Java基础内容集合
这部分是Java中的基础内容,集合,也叫做Java容器,用在很多的地方。
集合是用来存储数据的,简称为容器,其中这里的存储指内存层面的存储,不是持久化存储。
1. 数组的特点:
- 指定长度后,长度不可以更改
- 声明了类型后,数组只能存放这个类型的数据。
- 数组的查询效率高,删除、增加元素的效率低
- 数组中实际元素的数量无法获取,没有提供具体的方法来获取
- 数组存储数据是有序可重复的,这里的有序不是指实际数据排序,指是线性排列的意思
综上所述,数组的灵活性低,引入了集合,有Set、List、Map等等,不同集合底层数据结构不一样,所以每个集合都有各自的特点,适用于不同的场景。
2. 集合体系结构图
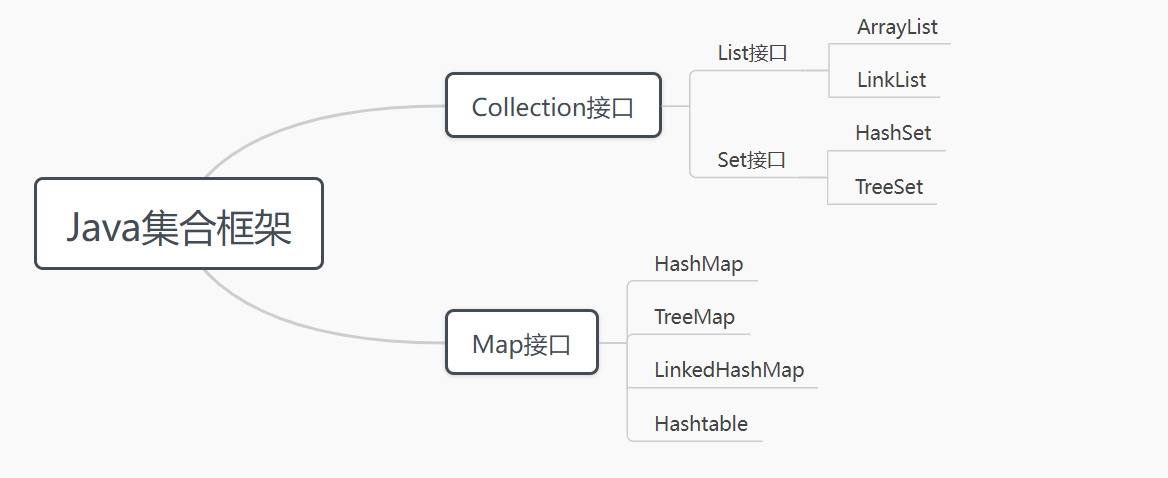
3. 集合的应用场合:
集合是用来存储数据的,在整个开发过程中从始到终一直在用到,根据各个集合的特点选用对应合适的集合使用。其中集合只能存放引用数据类型的数据,不能是基本数据类型,基本数据类型自动装箱。当使用泛型时候,为了方便统一管理,一般只会存入一种数据类型。
- 大致总结一下如:
- 如果需要频繁访问元素,使用ArrayList
- 如果需要频繁插入和删除元素,使用LinkedList
- 如果不允许重复元素且无序,使用HashSet
- 如果需要自动排序,使用TreeSet
- 如果需要快速查找和存储键值对,使用HashMap
- 如果需要按键自动排序,使用TreeMap
区别:
List接口特点:不唯一,有序的
Set接口特点:唯一,无序的(无序不等于随机,是相对于List接口部分来说的)
4. ArrayList
ArrayList是一个可变大小的数组实现,适用于需要频繁访问元素的场景,查询快,增删慢,是多线程不安全的。
在提前知道list长度的时候,可以提前指定集合的容量,这样可以减少扩容的次数,提高性能(数据量越大,效果越明显)
ArrayList源码类似StringBuilder,其中jdk1.7 中和jdk1.8版本中ArrayList实现有所不同(以下使用jdk1.8版本做说明)。
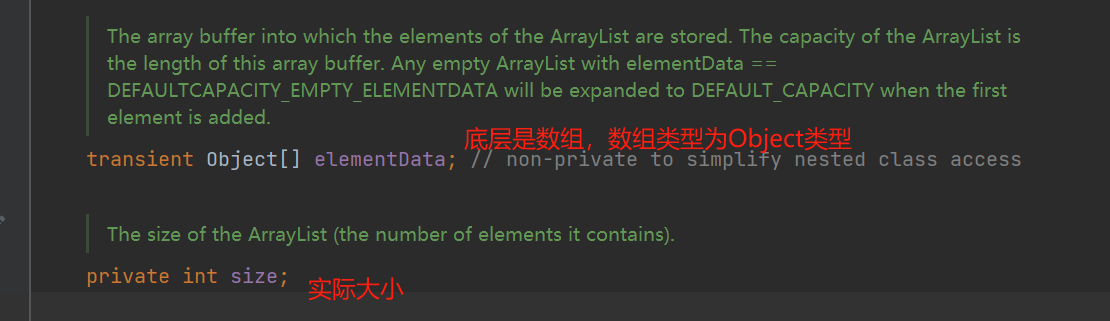
新建一个ArrayList对象,未指定大小时候,使用的数组为空。调用add后,才会确定数组长度,存实际数据

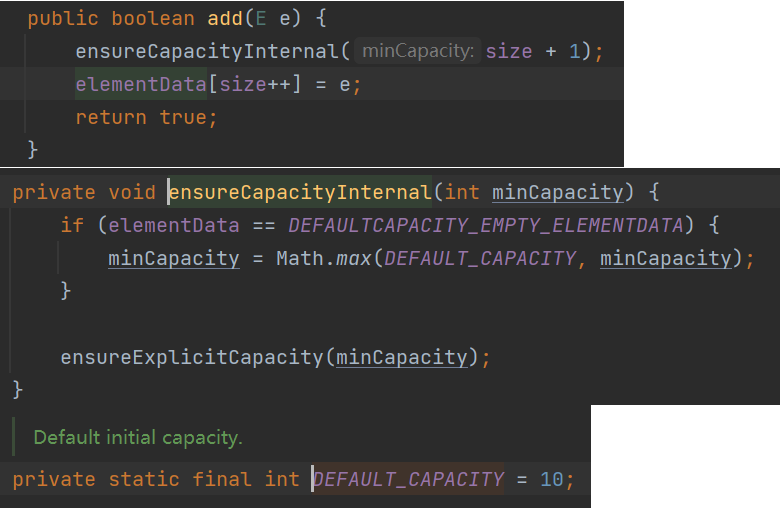
新增到空间不够了,再进行扩容
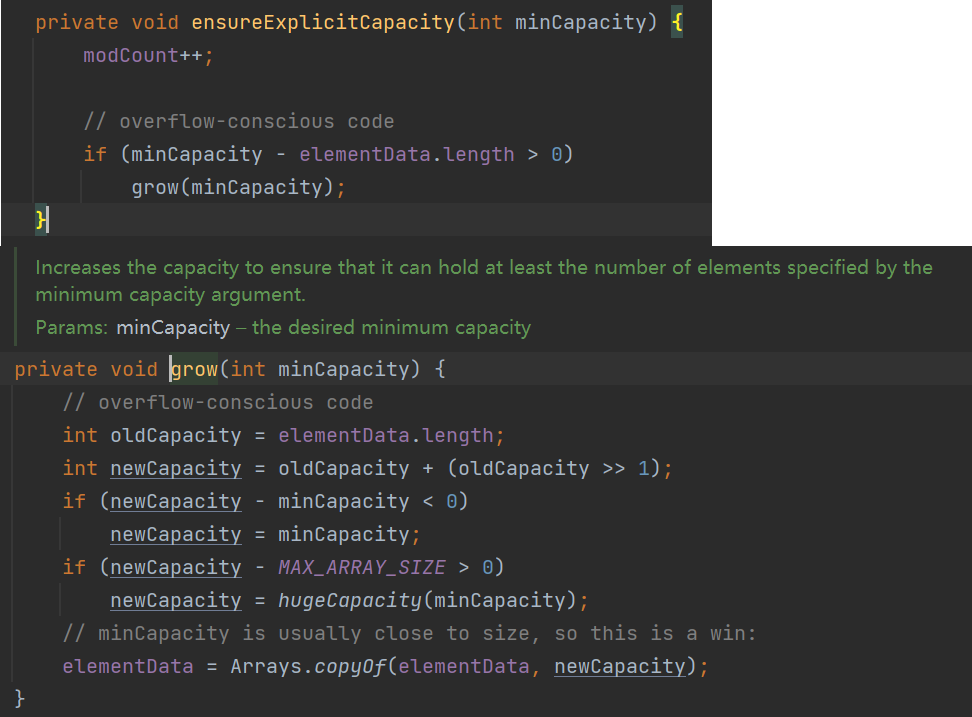
ArrayList底层的数据结构分为物理结构和逻辑结构,物理结构对应紧密结构,在内存中是连续着的,形成的逻辑结构是线性表中的数组。
public static void main(String[] args) {
List<Object> arrayList = new ArrayList<>();
arrayList.add(10);
arrayList.add(8);
arrayList.add(13);
System.out.println("arrayList中数据:" + arrayList);
arrayList.add(1, 24);
System.out.println("arrayList中数据2:" + arrayList);
arrayList.set(3, 12);
System.out.println("arrayList中数据3:" + arrayList);
arrayList.add(2);
System.out.println("arrayList中数据4:" + arrayList);
arrayList.remove(2);
System.out.println("arrayList中数据5:" + arrayList);
}
输出
arrayList中数据:[10, 8, 13]
arrayList中数据2:[10, 24, 8, 13]
arrayList中数据3:[10, 24, 8, 12]
arrayList中数据4:[10, 24, 8, 12, 2]
arrayList中数据5:[10, 24, 12, 2]
5. LinkedList
底层使用的双向链表,使用链表查找元素,所以查询慢,增删只需要替换掉指针的指向即可,所以增删快,元素按照插入的顺序排列,元素可以重复。
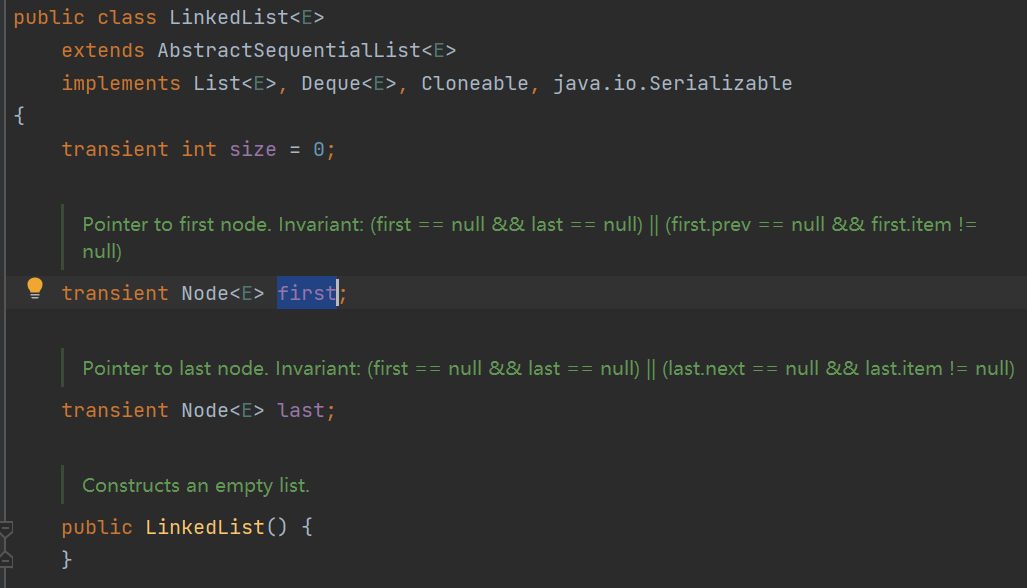
新增数据时候,创建新Node节点信息,指向上一个元素的地址
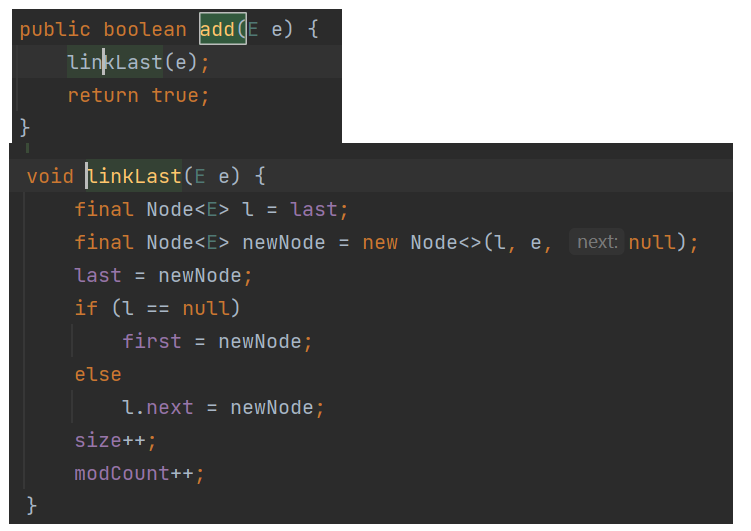
Node对象:存前一个元素的地址,当前存入的元素,下一个元素的地址,整个对象是链表中的一个节点。
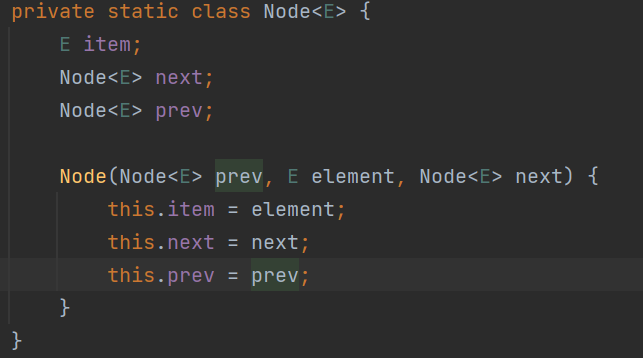
遍历LinkList的方式:
for (Object node : linkedList) {
System.out.println(node);
}
Iterator<Object> iterator = linkedList.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// 这种方式,it在for循环这个作用域内有效,for循环结束时候,it这个对象的生命周期结束,就自动消失了
for (Iterator<Object> it = linkedList.iterator(); it.hasNext(); ) {
System.out.println(it.next());
}
- LinkedList的数据结构:
- 物理结构:内存中是跳转结构,不连续的
- 逻辑结构:是线性表中的链表
6. HashSet
Set接口里没有跟索引相关的方法,意味着不能用普通for循环遍历
- 遍历方式:
- 迭代器
- 增强for循环(底层还是迭代器来的)
存放基本数据类型的数据时候,都满足唯一,无序的特点。
存放自定义类型的数据时候,没有满足唯一的特点。
HashSet集合存入的数据(以Integer类型为例):
调用对应的hashCode方法计算哈希值,哈希值是int类型的数据,再通过哈希值和一个表达式计算在数组中存放的位置。如位置冲突,则维护一个链表来存储数据,如果存放的数据重复了,不会再次放入(使用equals方法比较)
HashSet底层原理:数组+链表,即哈希表
所以,放入HashSet中的数据,一定要重写两个方法:hashCode和equals
其中底层用到了HashMap的结构
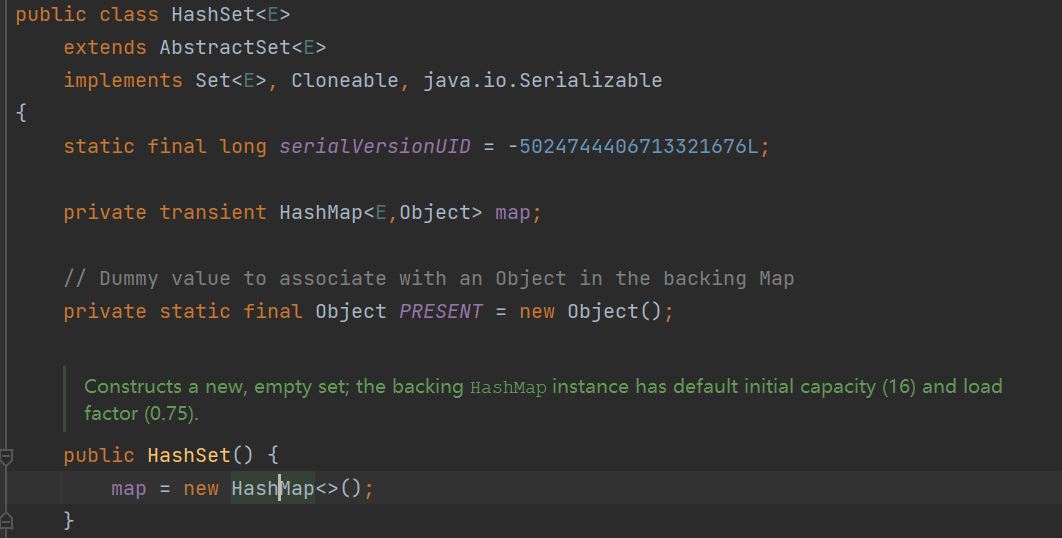
public static void hashSetTest() {
HashSet<Object> set = new HashSet<>();
set.add(12);
set.add(8);
set.add(9);
set.add(42);
set.add(14);
System.out.println(set);
}
输出:
[8, 9, 42, 12, 14]
7. LinkedHashSet
HashSet是无序的,所以出现LinkedHashSet,是唯一,有序的(按照输入顺序进行输出)
底层原理:其中就是再HashSet的基础上,多了一个总的链表,这个总链表将放入的元素串在一起,方便有序的遍历
public static void hashSetTest() {
HashSet<Object> set = new LinkedHashSet<>();
set.add(12);
set.add(8);
set.add(9);
set.add(42);
set.add(14);
System.out.println(set);
}
输出:
[12, 8, 9, 42, 14]
8. TreeSet
首先看一下比较器的内容先:
内部比较器java.lang.Comparable#compareTo,返回int类型,判断>0 =0 <0 来确定数据的大小

String类型也可以比较大小,因为实现了Comparable方法,重写了其中的compareTo方法
外部比较器:实现Comparator接口,重写compare方法
外部比较器比内部比较器好用些,因为用了多态,好扩展
然后是TreeSet的内容:
特点:唯一的,有序:可以按照升序进行遍历,没有按照输入顺序进行输出
底层是用的二叉树(逻辑结构)
其中二叉树有三种遍历方式,中序遍历、先序遍历、后序遍历
当前的TreeSet底层的二叉树使用的中序遍历,所以输出是升序的。
例如:Integer 实现了Comparable接口,所以可以比较(基本数据类型)
public static void test() {
TreeSet<Integer> set = new TreeSet<>();
set.add(6);
set.add(4);
set.add(34);
set.add(12);
System.out.println(set);
}
输出:
[4, 6, 12, 34]
如果放入自定义类型时候,自定义类型必须实现比较器,否则使用TreeSet添加数据会失败,可以使用内部比较器或者外部比较器。
public static void test() {
Comparator<User> comparator = new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
// return o1.getName().compareTo(o2.getName());
return o1.getAge() - o2.getAge();
}
};
TreeSet<User> set = new TreeSet<>(comparator);
set.add(new User(15, "娜娜"));
set.add(new User(12, "苗苗"));
set.add(new User(13, "文文"));
set.add(new User(15, "红红"));
System.out.println(set);
System.out.println(set.size());
}
输出:
[User{age=12, name='苗苗'}, User{age=13, name='文文'}, User{age=15, name='娜娜'}]
3
8. HashMap
首先Map是一个泛型接口,存储是key-value形式,称为键值对,键用key表示,值用value表示,是一对信息一起存储
HashMap的特点(在key的角度):无序,唯一的(是按照key进行总结的,因为底层key是遵循哈希表的)
哈希表的原理:比如放入集合的数据的那个类,必须重写hashCode和equals方法
一般HashMap的存放的key都是String类型的,String这个类默认重写了hashCode和equals方法
HashMap是无序的,不能按照输入顺序进行输出
9. TreeMap
这里可以和TreeSet对比着来学习
特点:唯一,有序(可以按照升序或者降序来输出)
底层原理:二叉树,这里key遵循二叉树的特点
所以放入集合中key的数据所对应的类型内部一定要实现比较器(内部比较器或者外部比较器都可以)
10. LinkedHashMap
底层在哈希表的基础上多维护了一个链表,所以可以按照输入顺序进行输出
特点:唯一(在key的角度),有序(按照输入顺序进行输出)
11. Hashtable
HashTable用起来和HashMap是一样的,当然两个也是有区别的。
区别:
HashTable是jdk1.0开始的,效率低,但是他是线程安全的,key不可以存空值。
HashMap 是jdk1.2开始的,效率高,是线程不安全的,这里key可以存空值,并且key的null值也遵循唯一的特点。
12. Vector
实际上已经很少用了,底层是Object数组,底层数组长度默认为10(当未指定长度时),底层扩容数组长度为2倍,是线程安全的

Vector和ArrayList的区别:
ArrayList底层扩容长度为原数组的1.5倍,Vector底层扩容长度为原数组的2倍。
ArrayList线程不安全,Vector是线程安全的(因为用了synchronized)