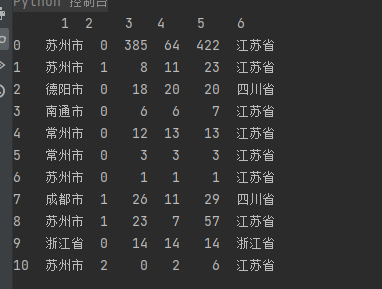
pandas - pd.DataFrame()的基本操作
数据
import pandas as pd data = [ {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 385, '确定安装': 64, '预计安装': 422, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 8, '确定安装': 11, '预计安装': 23, '省份': '江苏省'}, {'DEPT_NAME': '德阳市', '项目类型': '0', '已经安装': 18, '确定安装': 20, '预计安装': 20, '省份': '四川省'}, {'DEPT_NAME': '南通市', '项目类型': '0', '已经安装': 6, '确定安装': 6, '预计安装': 7, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 12, '确定安装': 13, '预计安装': 13, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 3, '确定安装': 3, '预计安装': 3, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 1, '确定安装': 1, '预计安装': 1, '省份': '江苏省'}, {'DEPT_NAME': '成都市', '项目类型': '1', '已经安装': 26, '确定安装': 11, '预计安装': 29, '省份': '四川省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 23, '确定安装': 7, '预计安装': 57, '省份': '江苏省'}, {'DEPT_NAME': '浙江省', '项目类型': '0', '已经安装': 14, '确定安装': 14, '预计安装': 14, '省份': '浙江省'}, {'DEPT_NAME': '苏州市', '项目类型': '2', '已经安装': 0, '确定安装': 2, '预计安装': 6, '省份': '江苏省'} ] # 将数据转换为数据框 df = pd.DataFrame(data)

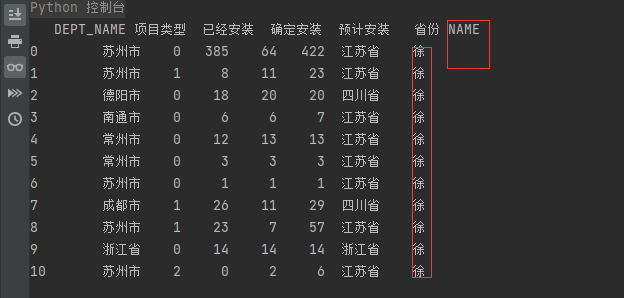
1.想在添加一列数据
df['NAME'] = ('徐') # 默认添加到最后
print(df)
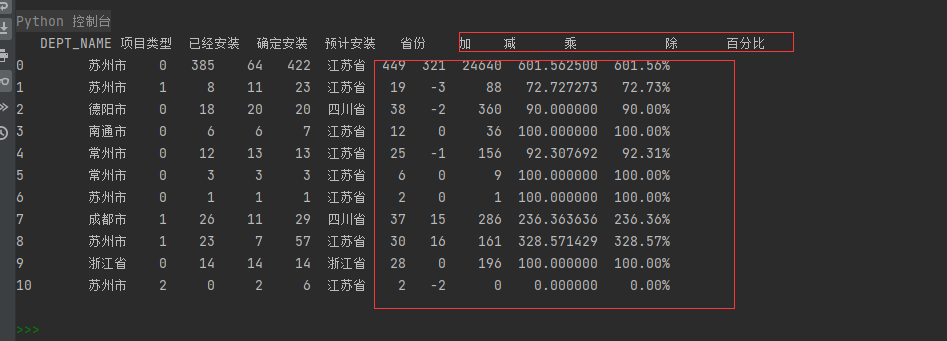
2.想对数据进行操作:加减乘除 ,并把数据保存在数据框架中(df)
# 将数据转换为数据框 df = pd.DataFrame(data) # 加 df['加'] = (df['已经安装'] + df['确定安装']) # 减 df['减'] = (df['已经安装'] - df['确定安装']) # 乘 df['乘'] = (df['已经安装'] * df['确定安装']) # 除 df['除'] = (df['已经安装'] / df['确定安装'])*100 # 转换为 % 格式 df['百分比'] = df['除'].apply(lambda x: "{:.2f}%".format(x)) print(df)
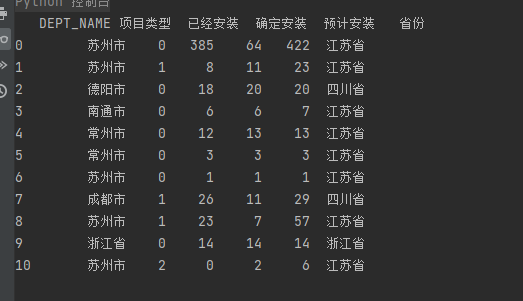
3. df.groupby()函数
pandas中,数据表就是DataFrame对象,分组就是groupby方法。将DataFrame中所有行按照一列或多列来划分,分为多个组,列值相同的在同一组,列值不同的在不同组。
分组后,就得到一个groupby对象,代表着已经被分开的各个组。后续所有的动作,比如计数,求平均值等,都是针对这个对象,也就是都是针对各个组。即在每个组组内进行计数,求平均值等
import pandas as pd data = [ {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 385, '确定安装': 64, '预计安装': 422, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 8, '确定安装': 11, '预计安装': 23, '省份': '江苏省'}, {'DEPT_NAME': '德阳市', '项目类型': '0', '已经安装': 18, '确定安装': 20, '预计安装': 20, '省份': '四川省'}, {'DEPT_NAME': '南通市', '项目类型': '0', '已经安装': 6, '确定安装': 6, '预计安装': 7, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 12, '确定安装': 13, '预计安装': 13, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 3, '确定安装': 3, '预计安装': 3, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 1, '确定安装': 1, '预计安装': 1, '省份': '江苏省'}, {'DEPT_NAME': '成都市', '项目类型': '1', '已经安装': 26, '确定安装': 11, '预计安装': 29, '省份': '四川省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 23, '确定安装': 7, '预计安装': 57, '省份': '江苏省'}, {'DEPT_NAME': '浙江省', '项目类型': '0', '已经安装': 14, '确定安装': 14, '预计安装': 14, '省份': '浙江省'}, {'DEPT_NAME': '苏州市', '项目类型': '2', '已经安装': 0, '确定安装': 2, '预计安装': 6, '省份': '江苏省'} ] # 将数据转换为数据框 df = pd.DataFrame(data)
# 进行分组操作。
单条件: df.groupby('省份') 单条件不用[]
多个条件: df.groupby(['省份','DEPT_NAME']) # 多个条件并别关系
grouped = df.groupby(['省份', 'DEPT_NAME'])
for province, group in grouped:
print(group)

后续所有的动作,比如计数,求平均值等,都是针对这个对象,也就是都是针对各个组。即在每个组组内进行计数,求和等
4.agg()函数
result1 = df1.groupby('省份').agg({'DEPT_NAME': 'count', '预计安装': 'sum', '确定安装': 'sum', '已经安装': 'sum'}).reset_index() # 把需要计算的的列和运算方法,放在{'key1':'value2','key2';'value2'}中
'count' # 统计
'sum' # 求和
后续待补充

修改数据列的列名字:
columns
result1.columns = ['1', '2', '3', '4', '5'] # 数据中有多少列就需要准备多少个名字,不然会报错

import pandas as pd data = [ {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 385, '确定安装': 64, '预计安装': 422, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 8, '确定安装': 11, '预计安装': 23, '省份': '江苏省'}, {'DEPT_NAME': '德阳市', '项目类型': '0', '已经安装': 18, '确定安装': 20, '预计安装': 20, '省份': '四川省'}, {'DEPT_NAME': '南通市', '项目类型': '0', '已经安装': 6, '确定安装': 6, '预计安装': 7, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 12, '确定安装': 13, '预计安装': 13, '省份': '江苏省'}, {'DEPT_NAME': '常州市', '项目类型': '0', '已经安装': 3, '确定安装': 3, '预计安装': 3, '省份': '江苏省'}, {'DEPT_NAME': '苏州市', '项目类型': '0', '已经安装': 1, '确定安装': 1, '预计安装': 1, '省份': '江苏省'}, {'DEPT_NAME': '成都市', '项目类型': '1', '已经安装': 26, '确定安装': 11, '预计安装': 29, '省份': '四川省'}, {'DEPT_NAME': '苏州市', '项目类型': '1', '已经安装': 23, '确定安装': 7, '预计安装': 57, '省份': '江苏省'}, {'DEPT_NAME': '浙江省', '项目类型': '0', '已经安装': 14, '确定安装': 14, '预计安装': 14, '省份': '浙江省'}, {'DEPT_NAME': '苏州市', '项目类型': '2', '已经安装': 0, '确定安装': 2, '预计安装': 6, '省份': '江苏省'} ] # 将数据转换为数据框 df1 = pd.DataFrame(data) # df1.columns = ['1', '2', '3', '4', '5', '6'] # print(df1)