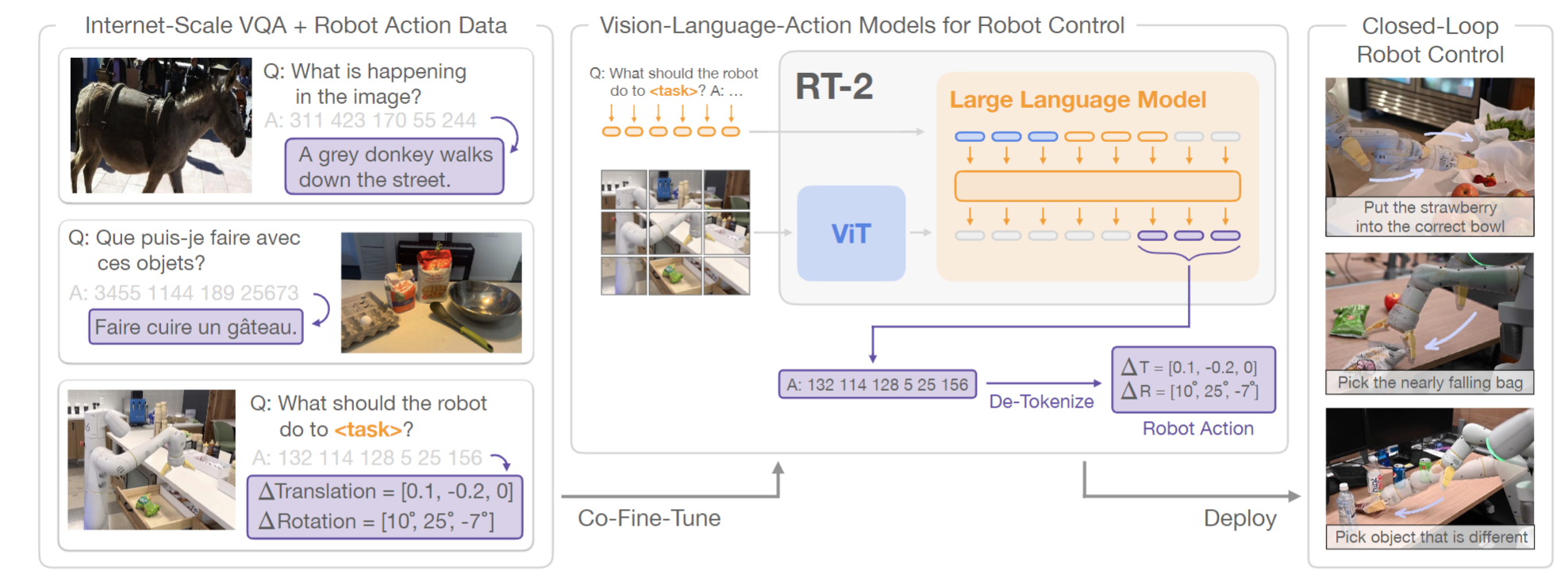
怎么做的
- 利用一个pretrained VLM
- 把action表示成文本tokens,变成multimodal sentences放到训练集中
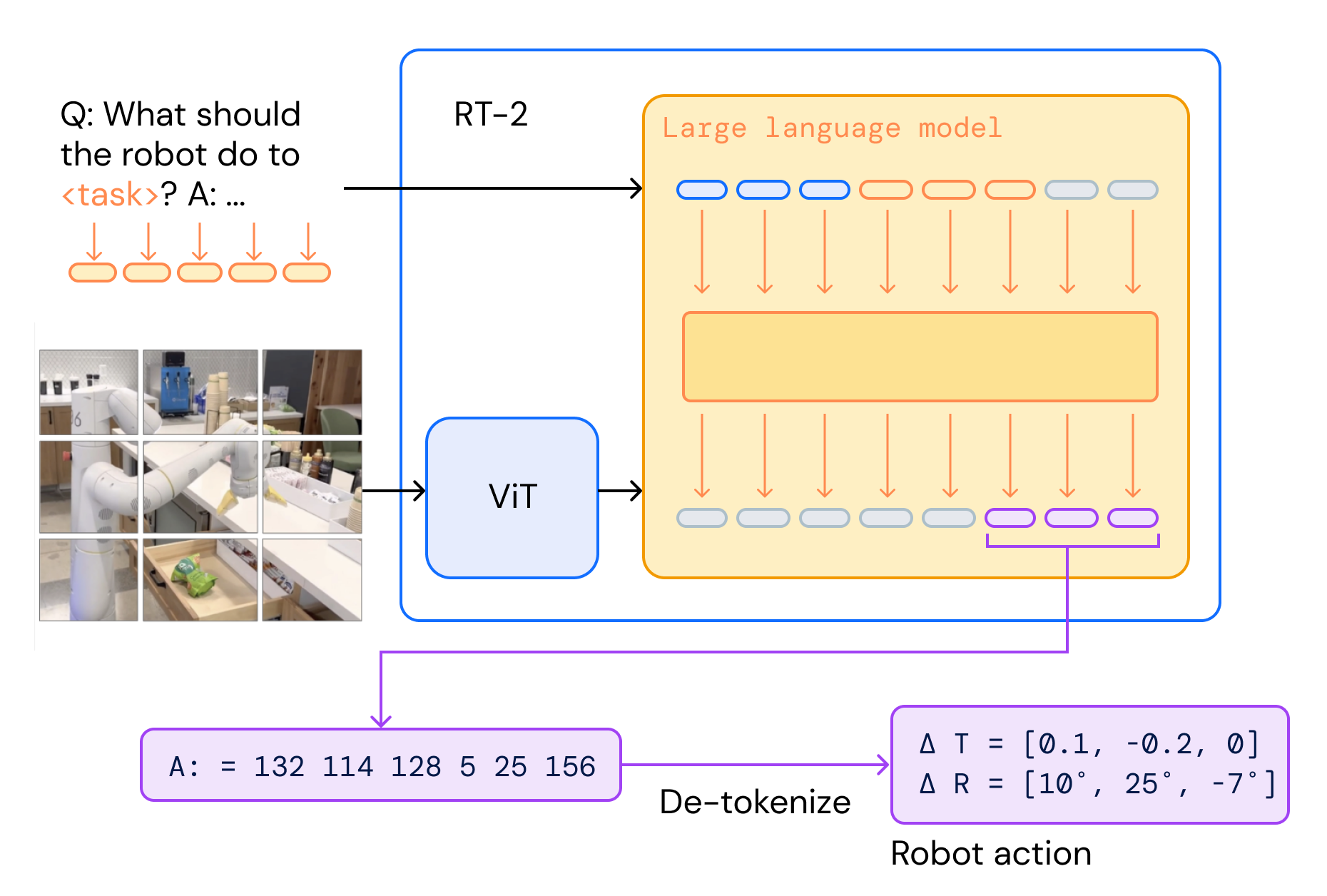
- 对现有的VLM与机器人数据进行co-finetune( fine-tuning and co-training的结合,其中保留了一些旧的视觉和文本数据,引入了新的机器人动作数据)。 机器人数据包括当前图像、语言命令和特定timestep的机器人动作。 把action表示成文本tokens,是以下图的形式,比如机器人动作的token numbers的序列可以是:“1 128 91 241 5 101 127 217”。这样以后,可以将action视为另外一种(操作机器人的)语言。之后要干的事情就是把action token和此前的text token空间进行co-finetune,使得他们能够对齐
- 与原始web data一起 co-finetune 机器人数据,增加机器人数据集上的采样权重来平衡每个训练批次中robotics data和web data的比率。

- 在inference阶段,transformer自回归生成的tokens会被de-tokenize为action(每一个timestep的action,交由机器人去执行)。
- 这种action tokens和文本tokens对齐的方式在机器人policy中利用了VLM的backbone和pretraining,一定程度转移了泛化性、语义理解、机器人控制方面的推理能力
效果
-
模型可以利用从互联网中学习过的文本图像数据,用新的方式部署所学到的动作技能(这些技能仍然是学习过的,但是用在了新的场景下。比如把可乐罐移动到taylor swift旁边),而数据集的demonstration中没有这样的图像-动作关系
- 在language-table benchmark 上打败了前SOTA(90% vs 77%)

- 在language-table benchmark 上打败了前SOTA(90% vs 77%)
-
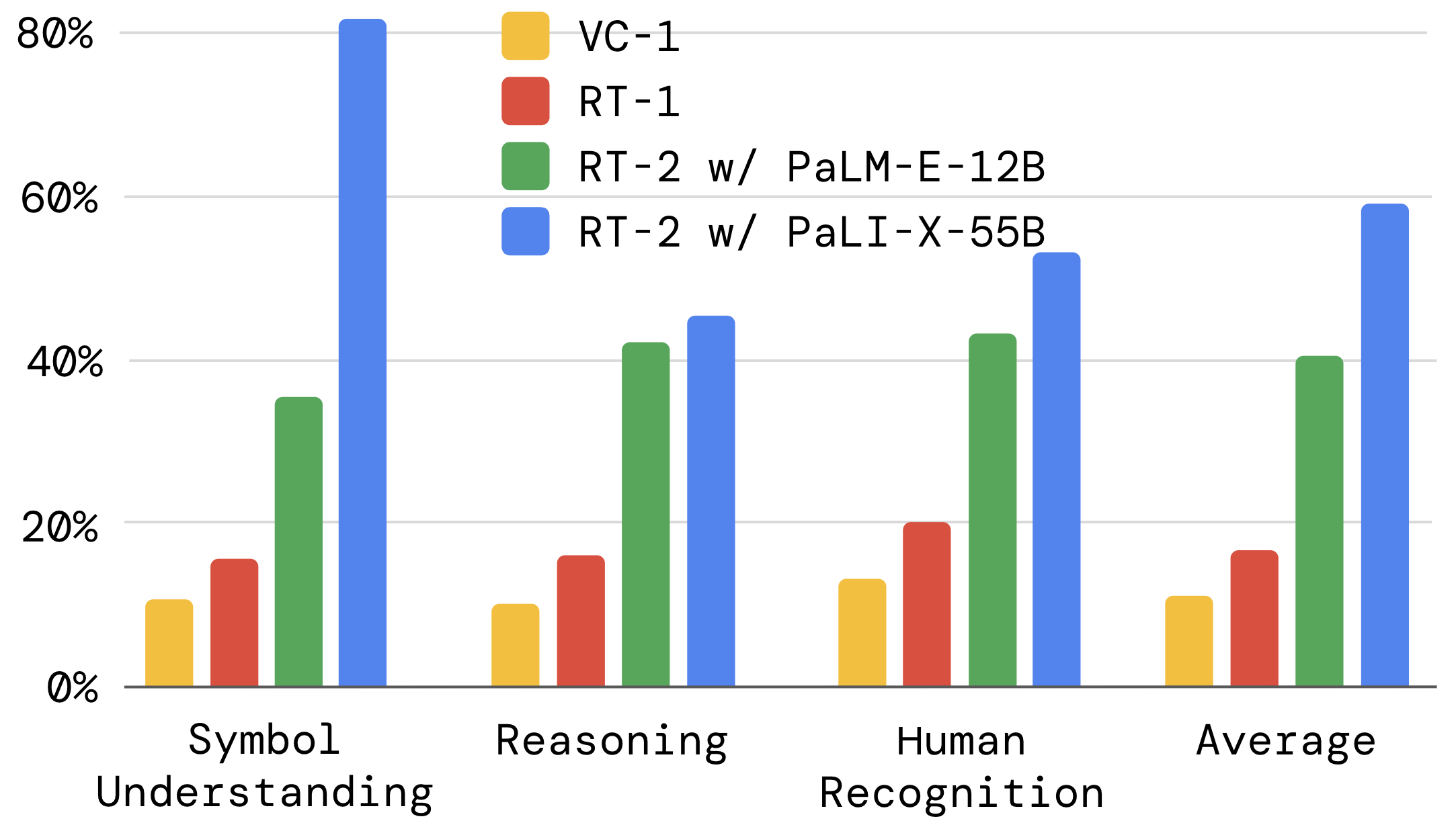
RT-2相对于前身RT-1有了接近三倍的提升。RT-2有两种变体,一种是基于PaLM-E-12B的VLM,一种是基于PaLI-X-55B的VLM,基于PaLI-X-55B的VLM会有更好的效果。下面是说不通类别任务的性能结果
-
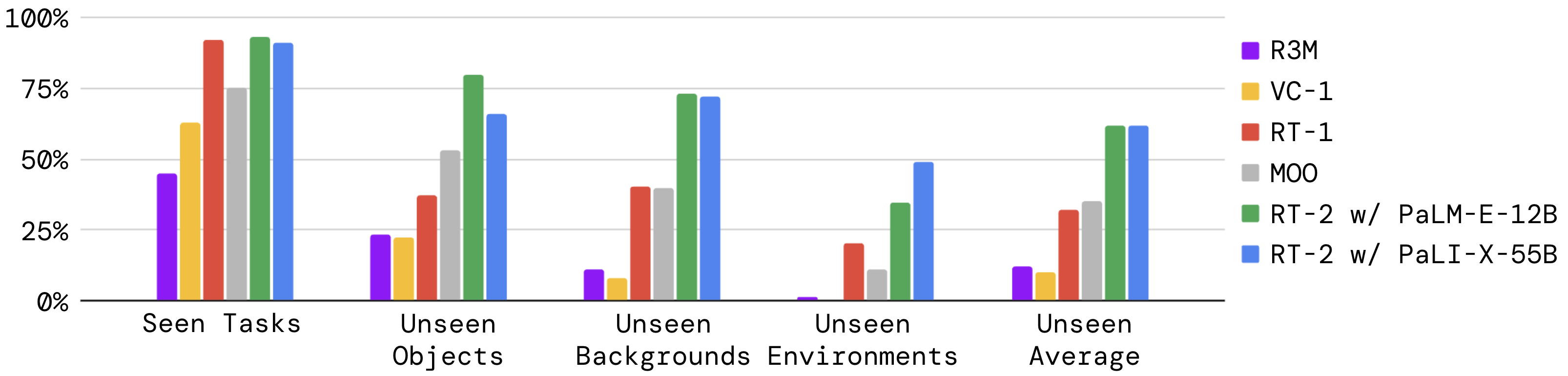
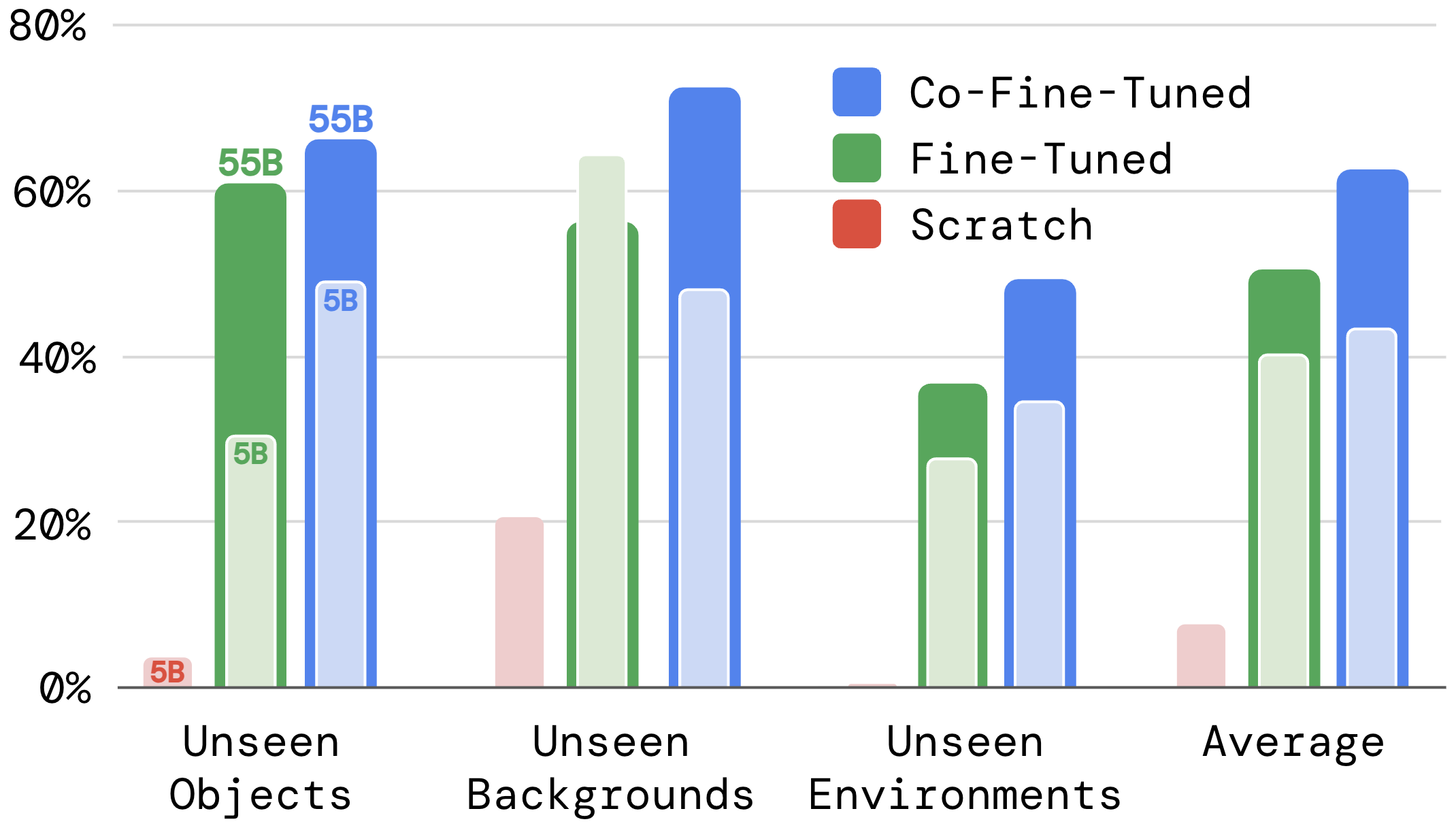
泛化性:包括没见过的物体、没见过的背景、没见过的环境,RT-2相比RT-1都有2倍提升
-
training from scratch. fine-tuning, co-fine-tuning三种训练方式的差别(这里scratch应该指的是从头开始训整个RT-2,但是数据不够吧?这些数据应该只够用于co-finetune?):
-
可以perform类似于ReAct的那种chain-of-thought:
-

highlights
-
对大型VLM的co-finetuning;能够从Internet-scale training中获益;把action表示成文本tokens,变成multimodal sentences放到训练集中,从而发挥VLM的能力
-
RT-2 可以表现出类似于VLM的chain-of-thought推理迹象。 具有chain-of-thought推理的 RT-2 能够回答更复杂的命令,因为它首先用自然语言规划其动作的位置。 这是一个很有前景的方向,它提供了一些初步证据,表明使用 LLM 或 VLM 作为规划器可以与单个 VLA 模型中的低级策略相结合。
-
之前看VIMA的总结,也提到这一点,就是未来发展方向的判断:多模态输入+行为(具身)模态输出将是机器人操控的一条道路
-
多模态输入,包括图像文本,可能还有行为(具身),需要有一个general-purpose captioner,把其他模态混杂在语言中,然后自然就可以把他们都对应到一个token序列中。比如[]表示图像,<>表示行为(具身)
-
状态:我看到了[那个,冰箱],我手上有[这个,可乐]。
目标or宏观行为:我要把[这个,可乐]<放到>[那个,冰箱]中
-
局限性
- 老生常谈的问题:场景比较局限,局限在简单桌面任务。不过有了VLM的视觉与语义理解助阵之后,确实可以更容易泛化到没见过的桌面场景和没见过的物品。桌面环境不是开放环境,我认为在强大的VLM的帮助下可以做到桌面环境通用机器人,只是现阶段有些问题比如桌面环境一旦复杂起来了就不好处理了,可能需要3D感知。
- 所以我的一个疑问就是,图中那些简单桌面环境在实际中应用场景有多大?实际应用中有多少是简单桌面环境,有多少是复杂桌面环境(比如立体、物体多、有遮挡)?
- 实时推理:还是好慢好笨拙的样子... 不过比之前快一些了。暂时不清楚控制频率的瓶颈点在哪儿,可能是VLM的推理很慢。 只有1-3 Hz !用5B VLM模型的话也只能达到5Hz
- 操作也不灵巧,两指做任务不灵活,视频中经常出现没抓稳、没放稳、捏香蕉捏得过于紧的问题
- data collection,利用RT-1的17个月收集的真实数据,过于昂贵,而且现有模型规模对VLA来说远远不够,因此未来还需要更大量的数据
- 采用的是模仿学习方法,因此学习得到的策略难以超过原先的demonstration(这一点局限性,对于现今世界、论文中实现的任务来说,暂时不是大问题)