【x86_64汇编】浮点数大小判断简化思路与实战
今天讨论的是《深入理解计算机系统》第214页的一示例题:

C代码:
typedef enum {NEG, ZERO, POS, OTHER} range_t; range_t find_range(float x){ int ret; if (x < 0) ret = 0; else if(x == 0) ret = 1; else if (x > 0) ret = 2; else ret = 3; return ret; }
本机编译器输出的汇编代码(-O3优化):
find_range: .seh_endprologue pxor %xmm1, %xmm1 xorl %eax, %eax comiss %xmm0, %xmm1 ja .L1 ucomiss %xmm1, %xmm0 jp .L7 jne .L7 movl $1, %eax .L1: ret .p2align 4,,10 .L7: xorl %eax, %eax ucomiss %xmm1, %xmm0 setbe %al addl $2, %eax ret .seh_endproc
得益于编译器的优化,本来只需要比较一次的浮点数,编译器整整比较了三次。其中,“.seh_endprologue”和“.seh_endproc”是编译器为处理异常(浮点计算出错)生成的,“.p2align 4,,10”则用于将代码与16字节对齐,都可以忽视。
所以首当其冲,就对比较次数进行一些简化,然后再删除一些冗余的地方,就有了以下代码:
find_range: .seh_endprologue pxor %xmm1, %xmm1 xorl %eax, %eax comiss %xmm0, %xmm1 ja .L1 jp .L7 jne .L7 incb %al .L1: ret .p2align 4,,10 .L7: setp %al addb $2, %al ret .seh_endproc
测试代码(未经过O3优化):
int main(){ float a = 1.5; printf("%d\n", find_range(a)); a = 0.0; printf("%d\n", find_range(a)); a = -0.873; printf("%d\n", find_range(a)); a = NAN; printf("%d\n", find_range(a)); return 0; }
得到正常输出:
2 1 0 3
理解层面上,这段代码能够运行的原因也很简单,完全在于comiss指令对标志寄存器的设定:
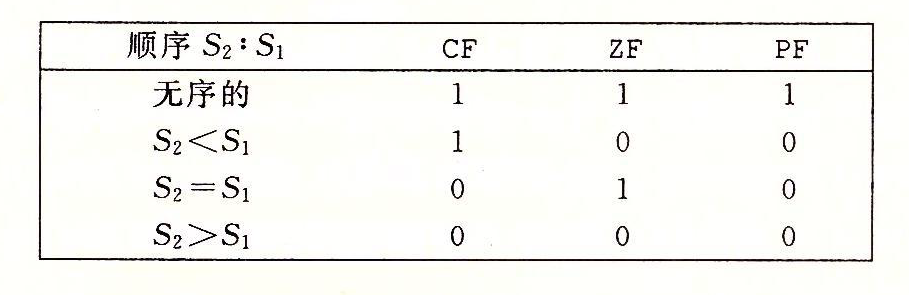
考虑到书上有对编译器代码的解释,这里便先略过,先解释这段简化代码。
首先代码中的ja指令,等效于~(CF|ZF),要求CF、ZF都是0才会生效,于是首先排除了0>x的情况,直接返回先前设定的空%rax,得0;
随后,jp代码排除NaN的情况,这一点毋庸置疑;而jne代码等效于~ZF,要求ZF为0,于是排除0<x的情况;最后只剩0=x的情况,inc加1返回 1;
到了L7这里,因为只有上面排除的两种情况(NaN与0<x),所以前者setp会置1而后者不会,两者再同时加2,前者就变成了3,后者变成了2,再返回便得到了他们。
然而,考虑到0、1、2、3是相邻数字,完全可以采用多个递增inc来产生,这样就有了以下代码:
find_range: .seh_endprologue pxor %xmm1, %xmm1 xorl %eax, %eax comiss %xmm1, %xmm0 ja L1 jnb L2 jne L3 incb %al L1: incb %al L2: incb %al L3: ret .seh_endproc
这样,代码用得更少了,只用了实际的10行代码,而且相比上一段还去掉了ret后面对齐用的的“.p2align 4,,10”,进一步减少占用。
至于原理,也是一样,ja排除CF、ZF都是0的情况(x>0),jnb再排除CF为0的情况(x=0),jne再排除ZF为0的情况(x<0),最后剩下的就是CF、ZF都是0的情况(x=NaN)。至于所排除的内容,都通过标签跳转到了正确的位置。基本只要想着那个表,整个过程都非常好理解。
但当想到那些标志的值的时候,突然发觉,既然代码是通过的那些值来体现比较结果,那为什么不把那些值直接提取出来,这样就不用再各种跳转、各种递增了。但是问题在于,并不知道如何提取那些标志,以为没有这种方法。但在网上一查,竟然真就找到了一条指令,lahf,可以直接把标志寄存器低8位的值放到%ah寄存器里,搭配在文章里找到的这幅图,就可以用了:
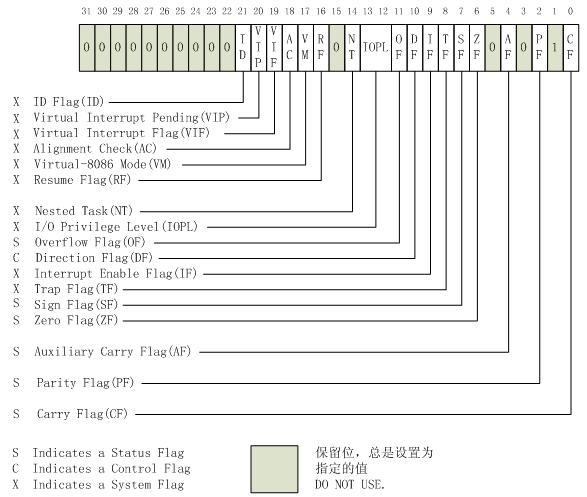
很快啊,就有了这段代码:
find_range: .seh_endprologue pxor %xmm1, %xmm1 xorl %eax, %eax comiss %xmm0, %xmm1 lahf movb %ah, %al addb %al, %al shlw $7, %ax shrw $14, %ax ret .seh_endproc
这次就只有实际的9行,占用了更少的空间,而且完全避免了分支代码,大幅降低了分支预测所带来的开销。
这次实战有三个感悟,第一个,如果是判断数值又输出数值,那大概率可以精简掉判断过程,取而以纯计算过程(数值→数值)代之。
第二个感悟前面没有深入,来自于最后的精简过程,即位移取数时,最好先固定一位不动,将另一位完善后,再位移得到所需。
第三个感悟来自书上,编译器对浮点运算的优化确实不好,遇到时真就可以手动优化一下。
以上,就是今天的实战过程。
扩展:
sahf指令:可将ah的值写入标志寄存器低8位