linux 中awk中match的使用
输出is和not后面的单词
001、
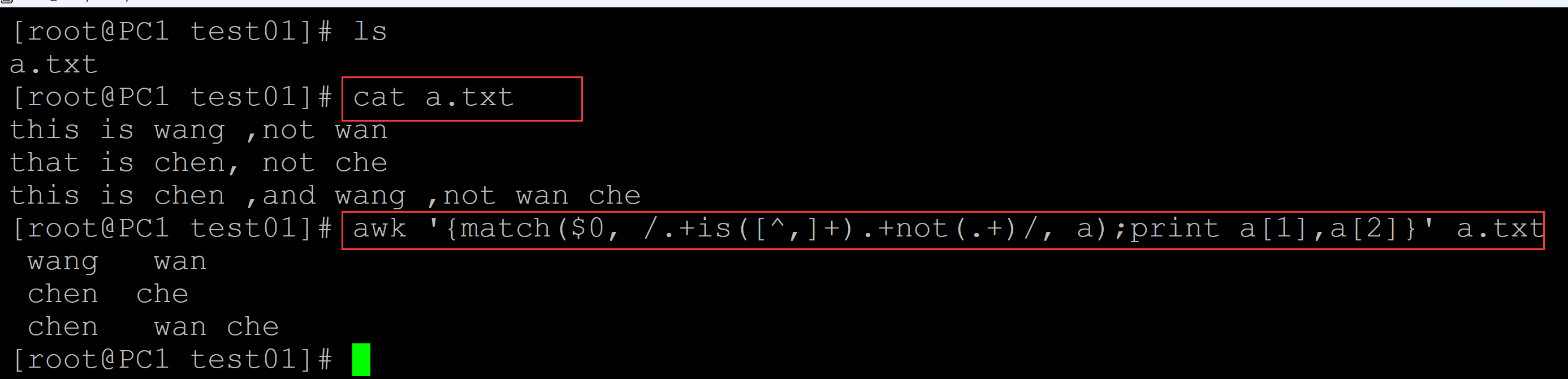
[root@PC1 test01]# ls a.txt [root@PC1 test01]# cat a.txt ## 测试数据 this is wang ,not wan that is chen, not che this is chen ,and wang ,not wan che [root@PC1 test01]# awk '{match($0, /.+is([^,]+).+not(.+)/, a);print a[1],a[2]}' a.txt ## 提取命令 wang wan chen che chen wan che
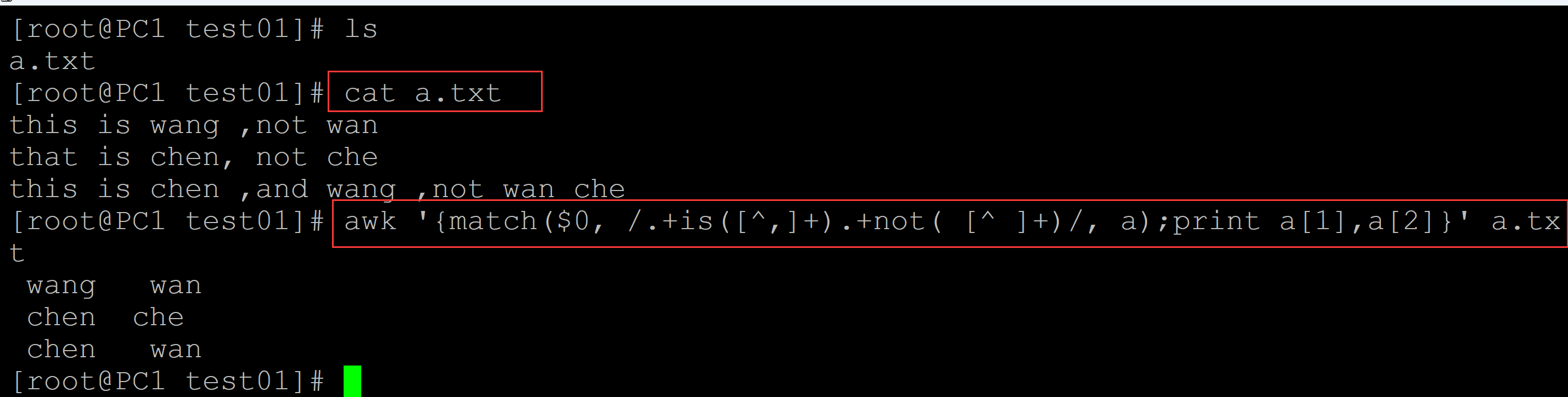
[root@PC1 test01]# ls a.txt [root@PC1 test01]# cat a.txt ## 测试数据 this is wang ,not wan that is chen, not che this is chen ,and wang ,not wan che ## 只提取not后面的第一个单词 [root@PC1 test01]# awk '{match($0, /.+is([^,]+).+not( [^ ]+)/, a);print a[1],a[2]}' a.txt wang wan chen che chen wan
002、
[root@PC1 test01]# echo "abc123def456" | awk '{match($0, /[0-9]+/); print substr($0, RSTART, RLENGTH)}' 123 ## RSTART 和 RLENGTH是内置函数,表示匹配的起点和终点

。