为什么说 elastic search 是近实时的?
我们都知道 elastic search 是近实时的搜索系统,这里面的原因究竟是什么呢?es 是近实时,是因为 lucene 是近实时的。我们看一段 lucene 的示例代码:
使用的 lucene 版本如下:
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>8.9.0</version> </dependency>
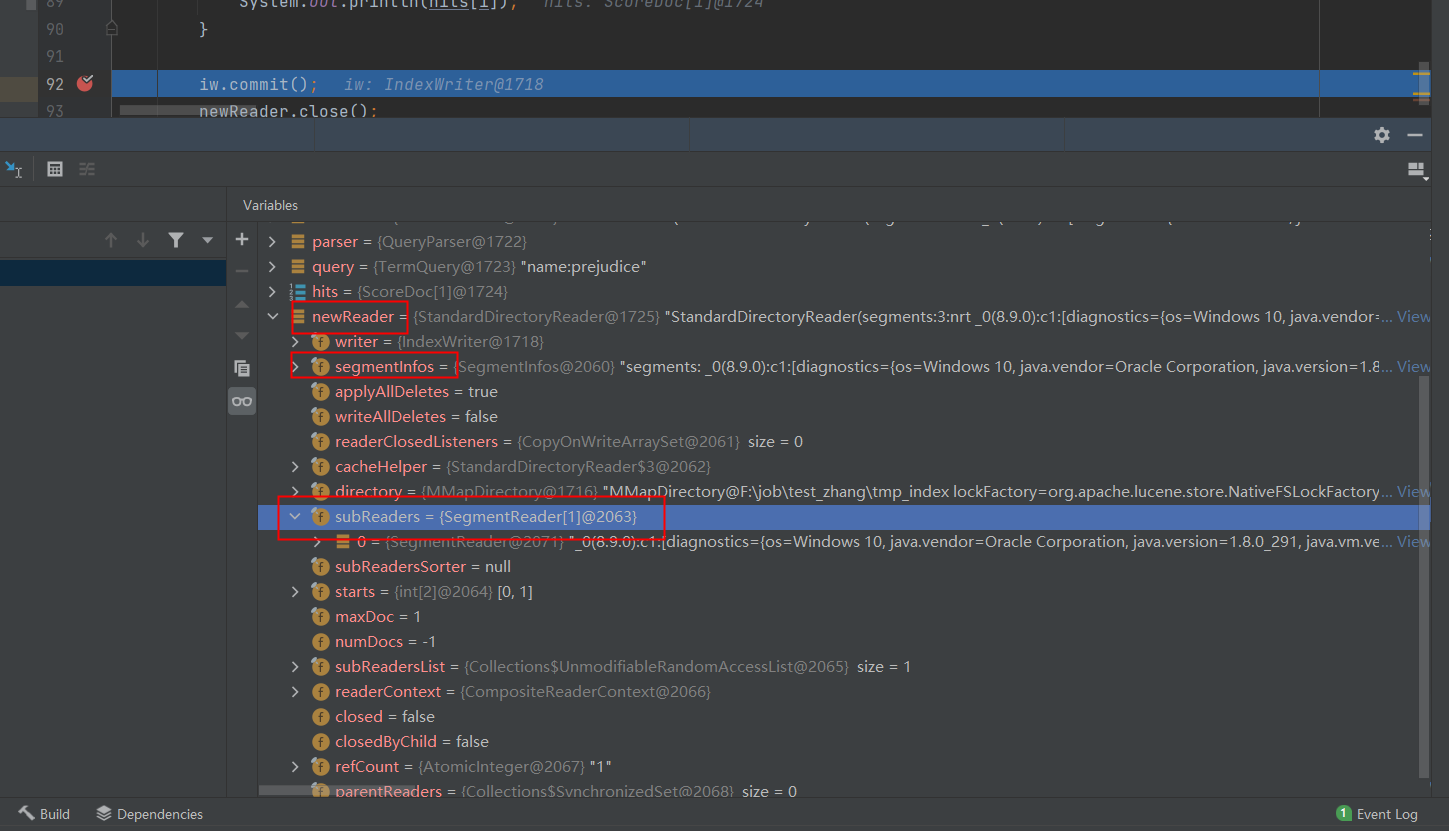
1 Analyzer analyzer = new StandardAnalyzer(); 2 3 Path indexPath = new File("tmp_index").toPath(); 4 IOUtils.rm(indexPath); 5 Directory directory = FSDirectory.open(indexPath); 6 IndexWriterConfig config = new IndexWriterConfig(analyzer); 7 // 使用 compound file 8 config.setUseCompoundFile(true); 9 // config.setInfoStream(System.out); 10 IndexWriter iw = new IndexWriter(directory, config); 11 // Now search the index: 12 StandardDirectoryReader oldReader = (StandardDirectoryReader) DirectoryReader.open(iw); 13 14 // 添加文档 1 15 Document doc = new Document(); 16 doc.add(new Field("name", "Pride and Prejudice", TextField.TYPE_STORED)); 17 doc.add(new Field("line", "It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.", TextField.TYPE_STORED)); 18 doc.add(new Field("chapters", "1", TextField.TYPE_STORED)); 19 iw.addDocument(doc); 20 21 IndexSearcher searcher = new IndexSearcher(oldReader); 22 // Parse a simple query that searches for "text": 23 QueryParser parser = new QueryParser("name", analyzer); 24 Query query = parser.parse("prejudice"); 25 ScoreDoc[] hits = searcher.search(query, 10).scoreDocs; 26 // Iterate through the results: 27 System.out.println("第一次查询:"); 28 System.out.printf("version=%d, segmentInfos=%s\n", oldReader.getVersion(), 29 oldReader.getSegmentInfos()); 30 for (int i = 0; i < hits.length; i++) { 31 System.out.println(hits[i]); 32 } 33 34 StandardDirectoryReader newReader = (StandardDirectoryReader) DirectoryReader.openIfChanged(oldReader); 35 oldReader.close(); 36 37 searcher = new IndexSearcher(newReader); 38 hits = searcher.search(query, 10).scoreDocs; 39 System.out.println("第二次查询:"); 40 System.out.printf("version=%d, segmentInfos=%s\n", newReader.getVersion(), 41 newReader.getSegmentInfos()); 42 // Iterate through the results: 43 for (int i = 0; i < hits.length; i++) { 44 System.out.println(hits[i]); 45 } 46 47 iw.commit(); 48 newReader.close(); 49 directory.close();
在第 15 行处,添加一个文档,然后执行搜索,并没有查询到文档。
在第 34 行处,调用 DirectoryReader.openIfChanged 方法,然后使用新的 reader 执行搜索,则可以查询到文档,注意此时文档仍然没有 flush 到磁盘中。
在第 47 行处,调用 IndexWriter.commit 方法,执行 flush 写盘。
OK ,现在看到了近实时的现象,对应到 ES 中的操作,在 ES 中写入一个文档,如同 15 行的操作,写入并不是立即可见;
需要执行 refresh,对应到第 24 行代码的 openIfChanged 方法;
ES 执行 flush 则对应到第 47 行的 IndexWriter.commit 方法。
针对网上所说的,ES 每次 refresh 之后都会生成一个 segment,看看 debug 截图:
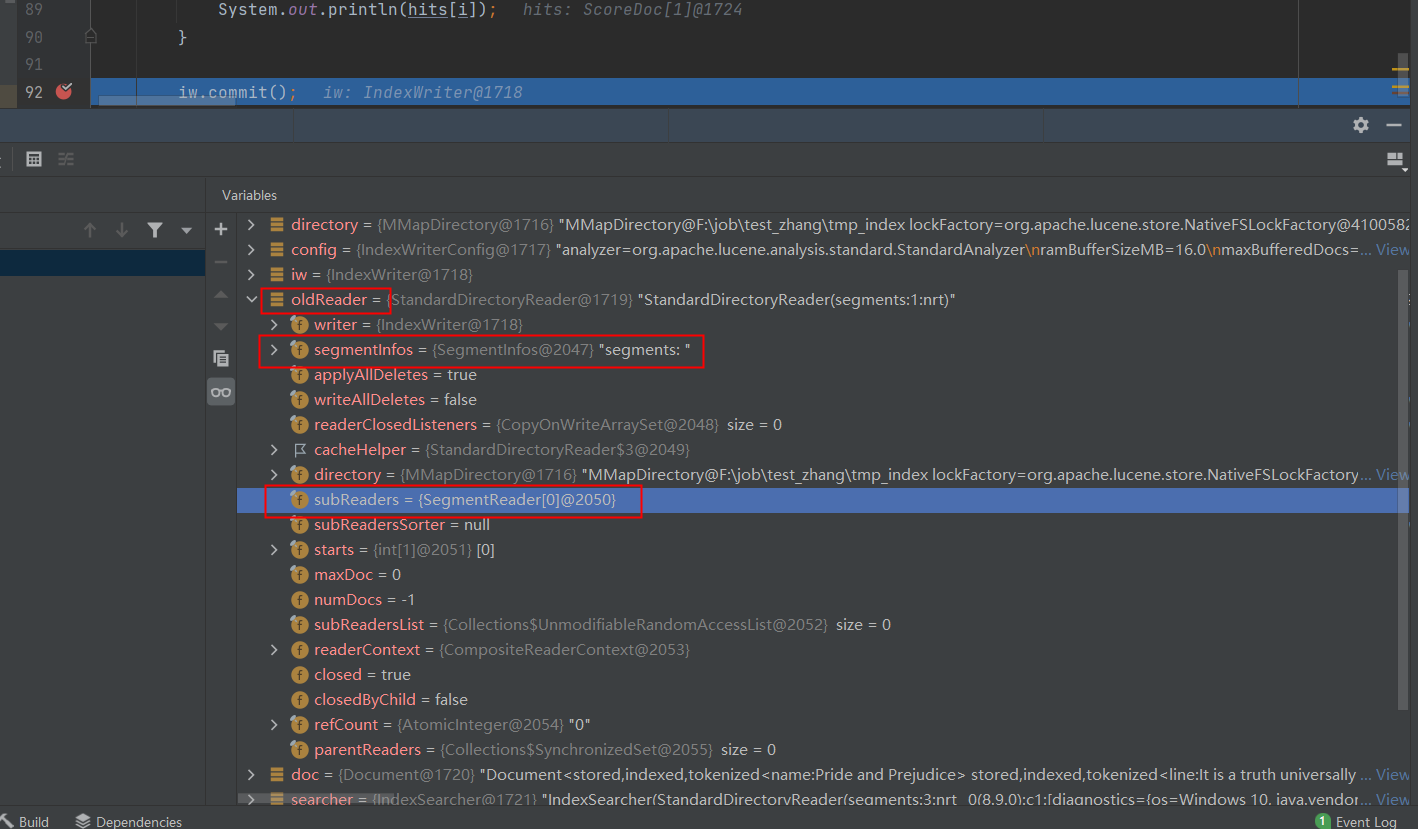
openIfChanged 之后确实生成了一个 SegmentReader