Linux基础22 进程的优先级nice, 后台进程管理, 系统平均负载, 系统启动流程, 救援模式, 单用户模式(有root权限)
进程的优先级:
nice值越高:表示优先级越低,例如19,该进程容易将CPU使用量让给其他进程。
nice值越低:表示优先级越高,例如-20,该进程更不倾向于让出CPU。
# 以设定的优先级启动 nice -n -10 tail -f /var/log/messages #重新设置一个进程的优先级(调整sshd的优先级) [root@oldboyedu ~]# renice -n -20 6684 (改完主进程变为-20,退出再登录sshd子进程也都变为-20) 6684 (process ID) old priority 0, new priority -20 6684 -20 /usr/sbin/sshd -D 9038 -20 sshd: root@pts/0 9067 -20 sshd: root@pts/1 注:java可能写了个进程,不断fork进程,占用文件描述符过多,导致oom,系统杀死线程后,进程fork出新的进程,达到死循环。此时sshd很难连接上去,很多服务页面打不开,但是都是通的 可以通过把sshd优先级调到最高,保证sshd正常连接
sshd连接不上的几种原因
1.网络 ping 10.0.0.100 2.端口 telnet 10.0.0.150 22 tcping 10.0.0.150 22 # 新买的阿里云会禁ping和telnet,可以用tcping测试 yum install -y tcping 3.用户 root 4.密码 1
nice:设置优先级
-n:指定优先级
nice -n -20 command
renice -n -5 pid
后台进程管理:
jobs:查看后台进程 # 会显示当前后台所有进程 bg:永久放到后台执行 fg:调出后台任务 # fg %1 会调出jobs中第一个任务
screen: # 后台进程管理, 可用于查看后台进程进度 -S:起名 -ls:查看后台进程的列表 -r:指定pid或者名字,进入后台进程 kill + pid 杀掉进程 退出终端:ctrl +a +d [root@oldboyedu ~]# yum install -y screen
操作举例(整套流程) [root@localhost ~]# screen # 创建终端 [root@localhost ~]# ping www.baidu.com ctrl +a +d # 退出终端,ping在后台运行(连按两次,会退出外层的终端(sshd)) [root@localhost ~]# screen -ls # 查看终端里任务pid There is a screen on: 113269.pts-0.localhost (Detached) 1 Socket in /var/run/screen/S-root. [root@localhost ~]# screen -r 113269 # 进入终端 [root@oldboyedu ~]# screen -ls # 查看终端 There is a screen on: 9461.pts-1.oldboyedu (Detached) 1 Socket in /var/run/screen/S-root. [root@oldboyedu ~]# screen -r 9461 # 进入该终端 [root@oldboyedu ~]# screen -S ping_baidu # 开一个终端,起个名 [detached from 9539.ping_baidu] [root@oldboyedu ~]# screen -ls There are screens on: 9539.ping_baidu (Detached) 9518.pts-1.oldboyedu (Detached) 9461.pts-1.oldboyedu (Detached) 3 Sockets in /var/run/screen/S-root. [root@oldboyedu ~]# screen -r ping_baidu # 进入终端 [detached from 9539.ping_baidu] [root@oldboyedu ~]# screen -r 9539 [detached from 9539.ping_baidu]
系统平均负载
cpu top上的load average 4 2 # 50%cpu没有合理利用到 2 2 # 100%cpu被用到 1 2 # 超负荷(一半的进程占用不到cpu)
企业中,一般当平均负载高于70%的时候,就需要排查负载高的问题了。
stress:是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。 [root@oldboyedu ~]# yum install -y stress mpstat:是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。 [root@oldboyedu ~]# yum install -y sysstat pidstat:是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标。 [root@oldboyedu ~]# yum install -y sysstat
测试操作 stress --cpu 4 --timeout 600 # cpu压测 查看系统平均负债 watch -d uptime # watch 动态查看 -d高亮标出变化的内容 查看cpu使用情况(判断是否是cpu引起的问题) mpstat -P ALL 5 查看哪个进程导致cpu持续上升 pidstat -u 5 1 stress --io 1000 --timeout 600 # io压测 查看系统使用情况 mpstat -P ALL 5 #CPU不高,但是io升高会导致%sys系统内核态升高 查看哪个进程导致内核态持续上升 pidstat -u 5 1 注: io的升高并不会导致系统很卡 stress -c 4 --timeout 600 # 大量进程 查看系统使用情况 mpstat -P ALL 5 #CPU上升 iostat -d 10 # 查io
总结:
1.平均负载高有可能是CPU密集型进程导致的
2.平均负载高并不一定代表CPU的使用率就一定高,还有可能是I/O繁忙
3.当发现负载高时,可以使用mpstat、pidstat等工具,快速定位到,负载高的原因,从而做出处理
系统启动流程
开机启动流程CentOS6: 1.加电自检(BIOS)检查硬件 2.内核引导MBR 3.grub菜单 --->选择系统 4.加载内核 5.加载init # 运行级别(默认为3, 5为图形化界面) 6.进入终端 开机启动流程CentOS7: 1.加电自检(BIOS)检查硬件 2.内核引导MBR 3.grub菜单 --->选择系统 4.加载内核 5.加载Systemd # 不再使用init, 改成systemd 6.进入终端
单用户模式(有root权限)
1. 启动界面下,按e进入单用户模式
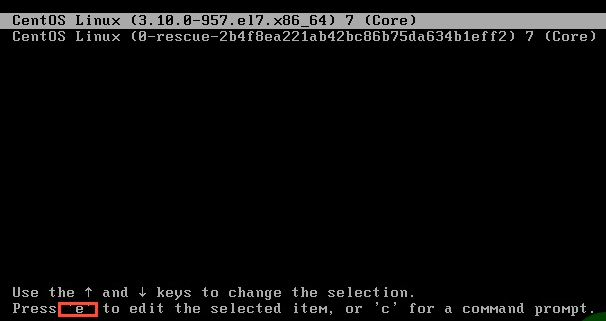
2.输入rd.break, 然后ctrl+x
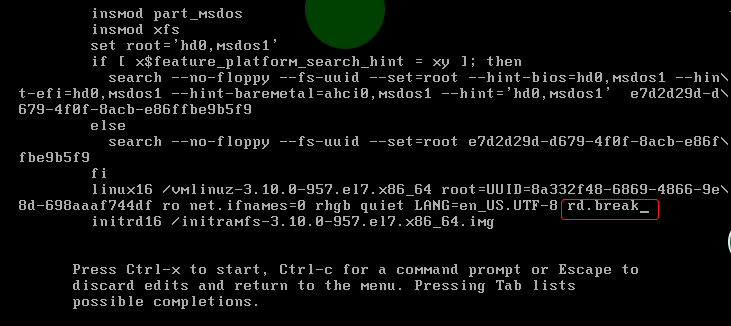
3.挂载 mount -o rw,remount /sysroot/ (挂载这个目录才能获得root权限)
4.输入 chroot /sysroot/

5. exit
6.reboot
救援模式
Linux系统无法启动,且单用户模式也无法启动,需要进入救援模式。
1.开启虚拟机,鼠标点击控制台启动页面,同时迅速按下ESC键,一定要快,然后选择选项3,CD-ROM Drive启动
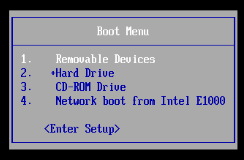
另一种vmware点打开电源进入固件,在虚拟机BIOS界面,将CD-ROM虚拟机调整为第一启动项,然后重新启动。
2.进入Troubleshooting
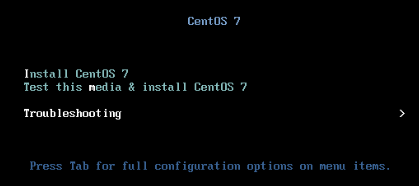
3.选择Rescue a CentOS system, 进入救援模式

4.输入1
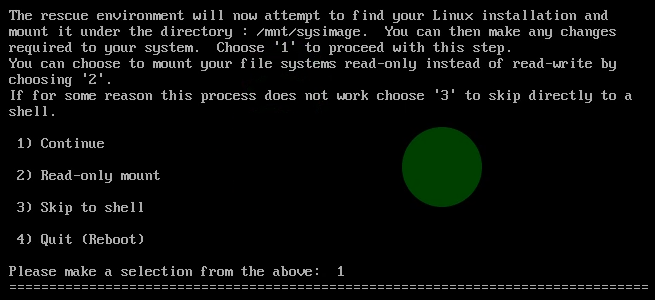
5. 输入 chroot /mnt/sysimage获取root权限
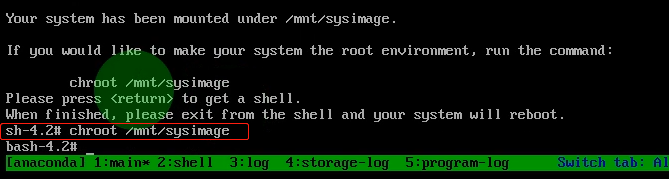
6. 磁盘修复
grub2-install /dev/sda
7.exit
8.reboot