记录一次线上oom排查
近日线上出现了一次oom,话不多说,马上排查。
排查经过
由于情况比较紧急,直接先重启了服务,这是老项目,当时也没有开启dump日志,所以获取不到当时的dump日志。
我们先是拿了一部分gc日志用于观察,下面是部分gc的日志
2023-10-09T10:01:08.920+0800: 15.687: [GC (Allocation Failure) [PSYoungGen: 1299456K->12721K(1348608K)] 1358416K->71689K(4145152K), 0.0135580 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
2023-10-09T10:01:11.068+0800: 17.835: [GC (Allocation Failure) [PSYoungGen: 1312177K->22561K(1352704K)] 1371145K->81537K(4149248K), 0.0184148 secs] [Times: user=0.09 sys=0.00, real=0.02 secs]
2023-10-09T10:01:13.478+0800: 20.245: [GC (Allocation Failure) [PSYoungGen: 1327649K->34624K(1350144K)] 1386625K->93608K(4146688K), 0.0294531 secs] [Times: user=0.12 sys=0.01, real=0.03 secs]
2023-10-09T10:01:15.793+0800: 22.560: [GC (Allocation Failure) [PSYoungGen: 1339712K->47601K(1334784K)] 1398696K->108729K(4131328K), 0.0373881 secs] [Times: user=0.17 sys=0.00, real=0.04 secs]
2023-10-09T10:01:39.981+0800: 46.747: [GC (Allocation Failure) [PSYoungGen: 1334769K->55279K(1342464K)] 1395897K->131090K(4139008K), 0.0434365 secs] [Times: user=0.19 sys=0.01, real=0.04 secs]
2023-10-09T10:01:51.339+0800: 58.105: [GC (Metadata GC Threshold) [PSYoungGen: 730622K->55275K(1251328K)] 806433K->202959K(4047872K), 0.0444378 secs] [Times: user=0.12 sys=0.04, real=0.04 secs]
2023-10-09T10:01:51.383+0800: 58.150: [Full GC (Metadata GC Threshold) [PSYoungGen: 55275K->0K(1251328K)] [ParOldGen: 147683K->174753K(2796544K)] 202959K->174753K(4047872K), [Metaspace: 96198K->96164K(1136640K)], 0.3867283 secs] [Times: user=1.15 sys=0.03, real=0.39 secs]
我们可以看到在高峰期几秒钟就进行一次young gc,而且gc前年轻代都是达到了1G多,这对于我们这种小业务场景是非常不正常的。
于是接下来就要用dump日志进行分析,我用jmap dump了一个日志用于分析
jmap -dump:live,format=b,file=dump-1137.hprof 9292
如果是在docker容器内的应用使用如下命令
docker exec <container_id> jmap -dump:live,format=b,file=/tmp/heapdump.hprof <java_pid>
docker cp <container_id>:/tmp/heapdump.hprof ./heapdump.hprof
此处java_pid要用docker容器里的进程id,而不是外面的
分析工具是用的jvm 的VisualVM2.1.7,官网下载地址是 点击跳转
切换到Objects下面,我们可以看到前面的100多个对象全是6.5M大小的byte数组
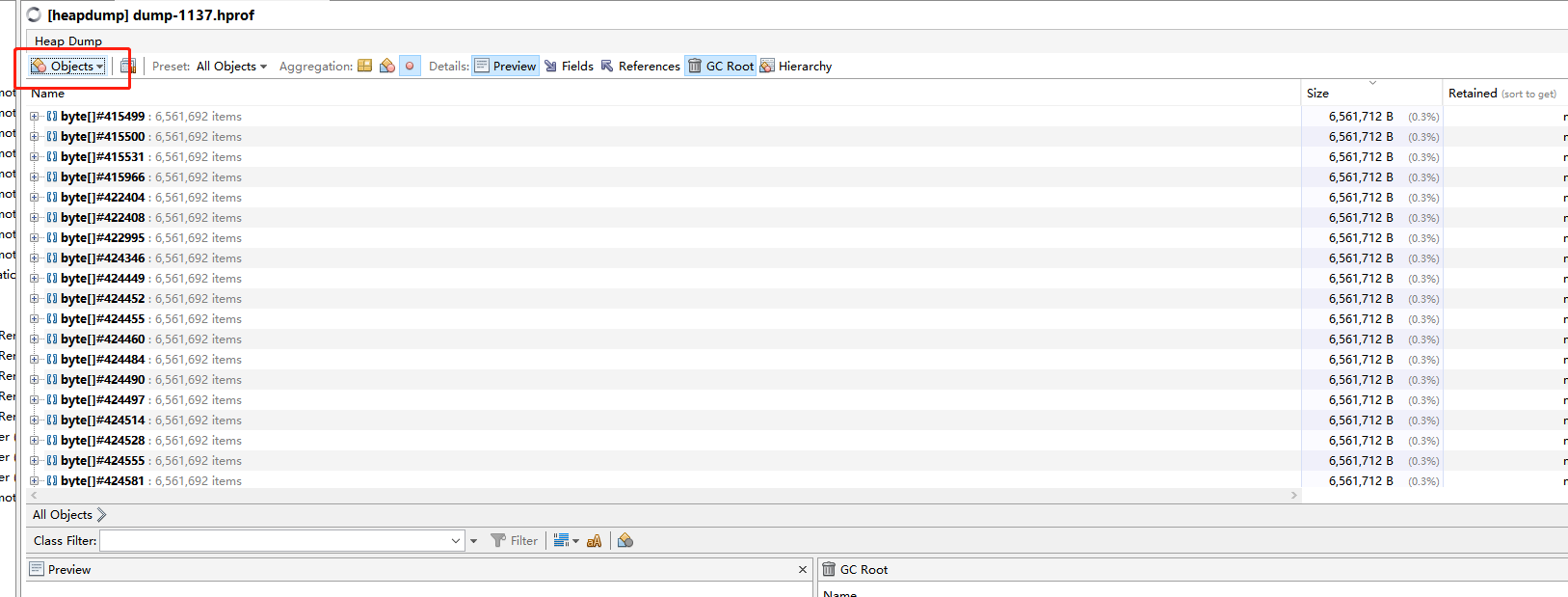
继续跟踪,preview预览一下发现这里面存的就是一个请求信息,这显然不应该占这么大空间,

继续往下看引用,发现引用的大部分都是tomcat的类,而且是header相关的类。
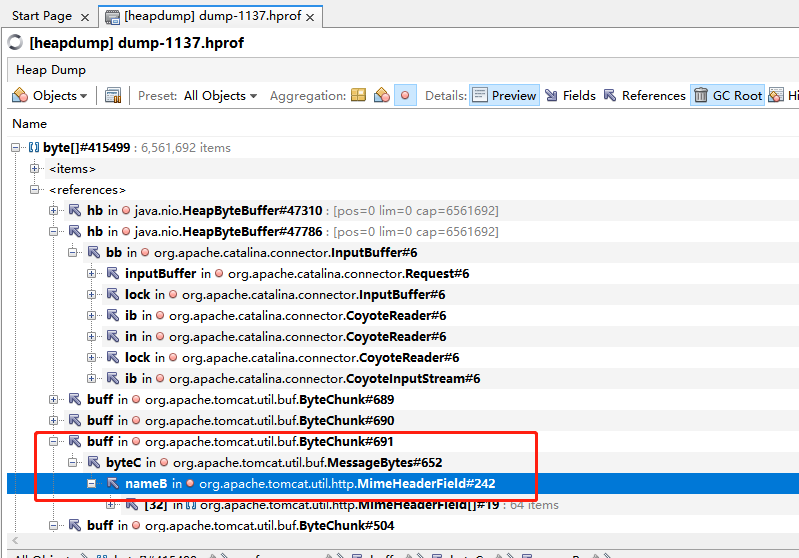
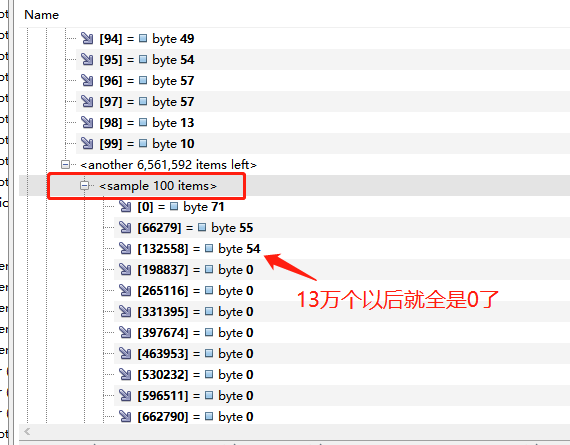
再看下对象的其他内容,用VisualVM可以看下所有的样本数据,大约是8万条字节一个样本,发现从132558这个样本往下就全是0了,说明后面的全是空数据,这样真实数据只占了132558/6561592=2%,其他数据全是byte[]的预留空间,全是浪费的。
看到这,其实已经发现了这个请求头是有问题的,这时候去看了一下配置类,发现有这么个配置
server:
max-http-header-size: 6553600
这是对请求头的大小限制,去网上确认了一下,果然就是这个搞的鬼。问了一下业务组,他们原先加这个是因为加了很多省市区的信息到header里,这个显然也是不合理的,这么多的省市区信息肯定是要放缓存里,怎么能放header里。
解决方案
既然知道原因了,那解决方法也就容易了
- 一种是把省市区信息放缓存里,彻底解决,但是这个影响比较大,他们暂时没动
- 第二种是对信息尝试压缩,把这个max-http-header-size改小
深层原因
gc有个规则叫动态年龄判断,如果当前Survivor区域里,一批对象的总大小超过了这块Survivor区域的内存大小的50%,那么此时大于等于这批对象年龄的对象,就可以直接进入老年代了。在业务场景比较频繁的情况下,年轻代对象产生比较频繁,又比较大,导致来不及回收,而且因为http连接没断开,header对象就会直接进入老年代,此时如果老年代本来空间就不足,就会被这波高峰请求直接压垮,导致oom。以上部分是我分析出来的,因为没有oom时的dump日志,也不能完全确认。但是结合线上偶尔oom的情况,大致应该就是这样。