5分钟带你回顾大文件分片以及异步计算hash的步骤
背景
文件上传功能在中后台项目中是最常见的功能,分片上传是一种将大文件分割成多个小片段进行上传的技术,可以有效提高文件上传的速度和稳定性。
思路
1.首先就是使用File.slice对文件进行分割产出一个数组用于存储每个小的chunk片段
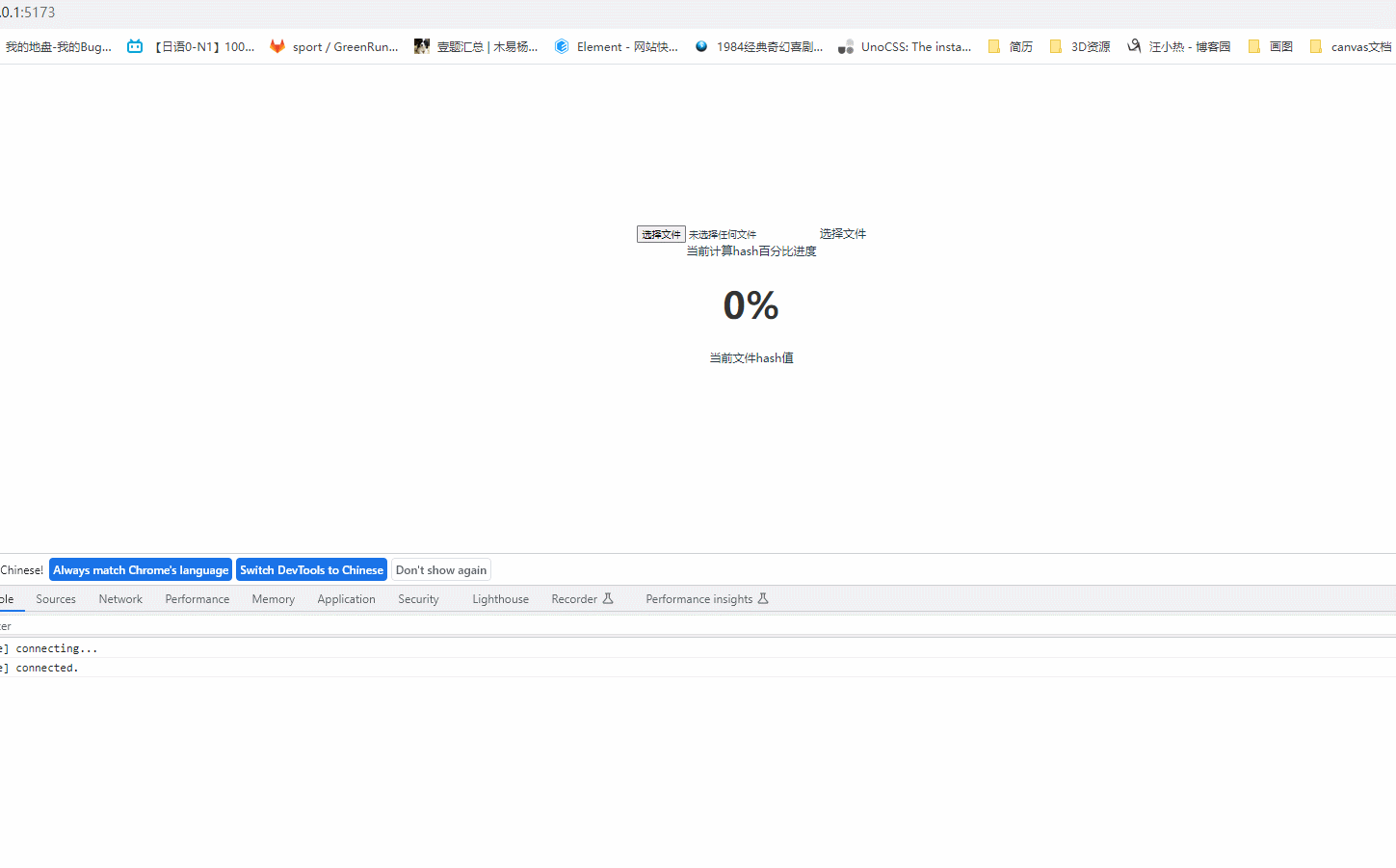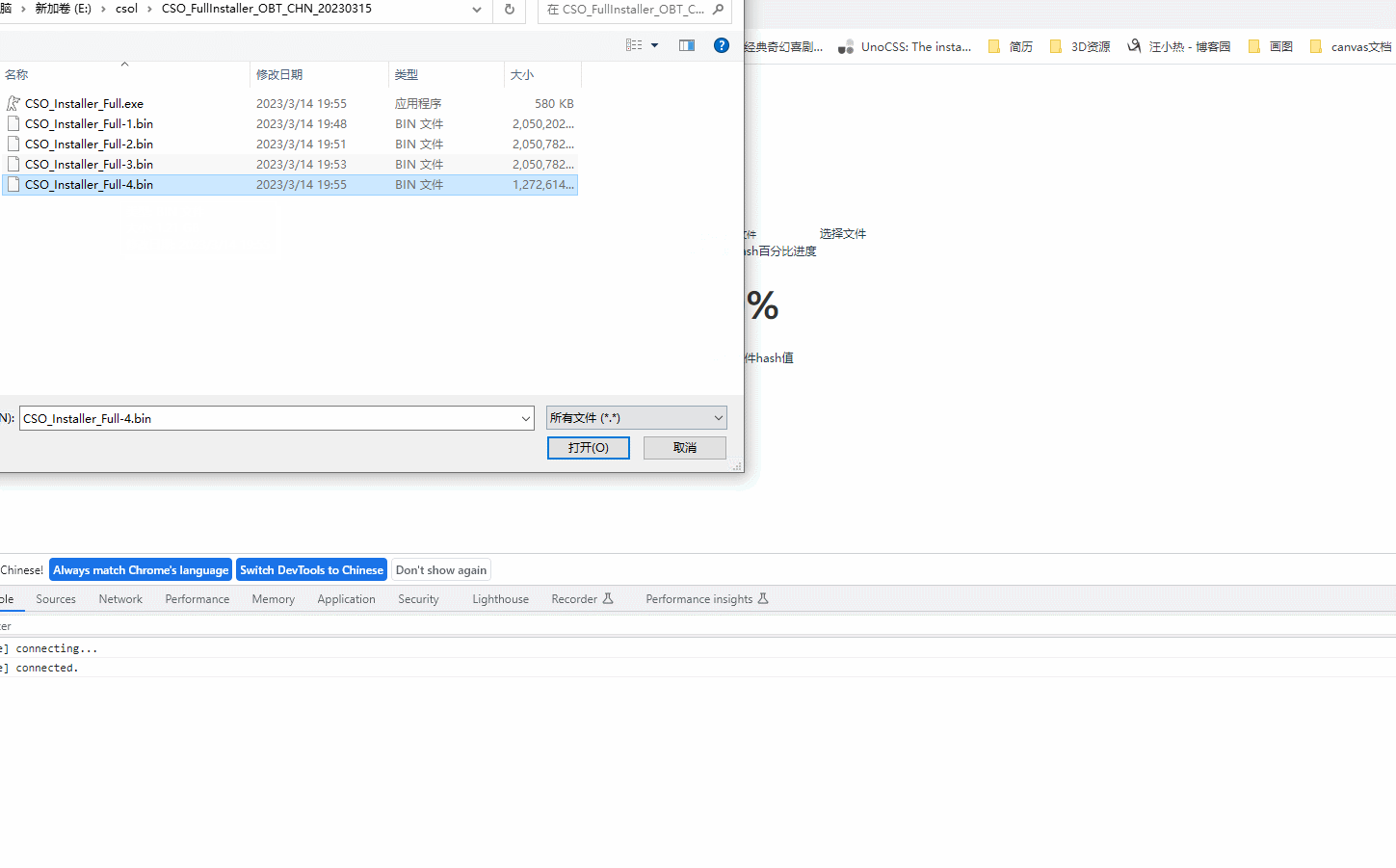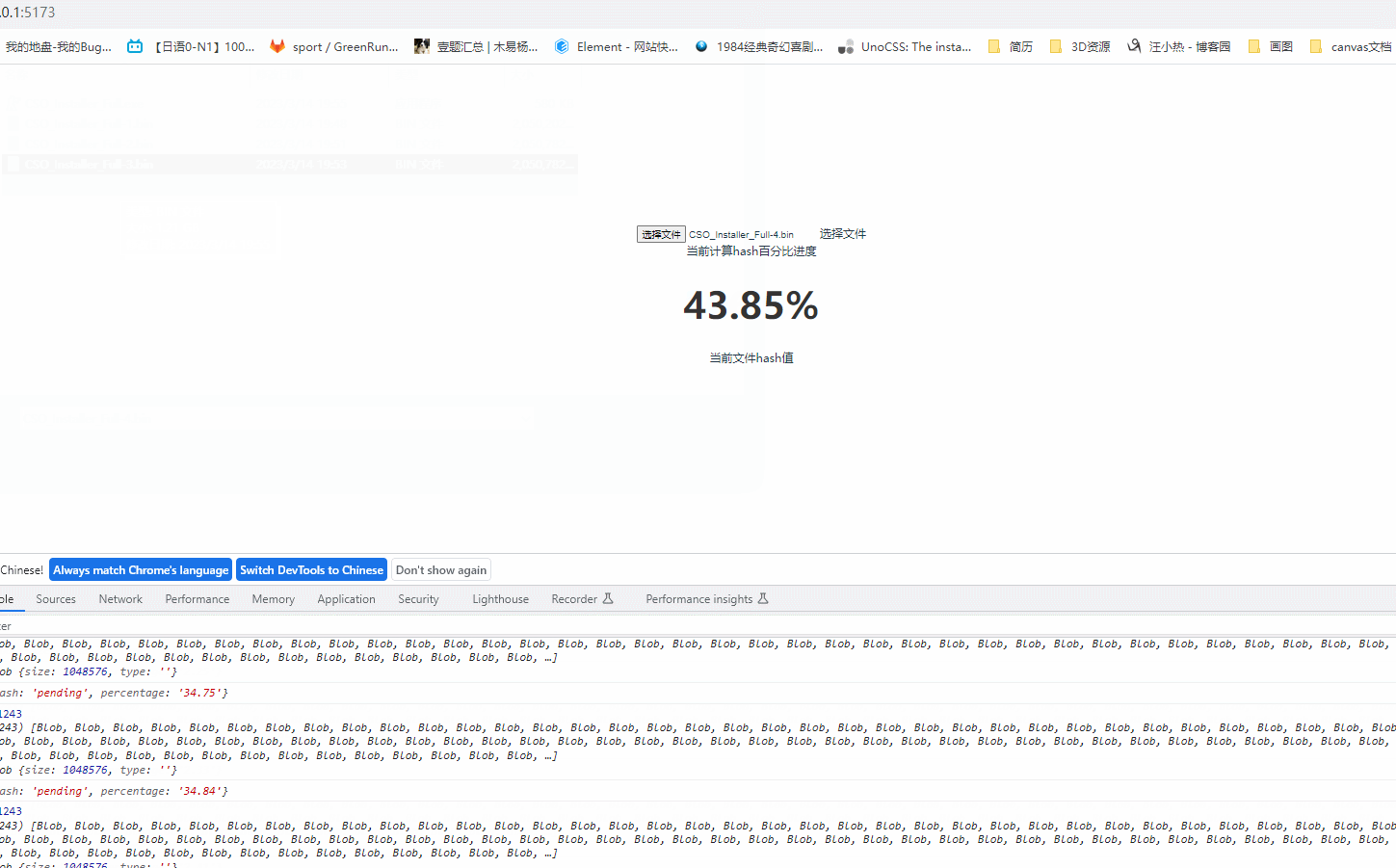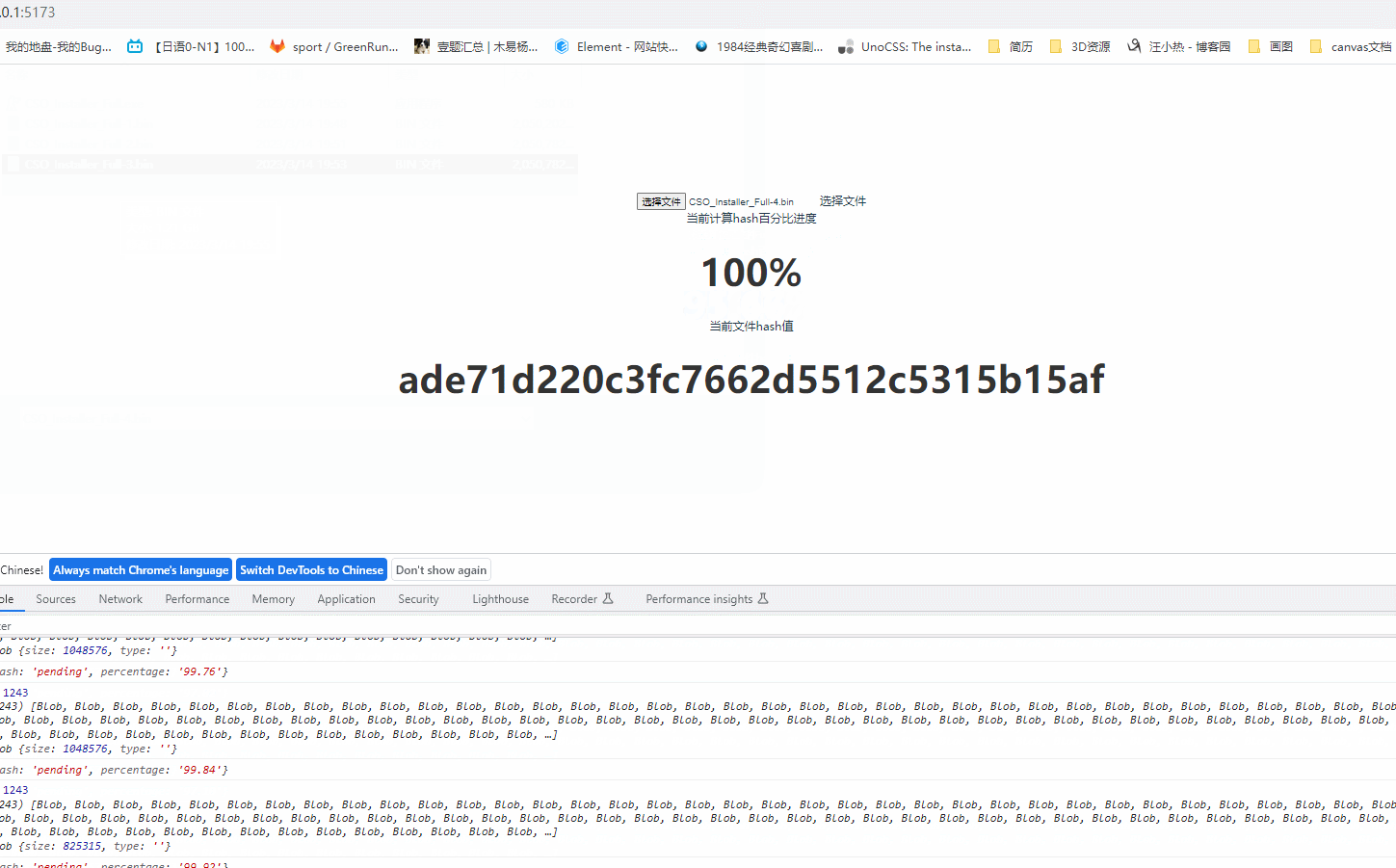
2.异步计算hash值,可用作标识文件进而实现文件的断点续传、秒传等功能,这里我们采用spark-MD5计算文件hash值
3.在计算hash的时候,特别是文件比较大的时候就会明显感觉应用卡顿,所以采用webworker的方式另外开一个线程去计算文件hash值
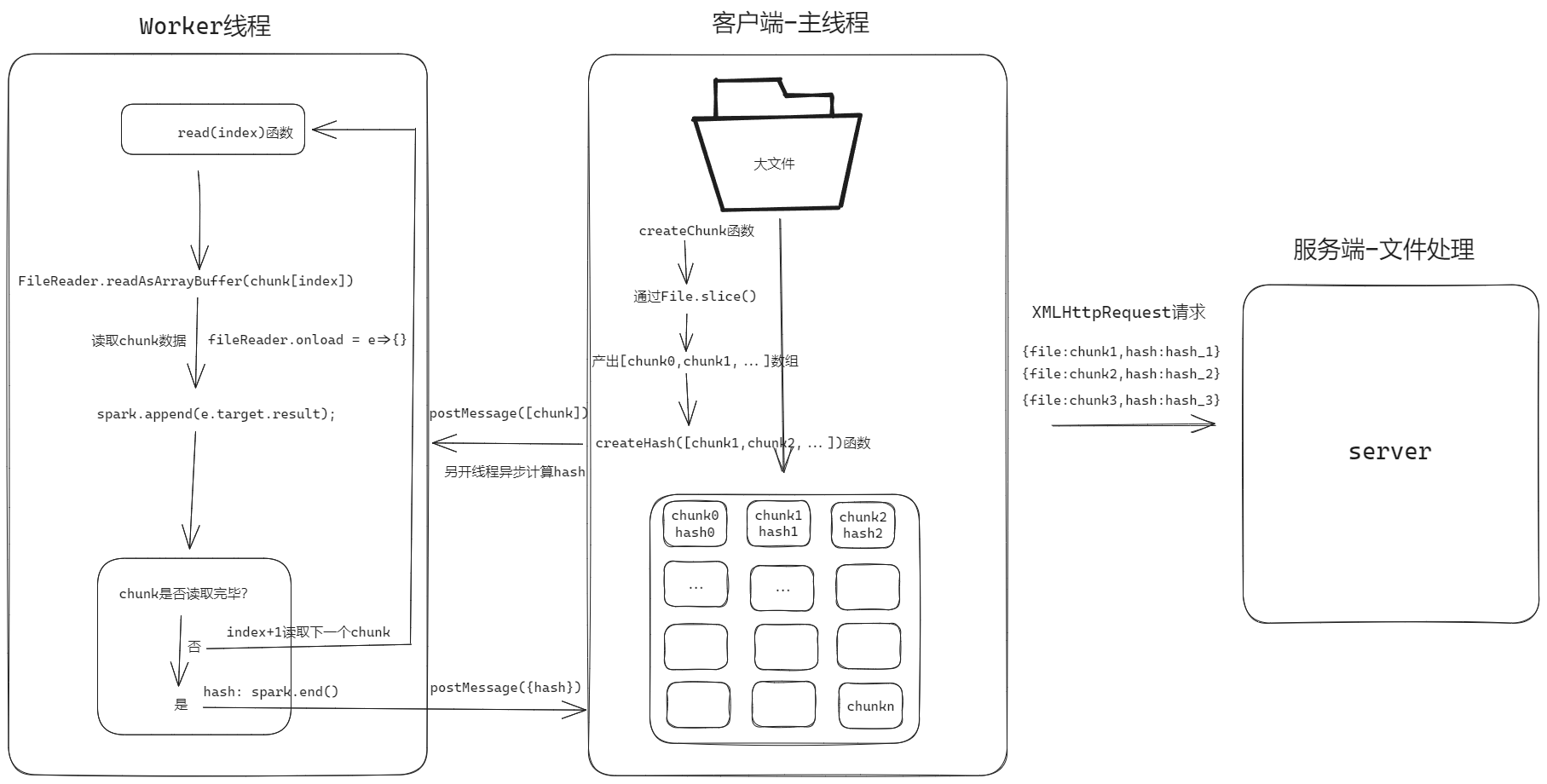
实现
本文基于vue作简单实现
1.简单布局-主要是一个input标签,加上用于展示当前计算hash值的进度。
<template>
<div>
<div>
<input
@change="handleChange"
ref="inputRef"
type="file"
/>选择文件
</div>
当前计算hash百分比进度<h1 style="color:#fff">{{ precentageRef }}%</h1>
</div>
</template>
2.创建切片功能函数
const createFileChunk = (file, size = 1024 * 20) => { //可根据传入尺寸确定单个chunk大小
const chunk = [];
for (let i = 0; i < file.size; i += size) {
chunk.push(file.slice(i, i + size));
}
return chunk;
};
3.创建hash读取函数
const createHash = async (file) => { //采用异步读取,主要将file传给worker读取
return new Promise((resolve) => {
const myWorker = new Worker(); // 创建worker
myWorker.postMessage({ file });//将要读取hash的文件传给worker
myWorker.onmessage = (e) => {//读取的过程,用onmessage监听,可以设置读取进度百分比
const {percentage,hash}=e.data
precentageRef.value=percentage//将百分比实时展示
if(percentage>=100){//如果到了100%代表已经读取完毕,就resolve出去
resolve(hash)
}
};
});
};
4.创建worker读取文件hash
import SparkMD5 from 'spark-md5'
let percentage = 0;//初始化百分比
self.onmessage = (e) => {
const { file } = e.data;//拿到传过来的文件
const spark = new SparkMD5();
function _read(index) {//index为读取的文件chunk下标
let fileReader = new FileReader();//创建fileReader对文件chunk进行数据读写,并将内容拿给sparkMD5计算hash
fileReader.readAsArrayBuffer(file[index]);
fileReader.onload = (e) => {
spark.append(e.target.result)
if (index >= file.length-1) {//如果读取完毕就向外发送读取完毕消息
self.postMessage({
hash: spark.end(),
percentage:100
});
} else {//否则递归读取下一个chunk
percentage+=100/file.length
self.postMessage({
hash: 'pending',
percentage:percentage
});
_read(index + 1);
}
};
}
_read(0);
};
这就是文件分片以及异步计算hash的简化流程。
完整代码:
fileLoader.vue
<template>
<div>
<div>
<input
@change="handleChange"
ref="inputRef"
type="file"
/>选择文件
</div>
当前计算hash百分比进度<h1 style="color:#fff">{{ precentageRef }}%</h1>
</div>
</template>
<script setup>
import Worker from '../worker.js?worker'
import {ref} from 'vue'
const precentageRef=ref(0)
const handleChange = async (e) => {
const { files } = e.target;
if(!files)return
let c = createFileChunk(files[0],1024*1024);
const hash = await createHash(c);
if (hash) {
console.log(c, hash);
}
};
const handleClick=()=>{
alert(1)
}
const createFileChunk = (file, size = 1024 * 20) => {
const chunk = [];
for (let i = 0; i < file.size; i += size) {
chunk.push(file.slice(i, i + size));
}
return chunk;
};
const createHash = async (file) => {
return new Promise((resolve) => {
const myWorker = new Worker(); // 创建worker
myWorker.postMessage({ file });
myWorker.onmessage = (e) => {
console.log(e.data);
const {percentage,hash}=e.data
precentageRef.value=percentage
if(percentage>=100){
resolve(hash)
}
}; // Greeting from Worker.js,worker线程发送的消息
});
};
</script>
<style lang="scss" scoped></style>
worker.js
import SparkMD5 from 'spark-md5'
let percentage = 0;
self.onmessage = (e) => {
const { file } = e.data;
const spark = new SparkMD5();
function _read(index) {
let fileReader = new FileReader();
console.log(index,file.length,file,file[index])
fileReader.readAsArrayBuffer(file[index]);
fileReader.onload = (e) => {
spark.append(e.target.result);
if (index >= file.length-1) {
self.postMessage({
hash: spark.end(),
percentage:100
});
} else {
percentage+=100/file.length
self.postMessage({
hash: 'pending',
percentage:percentage.toFixed(2)
});
_read(index + 1);
}
};
}
_read(0);
};
效果:UI界面比较low!!!