mybatis使用步骤
开发mybatis程序步骤:
1.配置mybatis
conf.xml:配置数据库信息和映射文件路径
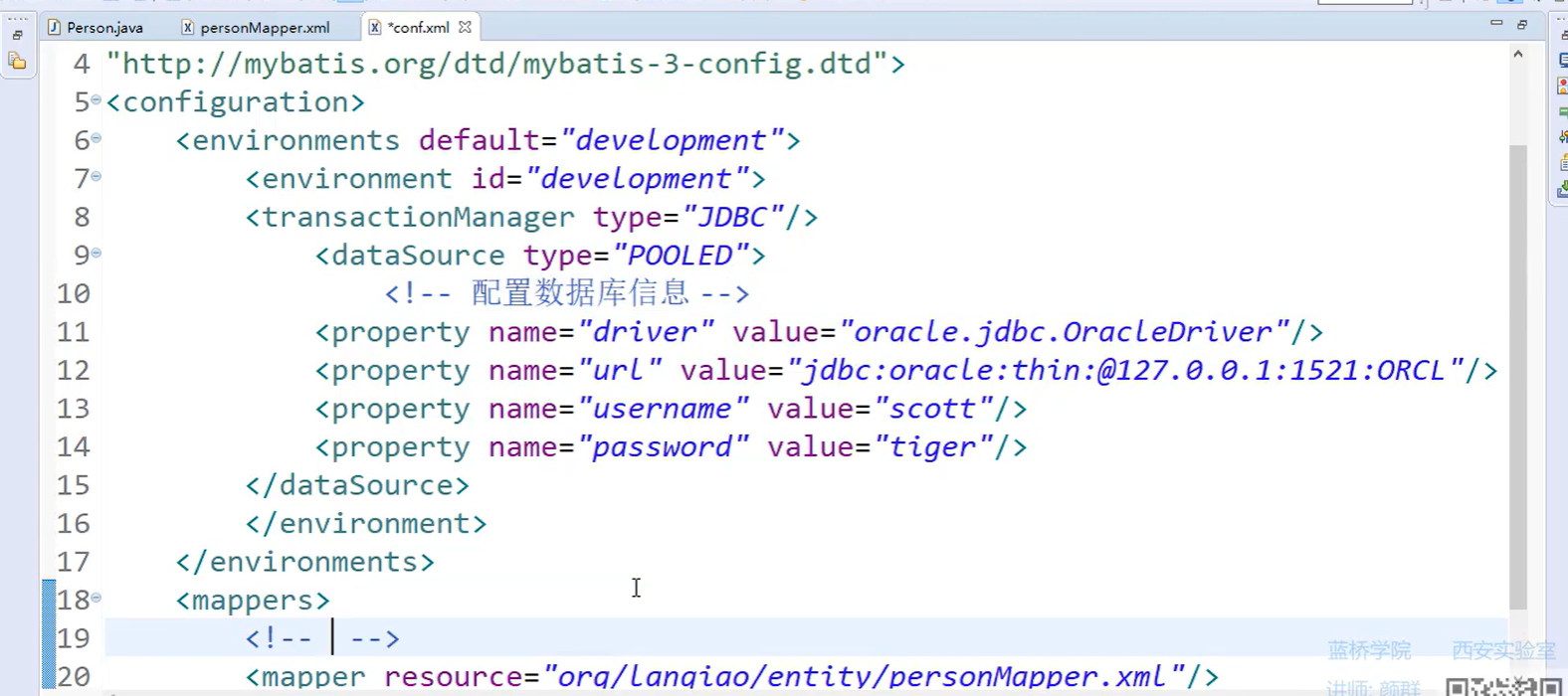
加载的映射文件
表----------类
映射文件xxMapper.xml:增删改查标签<select> 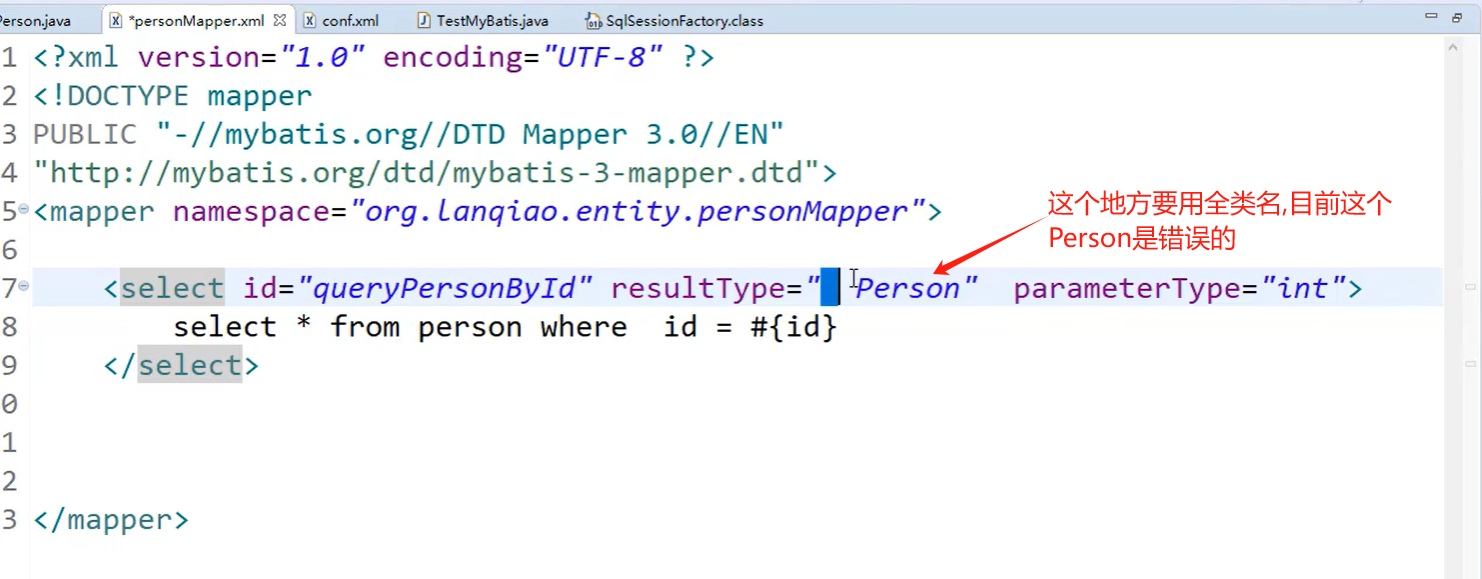
2.测试类
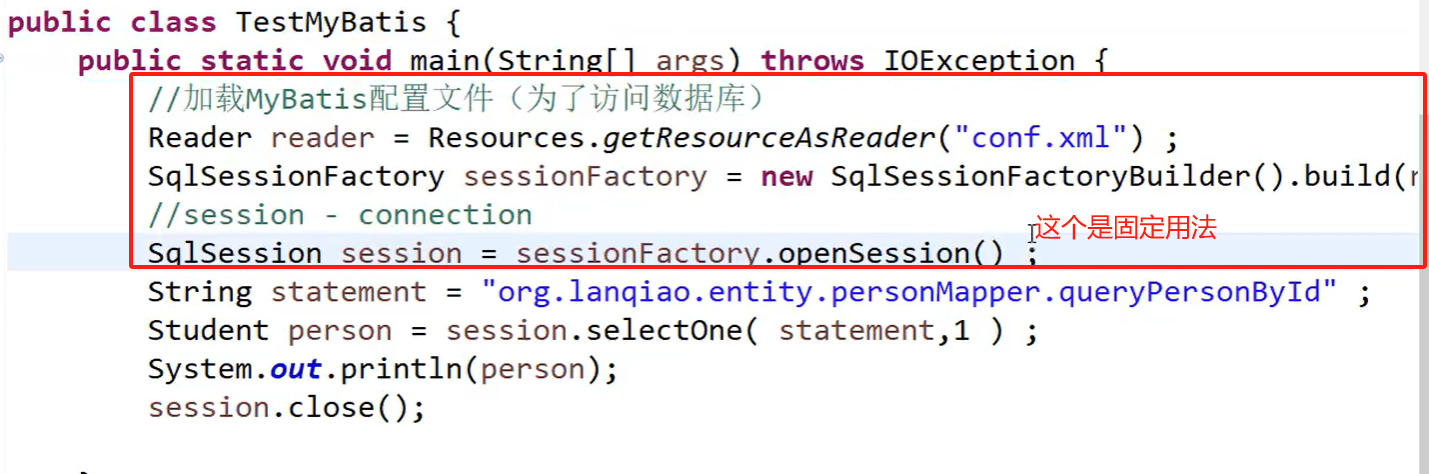
mybatis开发流程:
一,普通配置方式
1.vo----表对应关系
2.数据库xml文件
1>指定数据库 源配置
2>指定映射文件路径
3.xxMapper.xml(实现sql和代码的分离)
指定sql语句
4.代码中通过xxMapper.xml中的Namespace.sqlid找到指定的sql语句
1.session.selectOne(Namespace.sqlid,参数)
2得到查询结果
3.打印查询结果
代码部分如下:
二动态代理方式(基于接口开发):
其实是通过抽象类的签名进行定位到mapper.xml的sql语句进行查询的
1>基础环境配置与普通配置方式一样
mybatis.jar/ojdbc,jar,conf.xml,mapper.xml
2>(不同之处)
约定的目标:省掉statement,即根据约定直接定位出sql语句
1>接口
1.方法名和mapper.xml文件中的标签的id值相同
2.方法的输入参数和mapper.xml文件中的标签的parameterType类型一直
3.方法的返回值和mapper.xml文件中的标签的resultType类型一致(无论查询结果是一个还是多个,在mapper.xml中只写一个)
除了以上约定,要实现接口中的方法和Mapper.xml中SQL标签一一对应,还需要注意一下1点
1.namespace的值,就是接口的全类名
匹配的过程:(约定的过程)
1.根据接口名找到mapper.xml文件(根据的是namespace=接口全类名)
2.根据接口的方法名,找到mapper.xml文件中的sql标签(方法名=SQL标签Id值)
基于以上2点可以保证:当我们调用接口中的方法时,程序能自动定位到某一个Mapper.xml文件中的sql标签
习惯:SQL映射文件(mapper.xml)和接口放在同一个包中(注意修改conf.xml中加载mapper.xml文件的路径)

以上:可以通过接口的方法定位----------------------------->>>sql语句
执行:
StudentMapper studentMapper=session.getMapper(StudentMapper.class)
studentMapper.方法();
通过session对象获取接口(session.getMapper(接口.class)),再调用该接口中的 方法,获取到查询结果
代码部分:
只写接口,不写实现类

优化:
1.可以将配置信息单独放入db.properties文件中,然后再动态引入
db.properties:
k=v
<configuration>
<properties resource="db.properties" />
引入以后,使用${key}进行引用
2.MyBatis全局参数
在conf.xml中设置
<settings>
<setting name="cacheEnabled" value="false" />
<setting name="lazyLoadingEnabled" value="false">
</settings>
3.别名
1.设置单个别名
定义别名的时候,大小写无所谓
2.批量设置别名

类型处理器(类型转换器)
1.MyBatis自带一些常见的类型处理器
int-----number
2.自定义MyBatis类型处理器
java---数据库(jdbc类型)
示例:
实体类Student:boolean stuSex
true:男
false:女
表student: number stuSex
1:男
0:女
自定义类型转换器(boolean -number)步骤:
a.创建转换器:需要实习爱你TypeHandler接口
通过阅读源码发现,此接口有一个实现类BaseTypeHandler,因此要实现转换器有2种选择
1.实现接口TypeHandler接口
2.继承BaseTypeHandler类
b.配置
conf.xml配置类型转换器


需要注意的是:设置INTEGER类型的时候必须用纯大写
3.存储过程的调用
用map种的key的值匹配,占位符#{stuAge},如果匹配成功,就用map的value替换占位符
mybatis调用存储过程
<select id="queryCountByGradeWithProcedure" statementType="CALLABLE" parameterTye="HashMap">
{
CALL queryCountByGradeWithProcedure(
#{gName,jdbcType=VARCHAR,mode=IN}
#{scount,jdbcType=INTEGER,mode=OUT}
)
}
</select>
期中通过statementType="CALLABLE"设置sql的执行方式是存储过程,存储过程的输入参数gName需要通过HashMap在使用时,通过hashmap传入输入参数的值,通过hashmap的Get方法获取输出参数的值
要注意jar问题:ojdbc6.jar不能再调用存储过程时,打回车 ,tab,空格,jdbc7可以
mapper.xml->mapper接口--->测试方法
如果报错:No enum constant org.apache.ibatis.type.JdbcType.xx,则说明mybatis不支持xx类型
输出参数resultType
1.简单类型(8个基本+String)
2.输出参数为实体对象类型
3.输出参数为实体对象类型的集合:虽然输出类型为集合,但是resultType依然写集合元素的类型
4.输出参数类型为HashMap
--HashMap本身是一个集合,可以存放多个元素,但是根据提示发现,返回值HashMap时,查询的结果只是是一个学生(no,name)
结论:一个HashMap对应一个学生的多个元素(多个属性)
resultType和resultMap类型区别:
1.实体类的属性和数据表的字段类型不一致使用resultMp
2.实体类的属性和数据库字段名称不一致使用resultMap
3.一般都是使用resultType
注意:当属性名和字段名不一致时,除了使用resultMap以外,还可以使用resultType和HashMap
a用resultMap进行解决
<resultMap type="student" id="queryStudentByIdMap">
<!---指定类中的属性和表中的字段对应关系-->
<id property="stuNo" column="id" />
<result property="stuName" colum="name" />
</resultMap>
b>通过resultType解决
select 表的字段名 "类的属性名" from 来定制字段名和属性名的对应关系
<select id="queryStudentByIdWithHashMap" parameterType="int" resultType="student">
select id "stuNo",name "stuName" from student where id=#{id}
</select>
注意:如果有10个字段,但发现某个字段一直为null或者0,那么就是这个字段在mapper.xml没有对应上
select stuno,stuname,stuage from student <where> and stuname=#{stuName} and stuage=#{stuAge}
<where>会自动处理第一个<if>标签中的and,但不会处理之后的<if>中的and
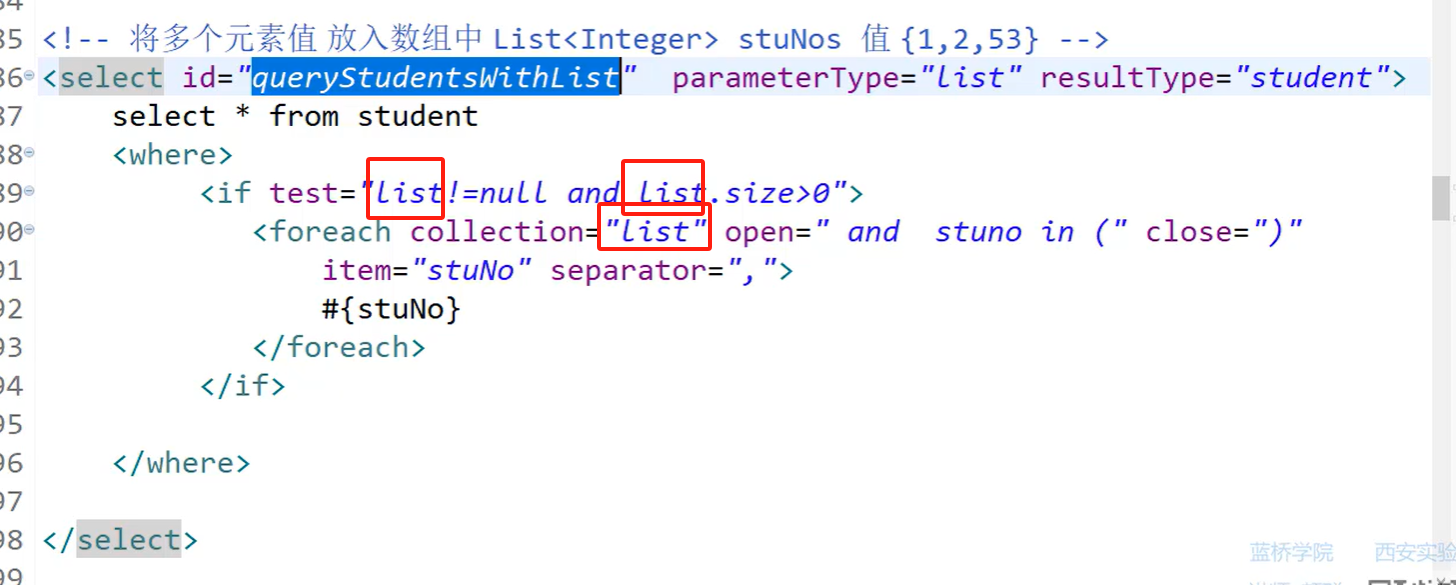
ids={1,2,53}
select stuno,stuname from student where stuno in (1,2,53)
<foreach>迭代的类型:数组,集合,对象数组,属性(Grade类,List<Integer> ids)
属性()
动态sql的拼接过程:
1>类作为参数传递

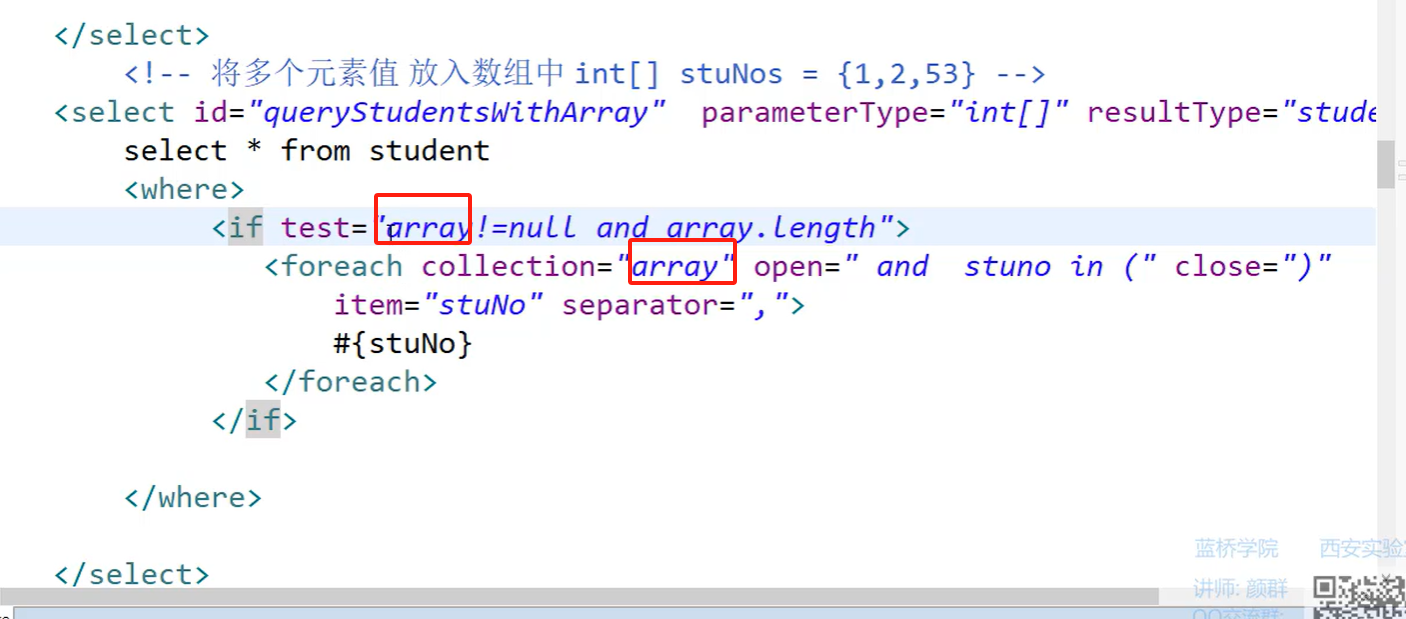
2.数组作为参数传递,关键字用array
无论编写代码时,传递的是什么参数名,在mapper.xml中,必须用array代替该数组
3.集合
无论编写代码时,传递是什么参数(stuNos),在mapper.xml中,必须用list代替该数组
4.对象数组:
Student[] students={student0,student1,student2}每个studentx包含一个学号属性
注意点:
parameterType=""Object[]"
<foreach collection ="array" open="" and stuno in (" close=")">
item="student" separator=",">
#{student.stuNo}
</foreach>

SQL 片段:
java:方法
数据库:存储过程,存储函数
MyBatis:SQL片段
步骤:
1.提取像是代码
2.引用
如果sql片段和引用处不在同一个文件中,则需要再refid引用时,加上namespace+id
关联查询:
1>一对一
a.通过业务扩展类
这种方法比较山寨,查询关联比较小的时候实用,如果比较复杂的时候还是用下面的resultMap
核心:利用业务扩展类实现一对一,用resultType指定类的属性包含多表查询的所有字段
b.resultMap

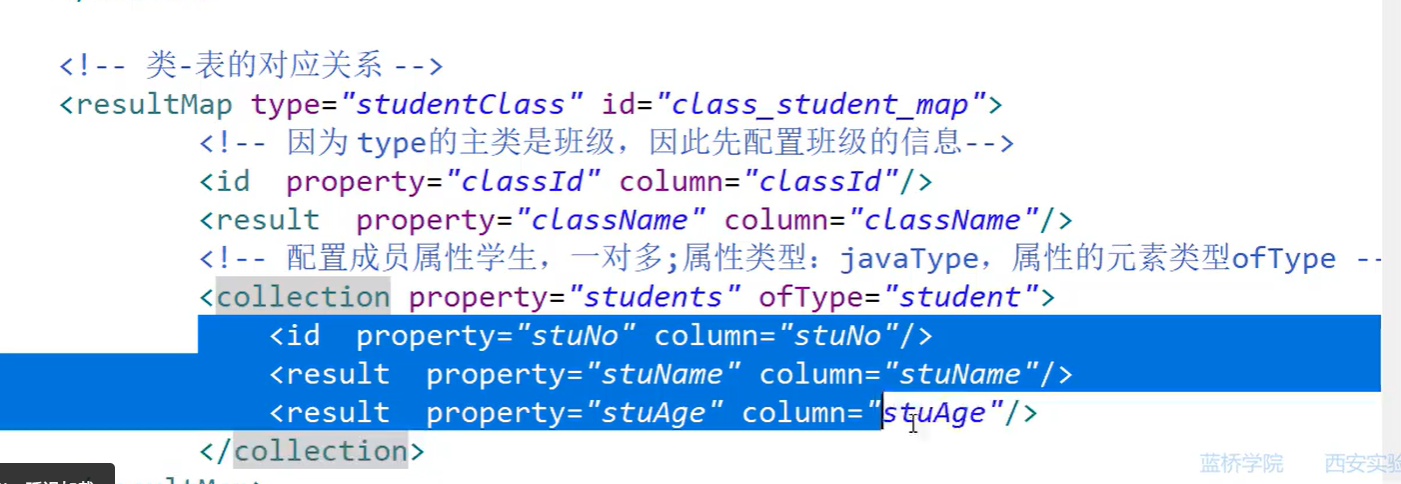
2>一对多
(多对一,多对多的本质就是一对多的变化)
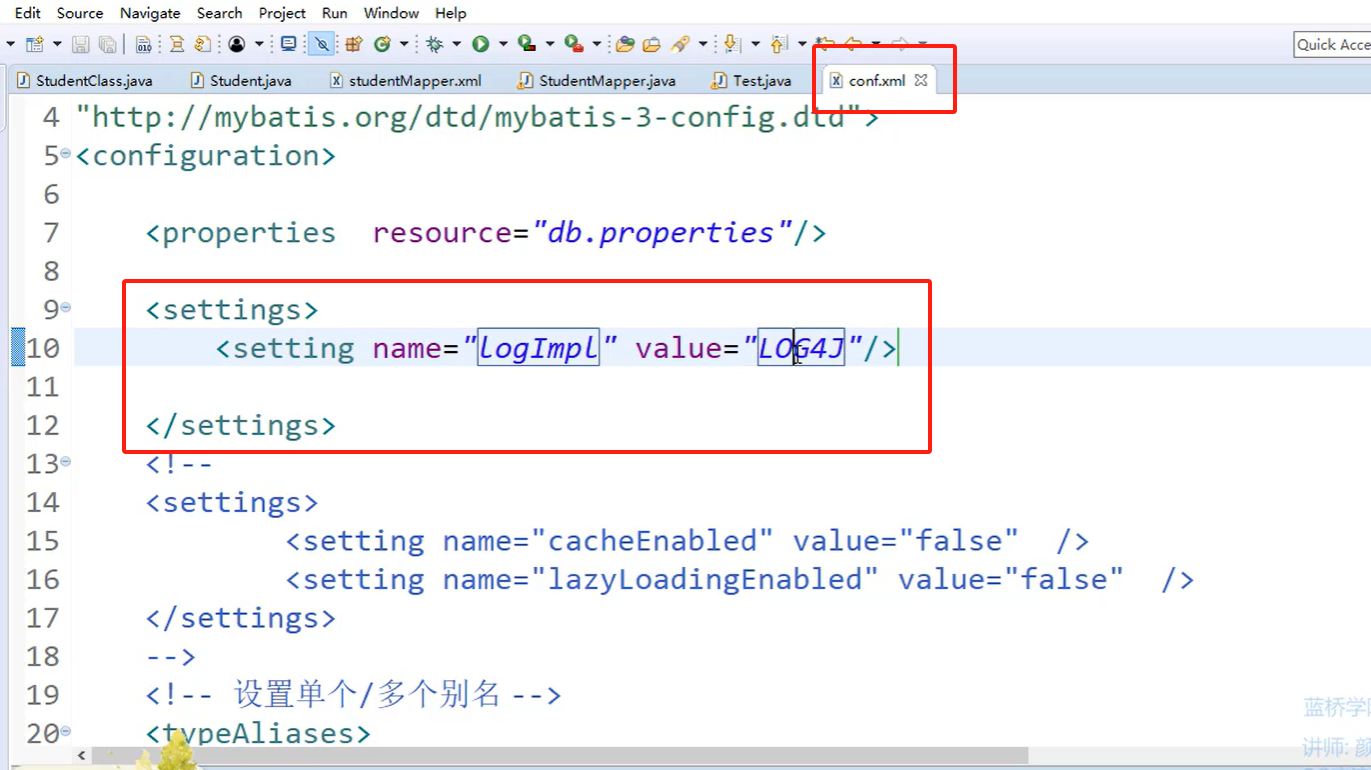
日志:Log4j
1.导入Jar包: log4j.jar
2.开启日志:
在confi.xml进行配置开启日志:
如果不指定,mybatis按照下面顺序去找日志包
SLF4J-------------->Apache Commons Logging--------------> Log4j 2-------------->Log4-------------->JDK logging
3.编写配置日志输出文件
log4j.properties
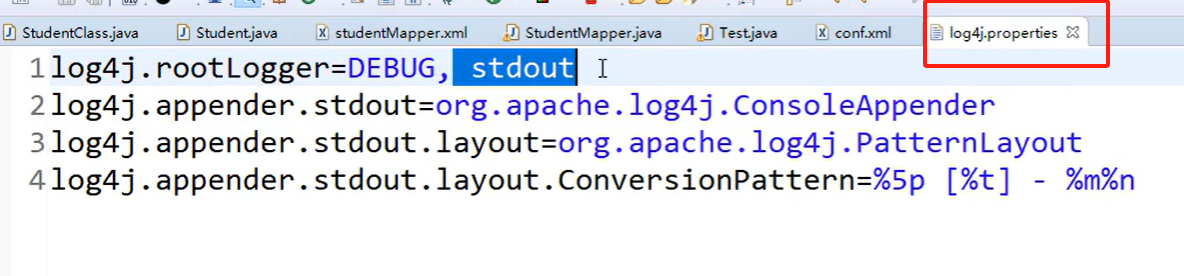
日志级别:
DEBUG<INFO<WARN<ERROR
如果设置为info,则只显示info以及以上级别的信息
延迟加载:(lazy加载)
一对一,一对多,多对一,多对多
一对多:班级---学生
如果不采用延迟加载(立即加载),查询时会将一和多都查询,班级和班级中的所有学生
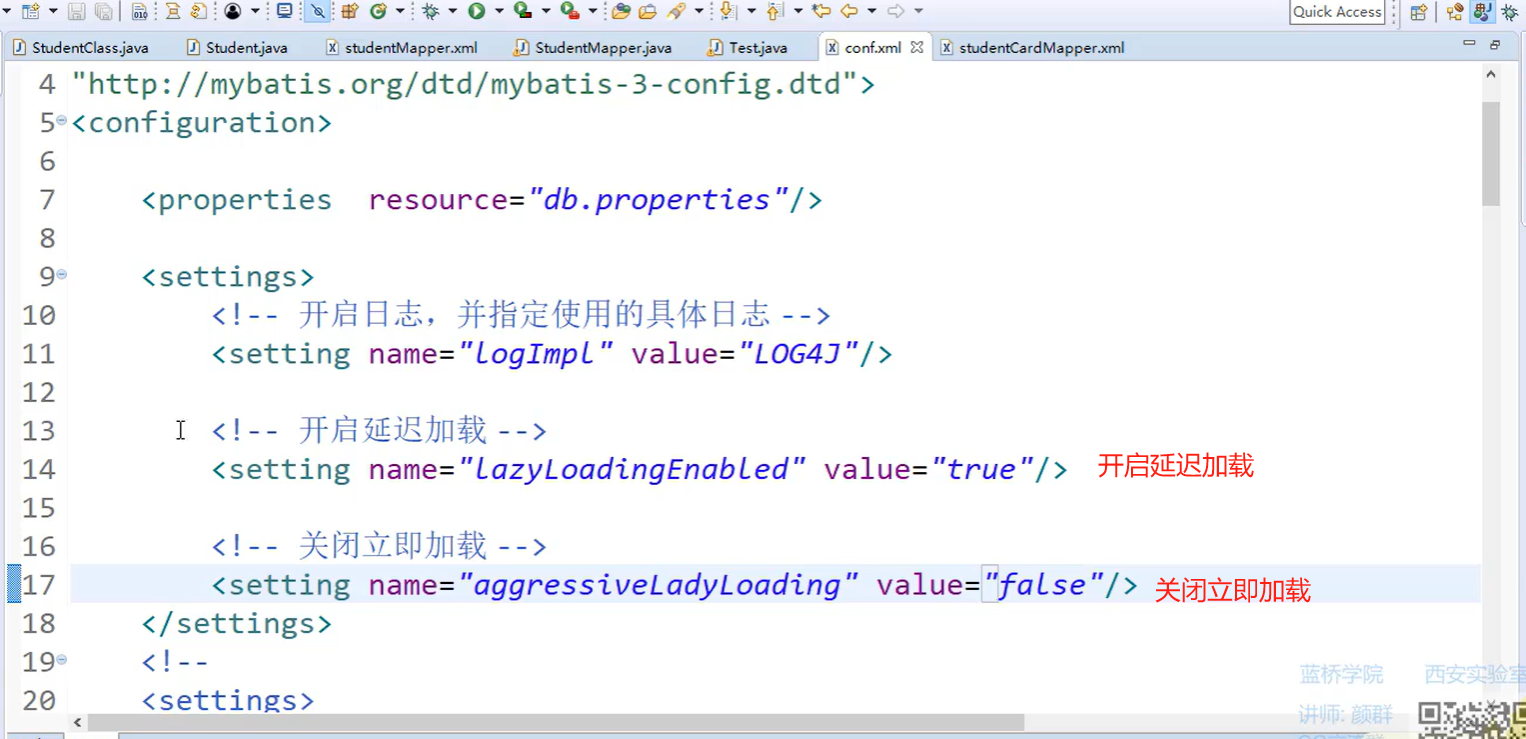
如果想要,暂时只查询1的一方,而多的一方,先不查询,而是在需要的时候再去查询---->延迟加载
一对一:学生,学生证
mybatis中使用延迟加载,需要先配置
<settings>
<!----开启延迟加载--->
<setting name="lazyLoadingEnabled" value="true">
<!---关闭立即加载-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
通过debug可以发现,如果程序只需要学生,则只向数据库发送了查询学生的sql
当我们后续需要用到学生证的时候,再第二次发送查学生证的sql
如果增加了mapper.xml,要修改conf.xml配置文件,将新增的mapper.xml加载进去
延迟加载步骤总结:
1.开启延迟加载:在conf.xml配置settings
在mybatis中使用延迟加载,需要先配置
<settings>
<!----开启延迟加载--->
<setting name="lazyLoadingEnabled" value="true">
<!---关闭立即加载-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
2.配置mapper.xml
涉及到2个类,涉及到2个mapper
写2个mapper:
班级mapper.xml
<select id="queryClassAndStudents" resultMap="class_student_lazyLoad_map">
select c.* from studentclass c
</select>
<resultMap type=""studentClass" id="class_student_lazyLoad_map">
<!--因为type的主类是班级,因此先配置班级的信息-->
<id property="classId" column="classId">
<result property="className" column="className">
<!---配置成员属性学生,一对多;属性类型:javaType,属性的元素类型ofType---->
<---再插班级对应的学生--->
<collection property="students" ofType="student" select="org.lanqiao.mapper.StudentMapper.queryStudentsByClassId" column="classId"> 蓝色部分是延迟加载的
<!---立即加载的部分result property="stuNo" column="stuName"/>
<!---立即加载的部分result property="stuAge" column="stuAge"/>
</collection>
</resultMap>
即查询学生的sql是通过select属性指定的,并且通过column指定外键
学生mapper.xml
<!--一对多,延迟加载需要的:查询班级中的所有学生---->
<select id="queryStudentsByClassId" parameterType="int" resultType="student">
select * from student where classId=#{classId}
</select>
1.查询缓存
一级缓存的范围:同一个SqlSession对象
MyBatis默认开启一级缓存,如果用同样的SqlSession对象查询相同的数据,则只会在第一次查询时想数据库发送sql语句,并将查询的结果放入到SQLSESSION中作为缓存存在.
后续再次查询该同样的对象时,则直接从缓存中查询该对象即可(即省略了数据库的访问,提高了性能)
二级缓存:
开启二级缓存:
1>.conf.xml配置开启项
<!----开启二级缓存---->
<setting name="cacheEnabled" value="true" />
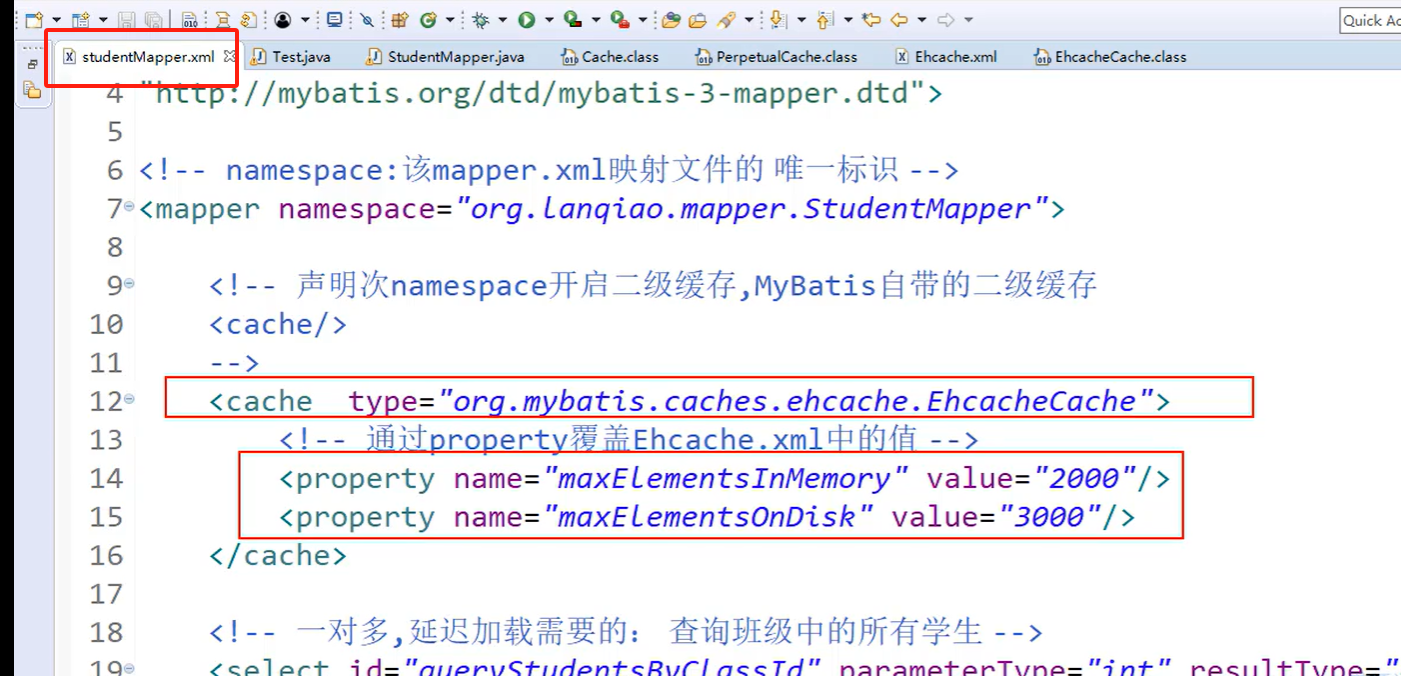
2>.在具体的mapper.xml中声明开启
Mybatis自带二级缓存:[同一个namespace]生成的mapper对象
回顾:namespace的值就是接口的全类名(包名.类名),通过接口可以产生代理对象(studentMapper对象)-
-----name决定了studentMapper对象的产生
结论:只要产生的xxxMapper对象来自于同一个,他们的二级缓存共享
根据异常提示:NotSerializableException可知,MyBatis的二级缓存是将对象放入硬盘文件中
序列化:内存---->硬盘
反序列化:硬盘----->内存
准备缓存的对象,必须实现了序列化接口(如果开启了缓存,Namespace="org.lanqiao.mapper.StudentMapper"),可知序列化对象为Student,因此需要将Student进行序列化
(序列化Student类,以及Student级联属性和父类也需要进行序列化)
触发将对象写入二级缓存的时间是:SqlSession对象的close()方法
禁用:select标签中useCache=false
清理:
a>与清理一级缓存的方法相同
commit():一般执行增删改时,会清理掉缓存,设计的原因是为了防止脏数据的产生
在二级缓存中,commit()不能是查询自身的commit
commit会清理一级和二级缓存,但是清理二级缓存时,不是查询自身的commit
b.在select标签中,增加flushCache="true"
三方提供的二级缓存:
ehcache.memcache
要想整合三方提供的二级缓存(或者自定义二级缓存),必须实现一个接口org.apache,ibatis.cache.Cache接口,该接口的默认实现类
整合ehcache二级缓存:
1>整合Ehcache
Ehcache-core.jar
mybatis-Ehcache.jar
slf4j-api.jar
2.编写ehcache配置文件 Ehcache.xml
3>开启第三方的二级缓存
2.逆向工程
表,类,接口,mapper.xml四者密切相关,因此当知道一个的时候,其它三个应该可以自动生成
表---->生成其他三个
实现步骤:
1>准备jra
mybatis-generator-core.jar
mybatis.jar
ojdbc.jar
2>逆向工程的配置文件generator.xml
3.执行
Mybatis高级篇:
1.数据库环境切换
a>切换environments(指定实际使用的数据库)
b>配置Provider别名
c>写不同数据库的sql语句
d>在mappe.xml中配置databaseId="Provider别名"
如果mapper.xml的ssql标签仅有一个不带databaseId的标签,则该标签自动适应数据
如果既有不带databaseId的标签,又有带databaseId的标签,则程序会优先使用带databaseId的标签
2.注解方式
推荐使用xml
a>将sql语句写在接口的方法前面@Select("")
b.将接口的全类名写入<mappers>,目的是让mybatis知道sql语句此时存储在接口中
注解/xml都支持批量引入
<mappers>
<!---以下可以将com.yanqun.mapper包中的注解类和mapper.xml全部一次性引入-->
<package name="com.yanqun.mapper" />
</mappers>
3.增删改的返回值问题
返回值可以是void,Integer,Long,Boolean
如何操作:只需要在接口中修改返回值即可
4.事务自动提交
sessionFactory.openSession();
session.commit()
自动提交:
sessionFactory.openSession(true)
5.自增问题:
mysql支持自增:
只需要配置两个属性即可:useGenerateKeys="true" keyProperty="stuNo",这个是自动生成字段的回写功能
<insert id="addStudent" parameterType="com.yanqun.entity.Student" databaseId="mysql" useGenerateKeys="true" keyProperty="stuNo">
insert into student(stuName,stuAge,graName) values(#{stuName},#{stuAge},#{graName})
</insert>
oracle不支持自增:通过序列模拟实现的