尚硅谷-flink
一、介绍
1.简介
flink是一个开源的分布式流处理框架
优势:高性能处理、高度灵活window操作、有状态计算的Exactly-once等
详情简介,参考官网:https://flink.apache.org/flink-architecture.html
中文参考:https://flink.apache.org/zh/flink-architecture.html
flink组件介绍:
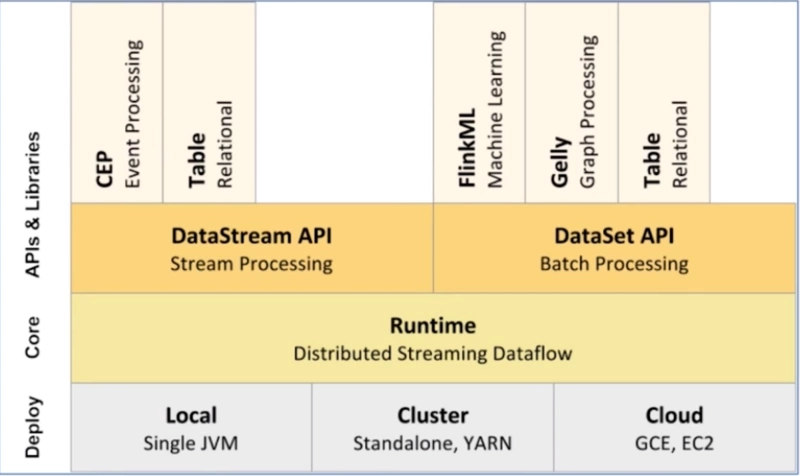
1)部署:支持本地、集群(支持yarn资源管理)、云
2)核心层:提供了计算的核心
3)API:提供了面向流处理的DataStream和面向批处理的DataSet
4)类库:支持Table/SQL
基本架构为 DataSource(数据源) -> Transfromation(算子处理数据) ->DataSink(数据目的)
分层API:

··
二、快速上手
wordcount:
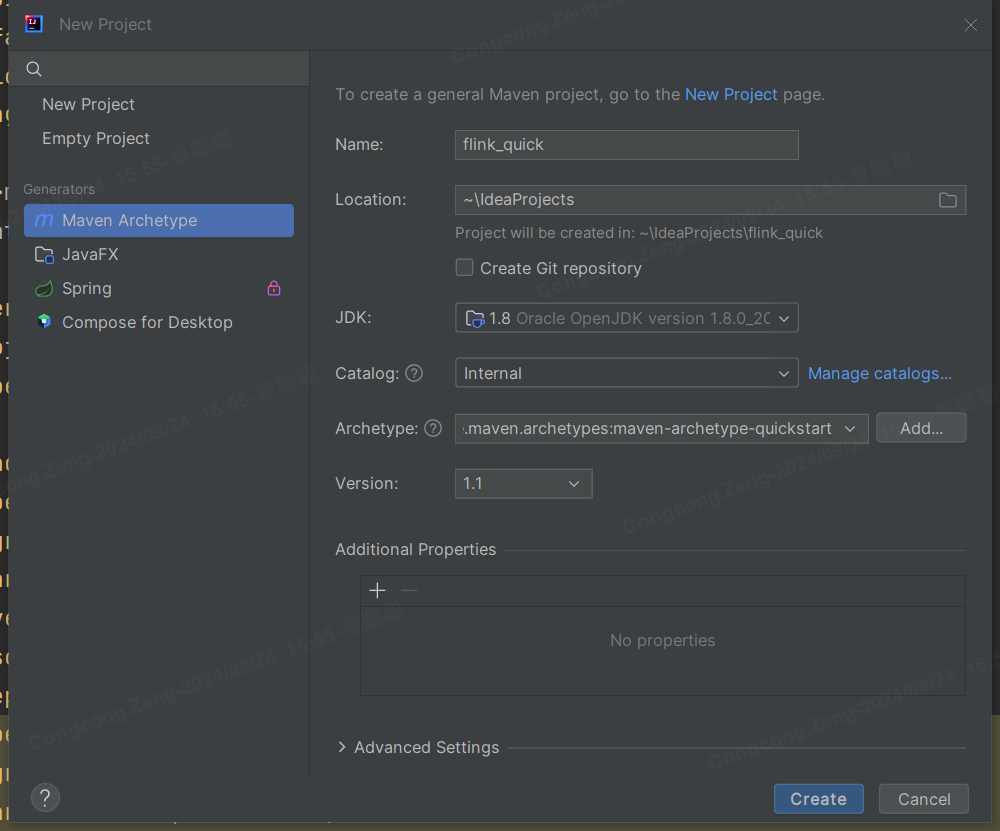
1.新建maven项目:
2.导入依赖
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <flink.version>1.17.0</flink.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> </dependencies>
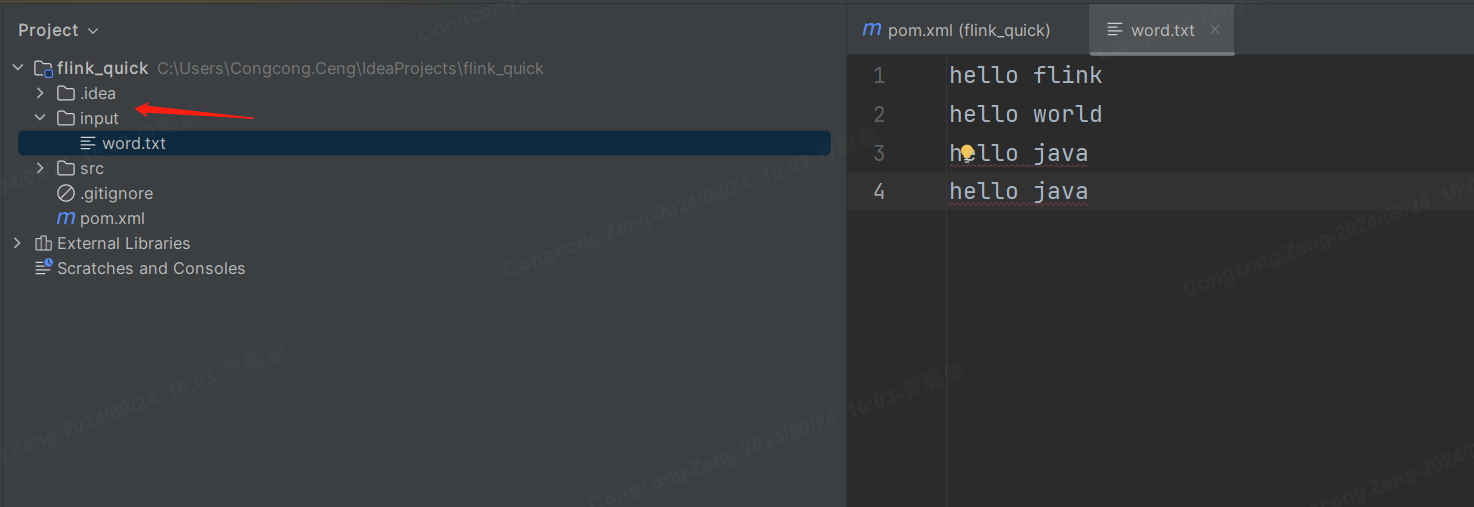
3.创建用于测试的txt文件
4.执行步骤
创建流处理环境:
从文件中读取数据:
进行WordCount操作:
打印结果到控制台:
执行任务:
代码如下:
package org.example; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * Hello world! */ public class App { public static void main(String[] args) throws Exception { // 创建flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从文件读取数据 DataStreamSource<String> source = env.readTextFile("input/word.txt"); // 处理数据,执行wordcount操作 SingleOutputStreamOperator<Tuple2<String, Integer>> summed = source.flatMap(new Tokenizer()) .keyBy(0) .sum(1); // 打印结果 summed.print(); // 启动执行 env.execute("WordCount"); } // 自定义FlatMapFunction,用于分词 public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 将输入的字符串按空格分割 String[] words = value.split("\\s+"); // 遍历每个单词,并生成 (word, 1) 的元组 for (String word : words) { out.collect(new Tuple2<>(word, 1)); } } } }
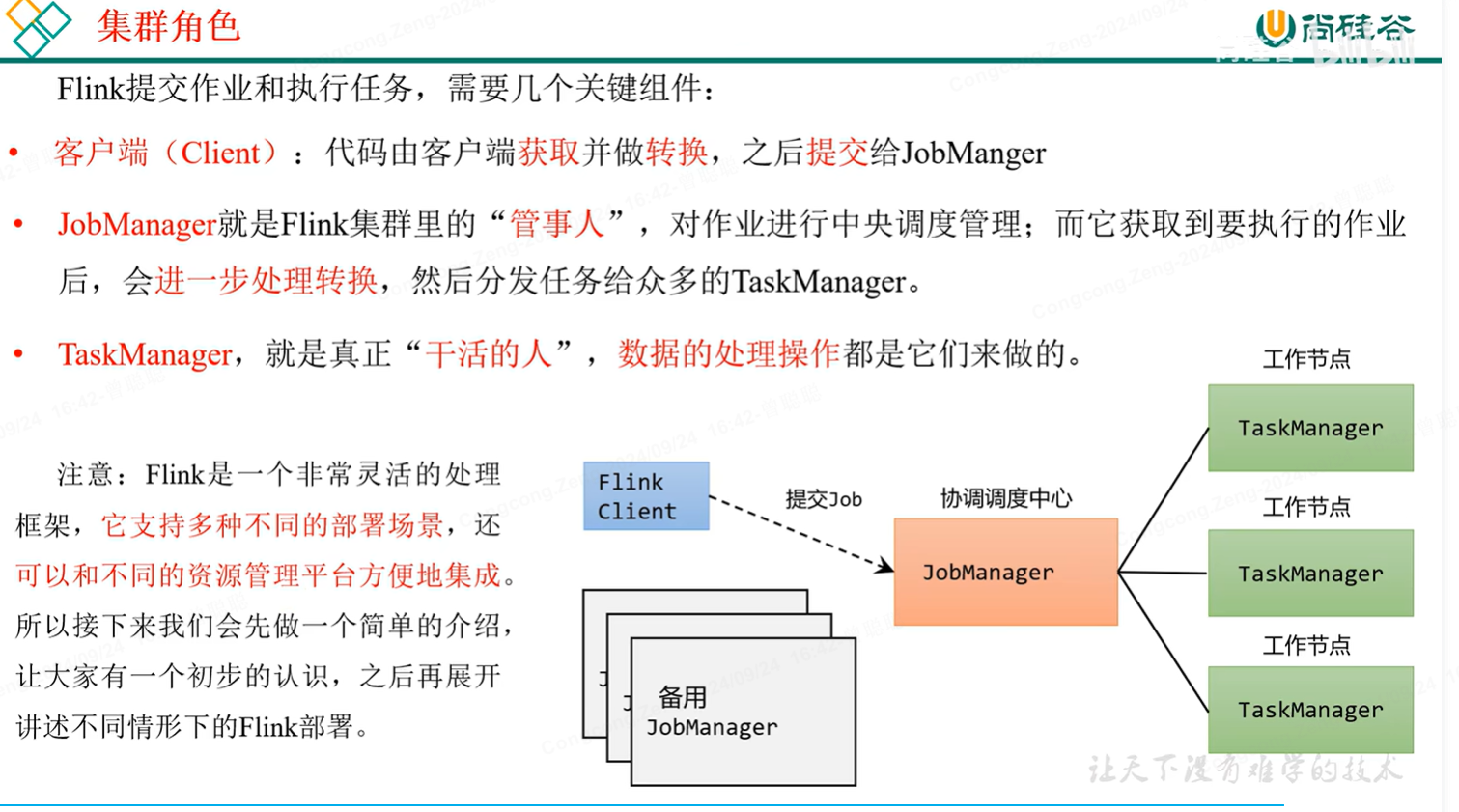
三、flink集群
集群角色: