22207334-章莲祥第一次博客
一、前言
对于这三次作业的知识点来讲我认为是相当密集的,无论是第一次作业中有无参构造方法、类和对象的使用和字符串的接收处理和输出,又或是往后的第二三次作业,都让我在思考中学到了很多。就题量来讲的话,基础类的题较多,难题虽少但是确实够难,
题量上的设置在我看来还是合理的。难度的话对我个人来说还是较大,对java中面向对象的思想还不是很能熟练运用,比如在一次大作业的时候对类的设置就没有设好,导致后续花了很长时间来精简代码。总体来说这三次作业的质量还是蛮高,我也从中学到了很多。
二、第一次作业
在第一题设计一个风扇Fan类的过程中,了解到了有参构造和无参构造的区别,无参构造默认参数相较于有参构造还是太死板,不过可以用来快速判断对象是否创建。
第三题成绩计算-1-类、数组的基本运用,一开始对输入样例里的
22201311 张琳 80 80 80
22201312 黄昊 66 82 81
22201313 李少辰 77 76 80
22201314 袁婷 62 79 90
22201315 朱哲一 74 98 94
一大串学号、姓名还有各科成绩不知道怎么去接收处理,想去用数组但无法把不同人的各科成绩分开来,后面网上查了一下了解到了字符串的split分割方法,于是便用这个方法来分开数据
Student[] students = new Student[5];
for (int i = 0; i < 5; i++) {
String[] input = scanner.nextLine().split(" ");
students[i] = new Student(input[0], input[1], Integer.parseInt(input[2]), Integer.parseInt(input[3]), Integer.parseInt(input[4]));
}
首先创建students 数组存储五个学生对象,为后面接收数据构造Student对象做准备,
String[] input = scanner.nextLine().split(" ");这一句首先是一行一行接收,然后又以空格切割,完美的提取出了每个学生的各项数据,让后面创建学生对象都不需做什么处理直接就new。
第四题成绩计算-2-关联类是在第三题的基础上添加两个方法,一个计算总成绩的方法和一个计算总分的方法,这题思路上没问题,但是一开始没看到各科分数计算规则定义
错了方法导致了几次错误提交;这题有一个小难点在于怎么把字符串转为浮点数而且还要实现四舍五入:
String formattedOutput = String.format("%s %s %d %.2f %.2f %.2f\n", id, name, all, avr_sim, avr_end, avr);
在网上搜索了解到了String.format方法来转化字符串
import java.math.BigDecimal;
import java.math.RoundingMode;
导入了数学的两个库,使用库里的方法比自己实现要省了不少功夫,这也是java的优势的体现吧
BigDecimal bd = new BigDecimal(re);
bd = bd.setScale(2, RoundingMode.HALF_UP); // 设置小数点后两位并四舍五入
Pattern pattern = Pattern.compile("#(.*?):"); Matcher matcher = pattern.matcher(responseLine); while (matcher.find()) { // 提取响应并追加到responseSheet String response = matcher.group(1).trim(); // 假设有一个方法appendResponse来处理响应 responseSheet.appendResponse(response); }一开始使用正则表达式来接收,但是发现这样分割出来的答案会时多一个符号时少一个答案,调试了很久没找出问题后面还是采取了分割的方法
String[] responseSegments = responseLine.split("#");
for (int j = 1; j < responseSegments.length; j++) {
String response = responseSegments[j].split(":")[1].trim();
responseSheet.appendResponse(response);
三、第二次作业
第一题 手机按价格排序、查找的题目中使用到了Collections类的sort方法,这又是一个对链表对象快速排序的高效方法:
Collections.sort(phones);
排序之后再遍历一遍链表
public int compareTo(MobilePhone other) { return Integer.compare(this.price, other.price); }
在第一次大作业代码问题类、答卷类、答案类基础上添加一个分值类,它的作用是判分生成记录答案等。但是这个类的功能实现起来很困难,因为它包含了三个类,需要调用不同的方法来实现判分。
不过一开始的版本中对输入的处理做的比较好,
if (line.startsWith("#N:")) {
// Process question input
String[] parts = line.split(" ", 3);
if (parts.length < 3) continue;
int id = Integer.parseInt(parts[0].substring(3));
String content = parts[1].substring(3);
String answer = parts[2].substring(3);
grader.addQuestion(new Question(id, content, answer));
先对#后的符号判断来判断输入给哪个类,然后按空格分三部分,再分别处理。这样可以高效的处理输入的数据。
使用Grader类实现功能时第一个输入样例总过不去,于是后面完善了一下processAnswers()答案处理判分函数。
for (Map.Entry<Integer, Integer> entry : testPaper.questionsAndScores.entrySet()) {
Question question = questions.get(entry.getKey());
String answer = getAnswerByIndex(answerSheet.answers, entry.getKey());
boolean isCorrect = answer != null && answer.equals(question.answer);
int score = isCorrect ? entry.getValue() : 0;
totalScore += score;
在for循环里先逐个提取出问题与答案,然后使用equals方法判断正误,返回一个boolean结果用于打印输出,同时true就加入总分里。
String outputAnswer = answer != null && answer.startsWith("#A:") ? answer.substring(3) : answer;
// Output the question content and the answer
System.out.println(question.content + "~" + outputAnswer + "~" + (isCorrect ? "true" : "false"));
之前读取答案过程中总是把" #A"给读取进来,总而导致每次判题的时候对的也能判成错的。声明一个outputAnswer来接收过滤掉" #A"的答案再比较。
在进行了诸多改进之后,到了样例5乱序输入的情况下我的接收逻辑又出现错误了,参照检测点11 12做出了改进:
打印警报信息:在处理测试卷的最大分数时,增加了输出具体测试卷 ID 的警告信息,以便于识别是哪个测试卷的问题。
System.out.println("alert: full score of test paper" + testPaper.id + " is not 100 points");
答案输出处理:在输出答案时,检查答案是否为 null,并提供相应的输出,防止程序尝试打印 null 值。
if (answer == null){
System.out.println(question.content + "~" + "answer is null" + "~false");
}
else {
System.out.println(question.content + "~" + outputAnswer + "~" + (isCorrect ? "true" : "false"));
}
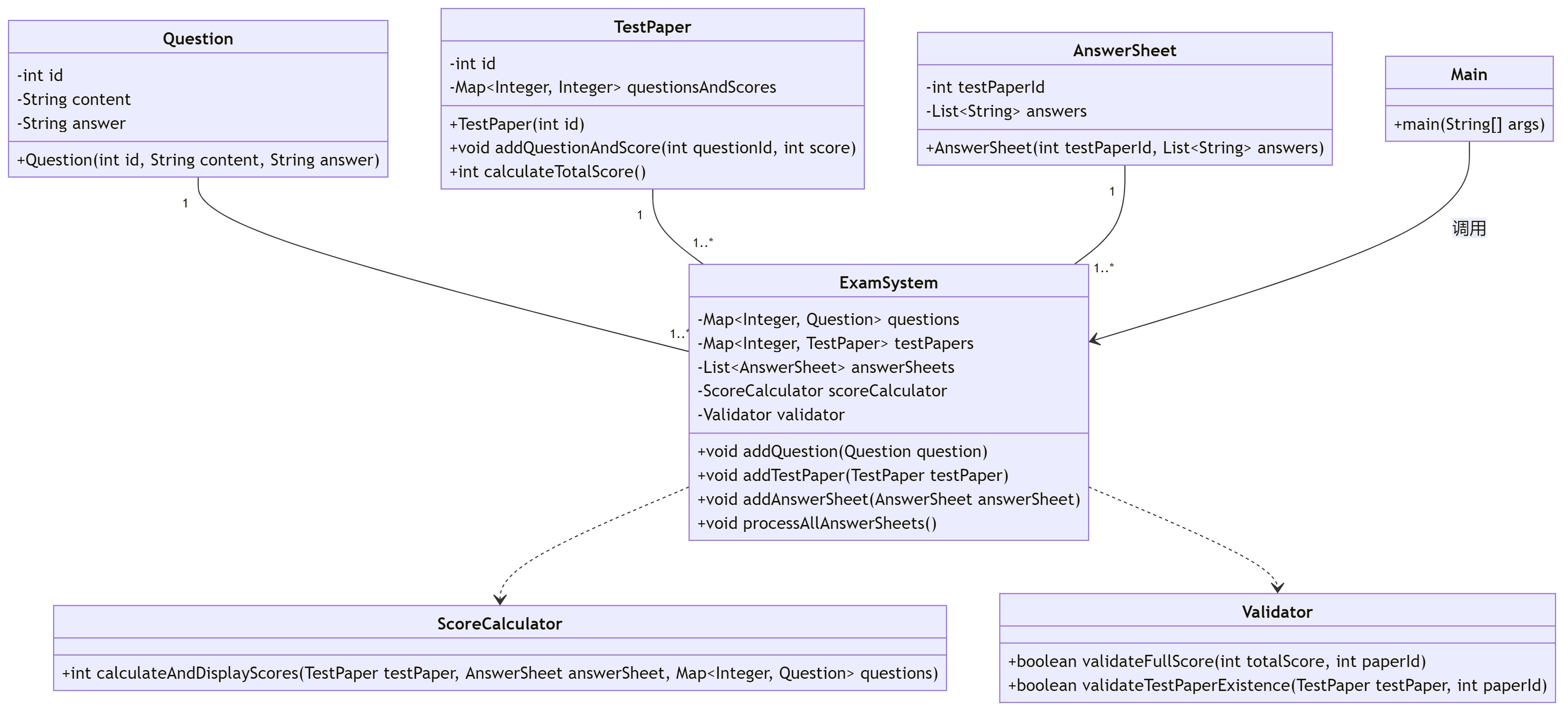
新的类设计中新增了验证器类Validator和记分器类ScoreCalculator ,同时不再由Main来调用这些类而是新建了一个考试系统类ExanSystem来调用这些方法,这样Main类只需处理用户输入已经调用系统了,
代码逻辑更加清晰了。
验证器类Validator中包含两个验证方法validateFullScore和validateTestPaperExistence 分别用来验证试卷是否满分和试卷是否存在(可能被删除)。
记分器类ScoreCalculator包含一个计分方法calculateAndDisplayScores,这个方法能输出每道题的得分以及总分,它的核心代码如下:
System.out.println(question.content + "~" + (answer != null ? answer : "answer is null")
+ "~" + isCorrect);
scoresPerQuestion.add(score);
questionIndex++;
考试系统类ExanSystem需要调用并且存储各类链表对象:
private Map<Integer, Question> questions = new HashMap<>();
private Map<Integer, TestPaper> testPapers = new HashMap<>();
private List<AnswerSheet> answerSheets = new ArrayList<>();
private ScoreCalculator scoreCalculator = new ScoreCalculator();
private Validator validator = new Validator();
类开头就创建存储各个不同对象的私有链表。
核心方法processAllAnswerSheets:
for (AnswerSheet answerSheet : answerSheets) {
TestPaper testPaper = testPapers.get(answerSheet.testPaperId);
if (!validator.validateTestPaperExistence(testPaper, answerSheet.testPaperId)) {
continue;
}
int maxPossibleScore = testPaper.calculateTotalScore();
validator.validateFullScore(maxPossibleScore, testPaper.id);
- 外层的
for循环遍历answerSheets列表,这个列表包含了所有的AnswerSheet对象,每个对象代表一个学生的答卷。 - 对于每个
AnswerSheet对象,通过answerSheet.testPaperId来获取对应的TestPaper对象。testPapers是一个映射,它根据试卷的 ID 存储对应的TestPaper对象。 - 接下来,使用
validator对象的validateTestPaperExistence方法来检查是否存在对应的TestPaper对象。如果TestPaper对象不存在(即testPaper为null),则打印一条消息并使用continue语句跳过当前循环,继续处理下一个AnswerSheet对象。 - 如果
TestPaper对象存在,就调用它的calculateTotalScore方法来计算该试卷的总分。 - 然后,使用
validator对象的validateFullScore方法来检查试卷的总分是否为100分。如果总分不是100分,打印一条警告消息。
这段代码的目的是确保每个学生的答卷都与一个有效的试卷相关联,并且该试卷的总分符合预期(在这个例子中是100分)。如果有任何不一致,它会打印相应的消息并继续处理下一个学生的答卷。
四、第三次大作业
第三次大作业在第二次作业的基础上多了很多检测点,同时第三次大作业中开始对含错误格式输入、有效删除以及无效题目引用信息、含错误格式输入、有效删除、无效题目引用信息以及答案没有输入、
输入的优先级、无效的试卷符号引用、信息输入顺序、答卷顺序输出这几个方面设置了输入输出样例。在第二次大作业我的类设计中这些都是不曾考虑进来的,因此在第二次大作业基础上写这次作业让我
很痛苦,于是我开始重新设计类结构。初始类图如下:

初始类图设计相当简单,考虑必须的三个类以外添加了Student类和TestSystem类,其中的TestSystem类中需要实现创建删除题目、检查题目顺序、判分输出等功能,
deleteQuestion方法一开始使用的是标记被删除的题号,将其存放于questions数组中
if (questions.containsKey(questionNumber)) {
// 从题目集合中删除
questions.remove(questionNumber);
System.out.println("Question " + questionNumber + " has been deleted.");
TestSystem类中比较核心的方法handleAnswerSheet用来处理学生提交的答题卡。通过检查试卷和学生是否存在,解析每道题的答案并记录。调用 evaluateAnswerSheet 方法对答题卡进行判分:
for (String ans : answers) {
String[] parts = ans.split("-");
if (parts.length != 2) {
System.out.println("wrong format:" + ans);
continue;
}
try {
int questionOrder = Integer.parseInt(parts[0].substring(3)); // 提取顺序号
String answer = parts[1].trim();
answerSheet.addAnswer(questionOrder, answer);
} catch (Exception e) {
System.out.println("wrong format:" + ans);
}
该代码实现的逻辑:
-
遍历学生提交的答案 (
answers):answers是一个String[]数组,每个元素是一个题目的答案,格式为"顺序号-答案",例如"Q01-A"。
-
解析答案格式:
String[] parts = ans.split("-");
这行代码通过"-"分割字符串,将每个题目的信息分成两部分:题目的顺序号和学生的答案。parts[0]:题目顺序号(如"Q01")。parts[1]:学生给出的答案(如"A")。
-
检查格式是否正确:
if (parts.length != 2):检查分割后的数组是否有两个部分,如果不等于2,说明格式有误。- 如果格式不正确,则输出
"wrong format"并跳过当前答案的处理。
-
提取题目顺序号:
int questionOrder = Integer.parseInt(parts[0].substring(3));
这里通过substring(3)提取题目的顺序号(去掉前缀,如"Q01"中的"Q",保留数字"01")。然后,将其转化为整数。- 假设题号格式为
"Q01",substring(3)提取出的是"01",然后转化为整数1。
- 假设题号格式为
-
提取并处理学生的答案:
String answer = parts[1].trim();
提取分割后的答案部分,并使用trim()去除首尾的空格,防止意外的空白字符。
-
将题目顺序号和答案存入答题卡:
answerSheet.addAnswer(questionOrder, answer);
将提取到的题目顺序号和答案添加到AnswerSheet中。
-
错误处理:
- 如果在提取顺序号或答案过程中出现异常(例如,题号格式不对导致无法转换为整数),会捕获异常,并输出
"wrong format"错误信息
- 如果在提取顺序号或答案过程中出现异常(例如,题号格式不对导致无法转换为整数),会捕获异常,并输出
然而实际运行上这段代码并未通过格式检查点,这个问题出在异常处理以及格式判断的缺乏。
TestSystem类中另一核心的方法evaluateAnswerSheet用来根据试卷的题目顺序和分值判分。跳过已删除题目或不存在的题目,空答案会给出提示。判分完成后,输出学生的总分情况。
遍历题目判分代码:
for (Map.Entry<Integer, Integer> entry : testPaper.questionsWithPoints.entrySet()) {
int questionNumber = entry.getKey();
int points = entry.getValue();
// 判断题目是否被删除
if (deletedQuestions.contains(questionNumber)) {
System.out.println("the question " + questionNumber + " invalid~0");
continue; // 跳过后续逻辑
}
// 判断题目是否不存在
if (!questions.containsKey(questionNumber)) {
System.out.println("non-existent question~0");
continue; // 跳过后续逻辑
}
// 获取学生的答案
String studentAnswer = answerSheet.answers.getOrDefault(questionNumber, "");
Question question = questions.get(questionNumber);
// 优先判断答案是否为空
if (studentAnswer.isEmpty()) {
System.out.println(question.content + "~answer is null");
} else {
boolean isCorrect = studentAnswer.equals(question.correctAnswer);
System.out.println(question.content + "~" + studentAnswer + "~" + isCorrect);
if (isCorrect) {
totalScore += points; // 只有在答案正确时才加分
}
}
}
该代码实现逻辑:
-
遍历试卷中的每个题目:
- 通过
testPaper.questionsWithPoints.entrySet()遍历试卷中的每一道题目及其对应的分值。 entry.getKey():获取题目的编号 (questionNumber)。entry.getValue():获取题目的分值 (points)。
- 通过
-
检查题目是否已删除:
if (deletedQuestions.contains(questionNumber)):判断当前题目是否在deletedQuestions集合中,即是否已被删除。- 如果已删除,则输出
"the question {questionNumber} invalid~0",并跳过该题的评估。
-
检查题目是否不存在:
if (!questions.containsKey(questionNumber)):判断当前题目是否存在于questions集合中。如果不存在,表示题目无效。- 输出
"non-existent question~0",并跳过该题的评估。
-
获取学生的答案:
String studentAnswer = answerSheet.answers.getOrDefault(questionNumber, "");
从answerSheet中获取学生针对当前题目的**。如果学生没有答该题,默认返回空字符串。
-
判断学生答案是否为空:
if (studentAnswer.isEmpty()):检查学生是否未对该题作答。- 如果答案为空,输出题目的内容以及
"answer is null"以提示学生未作答。
-
判断答案是否正确:
boolean isCorrect = studentAnswer.equals(question.correctAnswer);
比较学生的答案和题目的正确答案,判断是否匹配。- 输出当前题目的内容、学生的答案以及是否正确的布尔值。
- 正确答案加分:如果答案正确,则累加对应题目的分值到总分
totalScore。
-
对已删除题目处理的改进:
- 目前直接在评估时跳过已删除题目,但实际上删除题目时可以在
deletedQuestions中直接更新或移除题目的相关数据,避免在评估时每次都检查。
- 目前直接在评估时跳过已删除题目,但实际上删除题目时可以在
-
对不存在题目的处理逻辑:
- 如果某个题目不存在但依然出现在试卷中,可能是数据管理上的问题。在
addTestPaper时,可以对题目编号的有效性进行验证,而不是在评估时发现问题。
- 如果某个题目不存在但依然出现在试卷中,可能是数据管理上的问题。在
-
答案为空的处理:
- 如果学生未作答,可以选择在最终的得分报告中专门列出未答题目,而不仅仅在评估过程中的输出中显示。
-
答案判定的改进:
- 目前的答案判定是精确匹配
equals,如果允许部分匹配或对大小写不敏感,可以改用equalsIgnoreCase或自定义匹配逻辑。
- 目前的答案判定是精确匹配
-
输出的信息量:
- 每道题目的评估结果都逐个输出,可能在处理大规模答卷时显得繁琐。可以考虑将详细的题目评估记录到日志文件中,而只在控制台输出总成绩或错误信息
// 判断题目是否被删除
if (deletedQuestions.contains(questionNumber)) {
System.out.println("the question " + questionNumber + " invalid~0");
continue; // 跳过后续逻辑
}
// 判断题目是否不存在
if (!questions.containsKey(questionNumber)) {
System.out.println("non-existent question~0");
continue; // 跳过后续逻辑
}
这个逻辑将被删除题目的题号包含在deletedQuestions数组中,并且在判分的时候遍历数组,如果已被删除则 continue; // 跳过后续逻辑并输出"the question " + questionNumber + " invalid~0",这使我通过了检测点9和11对无效题目的处理。
大作业3我完成的并不理想,一来是类的设计太简单,二来是对于题目中提到的对含错误格式输入、有效删除以及无效题目引用信息、含错误格式输入、有效删除、无效题目引用信息以及答案没有输入、
输入的优先级、无效的试卷符号引用、信息输入顺序、答卷顺序输出这几个方面都没有进行处理,这是我个人面向对象思想还没有理解的体现,在后面的学习中我得认真去攻克这些方面了。
五、总结
在过去的三次作业中,我经历了从基础到高级的Java编程实践,这些作业不仅加强了我的编程技能,也加深了我对面向对象编程(OOP)的理解。以下是我的主要收获和反思:
-
基础建设与概念理解:
- 我学习了如何使用构造方法来初始化对象状态,体会到了无参构造方法在对象创建中的便捷性及其局限性。
- 通过实际操作,我掌握了类和对象的使用,如何利用
toString()和printInfo()等方法来输出对象信息,这让我对OOP有了更直观的认识。
-
数据处理与类设计:
- 我通过处理字符串输入和数组操作,学会了如何将复杂的数据结构分解为可管理的部分,这对我的编程逻辑有很大帮助。
- 我意识到了类设计的重要性,一个良好的类设计可以大大简化代码的复杂性,提高代码的可维护性。
-
面向对象的深入应用:
- 在处理更复杂的编程任务时,我学会了如何使用类来封装数据和行为,如何通过方法来实现具体的功能。
- 我认识到了代码重构的必要性,随着对问题理解的深入,我不断调整和优化我的类结构,以适应新的需求和挑战。
-
错误处理与有效性验证:
- 我学会了如何对输入数据进行有效性验证,以及如何处理错误和异常情况,这对于编写健壮的程序至关重要。
- 我意识到了在设计类和方法时需要考虑的边界情况和潜在的错误,这让我的代码更加健壮和可靠。
-
代码优化与重构:
- 我通过不断的实践,学会了如何识别和重构冗余代码,如何通过提取公共代码来简化程序结构。
- 我认识到了代码优化的重要性,不仅仅是为了提高性能,更是为了提高代码的可读性和可维护性。
-
面向对象思想的深入:
- 我深刻体会到了面向对象编程的核心思想,如封装、继承和多态,这些概念在我的编程实践中逐渐变得清晰。
- 我意识到了面向对象不仅仅是一种编程范式,更是一种思考问题和解决问题的方式。
通过这三次作业,我不仅提升了自己的编程技能,也学会了如何更好地组织和管理复杂的代码。我认识到了自己在面向对象编程方面的不足,并决心在未来的学习中加以改进。我相信,随着实践经验的积累,我将能够更加自信地应用这些概念,并在软件工程领域取得更大的进步。