分享
Elasticsearch 分词
为什么自定义分词
当 Elasticseach 自带的分词器无法满足时,可以自定义分词器,通过自组合不同的组件实现
-
Character Filter
-
Tokenizer
-
Token Filter
Character Filter
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符,可以配置多个 Character Filter 。
自带的 Character Filter
HTML strip —— 移除 html 标签
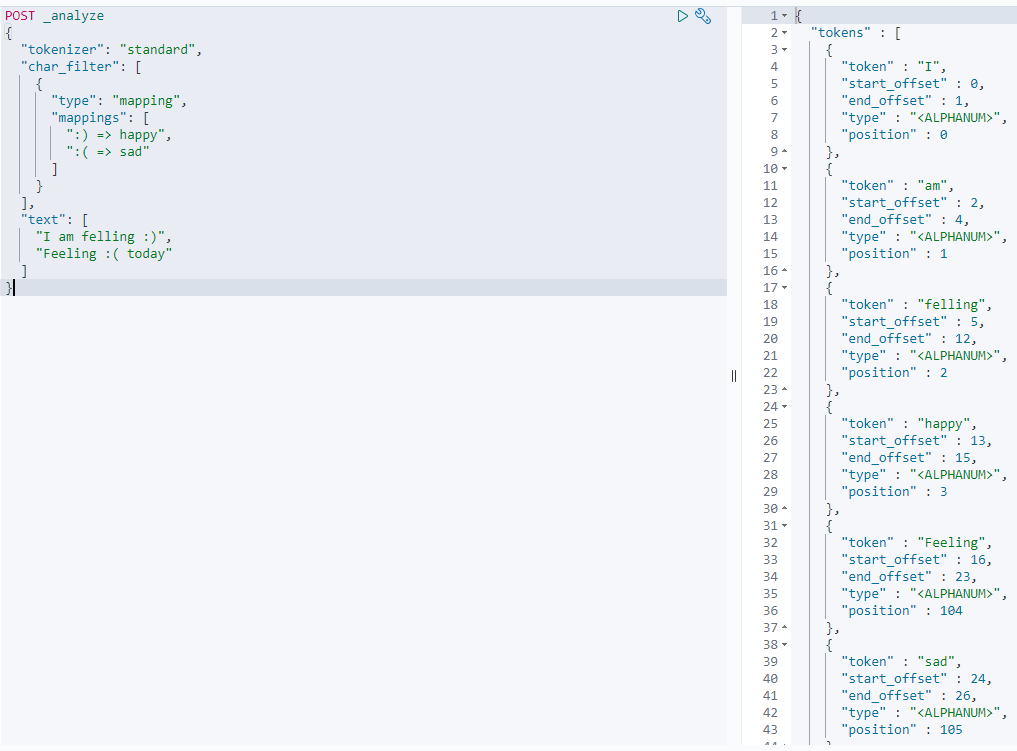
Mapping —— 字符串替换
Pattern —— 正则匹配替换
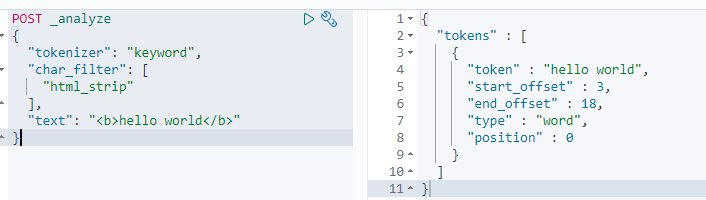
Tokenizer
将原始的文本按照一定的规则,切分为词(term or token),也可以用 java 开发插件,实现自己的 Tokenizer
内置的 Tokenizer
whitespace/standard/uax_url_email/pattern/keyword/path hierarchey
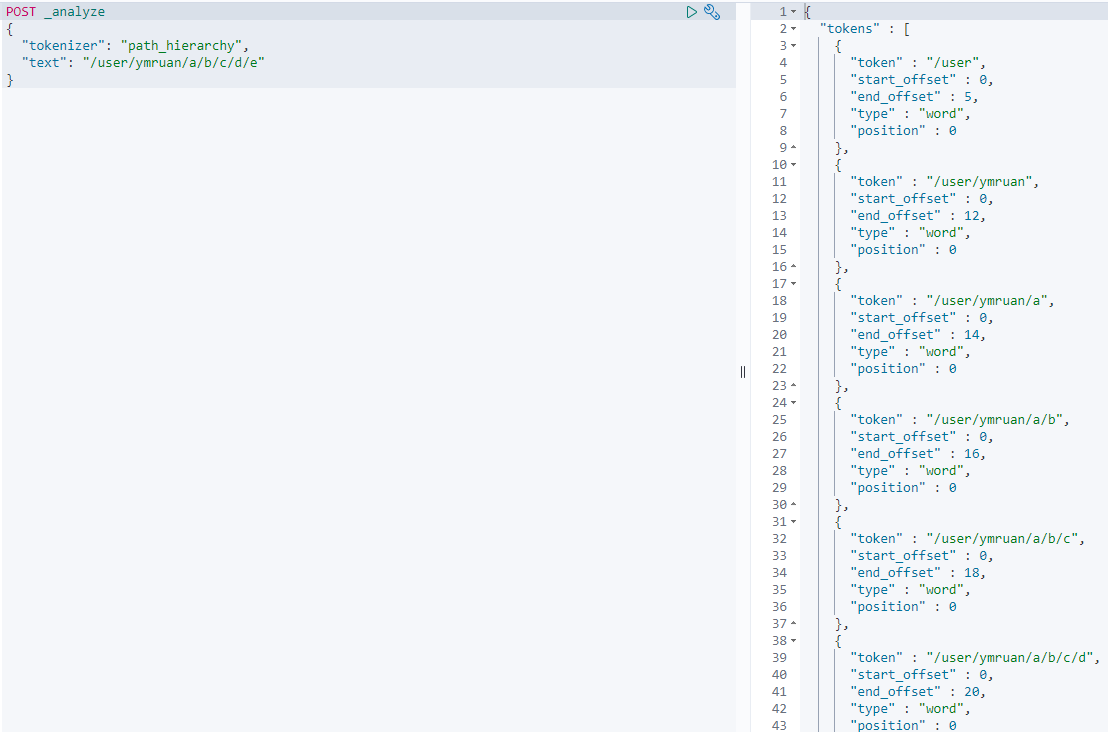
Tokenizer Filter
将 Tokenizer 输出的单词,进行增加,修改,删除
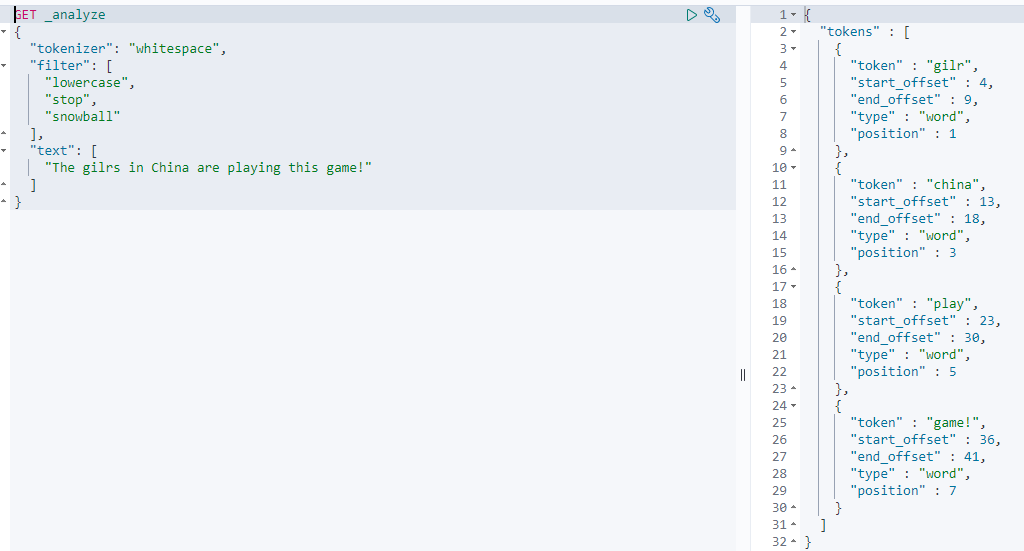
自带的 Token Filter
-
Lowercase
-
stop
-
synonym(添加近义词)
使用char filter 替换表情符号
lowercase stop snowball 组合使用
正则表达式 pattern

改善用户搜索体验
使用 suggester改善用户的搜索体验,即改正用户拼写错误和构建高效的自动补全机制,改善用户搜索体验最简单的方式之一是纠正拼写错误要么自动的,要么仅显示正确的查询短语。
Elasticsearch 目前允许我们使用4种 suggester: term suggester phrase suggester completion suggester 和 context suggester
前两种 suggester 可以用来改正用户拼写错误,后两种suggester 能够用来开发出迅捷且自动化的补全功能。
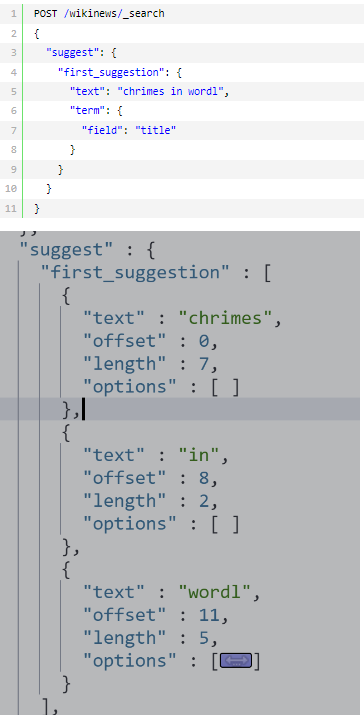
term suggester 基于单个词项的拼写纠错
term suggester 基于编辑距离来运作,这意味着,增删改某些字符串转化为原词的改动越少,这个建议词就越有可能是最佳选择。拿worl和work举例,距离worl转化为work,改动了一个字符,
因此编辑距离为1。
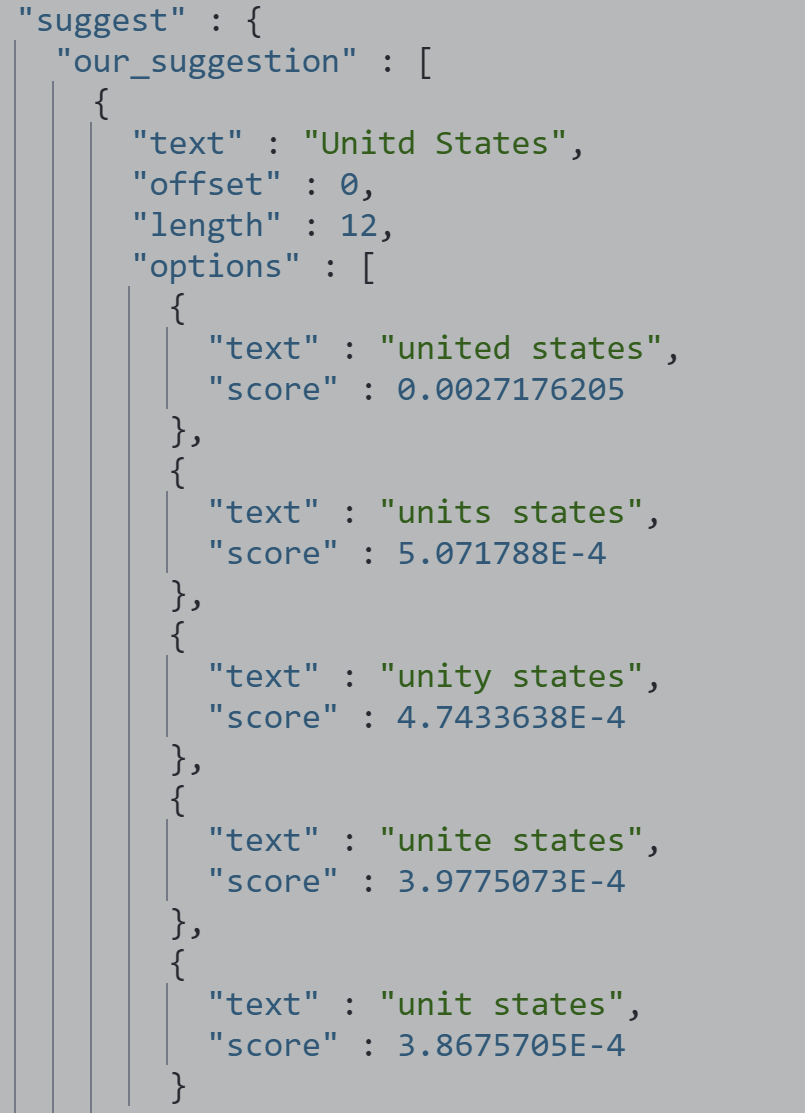
phrase suggester 基于短语的纠错
POST /wikinews/_search
{
"suggest": {
"text": "Unitd States",
"our_suggestion": {
"phrase": {
"field": "text"
}
}
}
}
返回的是完整的短语建议,而不是针对单个词项的建议
completion suggester
term 和 phrase suggester 都是用来提供建议的,completion 是一个基于前缀的 suggester 可以用非常高效的方法实现自动完成(当在敲键盘时它就在搜索)的功能,与用户的拼写错误无关
建立索引

运行suggest

案例:实现自己的自动完成功能
很多时候,自动完成功能只支持前缀查询就够了,有些时候用户需要实现更通用的残缺词完成功能, completion 就不能胜任这样的需求了,另一个限制是不支持高级查询和过滤器。为解决这些不足,基于 n-grams实现一个定制的自动完成功能,可以胜任几乎所有的场景。
创建索引
PUT /location-suggestion
{
"settings": {
"index.max_ngram_diff": 20,
"analysis": {
"filter": {
"nGram_filter": {
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol",
"whitespace"
],
"min_gram": "2",
"type": "nGram",
"max_gram": "20"
}
},
"analyzer": {
"nGram_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"nGram_filter"
],
"type": "custom",
"tokenizer": "whitespace"
},
"whitespace_analyzer": {
"filter": [
"lowercase",
"asciifolding"
],
"type": "custom",
"tokenizer": "whitespace"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "nGram_analyzer",
"search_analyzer": "whitespace_analyzer"
},
"country": {
"type": "keyword"
}
}
}
}
字符组:whitespace,letter, digit, punctuation, symbol 可以使用单个例如 -
token_chars: ["whitespace","-"]
letter 遇到非字母时分割文本
digit 数字,例如3或7
punctuation 标点,例如!或"
symbol 标记 例如$或√
(1)配置 settings
这里的 settings 包含两个定制的 analyzer: nGram_analyzer 和 whitespace_analyzer ,使用空格分词器定制一个 witespace_analyzer , 这样所有的 token 都以小写和 asci 格式索引起来
nGram_analyzer 有两个定制的过滤器 nGram_filter ,用到了下面这些参数:
type: 描述了 token 过滤器的类型
token_chars :描述在生成的字符中怎样的字符是合法的。标点和特殊字符都会被从字符流中除掉,但在例子中故意保留了下来;也保留了空格, 因此只要文中包含了United Status,那么当用户搜索us时,United Status就会出现在搜索列表中。
min_gram 和 max_gram 这两个属性设置了生成的字符串的最小和最大长度,并把他们加入搜索表。比如本文索引设置,India这个词将产生如下的字符 [ “di”, "dia", "ia", "ind", "indi", "nd", "ndi", "ndia" ]
(2)配置 mappings
这里索引的文档类型是 locations ,他有两个字段 name 和country。为name字段定义 analyzer的方法是用于自动推荐的。这个字段的索引分析器被设置成 nGram_analyzer的方法是用于自动推荐的。这个字段的索引分析器被设置成 Ngram_analyzer ,而搜索分析器则设置成 whitespace_analyzer。
索引文档
PUT /location-suggestion/_doc/1
{"name":"Bradford","country":"england"}
PUT /location-suggestion/_doc/2
{"name":"Bridport","country":"england"}
PUT /location-suggestion/_doc/3
{"name":"San Diego Country Estates","country":"usa"}
PUT /location-suggestion/_doc/4
{"name":"Ike’s Point, NJ","country":"usa"}
用自动完成功能搜索文档
POST /location-suggestion/_search
{
"query": {
"match": {
"name": "ke’s"
}
}
}