大数据指北
hadoop
概念解释
hadoop有很多工作项目,辅助计算的,负责存储的,负责文件调度,所以是一个生态
一般是指:Hadoop HDFS分布式存储系统, Hadoop MapReduce分布式计算系统, Hadoop YARN分布式资源调度系统, Apache Hive 分布式SQL引擎, Sqoop数据采集工具, 这些在离线计算方面的Apache体系。
如何理解分布式与集群,二者区别是什么?
分布式是指不同的业务分布在不同的地方,集群指的是将几台服务器集中在一起,实现同一业务。
学习笔记 :
名词简介
大数据生态圈:

分布式和集群的概念
相同点: 都是由多台机器组成的 ;
不同点 : 分布式 多台机器 , 每台机器部署不同的组件;
集群: 多台机器 , 每台机器部署相同的组件;
Hadoop集群概述:

Hadoop安装包目录结构介绍

Tips:

数据与元数据:
数据
指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
元数据
元数据(metadata)又称之为解释性数据,记录数据的数据;
文件系统元数据一般指___文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息。(Important)___
HDFS

-
HDFS(Hadoop Distributed File System ),意为:Hadoop分布式文件系统。
-
是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据的存储
-
HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
-
HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和 PB)。
-
HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
名字
特点
(1)主从架构
-
HDFS集群是标准的master/slave主从架构集群。
-
一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
-
Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
-
官方架构图中是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上
(2)分块
-
HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。
-
块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。
(3)副本机制
-
文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
-
副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本.
-
(4)元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
-
文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块
-
文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
(5)namespace
-
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
-
Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
-
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dira/dir-b/dir-c/file.data.
(6)数据块存储
- 文件的各个block的具体存储管理由DataNode节点
- 每一个block都可以在多个DataNode上存储。
操作系统四大分类 :
桌面操作系统 : 图形化界面 Mac OS , Windows , Linux
服务器操作系统 : 一般指的是安装在大型计算机上的操作系统 ,
嵌入式操作系统 : 完全嵌入受控制器件内部 , 为特定应用而设计的专用计算机系统;
移动设备操作系统 : 主要应用在智能手机 , 平板, 等智能设备上 ;
操作系统的核心部分简称内核;
ssh协议 :
是一种网络安全协议 , 为远程登录会话和其他网络服务提供安全性的协议.
在Linux系统中 , ssh主要用途由 : 用户加密实现远程登录, 服务器之间的免密登录,
ssh协议默认使用rsa算法实现非对称加密 ,需要两个密钥 : 公钥和私钥
公钥和私钥是一对 , 如果使用公钥对数据进行加密 ,只用用对应的私钥才能解密 ;
ssh加密实现远程登录的步骤 :
- 客户端向服务器端发起ssh请求 ;
- 服务器接收到请求 , 发送公钥给客户端 ;
- 客户端输入用户名和密码 进行公钥加密 , 回传给客户端 ;
- 服务器通过私钥解密得到用户名和密码和本地进行对比 ,验证成功 , 允许登录 , 否则再次验证 ;
具体的操作步骤:
ssh免密登录
Linux版本:CentOS7.9
1. 修改配置文件`/etc/ssh/sshd_config`
# 1. 打开配置文件
vim /etc/ssh/sshd_config
# 2. 在配置文件中配置如下内容
PubkeyAuthentication yes # 43行,将注释取消即可
AuthorizedKeysFile .ssh/authorized_keys # 47行,配置文件默认内容,无需修改
# 3. 退出保存
2. 重启ssh服务
systemctl restart sshd
3. 生成公钥文件id_rsa.pub
# 1. 在用户目录下创建一个文件夹.ssh,root用户如下:
mkdir /root/.ssh
# 2. 进入.ssh目录
cd /root/.ssh
# 3. 生成公钥文件id_rsa.pub
ssh-keygen -t rsa # 一路enter,不要自定义名称
# 4. 在.ssh目录下创建authorized_keys文件(有可以不创建)
touch authorized_keys
# 5. 文件授权
chmod 700 /root/.ssh
chmod 600 authorized_keys
4. 复制id_rsa.pub内容到authorized_keys文件中
# .ssh目录下,通过重定向将公钥文件内容复制到authorized_keys文件中
cat id_rsa.pub > authorized_keys
5. 复制配置文件到集群中的其它主机
# 例:复制配置文件到hadoop101
scp /etc/ssh/sshd_config
root@hadoop101:/etc/ssh/
scp -r /root/.ssh
root@hadoop101:/root
# 在hadoop101中执行如下操作
# 重启ssh服务
systemctl restart sshd
# 在.ssh目录下生成公钥文件
cd /root/.ssh
ssh-keygen -t rsa # 一路enter,不要自定义名称。Override?yes
# .ssh目录下,通过追加重定向将公钥文件内容复制到authorized_keys文件中
cat id_rsa.pub >> authorized_keys
# 在其它主机上重复如上操作,将所有主机的公钥内容都复制到authorized_keys文件中
6. 将包含所有主机公钥内容的authorized_keys文件分发到集群中所有主机上
# 方式1. 调用自定义分发脚本
xsync /root/.ssh/authorized_keys
# 方式2. 使用scp一台主机一台主机的复制,如:复制到hadoop100主机
scp /root/.ssh/authorized_keys root@hadoop100:/root/ssh
7. 配置完毕,可以使用ssh命令测试是否成功。
# 在hadoop100主机上连接hadoop101
ssh hadoop101
Linux 操作系统常用命令 :
ls : 查看当前目录下所有文件和文件夹的名称 ;
cd : 切换到指定目录 ;
mkdir : 在指定目录下创建一个文件夹 ;
rm : 用于删除文档 ;
MapReduce
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。

Hadoop---分布式安装
建立主服务文件夹
mkdir -p /export/server
配置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
进入配置文件,将IP改为静态的IP(三台都需要做,最好递增)

Hadoop集群分布式安装
-
集群规划
主机 角色 node1 NN DN RM NM node2 SNN DN NM node3 DN NM -
基础环境
3台机器都需要操作
# 主机名 cat /etc/hostname # hosts映射 vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.88.151 node1 192.168.88.152 node2 192.168.88.153 node3 # JDK 1.8安装 上传 jdk-8u241-linux-x64.tar.gz到/export/server/目录下 cd /export/server/ tar zxvf jdk-8u241-linux-x64.tar.gz #配置环境变量 vim /etc/profile export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #重新加载环境变量文件 source /etc/profile # 集群时间同步 ntpdate ntp5.aliyun.com # 防火墙关闭 firewall-cmd --state #查看防火墙状态 systemctl stop firewalld.service #停止firewalld服务 systemctl disable firewalld.service #开机禁用firewalld服务 # ssh免密登录(只需要配置node1至node1、node2、node3即可) #node1生成公钥私钥 (一路回车) ssh-keygen #node1配置免密登录到node1 node2 node3 ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3 -
上传Hadoop安装包到node1 /export/server
hadoop-3.3.0-Centos7-64-with-snappy.tar.gz tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -
修改配置文件(配置文件路径 hadoop-3.3.0/etc/hadoop)
-
hadoop-env.sh
#文件最后添加 export JAVA_HOME=/export/server/jdk1.8.0_241 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
core-site.xml
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 文件系统垃圾桶保存时间 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
hdfs-site.xml
<!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node2:9868</value> </property> -
mapred-site.xml
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- MR程序历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> -
yarn-site.xml
<!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 历史日志保存的时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> -
workers
node1 node2 node3
-
-
分发同步hadoop安装包
cd /export/server scp -r hadoop-3.3.0 root@node2:$PWD scp -r hadoop-3.3.0 root@node3:$PWD -
将hadoop添加到环境变量(3台机器)
vim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile #别忘了scp给其他两台机器哦 -
Hadoop集群启动
-
(首次启动)格式化namenode
hdfs namenode -format -
脚本一键启动
[root@node1 ~]# start-dfs.sh Starting namenodes on [node1] Last login: Thu Nov 5 10:44:10 CST 2020 on pts/0 Starting datanodes Last login: Thu Nov 5 10:45:02 CST 2020 on pts/0 Starting secondary namenodes [node2] Last login: Thu Nov 5 10:45:04 CST 2020 on pts/0 [root@node1 ~]# start-yarn.sh Starting resourcemanager Last login: Thu Nov 5 10:45:08 CST 2020 on pts/0 Starting nodemanagers Last login: Thu Nov 5 10:45:44 CST 2020 on pts/0 -
Web UI页面
- HDFS集群:http://node1:9870/
- YARN集群:http://node1:8088/
-
-
错误1:运行hadoop3官方自带mr示例出错。
-
错误信息
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration: <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value> </property> -
解决 mapred-site.xml,增加以下配置
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>
-
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序

特点
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
Hive的优缺点
优点
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
避免了去写MapReduce,减少开发人员的学习成本。
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
Hive架构原理

1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型 (是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库 完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
Hive运行机制示意图

总结
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive安装

Mysql安装
-
卸载Centos7自带的mariadb
[root@node3 ~]# rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 [root@node3 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps [root@node3 ~]# rpm -qa|grep mariadb [root@node3 ~]# -
安装mysql
mkdir /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar #执行安装 yum -y install libaio [root@node3 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%) -
mysql初始化设置
#初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004 -
修改root密码 授权远程访问 设置开机自启动
[root@node2 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "hadoop"; Query OK, 0 rows affected (0.00 sec) #授权 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld #建议设置为开机自启动服务 [root@node2 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node2 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabled -
Centos7 干净卸载mysql 5.7
#关闭mysql服务 systemctl stop mysqld.service #查找安装mysql的rpm包 [root@node3 ~]# rpm -qa | grep -i mysql mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #卸载 [root@node3 ~]# yum remove mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #查看是否卸载干净 rpm -qa | grep -i mysql #查找mysql相关目录 删除 [root@node1 ~]# find / -name mysql /var/lib/mysql /var/lib/mysql/mysql /usr/share/mysql [root@node1 ~]# rm -rf /var/lib/mysql [root@node1 ~]# rm -rf /var/lib/mysql/mysql [root@node1 ~]# rm -rf /usr/share/mysql #删除默认配置 日志 rm -rf /etc/my.cnf rm -rf /var/log/mysqld.log
Hive的安装
-
上传安装包 解压
tar zxvf apache-hive-3.1.2-bin.tar.gz -
解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/ -
修改配置文件
-
hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib -
hive-site.xml
vim hive-site.xml<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hadoop</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration>
-
-
上传mysql jdbc驱动到hive安装包lib下
mysql-connector-java-5.1.32.jar -
初始化元数据
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表 -
在hdfs创建hive存储目录(如存在则不用操作)
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse -
启动hive
-
1、启动metastore服务
#前台启动 关闭ctrl+c /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志 /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #后台启动 进程挂起 关闭使用jps+ kill -9 nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
-
-
2、启动hiveserver2服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上 -
3、beeline客户端连接
-
拷贝node1安装包到beeline客户端机器上(node3)
scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/ -
错误
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root (state=08S01,code=0)-
修改
在hadoop的配置文件core-site.xml中添加如下属性: <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> -
连接访问
/export/server/apache-hive-3.1.2-bin/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 beeline> root beeline> 直接回车
-
-
-
错误解决:Hive3执行insert插入操作 statstask异常
-
现象
在执行insert + values操作的时候 虽然最终执行成功,结果正确。但是在执行日志中会出现如下的错误信息。
-
开启hiveserver2执行日志。查看详细信息
2020-11-09 00:37:48,963 WARN [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. setPartitionColumnStatistics ERROR [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] exec.StatsTask: Failed to run stats task
-
但是 此错误并不影响最终的插入语句执行成功。
-
分析原因和解决
-
statstask是一个hive中用于统计插入等操作的状态任务 其返回结果如下
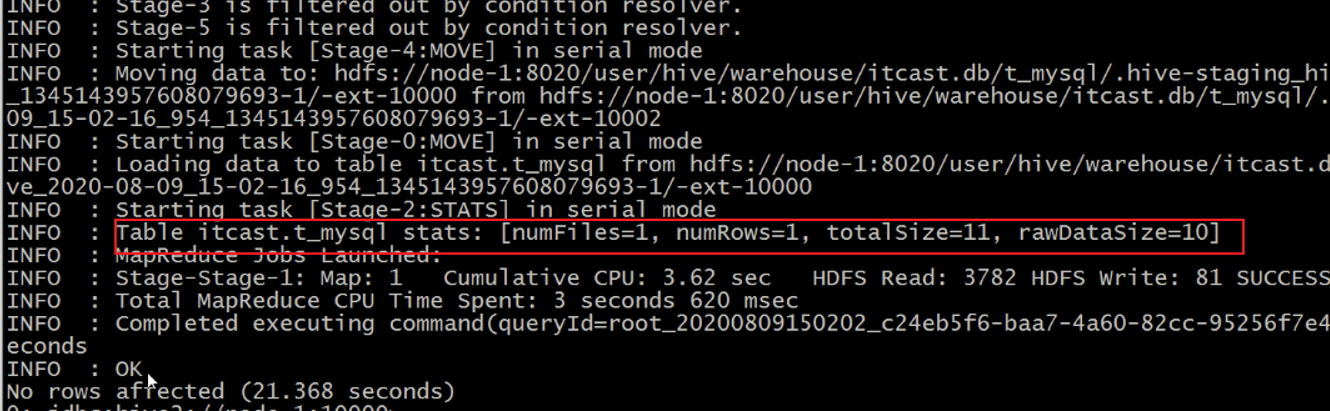
-
此信息类似于计数器 用于告知用户插入数据的相关信息 但是不影响程序的正常执行。
-
Hive新版本中 这是一个issues 临时解决方式如下
https://community.cloudera.com/t5/Support-Questions/Hive-Metastore-Connection-Failure-then-Retry/td-p/151661
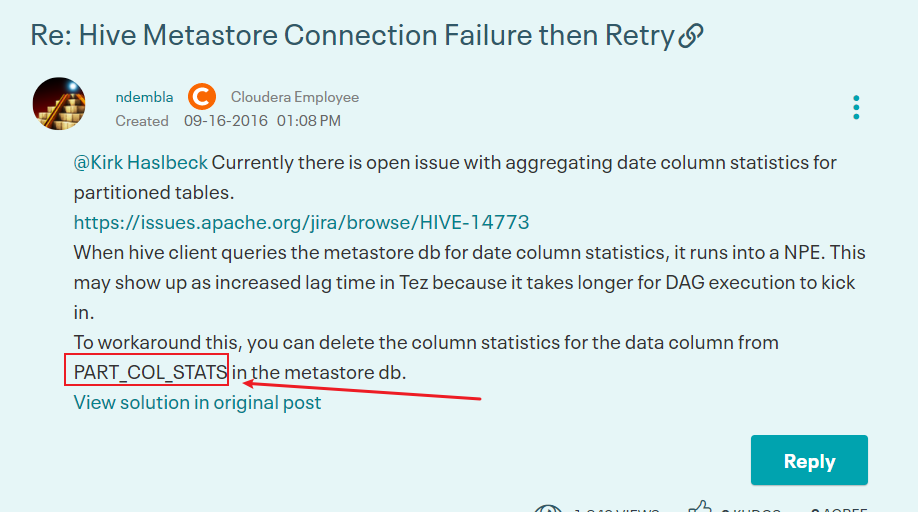
-
在mysql metastore中删除 PART_COL_STATS这张表即可。
-
-
Hive on Spark
上传文件到software文件夹下
cd /export/server
mkdir spark
#解压spark文件
tar -zxvf spark-3.0.0-bin-hadoop3.2
#将spark移动到server文件夹下
mv /export/software/spark-3.0.0-bin-hadoop3.2 /export/server/spark
编辑profile文件
vim /etc/profile
在尾部追加以下内容
#spark
export SPARK_HOME=/export/server/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
新建spark问价:
vim /export/server/apache-hive-3.1.2-bin/conf/spark-defaults.conf
追加以下这些内容:
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
根据配置文件设置的历史目录,在hdfs上新建相应的目录:
hadoop fs -mkdir /spark-history
向HDFS上传Spark纯净版jar包
由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到
- 上传并解压spark-3.0.0-bin-without-hadoop.tgz
tar -zxvf /export/software/spark-3.0.0-bin-without-hadoop.tgz
- 上传Spark纯净版jar包到HDFS
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
修改hive-site.xml文件
添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://node1:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
到这里,Hive on Spark就已经配置完了,可以进行测试,看是否配置成功
启动客户端之后,插入一条数据
insert into table student values(1,'abc');
zookeeper
配置信息
bin 存放系统脚本
conf 存放配置文件
contrib zk附加功能支持
dist-maven maven仓库文件
docs zk文档
lib 依赖的第三方库
recipes 经典场景样例代码
src zk源码
Config目录下的文件介绍





安装单机
1、在opt目录下创建一个zookeeper目录并在zookeeper目录下创建zkdata目录
mkdir zookeeper
2、讲zookeeper软件包上传到/opt/zookeeper目录中并解压
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
3、进入conf配置目录中修改zoo_sample.cfg文件
cd conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
4、将dataDir改为/opt/zookeeper/zkdata
保存退出
5、进入bin目录中测试是否安装成功
./zkServer.sh

如果出现上图所示,即表示安装成功
回到zookeeper目录下,启动客户端
bin/zkCli.sh


输入quit退出
配置集群
分发给node2和node3
scp -r zookeeper/ root@node2:$PWD
scp -r zookeeper/ root@node3:$PWD
在node1的zkData目录下执行
vim myid
将1存入其中,保存并退出
在node2的zkData目录下执行
vim myid
将2存入其中,保存并退出
在node3的zkData目录下执行
vim myid
将3存入其中,保存并退出
进入zookeeper的conf目录,编辑zoo.cfg(三台都需要)
加入
server.1=192.168.88.151:2888:3888
server.2=192.168.88.152:2888:3888
server.3=192.168.88.153:2888:3888
编辑环境变量
vim /etc/profile
加入以下代码
#zookeeper
export ZK_HOME=/export/server/zookeeper/apache-zookeeper-3.5.7-bin
export PATH=$PATH:$ZK_HOME/bin
问题
ZooKeeper JMX enabled by default
Using config: /export/server/zookeeper/apache-zookeeper-3.5.7-bin/bin/../conf/zoo.cfg
Starting zookeeper ... FAILED TO START

server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
不可以有空格,一定不能有空格!!!!!!!
在 zkServer.sh 文件的开头部分,加上jdk环境变量信息
添加JAVA_HOME的环境变量(这里要自己去查看自己配置的)
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin






博客推荐
http://t.csdn.cn/7Y2cm(安装zookeeper)
http://t.csdn.cn/jExCl(搭建zookeeper)
Sqoop
解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /export/server/sqoop
进到/export/server/sqoop/conf目录下重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh
修改配置文件
vim sqoop-env.sh
在下方添加这些数据
export HADOOP_COMMON_HOME=/export/server/hadoop-3.3.0
export HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.0
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export ZOOKEEPER_HOME=/export/server/zookeeper/apache-zookeeper-3.5.7-bin
export ZOOCFGDIR=/export/server/zookeeper/apache-zookeeper-3.5.7-bin/conf
拷贝mysql驱动至sqoop的lib目录下
[root@master software]# cp mysql-connector-java-5.1.27-bin.jar /export/server/sqoop/lib/
验证 进到sqoop目录下
[root@master sqoop-1.4.6]# bin/sqoop help
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
测试sqoop是否能够成功连接数据库
bin/sqoop list-databases --connect jdbc:mysql://node1:3306/ --username root --password 123456
information_schema
metastore
mysql
performance_schema
sys
superset
安装docker
curl -sSL https://get.daocloud.io/docker | sh
启动docker
systemctl start docker
systemctl enable docker
安装superset
docker pull amancevice/superset:0.37.2
mkdir -p /export/server/docker/superset/conf
mkdir -p /export/server/docker/superset/data
docker run --name superset -u 0 -d -p 8088:8088 -v /export/server/docker/superset/conf:/etc/superset -v /export/server/docker/superset/data:/var/lib/superset amancevice/superset:0.37.2
docker exec -it superset superset db upgrade
docker exec -it superset superset fab create-admin


docker exec -it superset superset init
docker exec -it superset superset run --with-threads --reload --debugger
浏览器地址栏输入 IP:8088

安装mysql
docker pull mysql
docker images
docker run -di --name=mysql -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
docker ps
docker exec -it mysql /bin/bash
mysql -h 127.0.0.1 -uroot -p
123456
