GPT2学习


import streamlit as st from transformers import GPT2LMHeadModel#, CpmTokenizer #from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel from transformers.models.cpm import CpmTokenizer import argparse import os import torch import time from utils import top_k_top_p_filtering import torch.nn.functional as F st.set_page_config(page_title="Demo", initial_sidebar_state="auto", layout="wide") @st.cache(allow_output_mutation=True) def get_model(device, model_path): tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符 sep_id = tokenizer.sep_token_id unk_id = tokenizer.unk_token_id model = GPT2LMHeadModel.from_pretrained(model_path) model.to(device) model.eval() return tokenizer, model, eod_id, sep_id, unk_id device_ids = 0 os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICE"] = str(device_ids) device = torch.device("cuda" if torch.cuda.is_available() and int(device_ids) >= 0 else "cpu") tokenizer, model, eod_id, sep_id, unk_id = get_model(device, "model/zuowen_epoch40") def generate_next_token(input_ids,args): """ 对于给定的上文,生成下一个单词 """ # 只根据当前位置的前context_len个token进行生成 input_ids = input_ids[:, -200:] outputs = model(input_ids=input_ids) logits = outputs.logits # next_token_logits表示最后一个token的hidden_state对应的prediction_scores,也就是模型要预测的下一个token的概率 next_token_logits = logits[0, -1, :] next_token_logits = next_token_logits / args.temperature # 对于<unk>的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token next_token_logits[unk_id] = -float('Inf') filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=args.top_k, top_p=args.top_p) # torch.multinomial表示从候选集合中选出无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标 next_token_id = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1) return next_token_id def predict_one_sample(model, tokenizer, device, args, title, context): title_ids = tokenizer.encode(title, add_special_tokens=False) context_ids = tokenizer.encode(context, add_special_tokens=False) input_ids = title_ids + [sep_id] + context_ids cur_len = len(input_ids) last_token_id = input_ids[-1] # 已生成的内容的最后一个token input_ids = torch.tensor([input_ids], dtype=torch.long, device=device) while True: next_token_id = generate_next_token(input_ids,args) input_ids = torch.cat((input_ids, next_token_id.unsqueeze(0)), dim=1) cur_len += 1 word = tokenizer.convert_ids_to_tokens(next_token_id.item()) # 超过最大长度,并且换行 if cur_len >= args.generate_max_len and last_token_id == 8 and next_token_id == 3: break # 超过最大长度,并且生成标点符号 if cur_len >= args.generate_max_len and word in [".", "。", "!", "!", "?", "?", ",", ","]: break # 生成结束符 if next_token_id == eod_id: break result = tokenizer.decode(input_ids.squeeze(0)) content = result.split("<sep>")[1] # 生成的最终内容 return content def writer(): st.markdown( """ ## GPT生成模型 """ ) st.sidebar.subheader("配置参数") generate_max_len = st.sidebar.number_input("generate_max_len", min_value=0, max_value=512, value=32, step=1) top_k = st.sidebar.slider("top_k", min_value=0, max_value=10, value=3, step=1) top_p = st.sidebar.number_input("top_p", min_value=0.0, max_value=1.0, value=0.95, step=0.01) temperature = st.sidebar.number_input("temperature", min_value=0.0, max_value=100.0, value=1.0, step=0.1) parser = argparse.ArgumentParser() parser.add_argument('--generate_max_len', default=generate_max_len, type=int, help='生成标题的最大长度') parser.add_argument('--top_k', default=top_k, type=float, help='解码时保留概率最高的多少个标记') parser.add_argument('--top_p', default=top_p, type=float, help='解码时保留概率累加大于多少的标记') parser.add_argument('--max_len', type=int, default=512, help='输入模型的最大长度,要比config中n_ctx小') parser.add_argument('--temperature', type=float, default=temperature, help='输入模型的最大长度,要比config中n_ctx小') args = parser.parse_args() context = st.text_area("请输入标题", max_chars=512) title = st.text_area("请输入正文", max_chars=512) if st.button("点我生成结果"): start_message = st.empty() start_message.write("自毁程序启动中请稍等 10.9.8.7 ...") start_time = time.time() result = predict_one_sample(model, tokenizer, device, args, title, context) end_time = time.time() start_message.write("生成完成,耗时{}s".format(end_time - start_time)) st.text_area("生成结果", value=result, key=None) else: st.stop() if __name__ == '__main__': writer()
GPT2的开始代码app
训练模型train:
import argparse import math import time import torch import torch.nn.functional as F import torch.optim as optim import logging from datetime import datetime import os from torch.utils.data import Dataset, DataLoader from os.path import join, exists from torch.nn import CrossEntropyLoss from tqdm import tqdm from torch.nn import DataParallel import transformers import pickle import sys from utils import set_logger, set_random_seed from sklearn.model_selection import train_test_split from data_parallel import BalancedDataParallel from transformers import GPT2LMHeadModel, GPT2Config, CpmTokenizer#pip install sentencepiece import pandas as pd #https://www.sciencedirect.com/science/article/pii/S266665102100019X import torch.nn.utils.rnn as rnn_utils import numpy as np from dataset import CPMDataset #--epochs 40 --batch_size 8 --device 0,1 --train_path data/train.pkl def set_args(): parser = argparse.ArgumentParser() parser.add_argument('--device', default='0,1', type=str, required=False, help='设置使用哪些显卡') parser.add_argument('--no_cuda', action='store_true', help='不使用GPU进行训练') parser.add_argument('--vocab_path', default='vocab/chinese_vocab.model', type=str, required=False, help='sp模型路径') parser.add_argument('--model_config', default='config/cpm-small.json', type=str, required=False, help='需要从头训练一个模型时,模型参数的配置文件') parser.add_argument('--train_path', default='data/train.pkl', type=str, required=False, help='经过预处理之后的数据存放路径') parser.add_argument('--max_len', default=200, type=int, required=False, help='训练时,输入数据的最大长度') parser.add_argument('--log_path', default='log/train.log', type=str, required=False, help='训练日志存放位置') parser.add_argument('--ignore_index', default=-100, type=int, required=False, help='对于ignore_index的label token不计算梯度') parser.add_argument('--epochs', default=100, type=int, required=False, help='训练的最大轮次') parser.add_argument('--batch_size', default=16, type=int, required=False, help='训练的batch size') parser.add_argument('--gpu0_bsz', default=6, type=int, required=False, help='0号卡的batch size') parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率') parser.add_argument('--eps', default=1.0e-09, type=float, required=False, help='AdamW优化器的衰减率') parser.add_argument('--log_step', default=10, type=int, required=False, help='多少步汇报一次loss') parser.add_argument('--gradient_accumulation_steps', default=6, type=int, required=False, help='梯度积累的步数') parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False) parser.add_argument('--save_model_path', default='model', type=str, required=False, help='模型输出路径') parser.add_argument('--pretrained_model', default='model/zuowen_epoch40', type=str, required=False, help='预训练的模型的路径') parser.add_argument('--seed', type=int, default=1234, help='设置随机种子') parser.add_argument('--num_workers', type=int, default=0, help="dataloader加载数据时使用的线程数量") # parser.add_argument('--patience', type=int, default=0, help="用于early stopping,设为0时,不进行early stopping.early stop得到的模型的生成效果不一定会更好。") parser.add_argument('--warmup_steps', type=int, default=4000, help='warm up步数') # parser.add_argument('--label_smoothing', default=True, action='store_true', help='是否进行标签平滑') args = parser.parse_args() return args def collate_fn(batch): input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=5) labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100) return input_ids, labels def load_dataset(logger, args): """ 加载训练集 """ logger.info("loading training dataset") train_path = args.train_path with open(train_path, "rb") as f: train_list = pickle.load(f) # test # train_list = train_list[:24] train_dataset = CPMDataset(train_list, args.max_len) return train_dataset def train_epoch(model, train_dataloader, optimizer, scheduler, logger, epoch, args): model.train() device = args.device ignore_index = args.ignore_index epoch_start_time = datetime.now() total_loss = 0 # 记录下整个epoch的loss的总和 epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量 epoch_total_num = 0 # 每个epoch中,预测的word的总数量 for batch_idx, (input_ids, labels) in enumerate(train_dataloader): # 捕获cuda out of memory exception try: input_ids = input_ids.to(device) labels = labels.to(device) outputs = model.forward(input_ids, labels=labels) logits = outputs.logits loss = outputs.loss loss = loss.mean() # 统计该batch的预测token的正确数与总数 batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index) # 统计该epoch的预测token的正确数与总数 epoch_correct_num += batch_correct_num epoch_total_num += batch_total_num # 计算该batch的accuracy batch_acc = batch_correct_num / batch_total_num total_loss += loss.item() if args.gradient_accumulation_steps > 1: loss = loss / args.gradient_accumulation_steps loss.backward() # 梯度裁剪 torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm) # 进行一定step的梯度累计之后,更新参数 if (batch_idx + 1) % args.gradient_accumulation_steps == 0: # 更新参数 optimizer.step() # 更新学习率 scheduler.step() # 清空梯度信息 optimizer.zero_grad() if (batch_idx + 1) % args.log_step == 0: logger.info( "batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format( batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr())) del input_ids, outputs except RuntimeError as exception: if "out of memory" in str(exception): logger.info("WARNING: ran out of memory") if hasattr(torch.cuda, 'empty_cache'): torch.cuda.empty_cache() else: logger.info(str(exception)) raise exception # 记录当前epoch的平均loss与accuracy epoch_mean_loss = total_loss / len(train_dataloader) epoch_mean_acc = epoch_correct_num / epoch_total_num logger.info( "epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc)) # save model logger.info('saving model for epoch {}'.format(epoch + 1)) model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1)) if not os.path.exists(model_path): os.mkdir(model_path) model_to_save = model.module if hasattr(model, 'module') else model model_to_save.save_pretrained(model_path) logger.info('epoch {} finished'.format(epoch + 1)) epoch_finish_time = datetime.now() logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time)) return epoch_mean_loss def train(model, logger, train_dataset, args): train_dataloader = DataLoader( train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn, drop_last=True ) logger.info("total_steps:{}".format(len(train_dataloader)* args.epochs)) t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.epochs optimizer = transformers.AdamW(model.parameters(), lr=args.lr, eps=args.eps) scheduler = transformers.get_linear_schedule_with_warmup( optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total )#设置warmup logger.info('start training') train_losses = [] # 记录每个epoch的平均loss # ========== start training ========== # for epoch in range(args.epochs): train_loss = train_epoch( model=model, train_dataloader=train_dataloader, optimizer=optimizer, scheduler=scheduler, logger=logger, epoch=epoch, args=args) train_losses.append(round(train_loss, 4)) logger.info("train loss list:{}".format(train_losses)) logger.info('training finished') logger.info("train_losses:{}".format(train_losses)) def caculate_loss(logit, target, pad_idx, smoothing=True): if smoothing: logit = logit[..., :-1, :].contiguous().view(-1, logit.size(2)) target = target[..., 1:].contiguous().view(-1) eps = 0.1 n_class = logit.size(-1) one_hot = torch.zeros_like(logit).scatter(1, target.view(-1, 1), 1) one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1) log_prb = F.log_softmax(logit, dim=1) non_pad_mask = target.ne(pad_idx) loss = -(one_hot * log_prb).sum(dim=1) loss = loss.masked_select(non_pad_mask).mean() # average later else: # loss = F.cross_entropy(predict_logit, target, ignore_index=pad_idx) logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1)) labels = target[..., 1:].contiguous().view(-1) loss = F.cross_entropy(logit, labels, ignore_index=pad_idx) return loss def calculate_acc(logit, labels, ignore_index=-100): logit = logit[..., :-1, :].contiguous().view(-1, logit.size(-1)) labels = labels[..., 1:].contiguous().view(-1) _, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index # 进行非运算,返回一个tensor,若labels的第i个位置为pad_id,则置为0,否则为1 non_pad_mask = labels.ne(ignore_index) n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item() n_word = non_pad_mask.sum().item() return n_correct, n_word def main(): # 初始化参数 args = set_args() # 设置使用哪些显卡进行训练 os.environ["CUDA_VISIBLE_DEVICES"] = args.device args.cuda = not args.no_cuda # if args.batch_size < 2048 and args.warmup_steps <= 4000: # print('[Warning] The warmup steps may be not enough.\n' \ # '(sz_b, warmup) = (2048, 4000) is the official setting.\n' \ # 'Using smaller batch w/o longer warmup may cause ' \ # 'the warmup stage ends with only little data trained.') # 创建日志对象 logger = set_logger(args.log_path) # 当用户使用GPU,并且GPU可用时 args.cuda = torch.cuda.is_available() and not args.no_cuda device = 'cuda:0' if args.cuda else 'cpu' args.device = device logger.info('using device:{}'.format(device)) # 设置随机种子 set_random_seed(args.seed, args.cuda) # 初始化tokenizer https://www.sciencedirect.com/science/article/pii/S266665102100019X tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model") args.eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符 args.pad_id = tokenizer.pad_token_id # 创建模型的输出目录 if not os.path.exists(args.save_model_path): os.mkdir(args.save_model_path) # 创建模型 if args.pretrained_model: # 加载预训练模型 model = GPT2LMHeadModel.from_pretrained(args.pretrained_model) else: # 初始化模型 model_config = GPT2Config.from_json_file(args.model_config) model = GPT2LMHeadModel(config=model_config) model = model.to(device) logger.info('model config:\n{}'.format(model.config.to_json_string())) assert model.config.vocab_size == tokenizer.vocab_size # 多卡并行训练模型 if args.cuda and torch.cuda.device_count() > 1: # model = DataParallel(model).cuda() model = BalancedDataParallel(args.gpu0_bsz, model, dim=0).cuda() logger.info("use GPU {} to train".format(args.device)) # 计算模型参数数量 num_parameters = 0 parameters = model.parameters() for parameter in parameters: num_parameters += parameter.numel() logger.info('number of model parameters: {}'.format(num_parameters)) # 记录参数设置 logger.info("args:{}".format(args)) # 加载训练集和验证集 # ========= Loading Dataset ========= # train_dataset = load_dataset(logger, args) train(model, logger, train_dataset, args) if __name__ == '__main__': main()
预执行preprocess:
import argparse from utils import set_logger from transformers import CpmTokenizer import os import pickle from tqdm import tqdm # --data_path data/zuowen --save_path data/train.pkl --win_size 200 --step 200 # https://huggingface.co/docs/transformers/main/en/model_doc/cpm#transformers.CpmTokenizer def preprocess(): """ 对故事数据集进行预处理 """ # 设置参数 parser = argparse.ArgumentParser() parser.add_argument('--vocab_file', default='vocab/chinese_vocab.model', type=str, required=False, help='词表路径') parser.add_argument('--log_path', default='log/preprocess.log', type=str, required=False, help='日志存放位置') parser.add_argument('--data_path', default='data/zuowen', type=str, required=False, help='数据集存放位置') parser.add_argument('--save_path', default='data/train.pkl', type=str, required=False, help='对训练数据集进行tokenize之后的数据存放位置') parser.add_argument('--win_size', default=200, type=int, required=False, help='滑动窗口的大小,相当于每条数据的最大长度') parser.add_argument('--step', default=200, type=int, required=False, help='滑动窗口的滑动步幅') args = parser.parse_args() # 初始化日志对象 logger = set_logger(args.log_path) # 初始化tokenizer tokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")#pip install jieba eod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符 sep_id = tokenizer.sep_token_id # 读取作文数据集目录下的所有文件 train_list = [] logger.info("start tokenizing data") for file in tqdm(os.listdir(args.data_path)): file = os.path.join(args.data_path, file) with open(file, "r", encoding="utf8")as reader: lines = reader.readlines() title = lines[1][3:].strip() # 取出标题 lines = lines[7:] # 取出正文内容 article = "" for line in lines: if line.strip() != "": # 去除换行 article += line title_ids = tokenizer.encode(title, add_special_tokens=False) article_ids = tokenizer.encode(article, add_special_tokens=False) token_ids = title_ids + [sep_id] + article_ids + [eod_id] # train_list.append(token_ids) # 对于每条数据,使用滑动窗口对其进行截断 win_size = args.win_size step = args.step start_index = 0 end_index = win_size data = token_ids[start_index:end_index] train_list.append(data) start_index += step end_index += step while end_index+50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集 data = token_ids[start_index:end_index] train_list.append(data) start_index += step end_index += step # 序列化训练数据 with open(args.save_path, "wb") as f: pickle.dump(train_list, f) if __name__ == '__main__': preprocess()
项目目录:
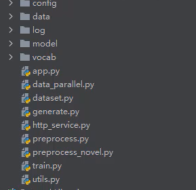
运行命令:
streamlit run app.py
https://docs.streamlit.io/library/advanced-features/caching
运行效果:

,Best Wish 不负年华