java大作业pta1-3总结性Blog
第一次大作业:
题目要求:一个答题程序,根据输入的题目和回答,判断回答是否正确
输入格式:
- 首先是输入题目个数;
- 对于题目的输入,格式为"#N:"+题号+" "+"#Q:"+题目内容+" "#A:"+标准答案;
- 对于回答的输入,格式为"#A:"+答案内容;
- end标记结束,end之后信息忽略;
输出格式:将题目内容和回答的答案按照输入的回答按照与题号相对应的顺序,格式为题目内容+" ~"+答案,一条答题信息为一行,输出所有答题信息后,将判题信息以题号的顺序,格式为判题结果+" "+判题结果+......输出,判题结果输出只可能时true或者false
对于上述题目,我做了以下类图:
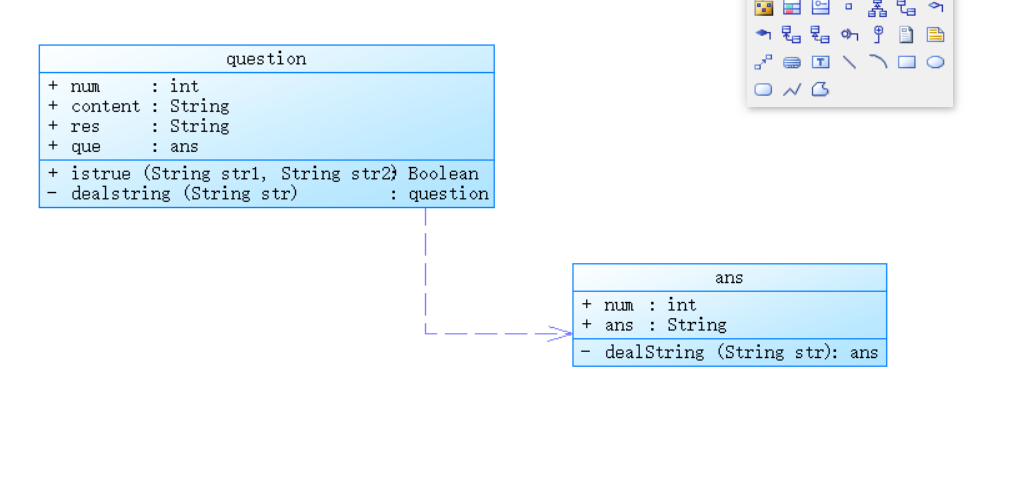
首先是question,用于存储题目类,num为题目题号,content为题目的内容,res为题目标准答案,que是该题所对应的回答;函数istrue用于判断题目的正确答案与回答是否相同,dealstring对应的是处理题目类的字符串:
import java.util.*; public class Question { private question dealstring(String str) { return null; } public int num; public int content; public int res; public ans que; }
对于ans类,num用于存储题号,ans用于存储对应题号对应的答案,dealstring是处理答案类的字符串,返回的是ans类:
import java.util.*; public class Ans { public int num; public String ans; }
主函数的逻辑顺序:主函数设计在question类中。首先定义一个question类数组,进入输入题目循环后,接收一行的字符串,然后传入question类中的dealstring进行处理数据,处理数据我主要用到了字符串中split,具体处理方式如下代码:
temp=temp.substring(3); String[] ss=temp.split("#"); ss[0]=ss[0].replaceAll(" ",""); int code= Integer.parseInt(ss[0]); String content= xx.consolve(ss[1]).trim(); String res=xx.ressolve(ss[2]).trim(); x[code]=new Question(code,content,res); //System.out.println(code+content+res);
其中temp为输入代码,x为我定义的question类数组,code为题号,content为题内容,res为题标答。
循环结束后输入字符串一行,为所有答案,然后传入ans类,对这行字符串进行处理,具体处理代码如下:
ans=ans.substring(3); //System.out.println(ans); String[] wohaolei=ans.split(" #A:");
利用循环将回答者的答案存储到question类中的定义的que里;
然后回到主函数,进入istrue函数开始比对,定义一个String类型的judge,将题目和回答者的答案按格式输出,如果比对的代码相同则字符串+true,否则+false:
if(m.istrue(x[i - 1].que.ans , x[i].res)) judge+="true"; else judge+="false"; if(i!=n)judge+=" ";
至此,答题判题程序的基本逻辑就完成了。
踩坑:最开始写了一堆但没看到题目输出顺序要按照题号,然后就是,确实应该多写注释,回看我之前没有写注释的代码,已经是看不懂的状态了。
改进:一开始提交的那个版本只有一个main函数所有逻辑都在里面,之后将那一大坨分成了两个类,望之后写题注重面向对象,多分类,如果命名没有用相关的英文的话,那一定要写注释,不要用太多单字母的变量,回看代码真的看不懂。
第二次大作业
题目要求:在大作业1基础上输入方面增加了试卷号题号分值的信息,输出方面增加了将各题得分的情况和总分数输出,并且对于试卷题目数量答卷数量还有答卷总分值增加了约束。
输入格式:
- 无题目数量和答卷数量输入信息,以end结尾表示输入结束。
- 对于题目的输入,格式为"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案,约束条件为题目的输入顺序与题号不相关,且允许题目编号有缺失。
- 对于试卷信息的输入,格式为"#T:"+试卷号+" "+题目编号+"-"+题目分值,一行信息中可能存在多项题目与分值。
- 对于答卷信息的输入,格式为"#S:"+试卷号+" "+"#A:"+答案内容,约束条件为答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略。
输出格式:
一张试卷总分不等于100则输出"alert: full score of test paper"+试卷号+" is not 100 points"。
答卷信息中格式为题目内容+"~"+答案++"~"+判题结果(true/false),如果输入的答案信息少于试卷的题目数量,没有答案信息的题目输"answer is null" ,通俗来说就是多写不管,少写不行。
对于判分,格式为题目得分+" "+....+题目得分+"~"+总分,顺序为试卷中题目的顺序。
如果答案信息中试卷的编号找不到,则输出”the test paper number does not exist”。
对于上述题目,我做了以下类图:
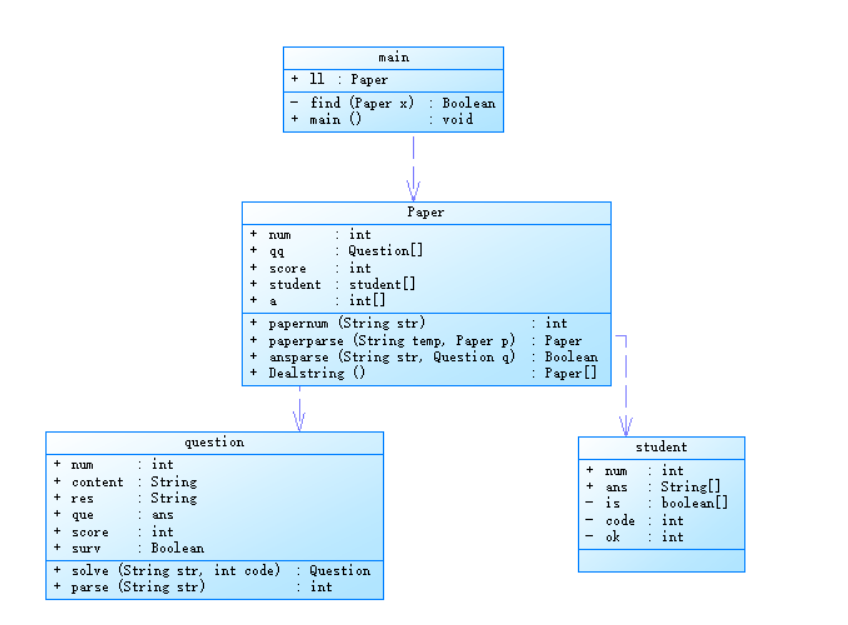
首先main函数里的ll是paper类,存储一张已经批阅完的试卷,find函数是查找该试卷号是否存在,接着是paper类中的num存储试卷号,qq存储这张试卷的所有题目,score存储这张试卷的总分,student存储回答这张试卷的学生,a存储题目号,papernum函数是解析字符串将试卷号信息提取出来,paperpase函数是将这张试卷除了试卷号以外的所有信息解析出来,Dealstring主要是将输入的字符串用正则表达式分类传送到各自处理的函数中去。然后就是question类,num存储题号,content存储题目内容,res存储题目标准答案,socre表示这道题的题分值,surv表示这道题是否存在,solve函数表示将解析字符串中题目的有效信息,parse是将字符串中题目的题目号解析出来,student中num是学生答卷的个数,ans是学生所做试卷所给出的所有答案,is是学生做的这张卷子的批阅情况,code是试卷号,ok是是否答案。类代码部分如下:
question:
class Question{ int num; String res; String content; int score;//题分值 boolean surv;//题目是否存在 public Question(int num,String content,String res){ this.num=num; this.content=content; this.res=res; this.surv=true; } }
paper:
class Paper { int num; // 试卷号 Question[] qq = new Question[101]; // 习题集 int score; // 总分 student[] students; int[] a; public Paper(int num, Question[] qq, student[] students) { this.num = num; this.qq = qq; this.students = students; this.score = 0; this.a = new int[101]; } }
student:
class student{ int num;//答卷个数 String[] ans;//给出的答案 boolean[] is;//是否正确 int code;//试卷号 boolean ok;//是否全部答完 public student(String[] ans,int num){ this.ans=ans; this.num=num; this.is = new boolean[101]; this.ok = false; } }
主函数的主要逻辑:首先先传送到paper类中的dealstring函数中对输入的字符串进行处理,主要利用到了正则表达式
while (!(str = input.nextLine()).equals("end")) { if (Pattern.compile("#N:(\\d+) #Q:(.*?) #A:(\\d+)").matcher(str).matches()) { // 题目 } else if (Pattern.compile("#T:(\\d+) (.+)").matcher(str).matches()) { // 试卷 } else { } }
经过判断后,是题目的话,将传送到question类中的solve函数,将题目的有效信息解析出来,然后返回解析后的题目类,如果是试卷的话,将会把字符串传入paper类中的paperparse提取字符串中的有效信息,然后再把出现过的题目集按照解析出来试卷出现的题目按照题号加入到试卷类中的qq题目集里,然后顺便将这张卷子的分数分值全部加到paper类中的score中。如果是学生的答题信息的话,首先先利用字符串处理的substring获取试卷号,然后判断该试卷是否存在,接着利用字符串梳理split将一长串字符串以“ #A”分来,这样就获取了学生答题的所有答案,然后将正确或者不正确判断的结果写入student类中的is数组里,如果正确,则定义一个sum变量初始化为0,将获取到的试卷号相对应的试卷的题目的分值加上,最后返回paper数组类型的变量回到主函数。
在主函数中,上述为预处理,接下来将所有试卷遍历一遍,如果该试卷的score不满100分则输出
“alert: full score of test paper"+试卷号+" is not 100 points”,然后再次遍历试卷进入每张试卷的处理循环中,将对应写了这张试卷的学生找到后,将题目和对应的答题信息输出,,如果学生并没有回答这道题的话则输出"answer is null",将学生答卷和题目信息输出完后,再将对应的题目的得分值利用student中的is数组输出得分和score输出总分。
至此,答题判题程序2的基本逻辑差不多描述完了。
踩坑:没写注释,我分了两天写,然后第一天没写完,太困了睡觉去了,然后第二天没课的时候开始写,已经不知道自己在写什么了,然后就定义了很多重复的变量,比如判断试卷是否有100分,我第一天定义了一个Boolean类型的变量预处理的判断,第二天感觉第一天好像没写这个判断,于是又写了一个score记录总分等等

这次用到的数组比较多,因为刚开始写的时候是直接上手的,没把题目读全,想着看到什么信息就定义什么变量,结果数组越来越多,到后面预处理结束后主函数输出阶段,我频繁出现了以下一长串代码:

如果只有一两个其实还好,累的是我通篇都是这样的引用。
写到最后的最后手还在引用变量,脑子已经忘记我在干嘛了。
改进:用map代替过多的数组,以及起名字最好起拼音或者英文,反正就是自己到时候能看懂的东西,然后就是多写注释,这次难度比第一次增加,应该先看完整题再开始对代码结构进行思考,而不是边写边看题目。然后就是,因为我第二天看不懂第一天写的代码,当时一着急所以又犯了将大部分逻辑挤在main函数里面,for套for套if套if,希望在之后的大作业里避免出现因看不懂而写形似面向过程的代码,坚持一个功能就多写一个函数,对于一道题,先分析再下手。
第三次大作业
题目要求:在答题判题程序2的基础上,增加学生具体信息和删除题目的功能。
输入格式:
- 题目信息:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
- 试卷信息:"#T:"+试卷号+" "+题目编号+"-"+题目分值+" "+题目编号+"-"+题目分值+...
- 学生信息:"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
- 答卷信息:"#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...
- 删除题目信息:"#D:N-"+题目号
输入的题目信息是无序的,也就是不会按照题号的顺序来输入,然后就是题目可能是有缺的,也就是题目不存在。
卷子总分不足100,需输出相关提示,如果卷子中的题目不存在,一若学生回答了这个问题,那么输出题目不存在的提示,二如果学生没有回答这个问题则输出学生没回答的提示
对于答卷信息的输入,如果输入的答卷信息所对应的试卷号不存在,则答案照常,然后输出试卷不存在的提示,答案的顺序号为试卷信息中出现题目的顺序号。如果题目不存在和学生无答案同时存在,则输出学生无答案的提示。
对于删除功能,被删以后题目存在,需要输出无效的提示。
输出格式:
试卷总分警示:"alert: full score of test paper"+试卷号+" is not 100 points"。
答卷信息:题目内容+"~"+答案++"~"+判题结果(true/false),题目缺失输出"answer is null"。
判题信息:**学号+" "+姓名+": "**+题目得分+" "+....+题目得分+"~"+总分。
被删信息:”the question 2 invalid~0”。
题目引用错误提示信息:”non-existent question~”加答案。
格式错误信息:”wrong format:”+信息内容。
试卷引用错误信息:”the test paper number does not exist”。
学生不存在:学号+”not found“。
对于本题,我做了以下类图:
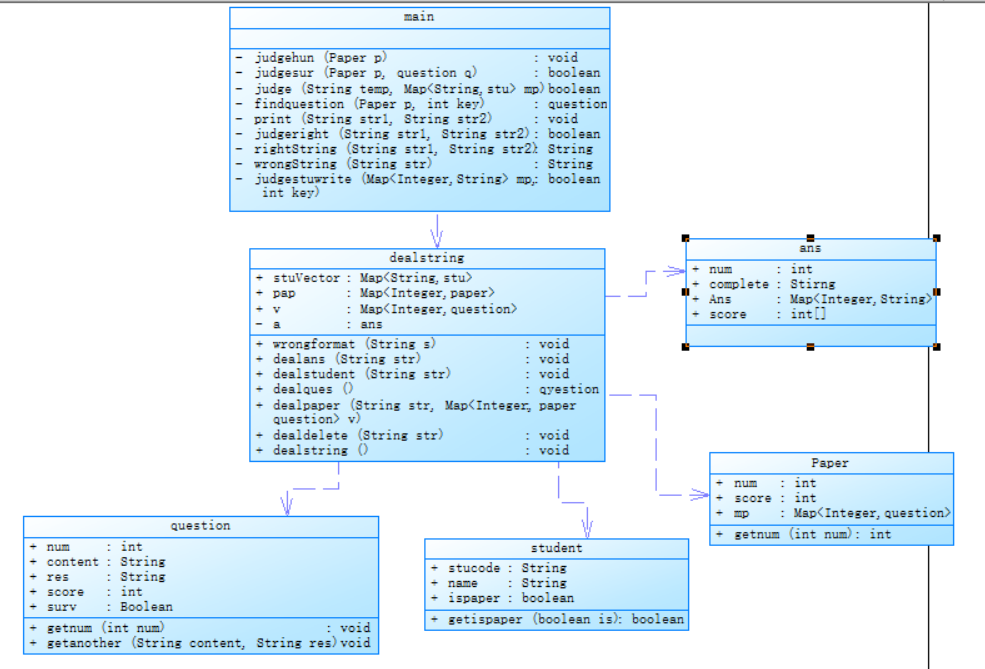
逻辑顺序是,首先传入dealstring处理函数,进入while循环,如果输入的不是“end”,那么就一直循环,利用正则表达式将输入的字符串进行分类处理,具体代码如下:
while (!(str = input.nextLine()).equals("end")){ if(Pattern.compile("#N:(\\d+) #Q:([^\\s#]*) #A:([^\\s#]*)").matcher(str).matches()){ ques q = dealques(str);//处理题目字符串 this.v.put(q.num,q); } else if(Pattern.compile("#X:(\\d+) (.+)").matcher(str).matches()){ dealstudent(str);//处理学生信息 } else if(Pattern.compile("#T:(\\d+) (.+)").matcher(str).matches()){ pa p=dealpaper(str,this.v);//处理试卷字符串 } else if(Pattern.compile("^#D:N-\\d+$").matcher(str).matches()){ dealdelete(str); } else if(Pattern.compile("#S:(\\d+) (\\d+) (.+)").matcher(str).matches()){ dealans(str);//处理学生考卷 } else{ wrongformat(str);//格式错误 }
如果是条件处理题目信息的字符串,传入相关函数后,首先是定义一个空问题类,然后利用substring函数将字符串中的题号信息提取出来,然后再利用split对字符串进行以“#”的切割,最后将题目内容和题目标准答案的信息去除多余空格,将所有信息添加到question类中,具体代码如下所示:
public ques dealques(String str){ ques temp=new ques(); str=str.substring(3); String[] ss=str.split("#"); ss[0]=ss[0].replaceAll(" ",""); int a= Integer.parseInt(ss[0]); temp.getnum(a);//加入题号 String content= ss[1].substring(2).trim(); String res=ss[2].substring(2).trim(); temp.getanother(content,res);//正确答案和内容记录类 return temp; }
如果字符串是对学生信息的描述,传入相关函数,将学生信息和学号加入到stuvector中,这样就可实现利用学号查找学生信息的要求,部分代码如下:
for(int i=0;i<ss.length;i++){ String stucode = ss[i].substring(0, ss[i].indexOf(" "));//学号 String name = ss[i].substring((stucode.length() + 1)); stu temp=new stu(name,stucode); this.stuVector.put(stucode,temp); }
如果是处理试卷的字符串,传入相关函数后,首先先判断paper中的mp(哈希表)是否为null,为null需要进行初始化定义,然后再对试卷进行处理,处理过程中需要判断题目是否存在,如果存在的话记录卷子总分和题目在试卷中的顺序,将题分记录题类中的score,如果不存在的话,那么就记录试卷的顺序(第几道题)为null,部分代码如下所示:
for (int i = 1; i < ss.length; i++) { String squenum = ss[i].substring(0, ss[i].indexOf("-")); int quenum = Integer.parseInt(squenum); if(v.get(quenum)!=null){ p.mp.put(i,v.get(quenum)); int score = Integer.parseInt(ss[i].substring((squenum.length() + 1))); p.score+=score;//记录卷子总分 v.get(quenum).score=score;//将题分记录题类 } else{ p.mp.put(i,null); }
因可能有多张试卷,所以就将一张试卷的信息存储:
this.pap.put(p.num,p);
如果检测到的字符串想要进行删除操作后,传入相关函数,将题目记录是否被删的变量更改:
this.v.get(code).surv=true;//题目被删了
如果检测的字符串操作时学生考卷的信息,则传入dealans处理答卷:
for(int i=0;i<ss.length;i++){ String stucode = ss[i].substring(0, ss[i].indexOf(" "));//学号 String name = ss[i].substring((stucode.length() + 1)); stu temp=new stu(name,stucode); this.stuVector.put(stucode,temp); }
如果什么都不符合,那么就是格式错误:
public void wrongformat(String s){//格式问题 System.out.println("wrong format:"+s); }
如果检测到end,那么输入完毕,预处理结束,返回主函数。
进入for循环,我是对试卷信息进行遍历,首先是判断这张卷子是否有满分:
public void judgehun(pa p){ if(p.score!=100){ System.out.println("alert: full score of test paper"+p.num+" is not 100 points"); } }
接着是对学生的判断,传入judgestu判断这张卷子所完成的学生是否存在:
boolean istusur = x.judgestu(deal.a.complete,deal.stuVector);//判断学生是否存在
利用哈希表中的查找函数:
if(mp.containsKey(temp))return true; return false;
如果存在就找到这个学生的信息,如果不存在则为null。
然后遍历这张卷子的所有题目与这个学生所给的答卷的答案,首先先判断学生是否写了这道题,没写的话存0分并且输出“answer is null”:
String temp = mp.get(key); if(temp==null){ System.out.println("answer is null"); return false; } return true;
如果写了这道题,就开始判断题目是否存在,如果题目不存在,则输出“non-existent question~0“:
for(Map.Entry<Integer,ques> entry : p.mp.entrySet()){ if(entry.getValue()==q&&entry.getValue()!=null)return true;//找到了题目 } System.out.println("non-existent question~0"); return false;//题库中没有这道题
如果存在那么获取当前题目的题目内容和标准答案,判断题目是否被删,如果被删了,那么这道题计0分,并输出题目被删的提示:
if(qtemp.surv){//被删了 qtemp.score=0; System.out.println("the question "+qtemp.num+" invalid~0"); everyscore = x.wrongString(everyscore); continue; }
输出题目的内容和学生给的答案,比对学生给的答案和标准答案是否一致:
if(Objects.equals(str1 , str2)){ System.out.println("true"); return true; } else { System.out.println("false"); return false; } }
将考卷的所有题目遍历完后,输出学生的学号以及得分情况,如果学生不存在则输出学生不存在的提示。至此我的程序运行结束。
以下为主函数的流程图:
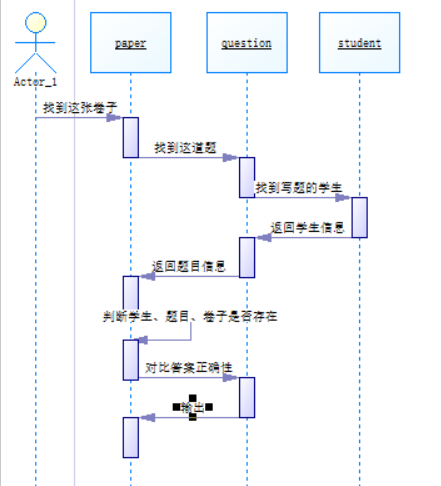
对于错误格式的信息无效试卷的引用,题目答案数据乱序输入这两条case我的错误是非0返回,可能在这两条case中,我的输入不适用?我发现我所有的错误里面都有无效试卷引用,也许都错在这里,然后因为没有实例,所以我无法判断我应该如何修改我的代码,可能只能多看正确代码去了解他们的逻辑从而找到自己的漏洞。
改进:在对一些高频率使用的方法编码时,我认为应该创建一个单独的类来实现,这样不仅能更高效地解决问题,还能将代码简化,大大提高了代码的可读性。代码逻辑问题需要更加完善吧,多看正确的代码完善自己的算法逻辑漏洞,然后就是同一类的代码尽量在同一天内完成,因为隔天就完全不知道自己写了什么,即使有注释,可能也没有在同一天内完成的效果更好。
总结:对于这三次大作业,总共有13道题,每次都是最后一道题难度较大,每一题都需要仔细揣摩每一个测试点,分析问题,设计合适的解题思路和算法,在调试解决这些测试点的过程中,我发现了自己代码的条理性、逻辑性欠佳,以及学习到了一些新的方法使代码更简洁有效。有时候做错题目是因为没有完全理解问题的要求。重温题目,确保理解每个要求和限制条件。