Java基础复习
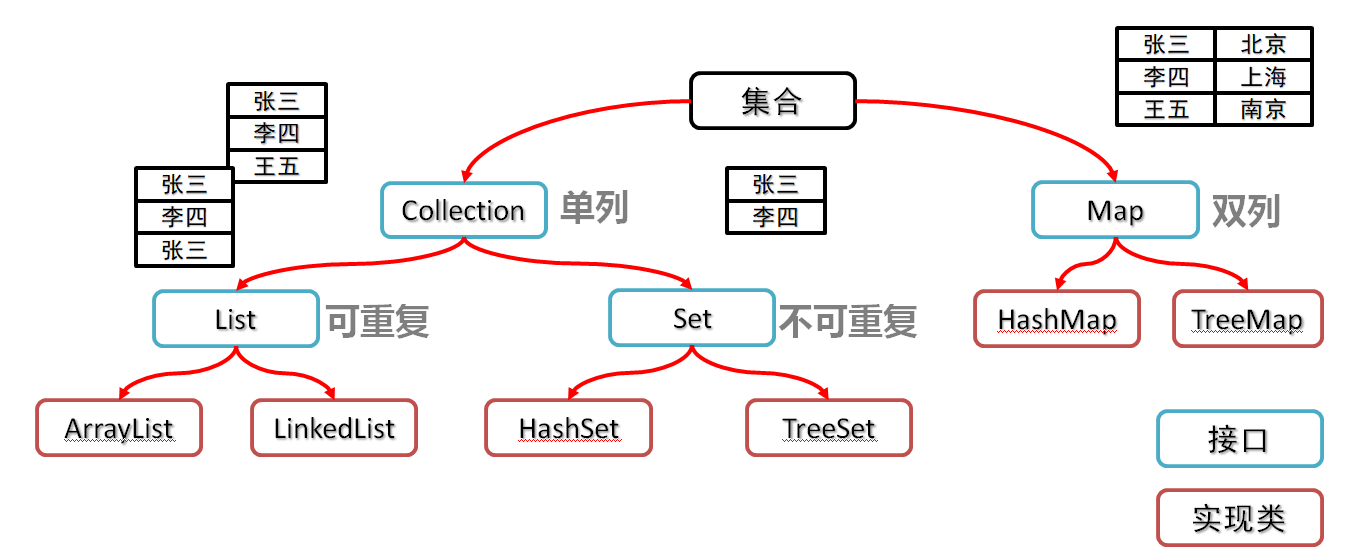
一、Collection集合
-
都是容器,可以存储多个数据
-
不同点
-
数组的长度是不可变的,集合的长度是可变的
-
数组可以存基本数据类型和引用数据类型
-
-
迭代器,集合的专用遍历方式
-
Iterator<E> iterator(): 返回此集合中元素的迭代器,通过集合对象的iterator()方法得到
-
-
Iterator中的常用方法
boolean hasNext(): 判断当前位置是否有元素可以被取出 E next(): 获取当前位置的元素,将迭代器对象移向下一个索引位置
-
public class IteratorDemo1 { public static void main(String[] args) { //创建集合对象 Collection<String> c = new ArrayList<>(); //添加元素 c.add("hello"); c.add("world"); c.add("java"); c.add("javaee"); //Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到 Iterator<String> it = c.iterator(); //用while循环改进元素的判断和获取 while (it.hasNext()) { String s = it.next(); System.out.println(s); } } }
增强for循环【应用】
-
-
它是JDK5之后出现的,其内部原理是一个Iterator迭代器
-
实现Iterable接口的类才可以使用迭代器和增强for
-
简化数组和Collection集合的遍历
-
-
格式
for(集合/数组中元素的数据类型 变量名 : 集合/数组名) {
// 已经将当前遍历到的元素封装到变量中了,直接使用变量即可
}
- 代码
public class MyCollectonDemo1 { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.add("e"); list.add("f"); //1,数据类型一定是集合或者数组中元素的类型 //2,str仅仅是一个变量名而已,在循环的过程中,依次表示集合或者数组中的每一个元素 //3,list就是要遍历的集合或者数组 for(String str : list){ System.out.println(str); } } }
-
栈结构
先进后出
-
队列结构
先进先出
数据结构之数组和链表【记忆】
-
数组结构
查询快、增删慢
-
队列结构
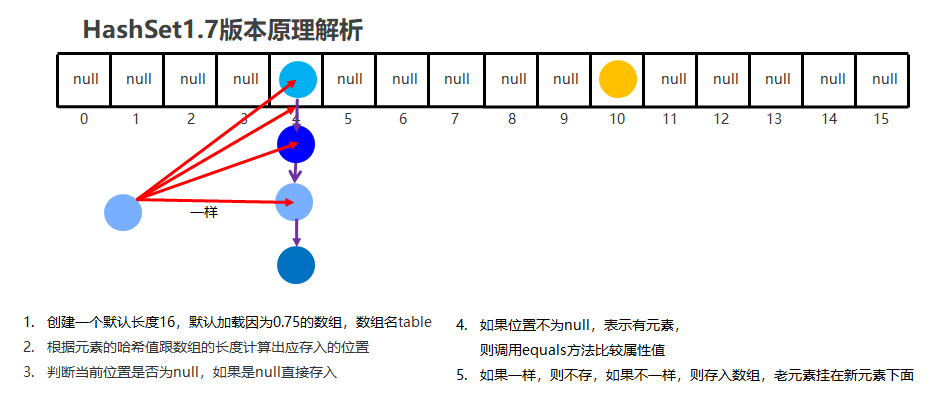
哈希值【理解】
-
是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
-
如何获取哈希值
Object类中的public int hashCode():返回对象的哈希码值
-
哈希值的特点
-
同一个对象多次调用hashCode()方法返回的哈希值是相同的
-
-
-
节点个数少于等于8个
数组 + 链表
-
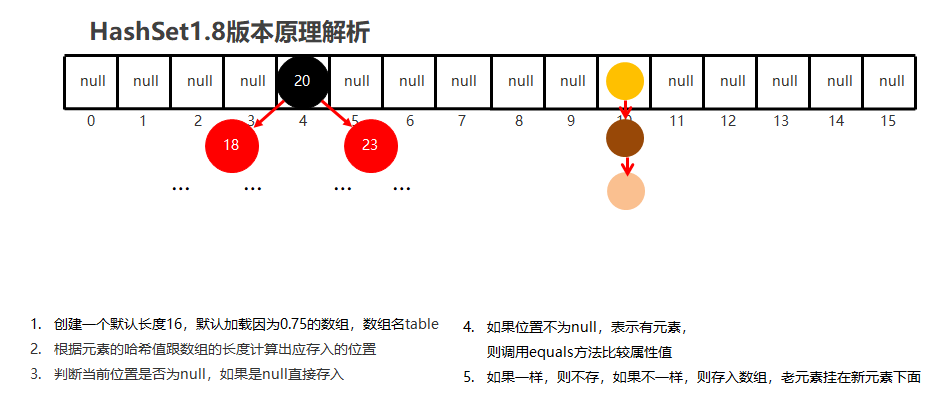
节点个数多于8个
1.1、List集合子类的特点【记忆】
-
ArrayList集合
底层是数组结构实现,查询快、增删慢
-
LinkedList集合
2.1、Set集合概述和特点【应用】
-
不可以存储重复元素
-
没有索引,不能使用普通for循环遍历
2.2、TreeSet集合概述和特点【应用】
-
不可以存储重复元素
-
没有索引
-
可以将元素按照规则进行排序
-
TreeSet():根据其元素的自然排序进行排序
-
-
2.3、HashSet集合概述和特点【应用】
-
底层数据结构是哈希表
-
存取无序
-
不可以存储重复元素
-
没有索引,不能使用普通for循环遍历
3.1、Map集合概述和特点【理解】
-
Map集合概述
interface Map<K,V> K:键的类型;V:值的类型
- Map集合的特点
- 双列集合,一个键对应一个值
- 键不可以重复,值可以重复
-
HashMap底层是哈希表结构的
-
依赖hashCode方法和equals方法保证键的唯一
-
-
TreeMap底层是红黑树结构
-
依赖自然排序或者比较器排序,对键进行排序
-
interface Map<K,V> K:键的类型;V:值的类型