【数据结构】散列表
这种查找结构与线性表和树形结构都不同,前两者的共同特点是关键字与记录位置之间没有确定关系,需要从一个起点不断进行比较查找位置。

可以知道散列表(哈希表)是一种完全不同机制的查找结构,不采用基于比较选择的查找机制,而是直接在关键字与位置之间建立映射。
所以在讨论它时也和上面的几种查找结构的思路不同。
1.散列函数的构造方法

构造散列函数需要参考的几个原则。
几种常用的散列函数
1.直接定址法
根据关键字的线性函数值来取地址 如H(key) = a ×key +b
优点:计算简单,不会有冲突(因为查找表中不会有重复的关键字)
缺点:若关键字分布不连续,则存储空间浪费较多
2.除留余数法
最常用
H(key) = key % p
地址等于关键字key除p取余的结果
关于如何选择合适的除数p:
p一定要小于散列表的表长m(这里的表长注意是查找表的长度,而不是关键字的个数,所以除数p不能大于m,大于的话得到的余数就可能大于表长,这时就溢出了)
p应该是一个质数,并且要在一定范围内尽可能大,p在小于m的情况下取值越大则冲突的可能性越小,反之p越小则冲突可能性越大。p取质数也是为了尽量减少冲突
p如果过大的话也会有缺点,在关键字个数一定的情况下,可以得知余数p取得太大的话会造成很大的空间浪费(空隙太多)
3.数字分析法
4.平方取中法

数字分析法这里讲的太拉了

2.处理冲突的方法
(1)开放定址法
指的是可存放新表项的空闲地址除了向其同义词表项开放之外还对其非同义词表项开放
这里的同义词表项指的是直接通过一次散列函数分配的关键字,而向非同义词表项开放指的就是除了用散列函数以外还能用其他的方式将关键字分配到表项中
即 Hi = (H(key) + di) % m
di指的是增量序列,指的是发生冲突后进行后调整时取的参数
%m是为了向后调整关键字存储位置时如果遇到表尾能跳到表头重新寻找
这种方法根据增量的不同取法可以分为四种处理方法:
1,线性探测法
也就是调整冲突时每次向后移一位(di = i-1),直到找到一个空闲单元
这种方法的缺点显而易见,当在i处冲突的关键字存储到i+1处时,原本要存储在i+1处的元素就会被挤走而不得不再找别的空闲单元,这样一方面比较繁杂,另一方面会使大量元素堆积在一段相邻的散列地址上,从而使查找效率降低
2.平方探测法
和上面的思路相同,只不过是增量序列取的是 di = ±n^2,(n=1,2,3…m/2)
探测新的空闲单元时,以冲突位置向外逐渐扩大探测范围,探测距离都是整数的平方
±指的是探测时交替向两个方向探测
其优点是:解决了线性探测法中的元素堆积问题,但是以平方为距离探测时,会有些散列表单元永远都探测不到。但是能保证至少能探测到一半的单元
3.双散列法
di = Hash2(key)
其实用另一种散列函数来取探测时的增量序列
4.伪随机序列法
用伪随机数来生成di

拉链法就是在同一个位置挖坑增加纵深,用这种方法在一个位置存储相互冲突的多个关键词。
3.散列表的查找过程以及性能分析
查找过程:
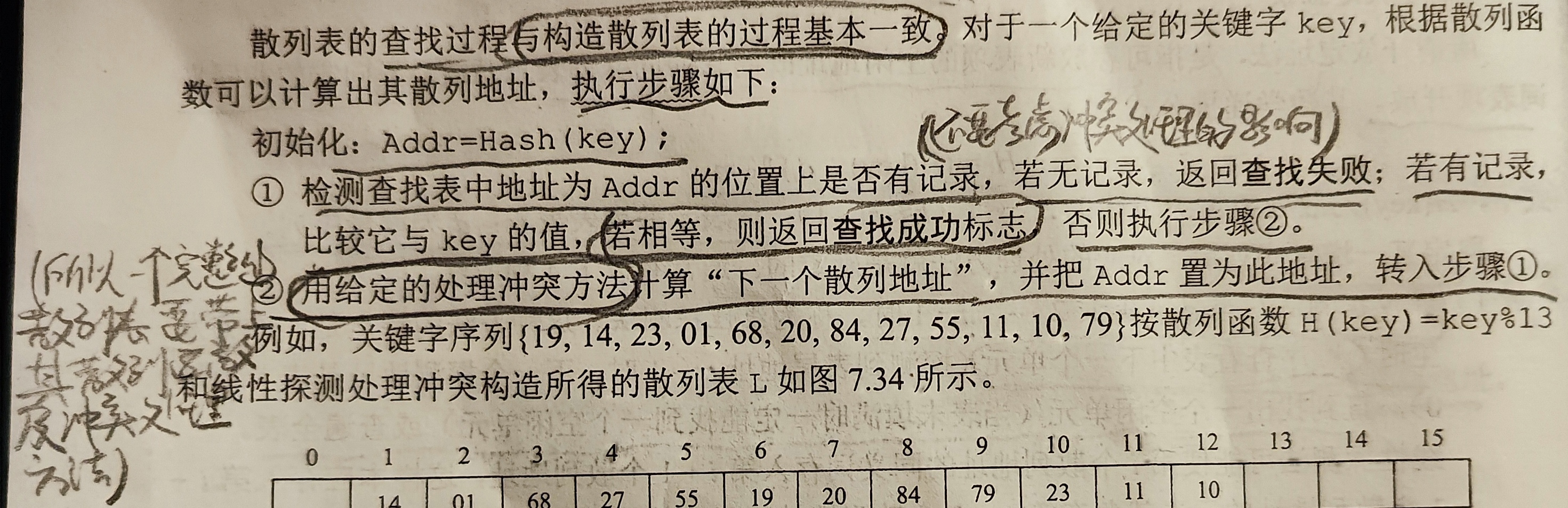
性能分析:(平均查找长度)

由此看出散列表的平均查找长度只能特殊地逐个分析(因为只有散列表构造完成后才能知道其装填因子)。